Downloaded 28 times




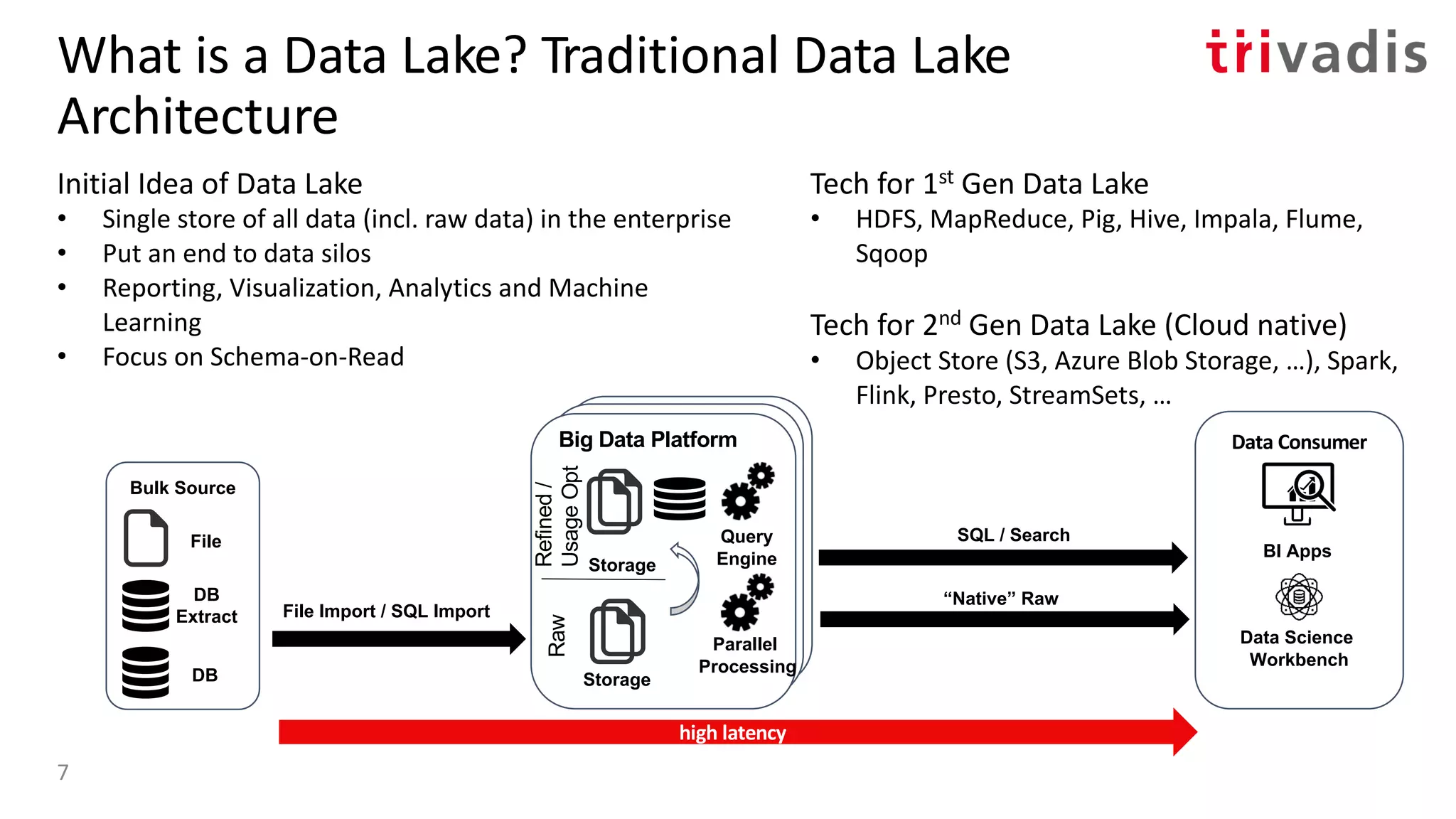
![”Streaming Data Lake” – aka. Kappa Architecture
Event
Stream
Stream Processing Platform
Stream Processor V1.0 State V1.0
Event Hub
Reply Bulk Data Flow
Hadoop ClusterdHadoop Cluster(Big) Data Platform
Storage
Storage
Raw
Refined/
UsageOpt
Bulk
Data Flow
Data
Consumer
BI Apps
Dashboard
Serving
Stream Processor V2.0 State V2.0
Result V1.0
Result V2.0
API
(Switcher)
{ }
Parallel
Processing
Query
Engine
SQL / Search
“Native” Raw
Data Science
Workbench
