Download to read offline




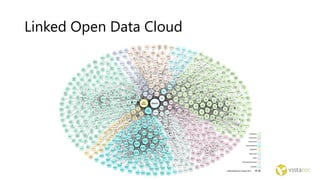
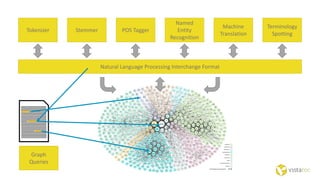
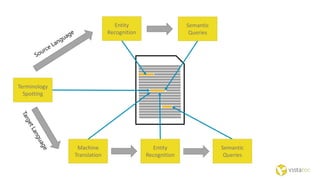

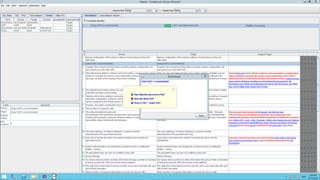

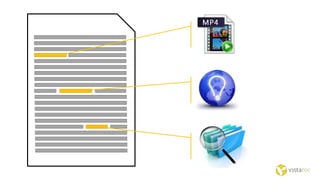

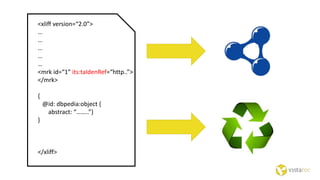
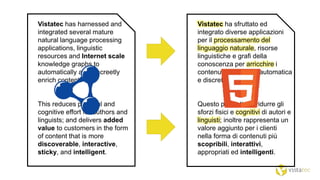
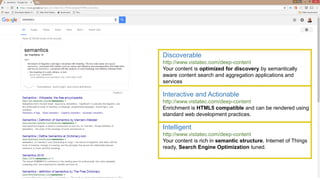

The document discusses the Internet of Things and natural language processing. It describes how Vistatec has integrated various natural language processing tools, linguistic resources, and knowledge graphs to automatically enrich content. This reduces effort for authors while delivering more discoverable, interactive, and intelligent content for customers. Content enriched by Vistatec's techniques is optimized for discovery, can be interacted with, and is prepared for the Internet of Things.






























































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)












