Downloaded 76 times

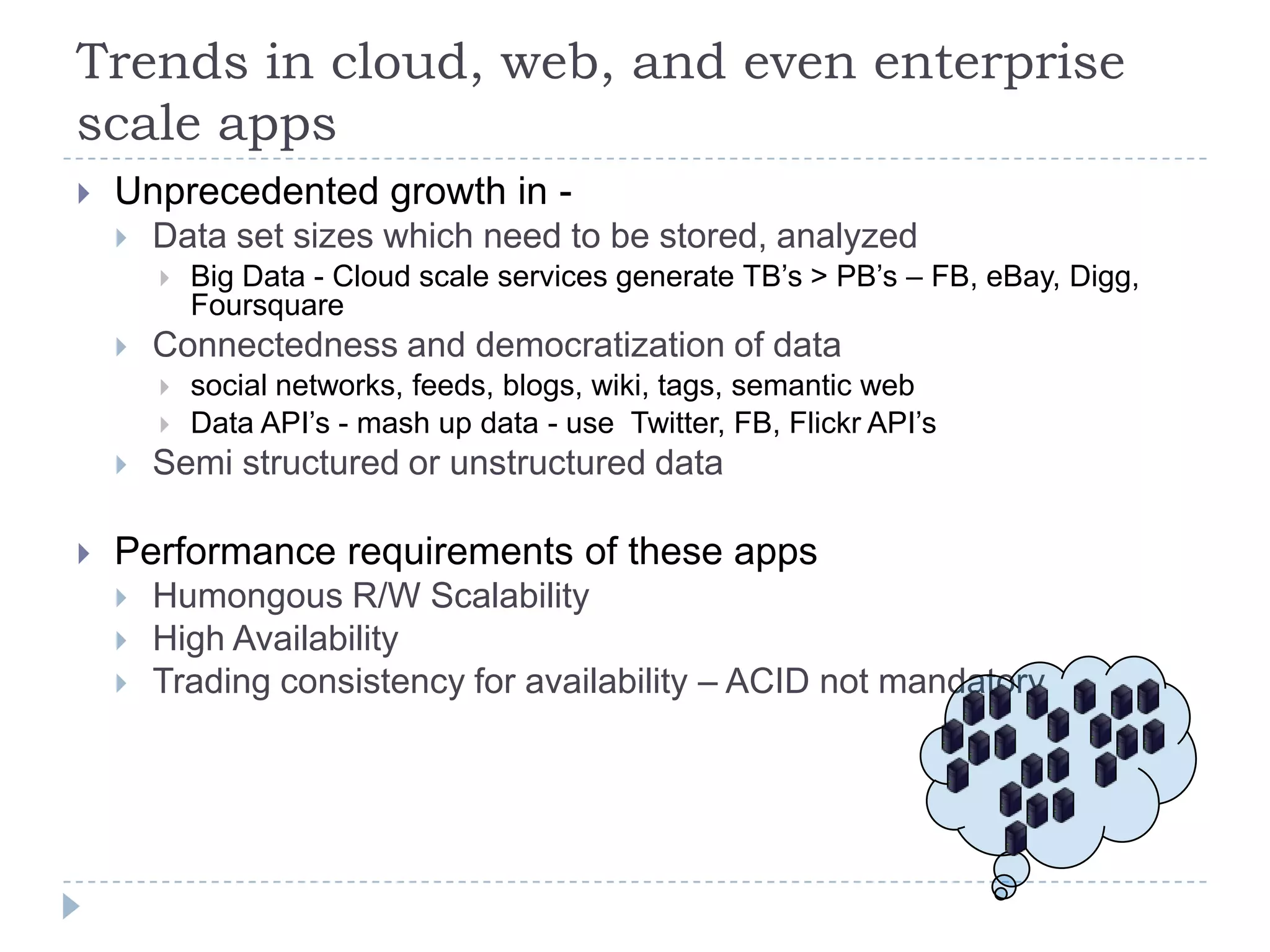
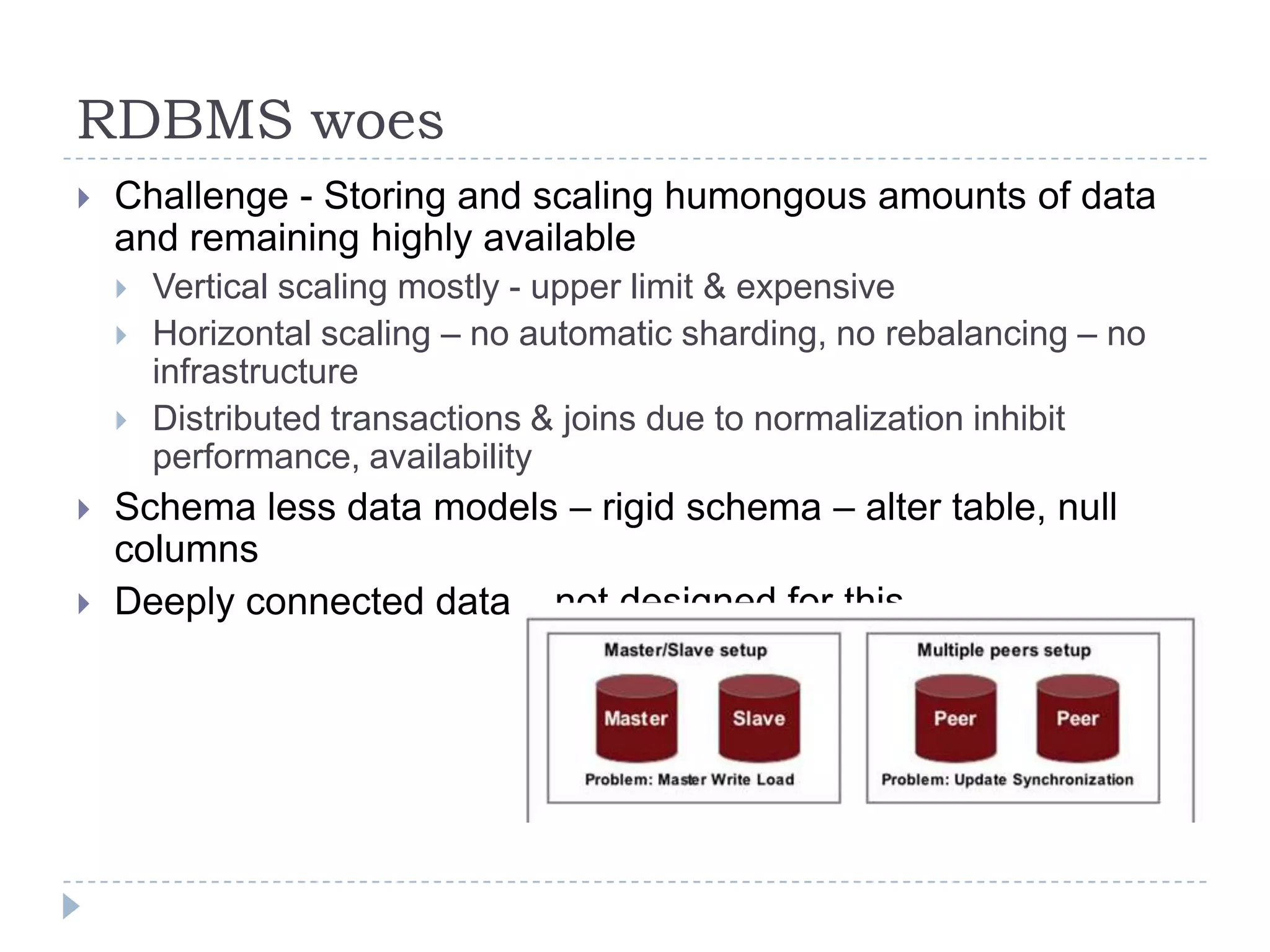






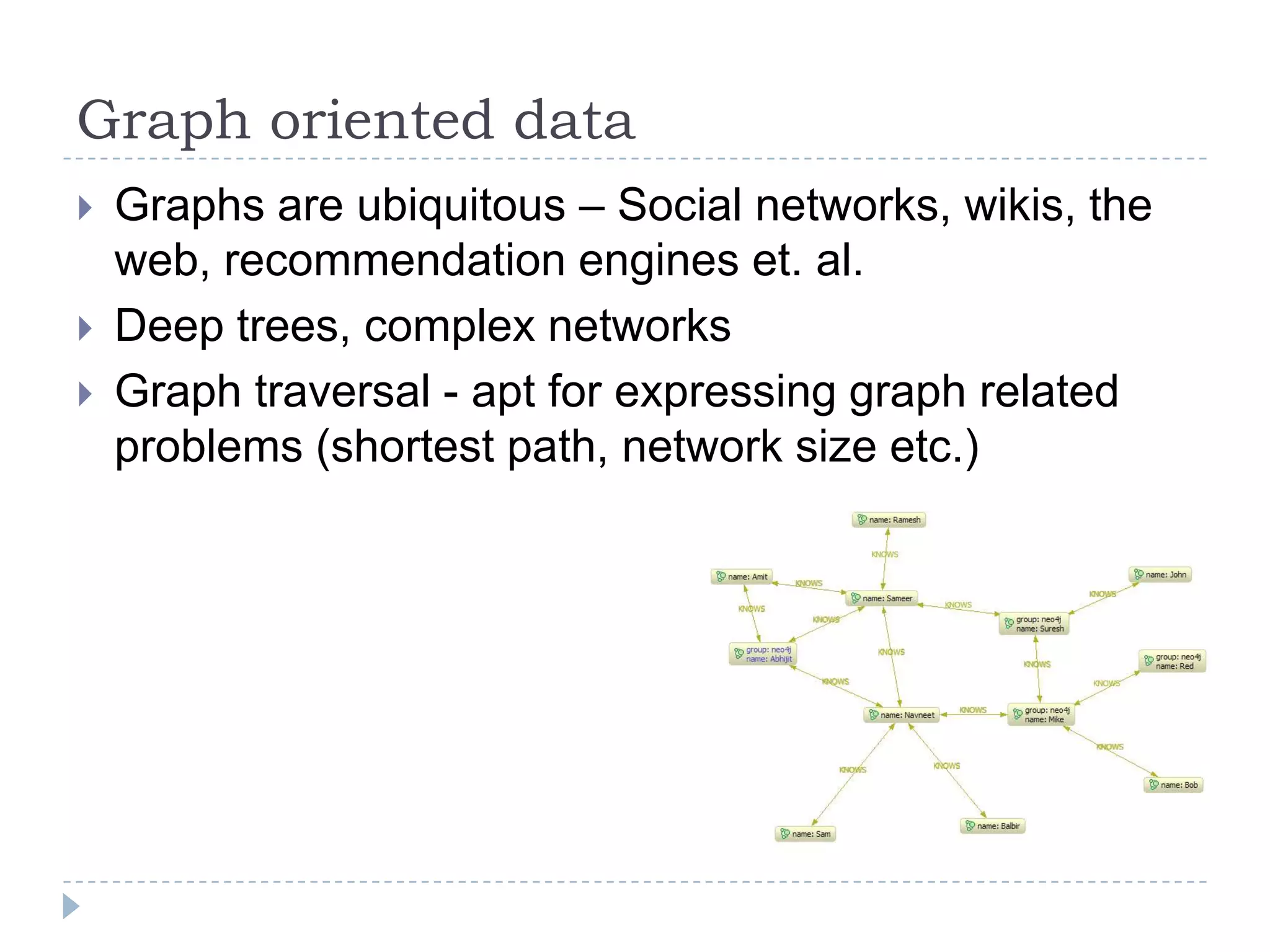