Result
Stream Source
of
Truth
11
Bulk Source
Event Source
Location
DB
Extract
File
Weather
DB
IoT
Data
Mobile
Apps
Social
Change
Data
Capture
Event
Stream
[8] – Questioning the Lambda Architecture – by Jay Kreps](https://image.slidesharecdn.com/s060guidoschmutzkafka-as-a-datalake-200910044735/75/Kafka-as-your-Data-Lake-is-it-Feasible-Guido-Schmutz-Trivadis-Kafka-Summit-2020-7-2048.jpg)
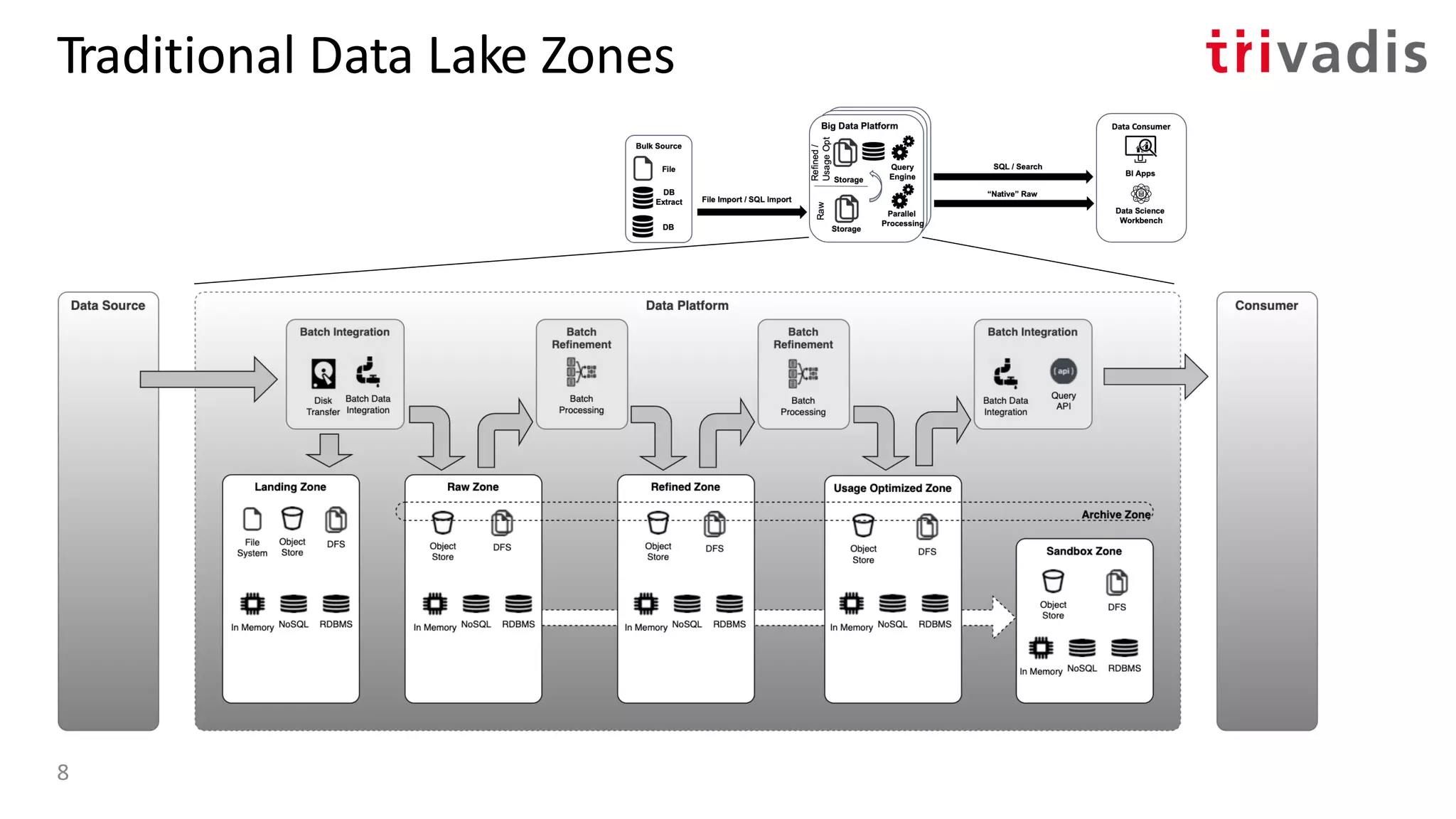
![Bulk
Data Flow
Result
Stream
SQL / Search
“Native” Raw
Event
Stream
Stream Processing Platform
