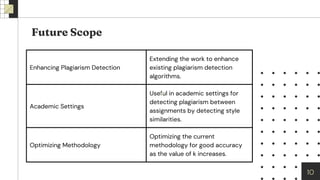
The document presents a methodology for analyzing writing styles using stylometric analysis, focusing on various clustering algorithms such as k-means and DBSCAN. It discusses the evaluation of linguistic and structural features, including lexical patterns, vocabulary richness, and readability scores, using silhouette scores for measuring cluster cohesion. The findings suggest that the optimized system effectively distinguishes between different writing styles and indicates opportunities for future research to enhance accuracy.