Download as PDF, PPTX


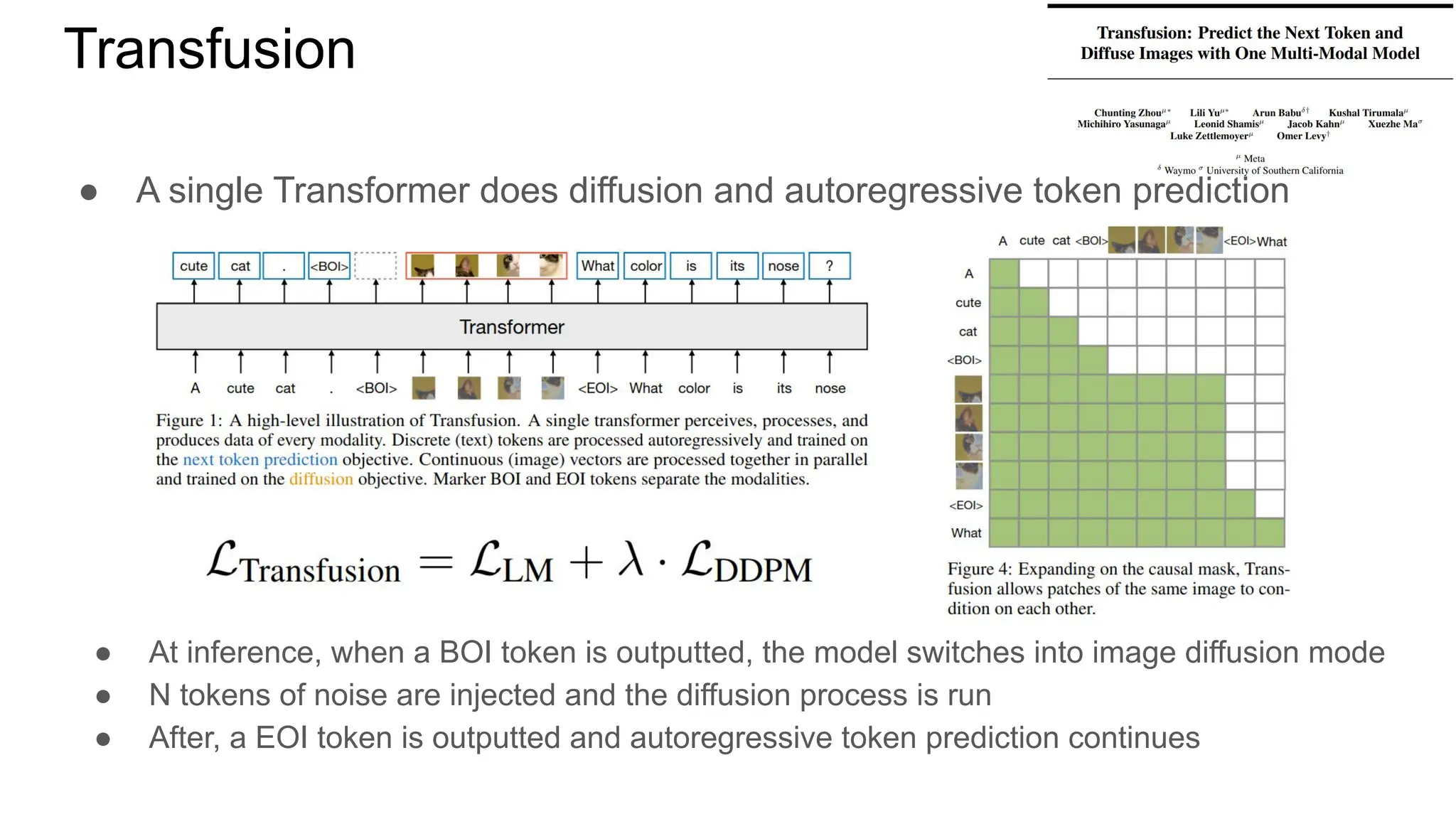
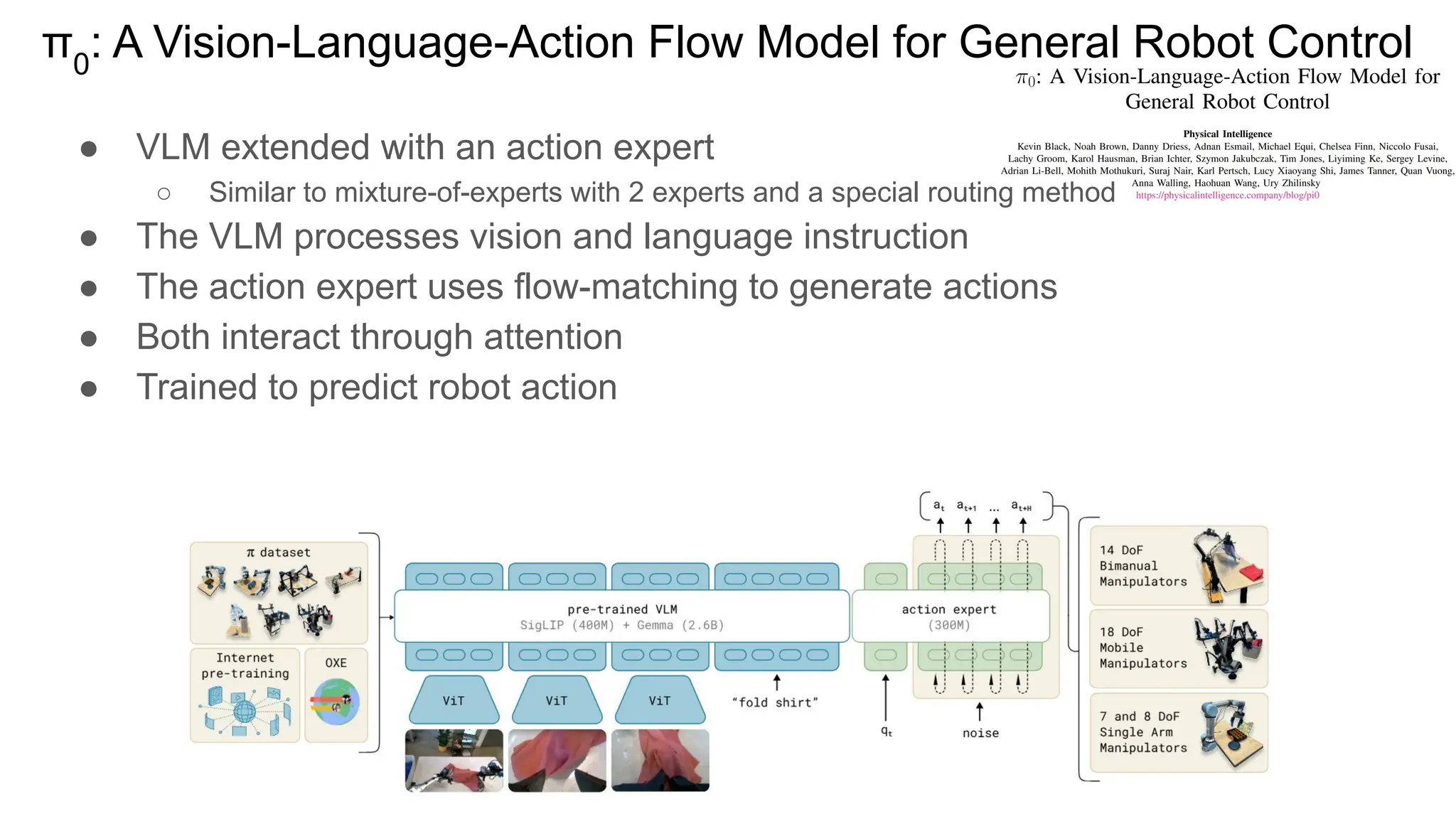

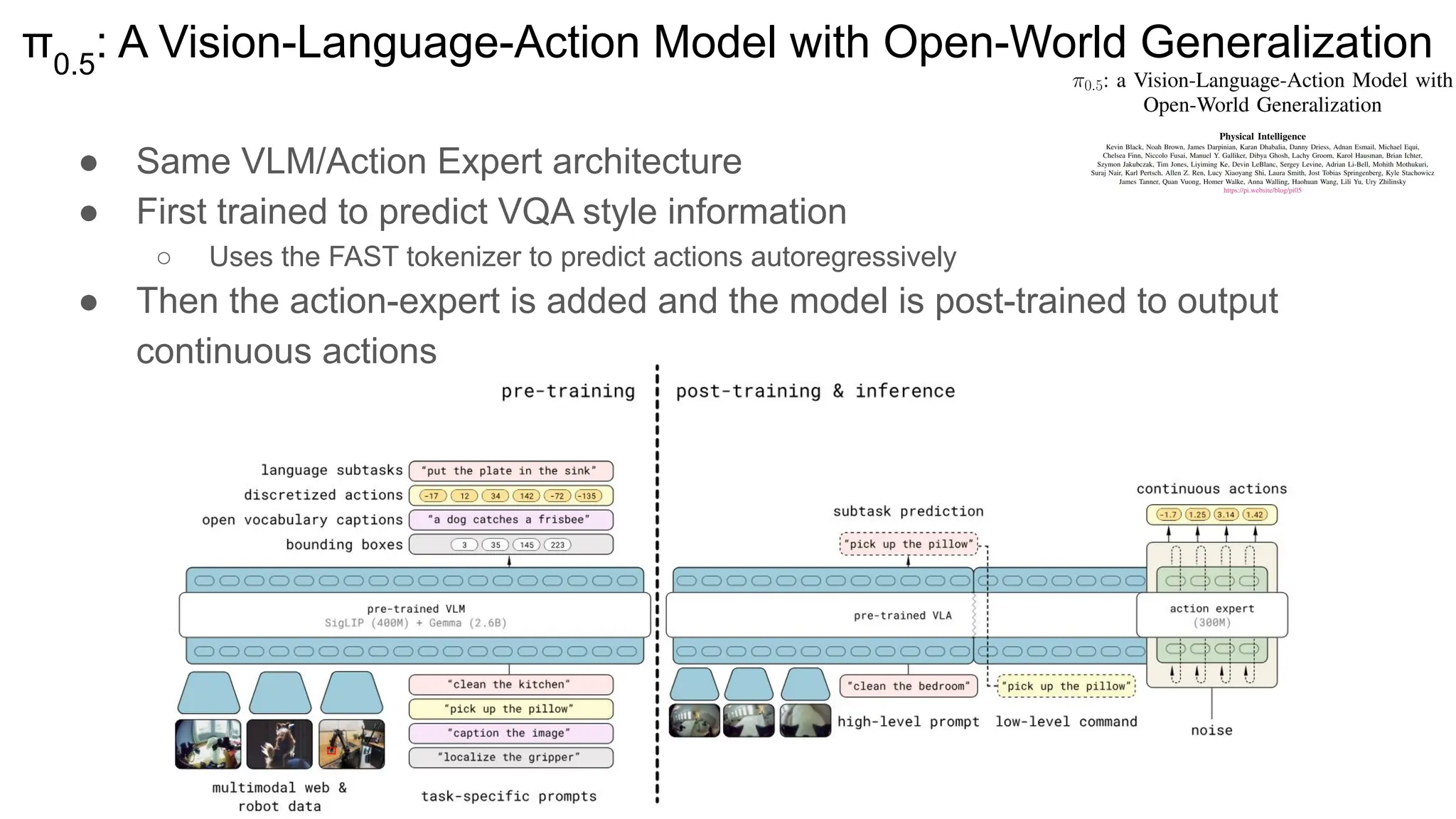





今回の資料「Transfusion / π0 / π0.5」は、画像・言語・アクションを統合するロボット基盤モデルについて紹介しています。 拡散×自己回帰を融合したTransformerをベースに、π0.5ではオープンワールドでの推論・計画も可能に。 This presentation introduces robot foundation models that integrate vision, language, and action. Built on a Transformer combining diffusion and autoregression, π0.5 enables reasoning and planning in open-world settings.









![Blue_Futuristic_Technology_Presentation_(3)[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/bluefuturistictechnologypresentation31-250520171656-4912de65-thumbnail.jpg?width=640&height=640&fit=bounds)

























































