



















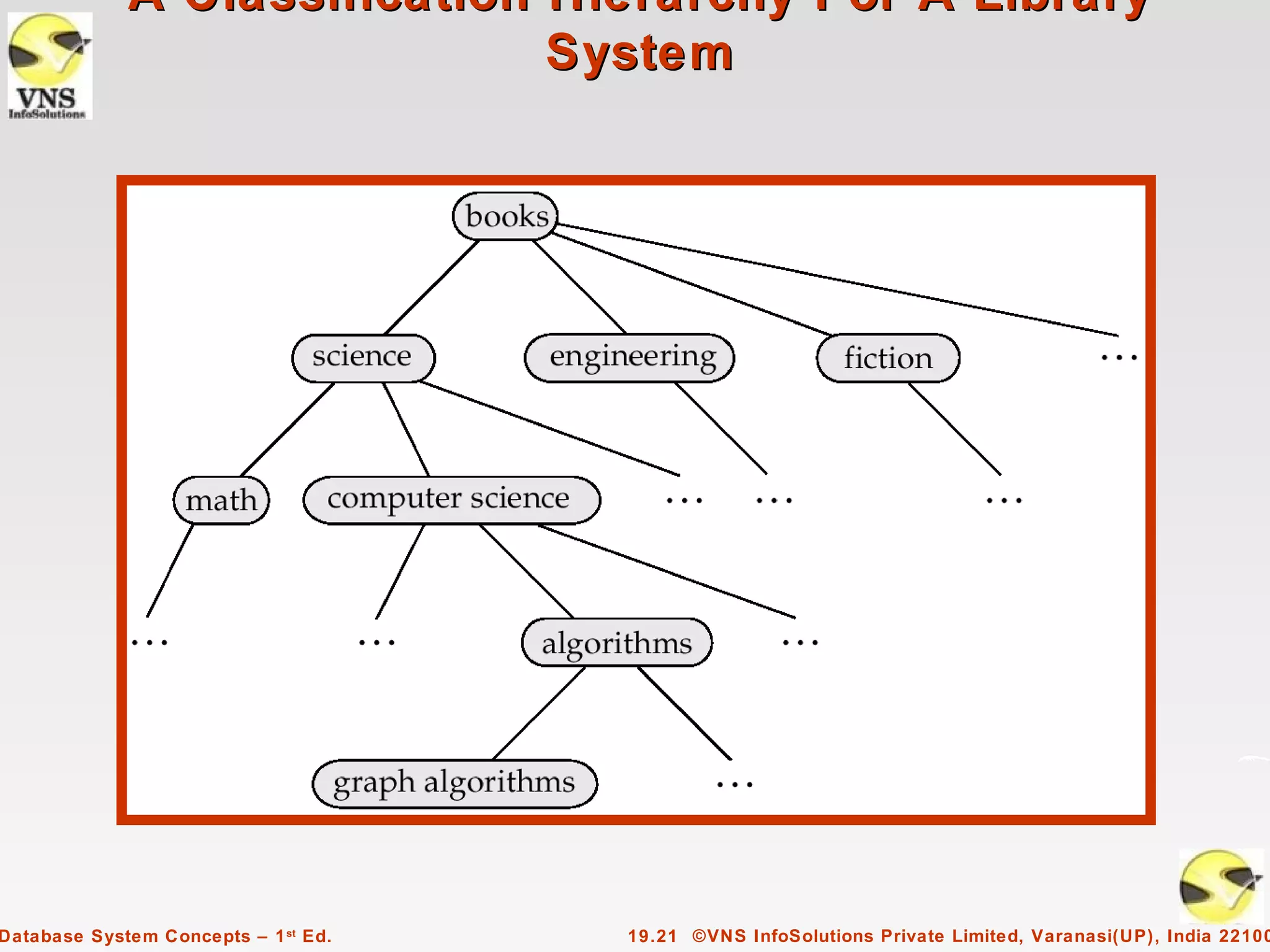
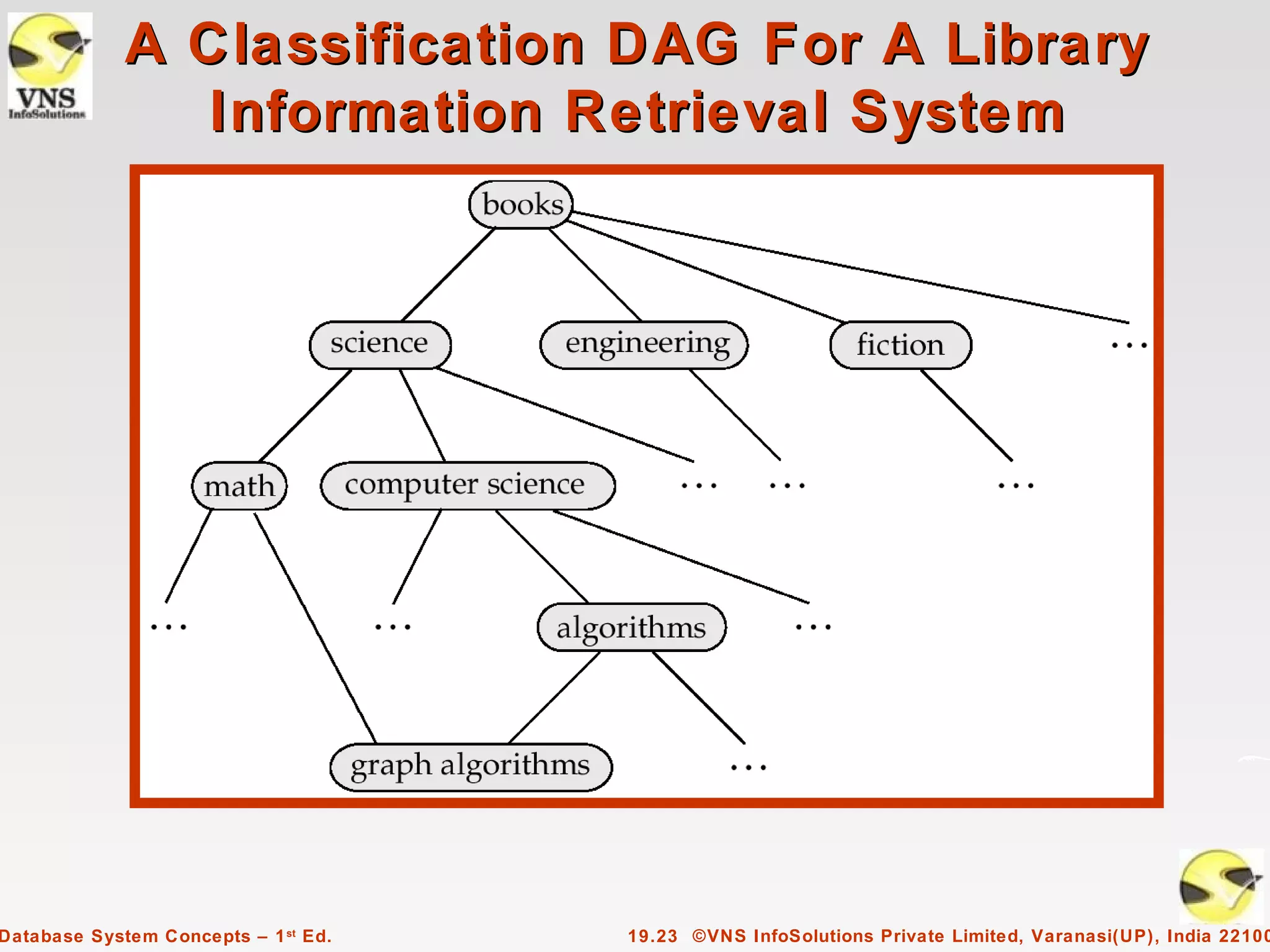



Chapter 19 discusses information retrieval (IR) systems, which differ from database systems by handling unstructured data and utilizing keyword-based searches for relevance ranking. Key concepts include term frequency-inverse document frequency (TF-IDF), hyperlink analysis, and the importance of context in disambiguating synonyms and homonyms. Additionally, the chapter covers indexing techniques, measuring retrieval effectiveness, and the role of web search engines and crawlers in IR systems.



































