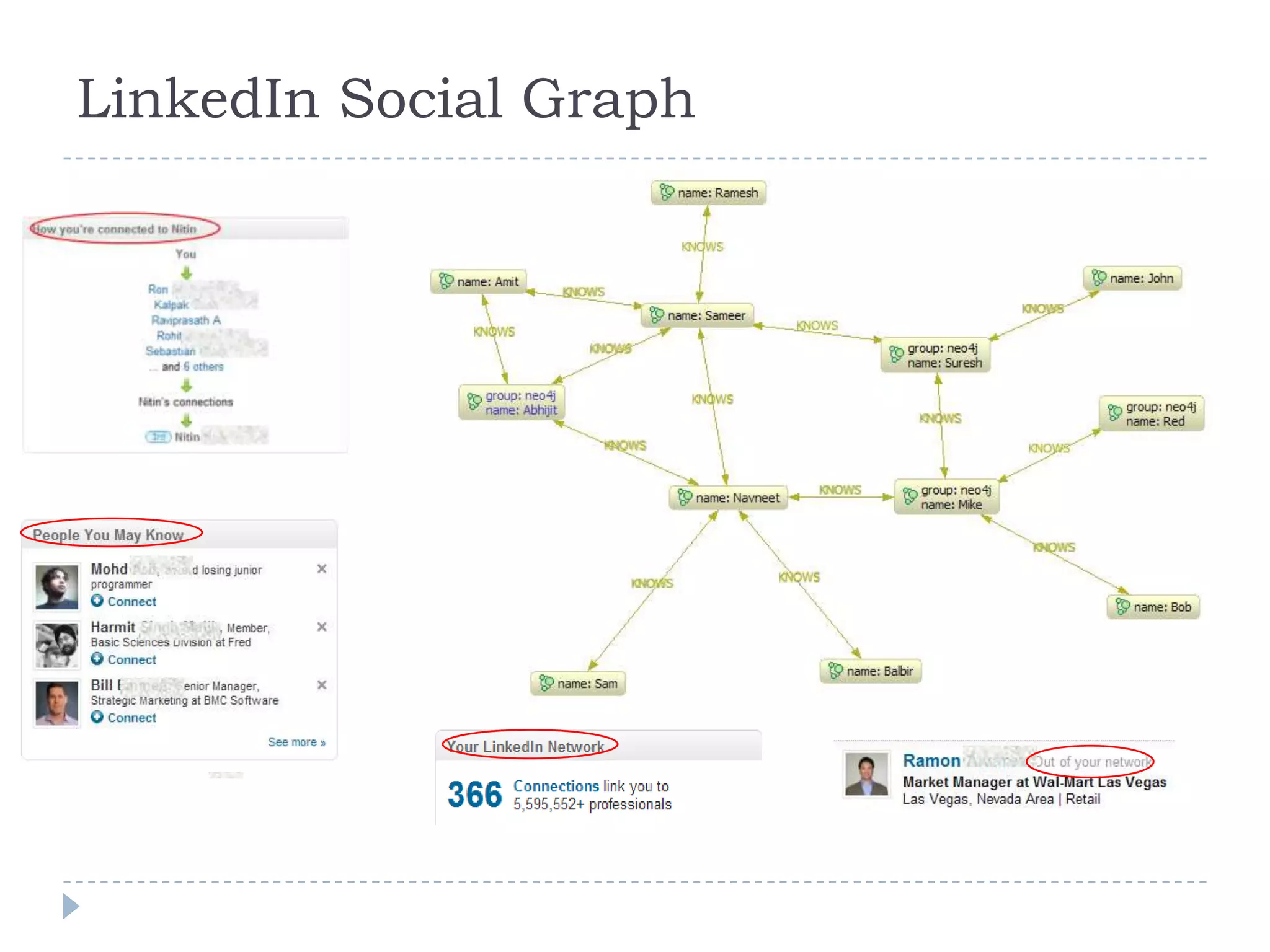


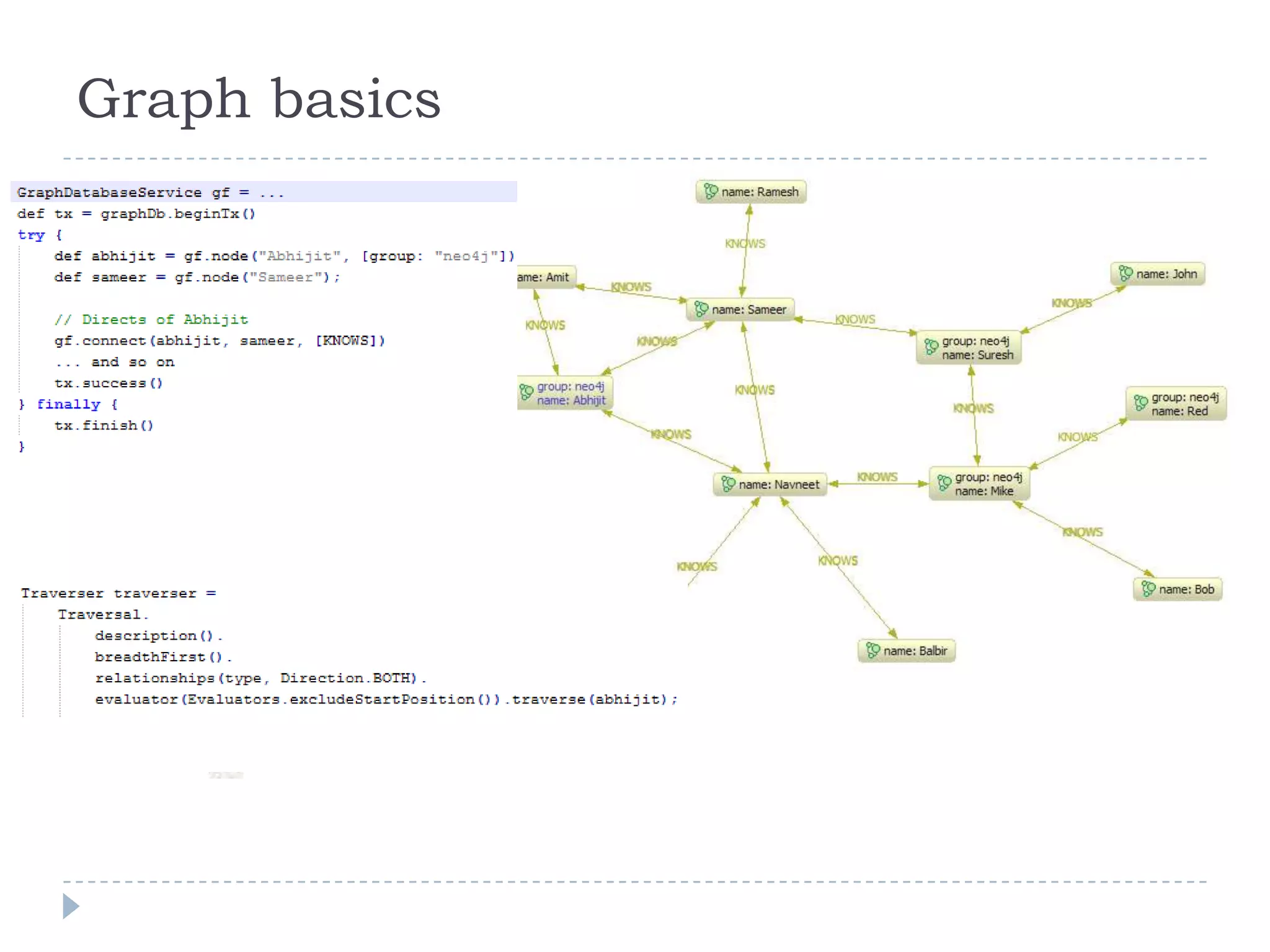
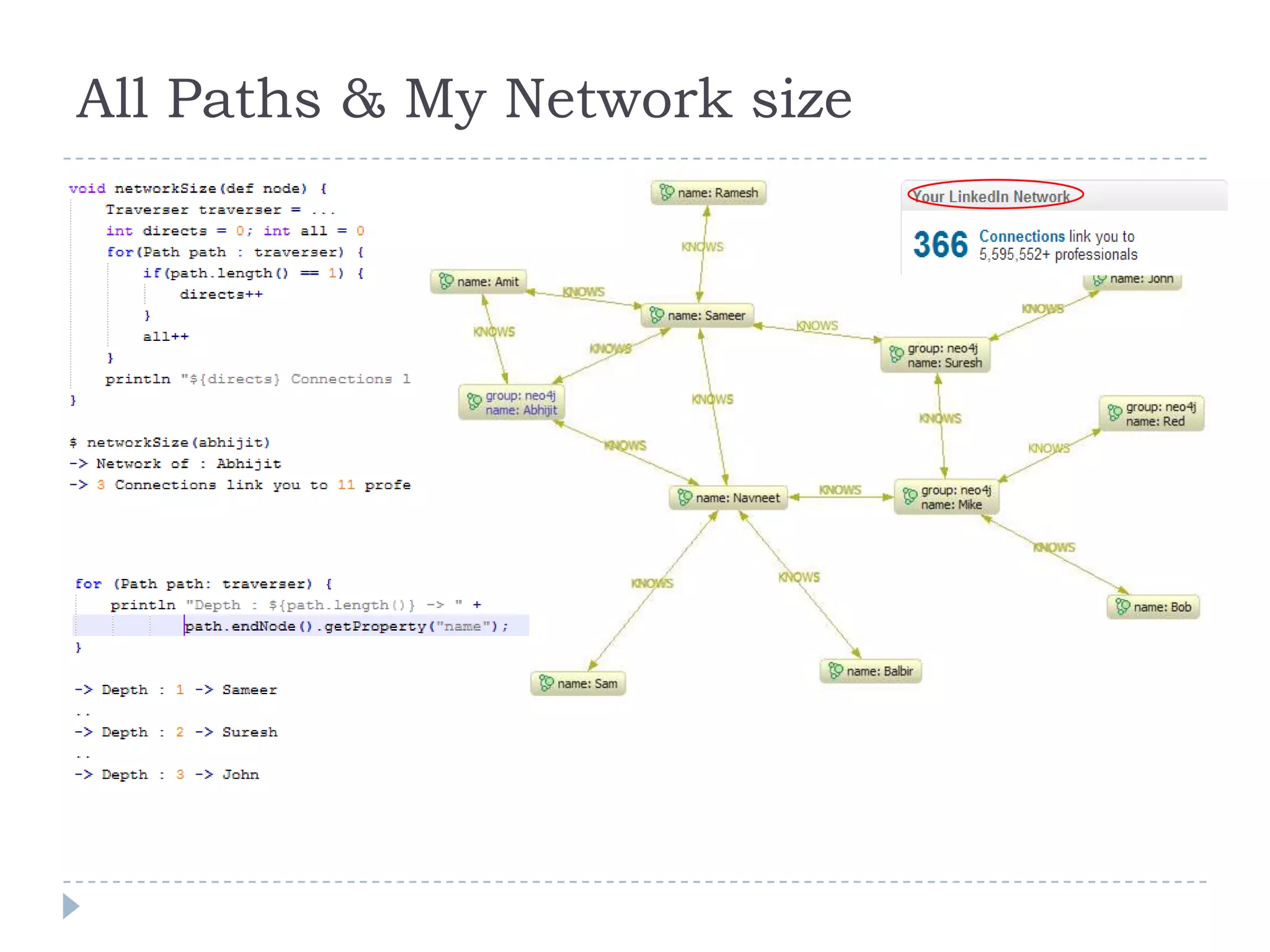
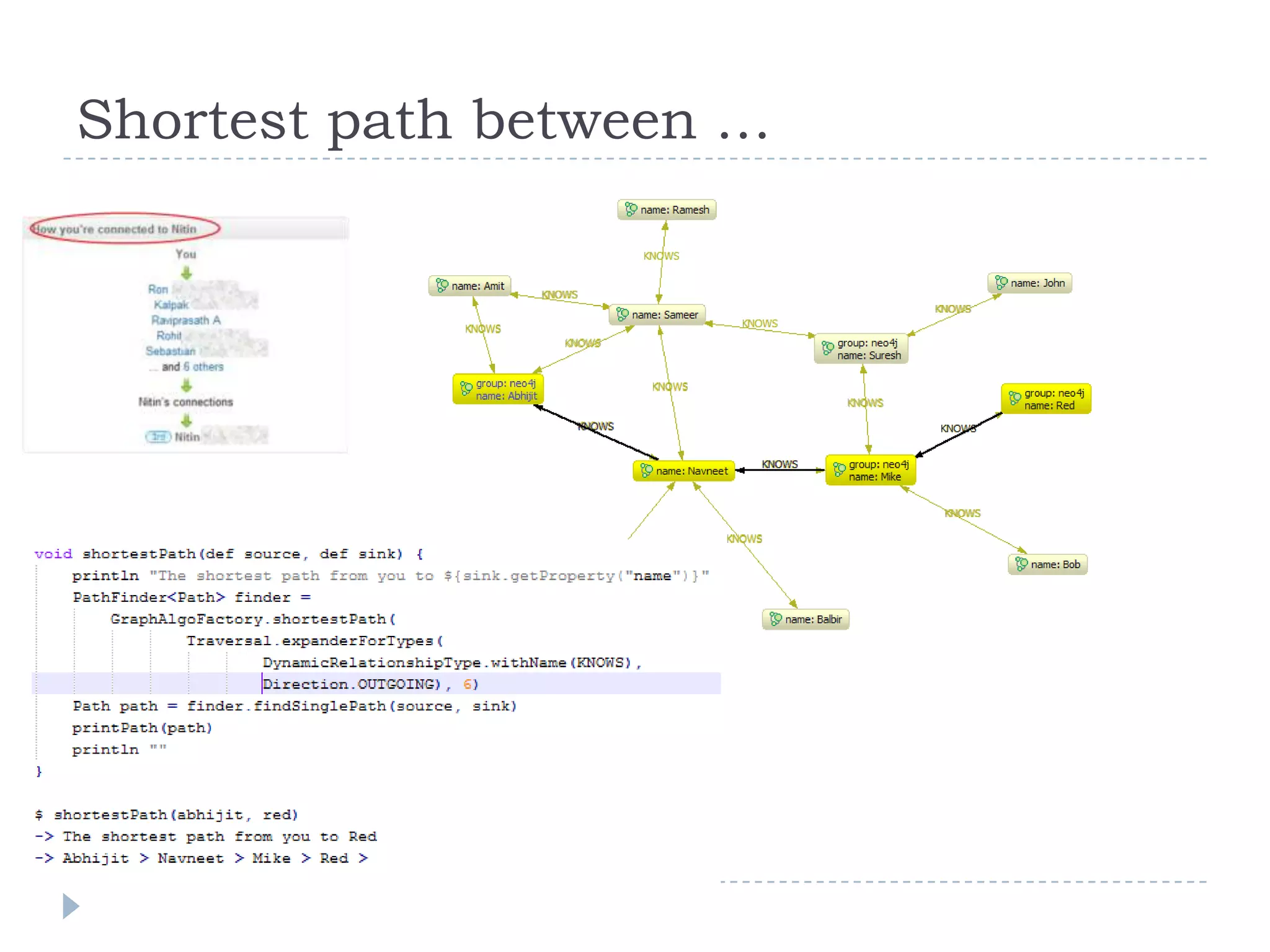
