Downloaded 25 times









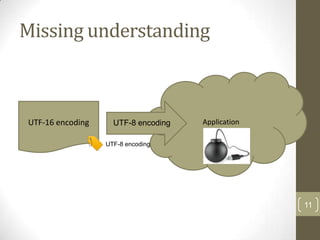



This document provides an overview of character encoding and introduces Unicode. It defines character encoding as a system that represents characters with codes and specifies how to store characters as byte sequences. The document explains that Unicode maps every known character to a number and can be encoded in different formats, such as UTF-8, UTF-16, and UTF-32. It also notes that a lack of understanding of encodings can cause problems for applications.









































































