Downloaded 23 times








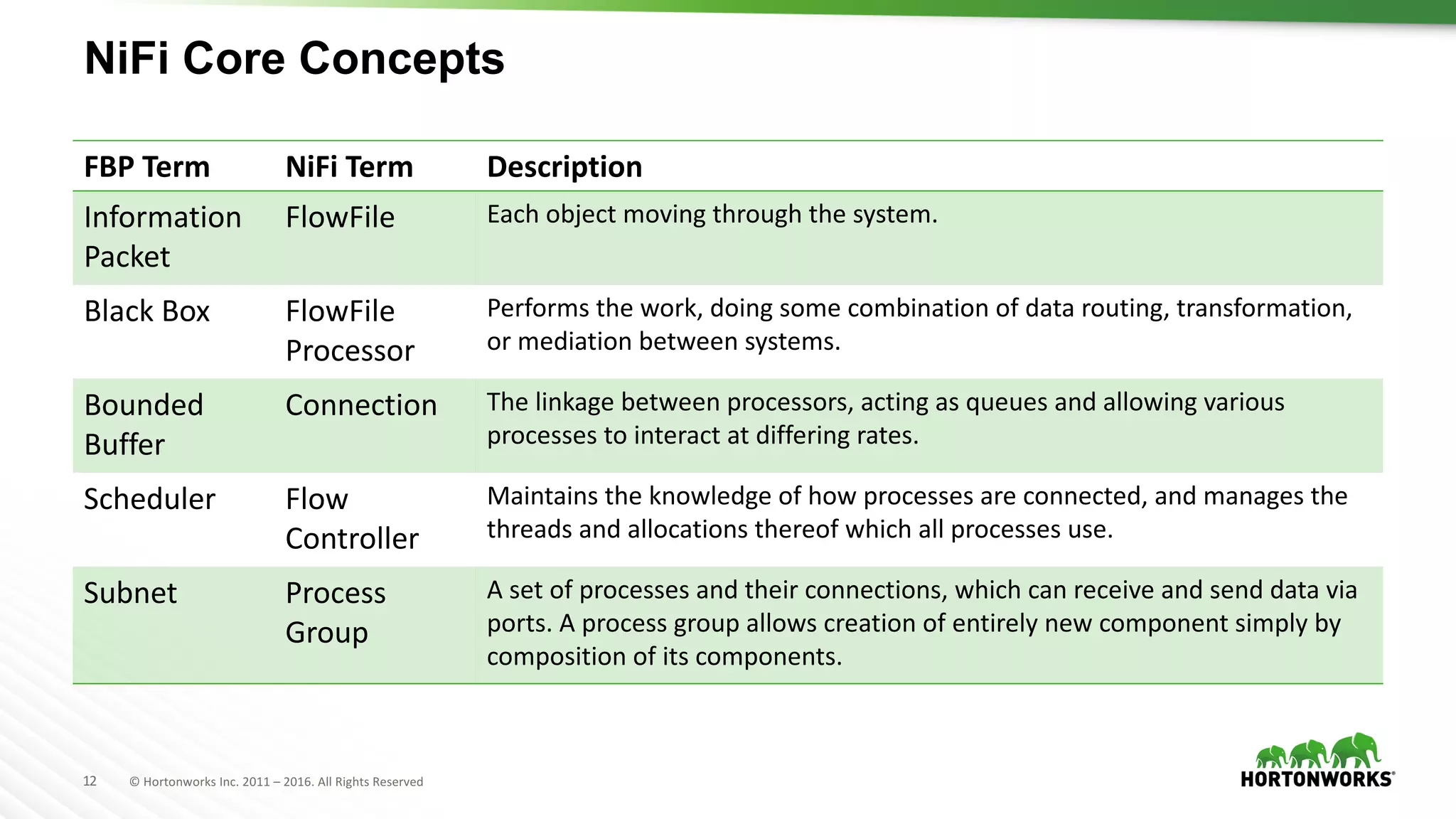

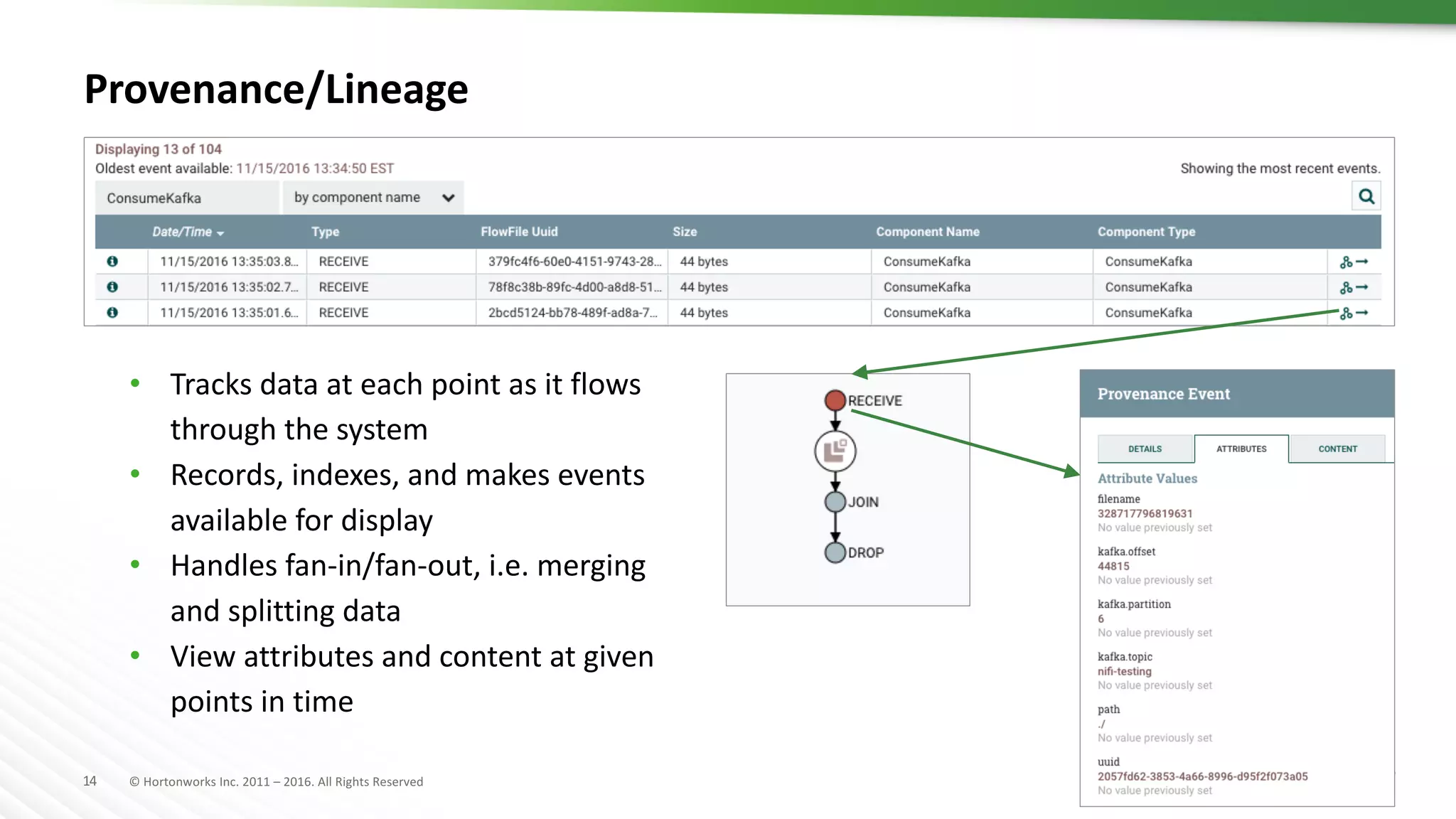



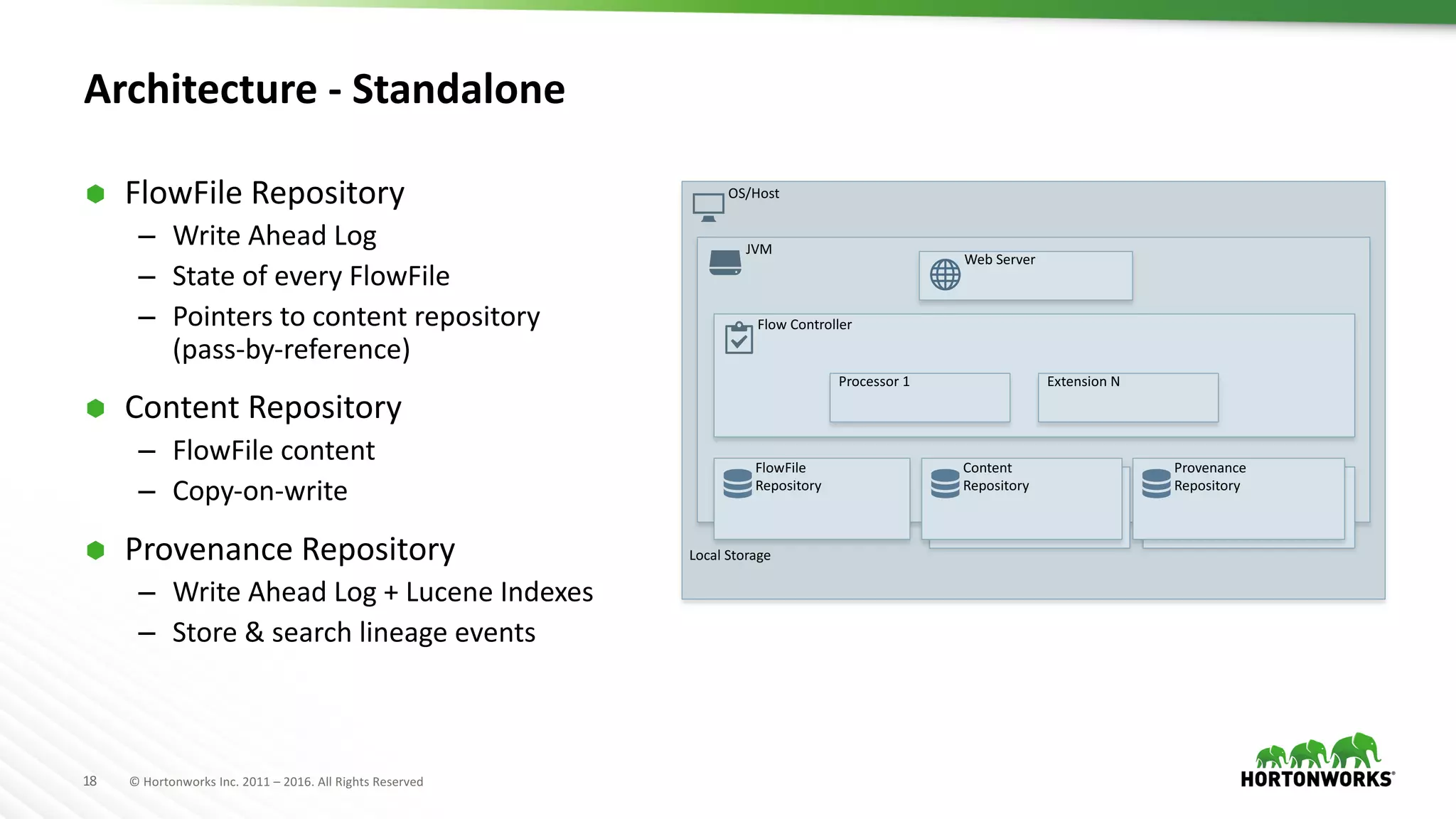
