




![I/O Parallelism (Cont.)
s Partitioning techniques (cont.):
s Range partitioning:
q Choose an attribute as the partitioning attribute.
q A partitioning vector [vo, v1, ..., vn-2] is chosen.
q Let v be the partitioning attribute value of a tuple. Tuples such that
vi ≤ vi+1 go to disk I + 1. Tuples with v < v0 go to disk 0 and tuples
with v ≥ vn-2 go to disk n-1.
E.g., with a partitioning vector [5,11], a tuple with partitioning attribute
value of 2 will go to disk 0, a tuple with value 8 will go to disk 1,
while a tuple with value 20 will go to disk2.
Database System Concepts – 1 st Ed. 21.6 © VNS InfoSolutions Private Limited, Varanasi(UP), India 22100](https://image.slidesharecdn.com/vnsispldbmsconceptsch21-120310154329-phpapp02/75/VNSISPL_DBMS_Concepts_ch21-6-2048.jpg)

















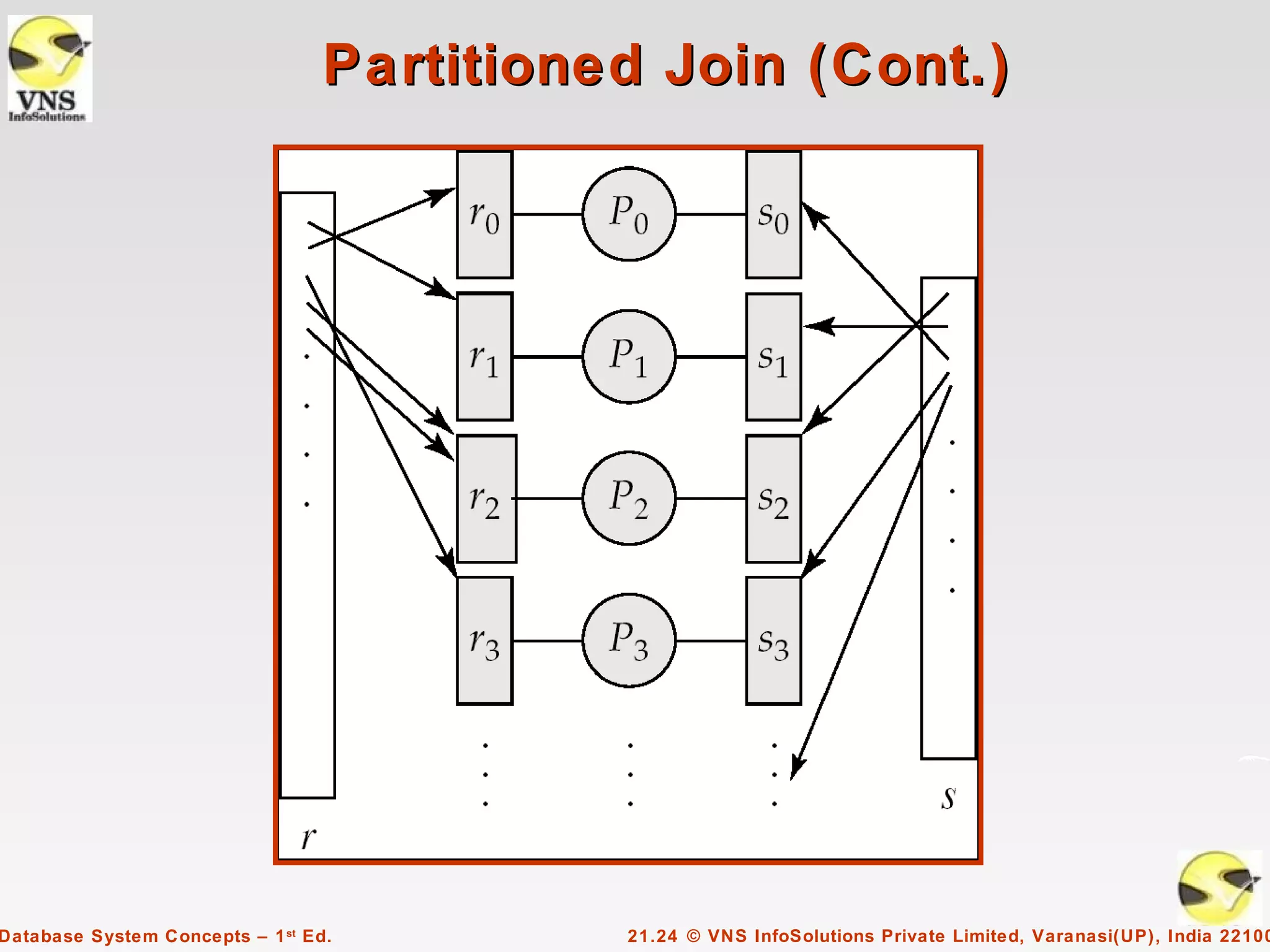

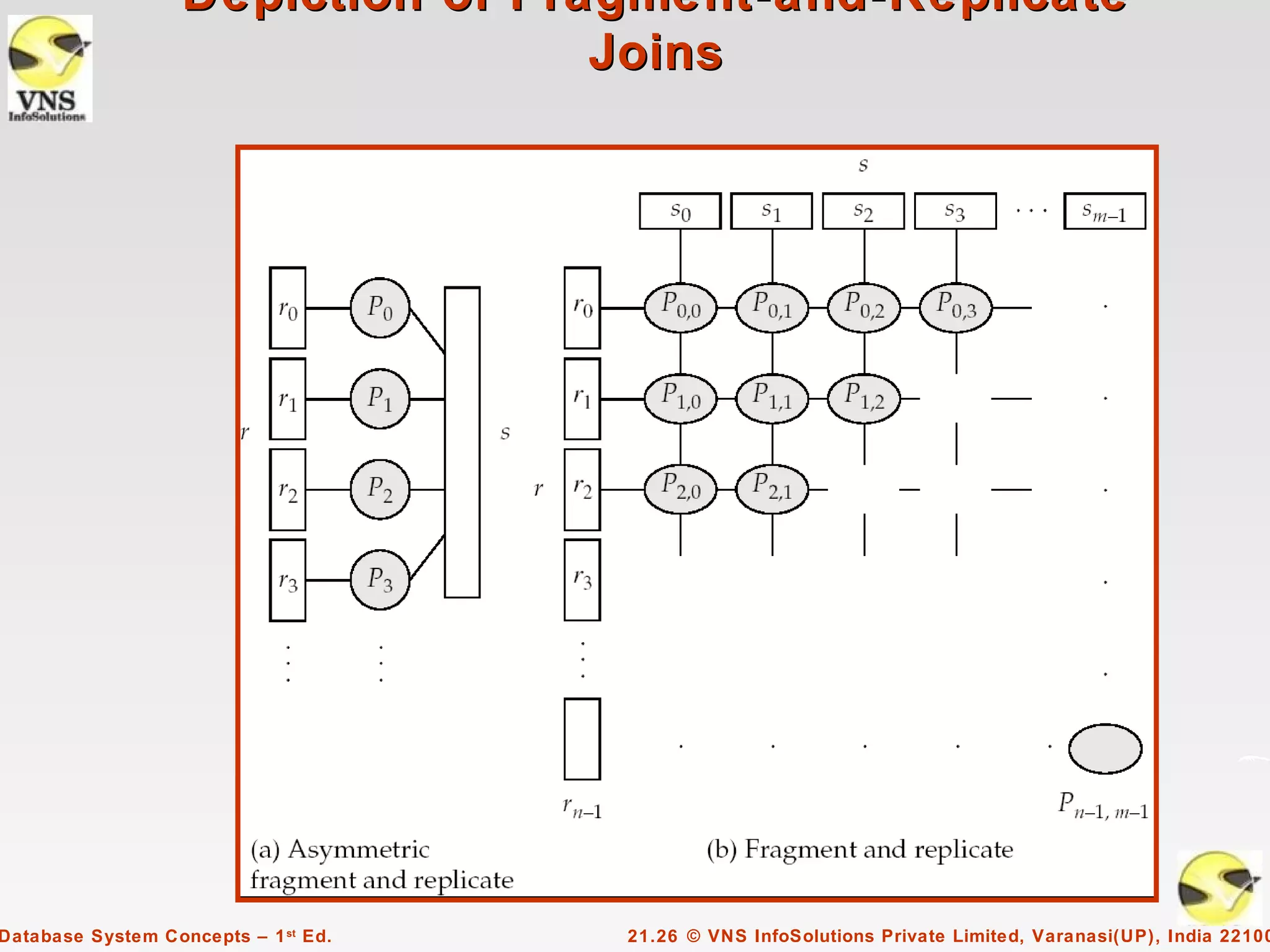


















Chapter 21 discusses parallel databases, emphasizing the increasing affordability of parallel machines and the growing volume of data in databases. It elaborates on various types of parallelism including I/O, interquery, and intraquery parallelism, as well as techniques for partitioning data across multiple disks to enhance query performance. Additionally, it covers the handling of data skew and techniques such as fragment-and-replicate joins for efficient query execution.



































































