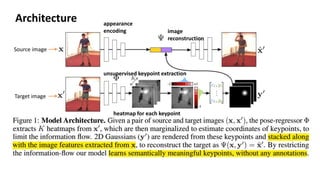
This document summarizes an unsupervised learning method for extracting object landmarks from images without manual annotations. The method uses a generator network that takes an input image and learns to generate a target image conditioned on extracted landmark heatmaps. It employs a perceptual loss between the generated and target images to train the landmark detection network in an unsupervised manner. The trained model is shown to learn semantically meaningful landmarks for faces, human bodies, and 3D objects from different datasets in an unsupervised way, demonstrating the ability to disentangle object appearance from geometry.






































![Objects as points (CenterNet) review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/objectsaspointscenternetreviewcdm-200327113331-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[NS][Lab_Seminar_241118]Relation Matters: Foreground-aware Graph-based Relati...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar241118fgrr-241118111529-1ff1aba4-thumbnail.jpg?width=640&height=640&fit=bounds)






































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)