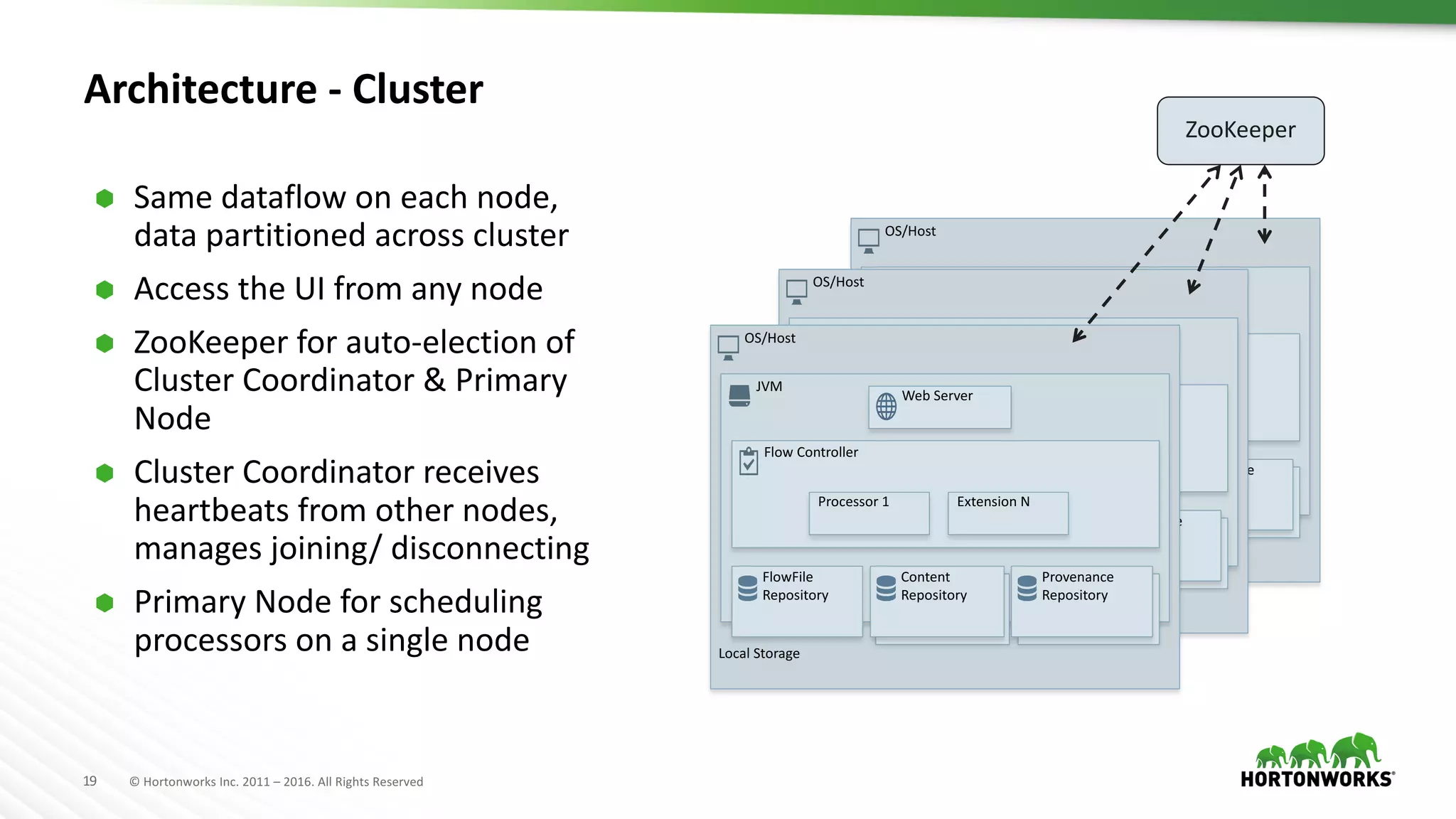


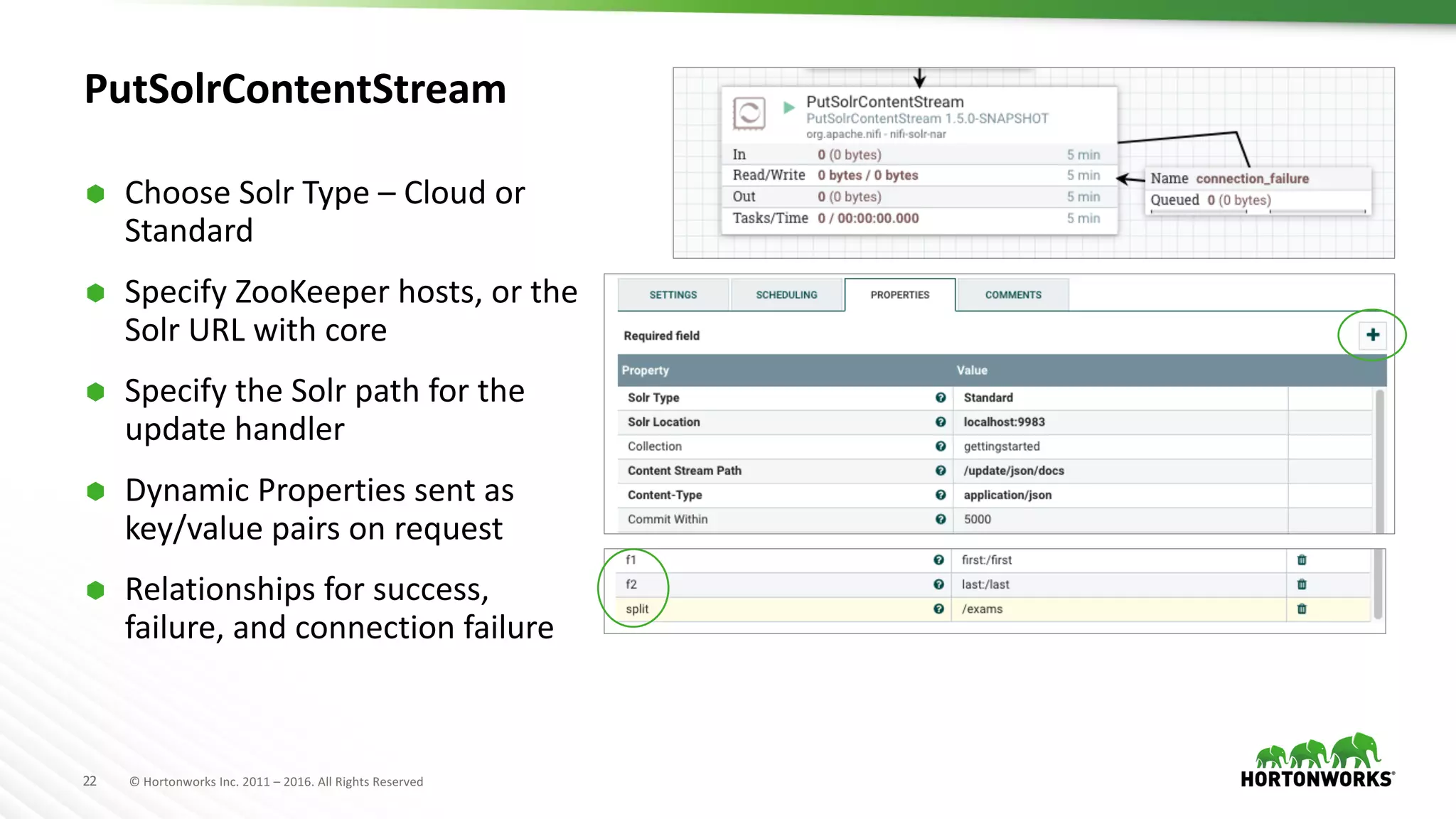














The document presents an overview of Apache NiFi, a tool designed to facilitate global enterprise data flow by addressing challenges related to data formats, protocols, and security. It discusses key features of NiFi, including visual command and control, data lineage, prioritization, and integration with Solr for data management. Recent developments and future improvements in NiFi, such as enhanced record processing and a variable registry for better parameter handling, are also highlighted.



































































