Download as PDF, PPTX


















producer.send(topic, key, value)](https://image.slidesharecdn.com/updatingmaterializedviewsandcachesusingkafka-161029132430/85/Updating-materialized-views-and-caches-using-kafka-24-320.jpg)

consumer.subscribe(topics)
while (true) {
val messages = consumer.poll(timeout)
//process list of messages
}](https://image.slidesharecdn.com/updatingmaterializedviewsandcachesusingkafka-161029132430/85/Updating-materialized-views-and-caches-using-kafka-25-320.jpg)

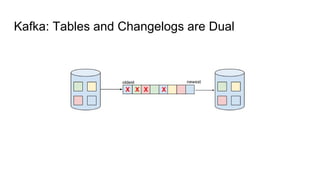
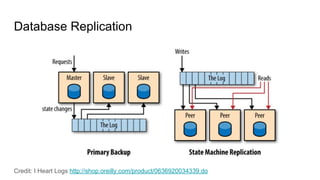


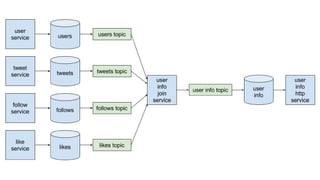
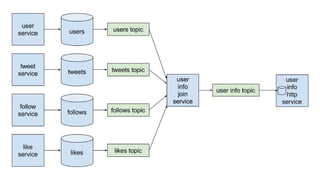

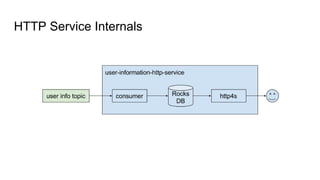

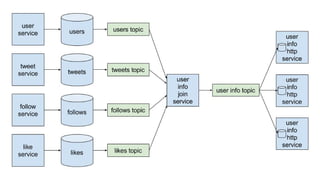
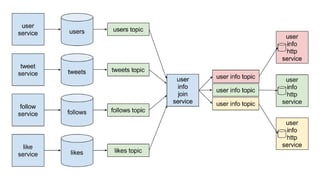
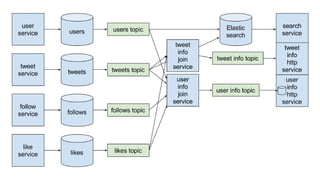
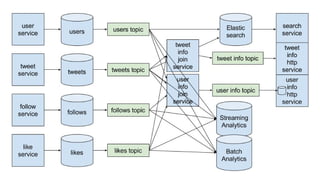

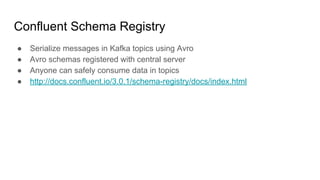

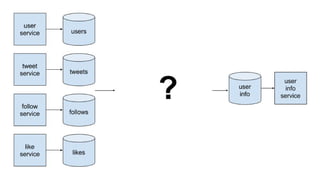
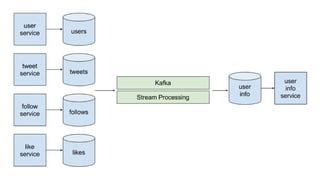
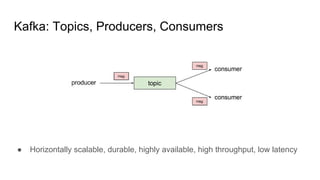
The document discusses using Apache Kafka to publish data changes and updates to materialized views and caches. It describes building a user information service that currently queries normalized data from multiple tables in a database. This has issues like slow response times and stale data. The document proposes using Kafka streams to read from topics containing normalized data changes. This allows building and storing materialized views locally using RocksDB for low latency access without stale data.












































































