Downloaded 15 times














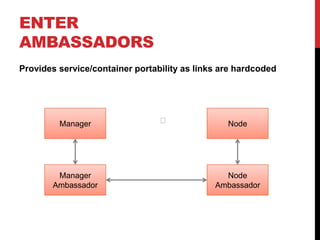





The document discusses Docker, an open platform for building and running distributed applications, and outlines its components, such as images, containers, and volumes. It explains how Docker integrates with various operating systems and cloud services, highlighting tools like Docker Machine and Docker Compose for managing and orchestrating containers. Additionally, it includes links to relevant resources and references for further exploration of Docker and its applications in development environments.























































