Stream Processor V1.0 State V1.0
Event Hub
Hadoop ClusterdHadoop Cluster(Big) Data Platform
Storage
Storage
Raw
Refined/
UsageOpt
Data
Consumer
BI Apps
Dashboard
Serving
Stream Processor V2.0 State V2.0
Result V1.0
Result V2.0
API
(Switcher)
{ }
Parallel
Processing
Query
Engine
Data Science
Workbench
Reply Bulk Data Flow
Source
of
Truth
[1] Turning the database inside out with Apache Samza – by Martin Kleppmann13
Bulk Source
Event Source
Location
DB
Extract
File
Weather
DB
IoT
Data
Mobile
Apps
Social
Change
Data
Capture
Event
Stream
Moving the Source of Truth to Event Hub
Turning the
database inside-out!](https://image.slidesharecdn.com/s060guidoschmutzkafka-as-a-datalake-200910044735/75/Kafka-as-your-Data-Lake-is-it-Feasible-Guido-Schmutz-Trivadis-Kafka-Summit-2020-9-2048.jpg)
![Bulk
Data Flow
Result
Stream
SQL / Search
“Native” Raw
Event
Stream
Stream Processing Platform
Stream Processor V1.0 State V1.0
Event Hub
Hadoop ClusterdHadoop Cluster(Big) Data Platform
Storage
Storage
Raw
Refined/
UsageOpt
Data
Consumer
