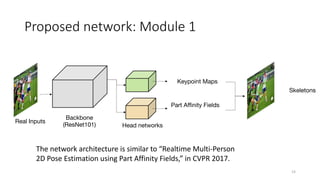
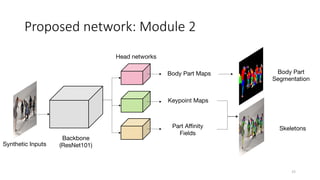
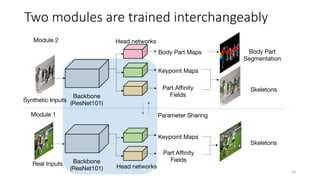
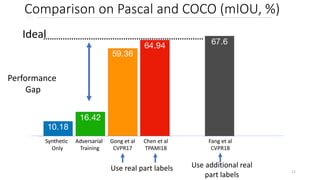
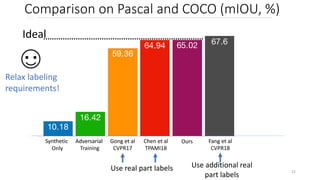
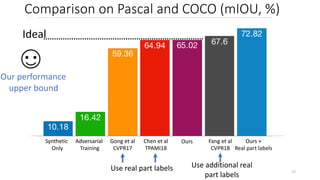
This document proposes a cross-domain complementary learning method with synthetic data for multi-person part segmentation. The method trains two modules interchangeably: one on synthetic data to predict keypoints and part segmentation, and one on real data to predict keypoints. By sharing parameters between the modules and leveraging the common skeleton representation in both domains, the method is able to transfer knowledge between synthetic and real data to improve part segmentation performance without requiring real part labels. Experimental results show the method outperforms alternatives that only use synthetic or real data, demonstrating it can relax labeling requirements for multi-person part segmentation tasks.





![Previous works
• People have been exploring synthetic data as an alternative.
• They trained deep CNN using the synthetic data.
Samples of the synthetic training data and the synthetic labels [CVPR17]
5](https://image.slidesharecdn.com/kevinlin1206-191214232512/85/Cross-domain-complementary-learning-with-synthetic-data-for-multi-person-part-segmentation-5-320.jpg)


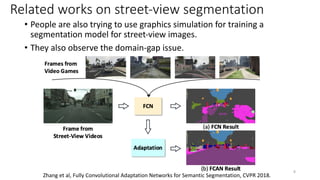
![Related works on street-view segmentation
• Previous studies tried to address the domain-gap issue by using
adversarial training.
• They use a discriminator to distinguish whether the input is from the
source or target domain.
[Tsai et al, ICCV2019], [Tsai et al, CVPR 2018], [Ren et al, CVPR2018], [Tzeng et al, CVPR2017], [Ganin et al, ICML2015]
Graphics simulation
Real-world images
9](https://image.slidesharecdn.com/kevinlin1206-191214232512/85/Cross-domain-complementary-learning-with-synthetic-data-for-multi-person-part-segmentation-9-320.jpg)




![Qualitative comparison
Training with Synthetic Data Only
[CVPR17]
Ours
24](https://image.slidesharecdn.com/kevinlin1206-191214232512/85/Cross-domain-complementary-learning-with-synthetic-data-for-multi-person-part-segmentation-24-320.jpg)
![Qualitative comparison
Domain Adaptation with
Adversarial Training
[CVPR18]
Ours
25](https://image.slidesharecdn.com/kevinlin1206-191214232512/85/Cross-domain-complementary-learning-with-synthetic-data-for-multi-person-part-segmentation-25-320.jpg)


![Qualitative comparison
[1] Learning from Synthetic Humans, CVPR17.
28](https://image.slidesharecdn.com/kevinlin1206-191214232512/85/Cross-domain-complementary-learning-with-synthetic-data-for-multi-person-part-segmentation-28-320.jpg)
![Qualitative comparison
[1] Learning from Synthetic Humans, CVPR17.
29](https://image.slidesharecdn.com/kevinlin1206-191214232512/85/Cross-domain-complementary-learning-with-synthetic-data-for-multi-person-part-segmentation-29-320.jpg)








































![[Mmlab seminar 2016] deep learning for human pose estimation](https://cdn.slidesharecdn.com/ss_thumbnails/mucdgsomrcs8cgkh9gsp-signature-54f17826ed7e29e13653ed835b10fabd79d8e26ac84412798c7e96ef7d109006-poli-160811023645-thumbnail.jpg?width=640&height=640&fit=bounds)












![[NS][Lab_Seminar_250106]SAM-Aware Graph Prompt Reasoning Network for Cross-Do...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar250106gprn-250106075150-b64c5cde-thumbnail.jpg?width=640&height=640&fit=bounds)







