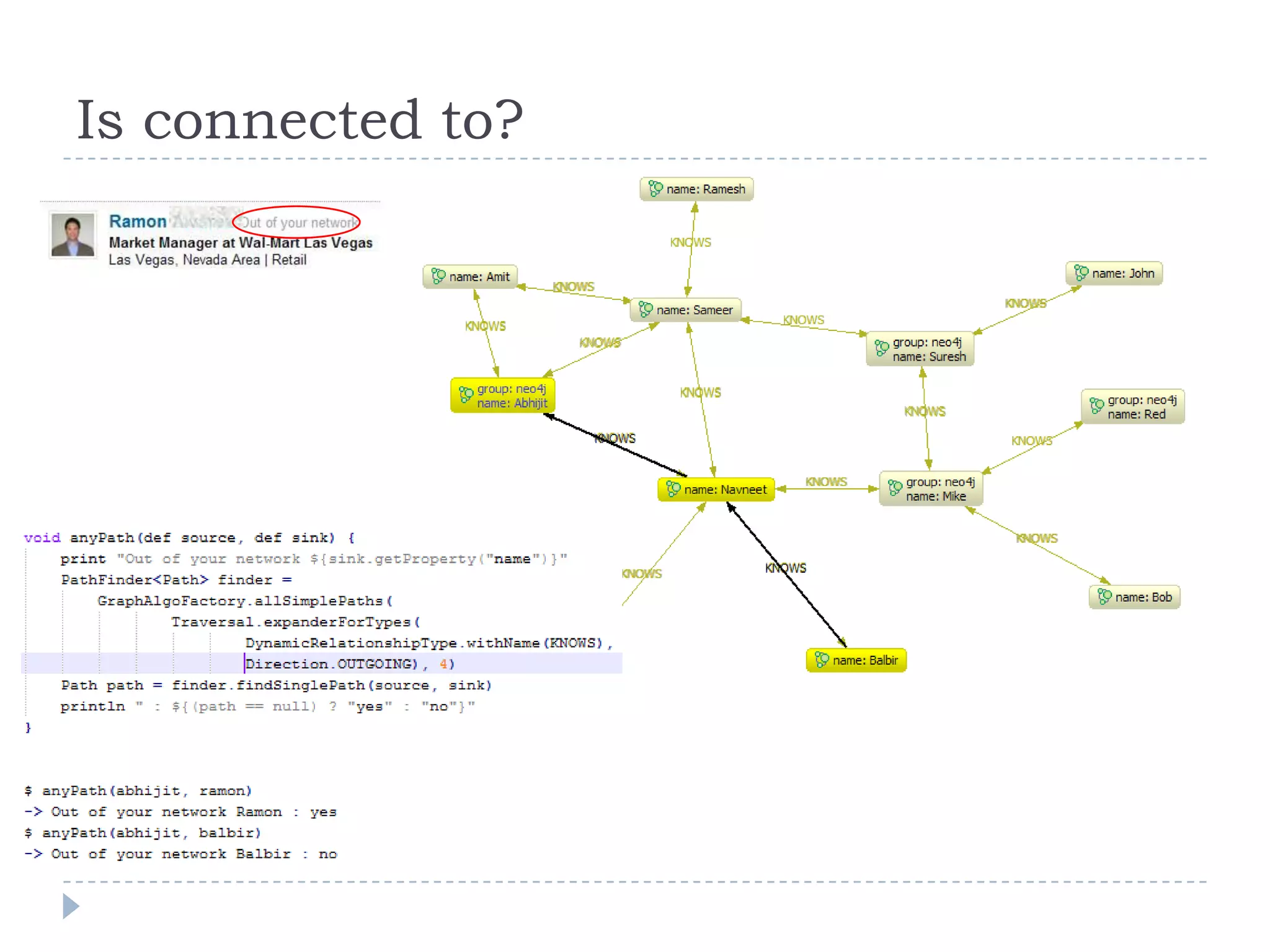
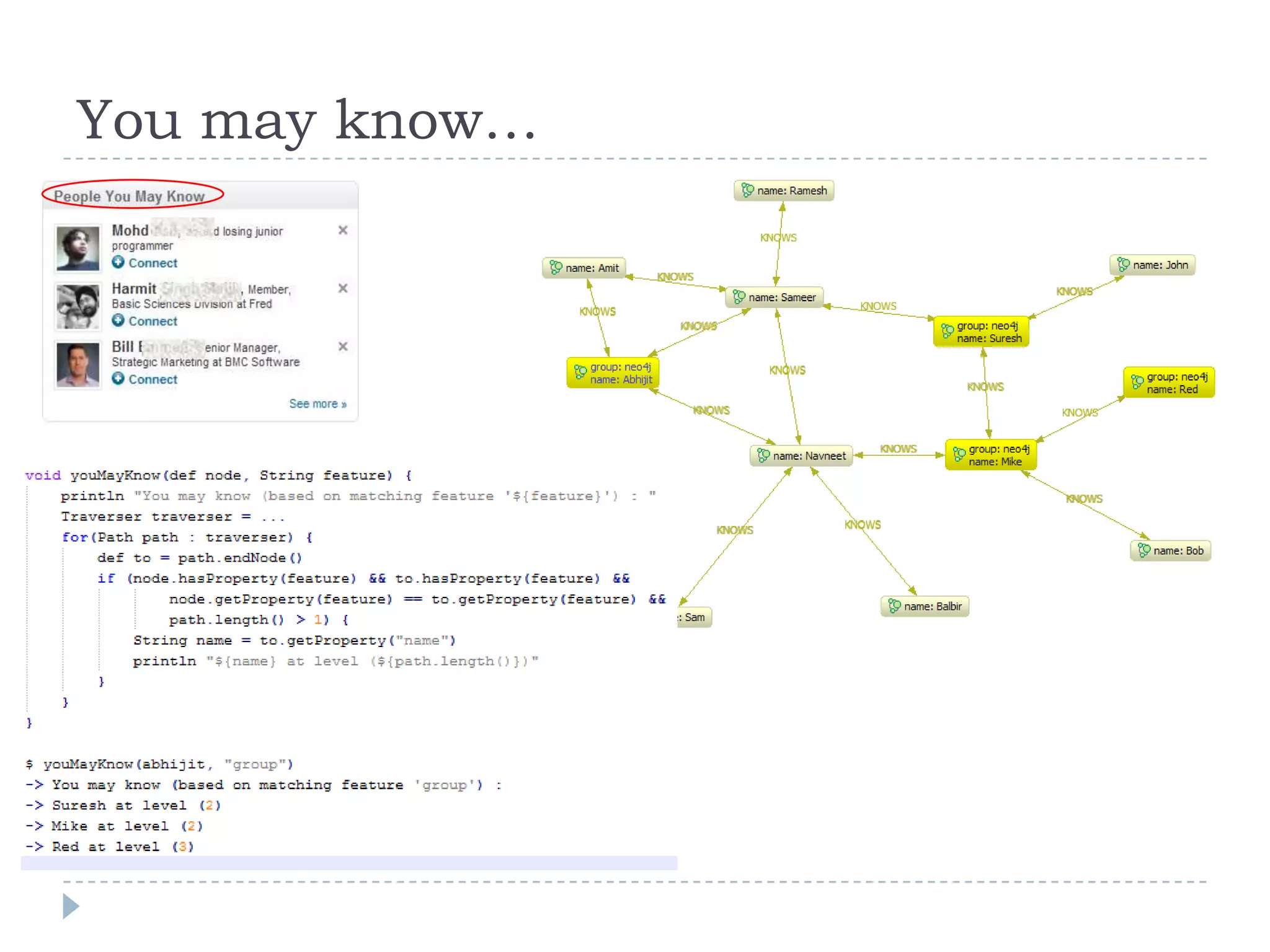






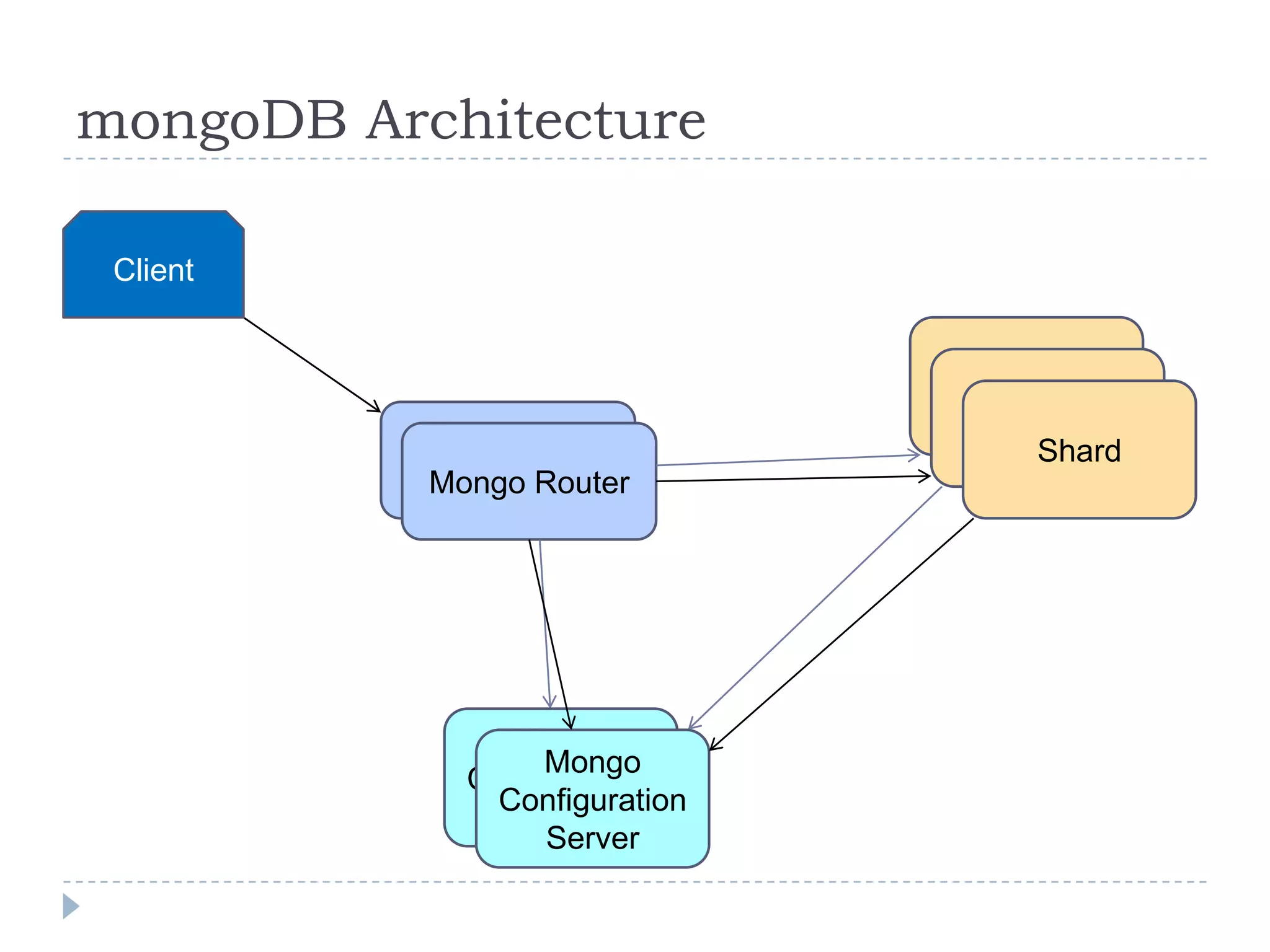