BI Apps
Dashboard
Serving
Stream Processor V2.0 State V2.0
Result V1.0
Result V2.0
API
(Switcher)
{ }
Data Science
Workbench
Source
of
Truth
Moving the Source of Truth to Event Hub
[2] – It’s Okay To Store Data In Apache Kafka – by Jay Kreps14
Parallel
Processing
Query
Engine
Bulk Source
Event Source
Location
DB
Extract
File
Weather
DB
IoT
Data
Mobile
Apps
Social
Change
Data
Capture
Event
Stream
is it feasible?](https://image.slidesharecdn.com/s060guidoschmutzkafka-as-a-datalake-200910044735/75/Kafka-as-your-Data-Lake-is-it-Feasible-Guido-Schmutz-Trivadis-Kafka-Summit-2020-10-2048.jpg)
![Confluent Enterprise Tiered Storage
Data Retention
• Never
• Time (TTL) or Size-based
• Log-Compacted based
Tiered Storage uses two tiers of storage
• Local (same local disks on brokers)
• Remote (Object storage, currently AWS S3 only)
Enables Kafka to be a long-term storage
solution
• Transparent (no ETL pipelines needed)
• Cheaper storage for cold data
• Better scalability and less complex operations
Broker 1
Broker 2
Broker 3
Object
Storage
