Download as PDF, PPTX





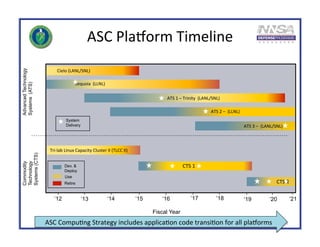


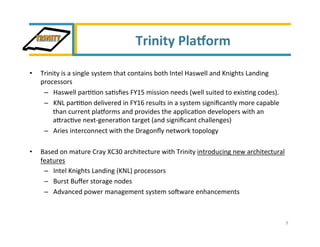

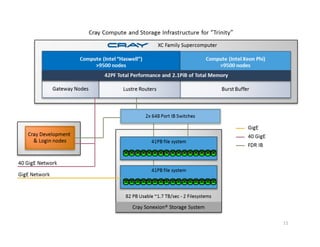
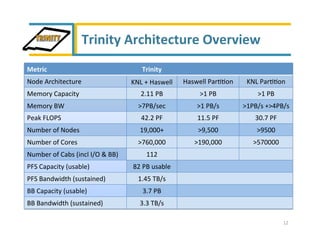
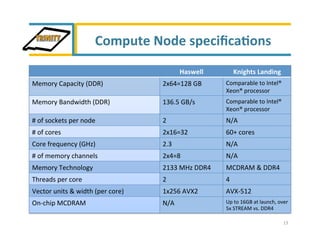









Trinity is an advanced technology supercomputer system for the ASC Program that will be located at Los Alamos National Laboratory. It is designed to support the largest and most demanding applications of the ASC Program. Trinity will have a peak performance of over 42 petaflops and will introduce new technologies like the Intel Knights Landing processor, burst buffer storage, and advanced power management. The system is scheduled to be delivered in September 2015 and will help the ASC Program prepare for future exascale systems.



































