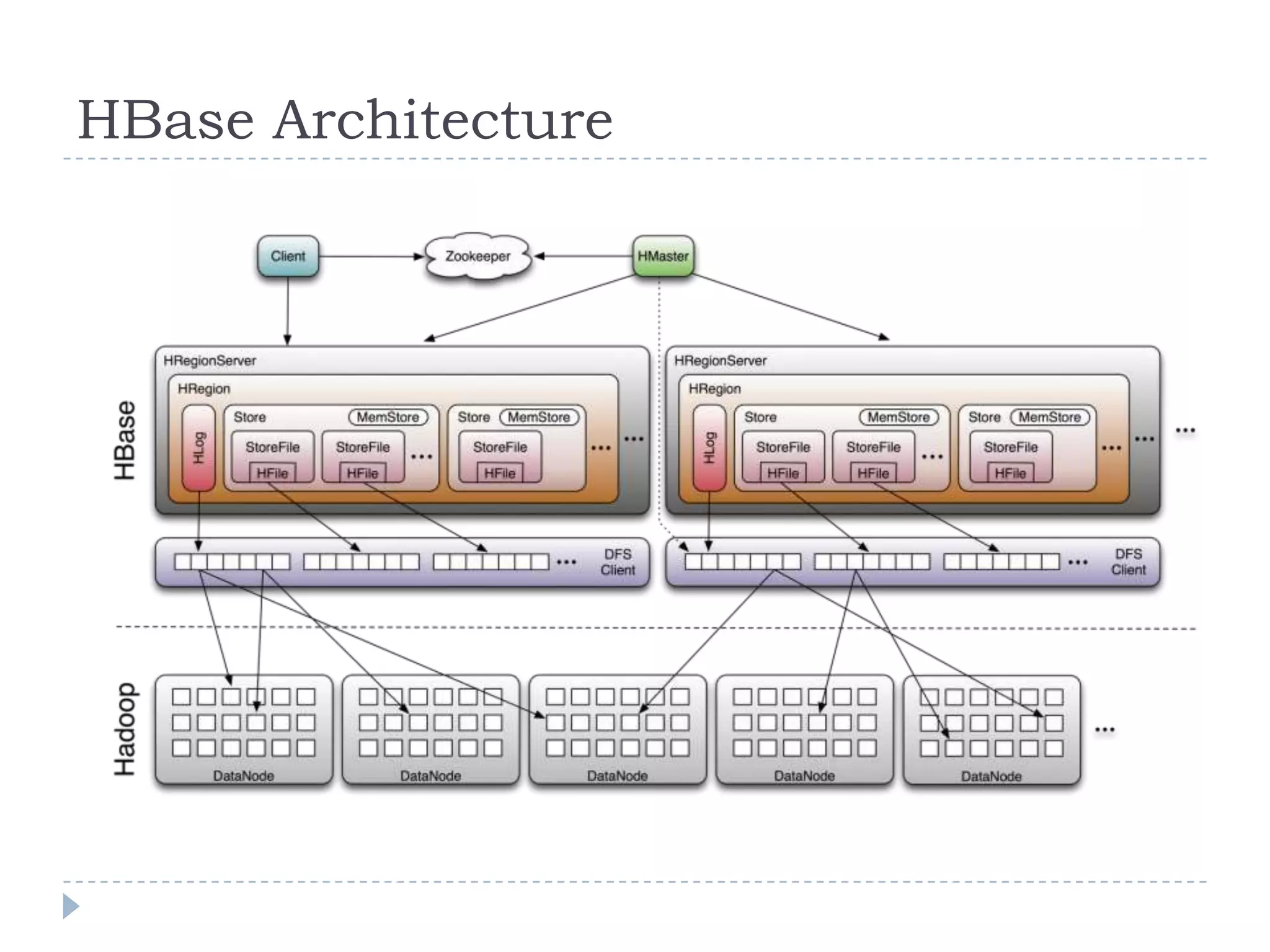






The document discusses trends in big data and the rising importance of NoSQL databases. It covers the growth in data sizes, connectedness of data, and performance needs of modern applications. Relational databases struggle with these trends. NoSQL databases provide alternatives with flexible data models, horizontal scalability, and availability over consistency. The document categorizes NoSQL databases as graph databases, document databases, column stores, and key-value stores, providing examples and use cases for each type.
































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)














![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)