hot cold
[3] Infinite Storage in Confluent Platform – by Lucas Bradstreet, Dhruvil Shah, Manveer Chawla
[4] KIP-405: Kafka Tiered Storage – Kafka Improvement Proposal
15](https://image.slidesharecdn.com/s060guidoschmutzkafka-as-a-datalake-200910044735/75/Kafka-as-your-Data-Lake-is-it-Feasible-Guido-Schmutz-Trivadis-Kafka-Summit-2020-11-2048.jpg)


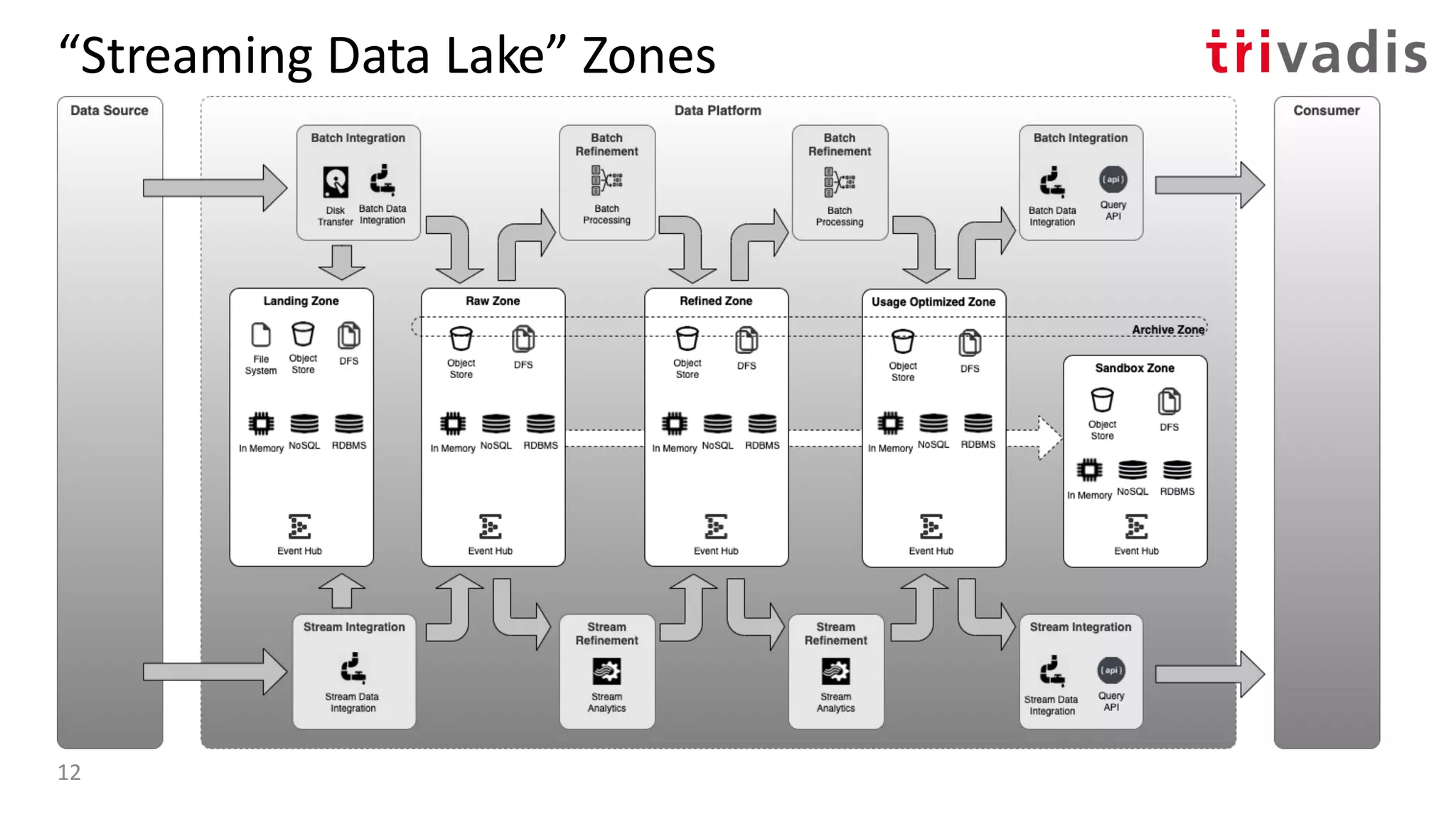
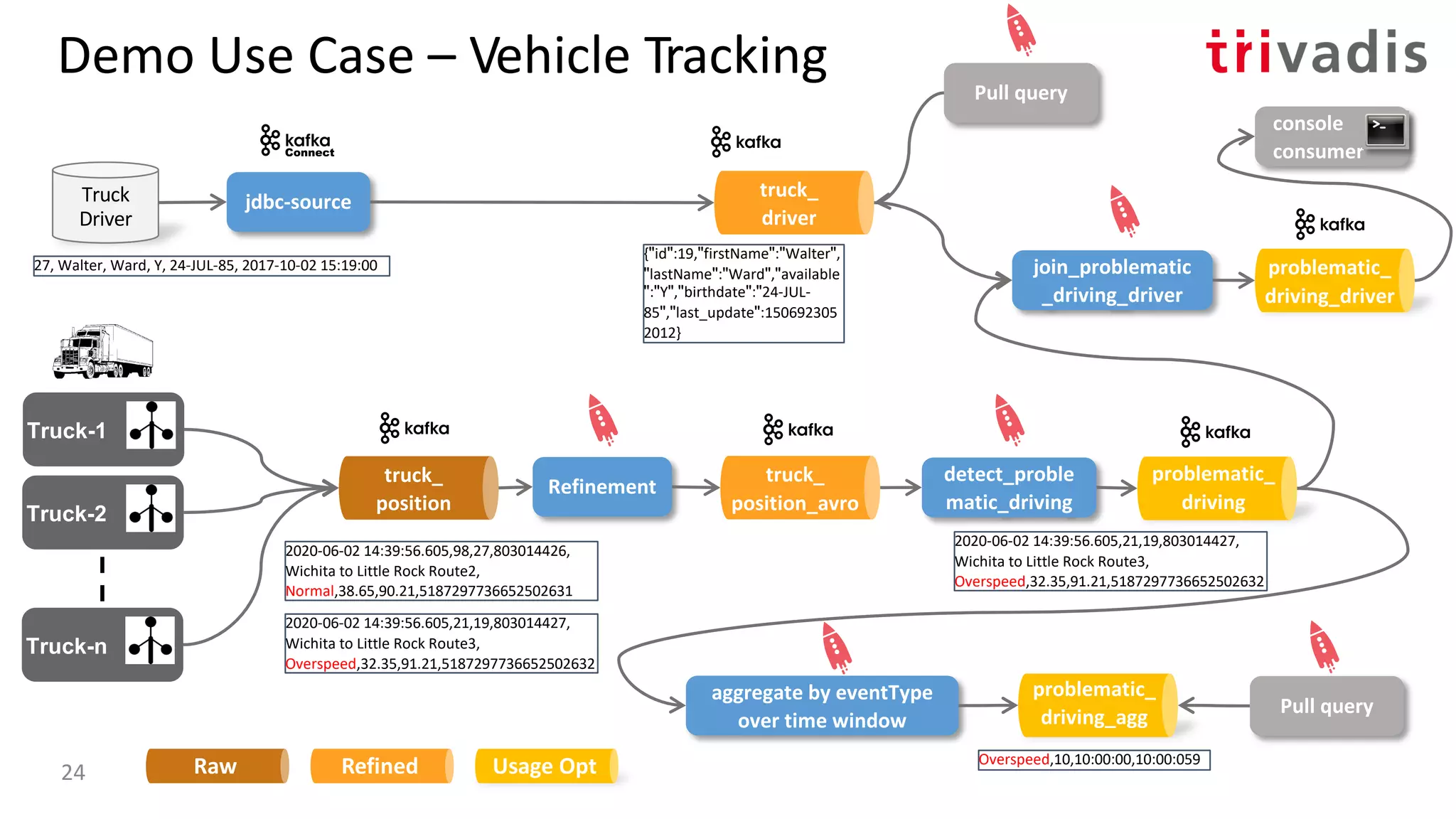
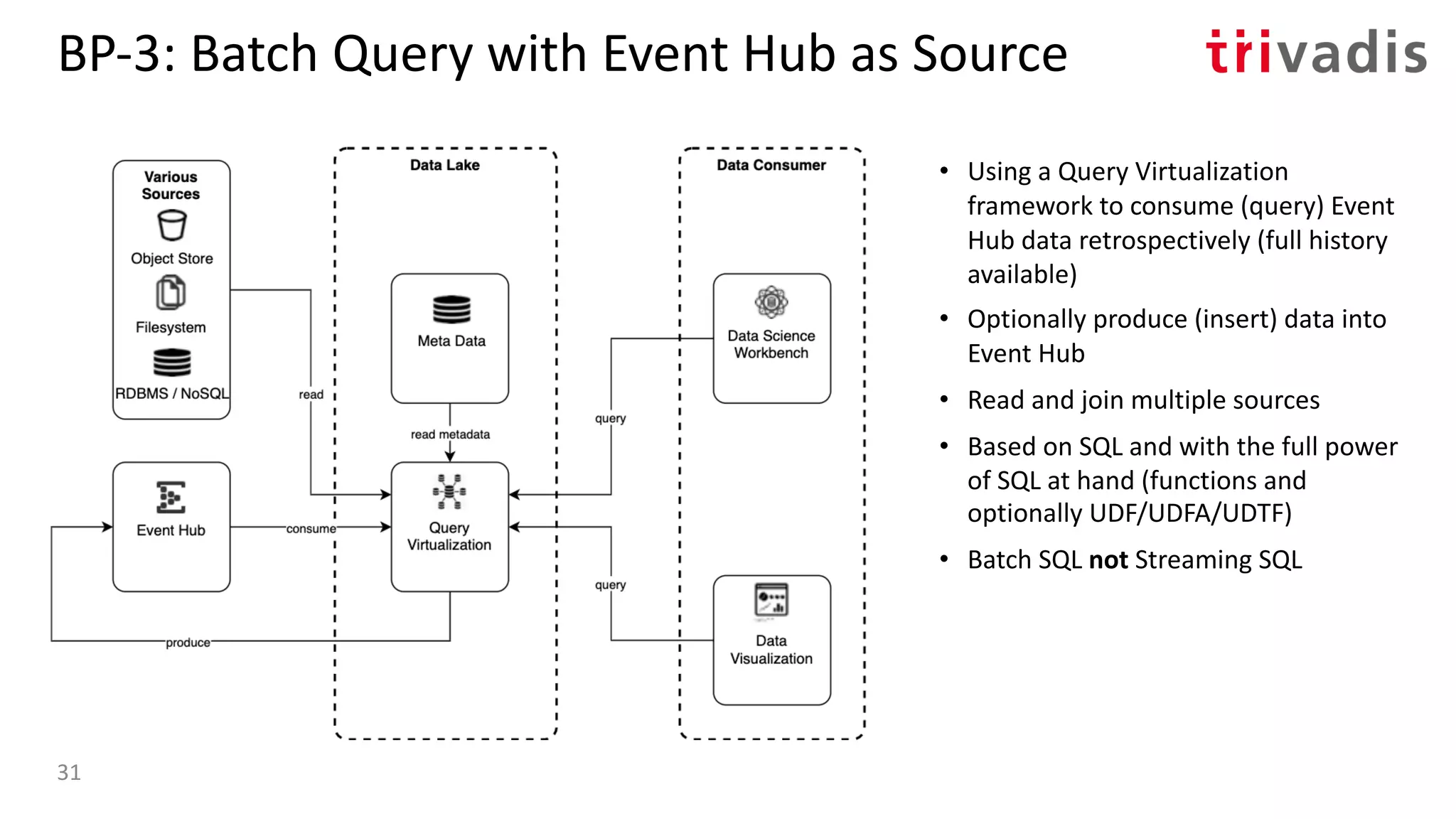
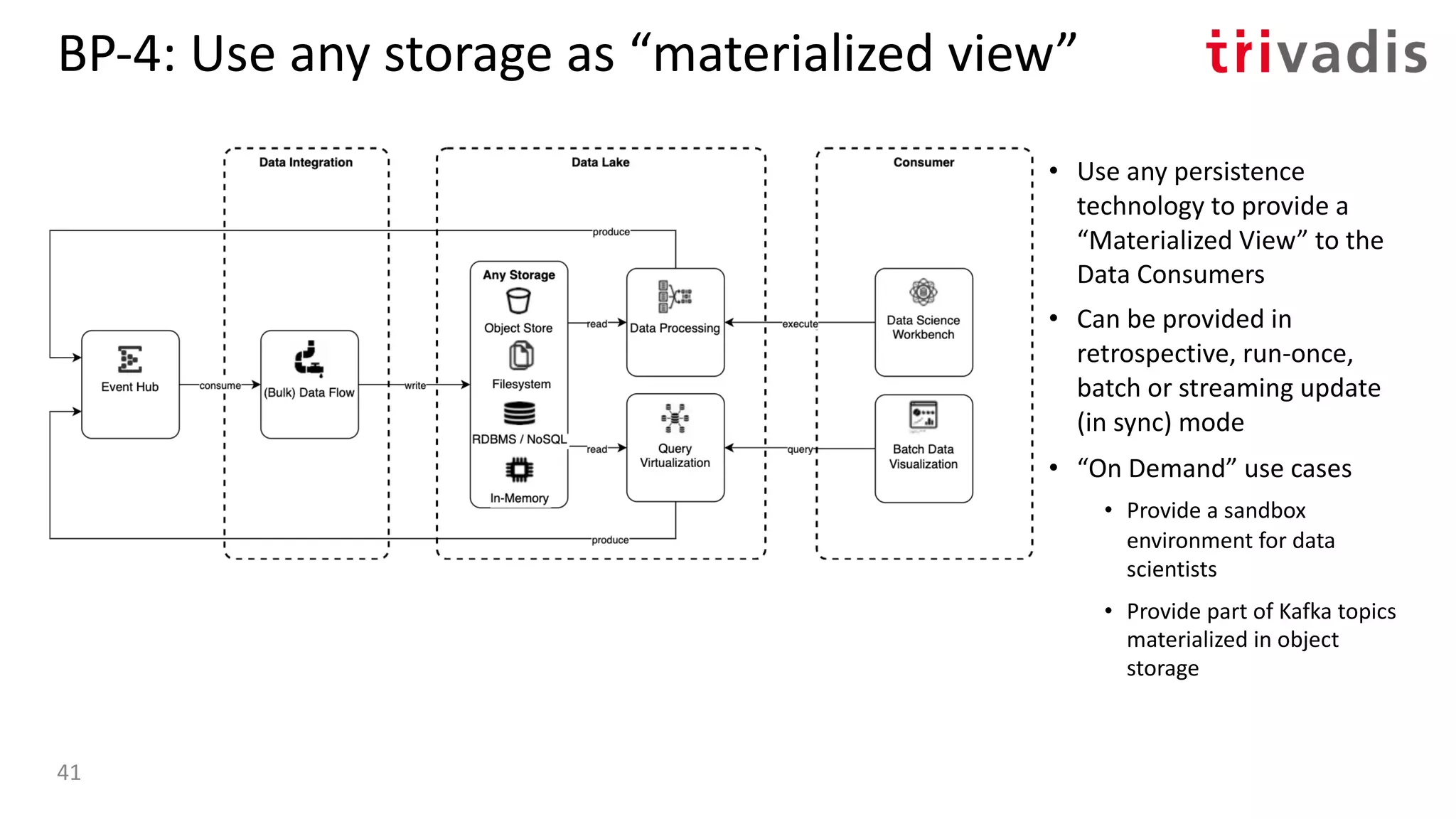
![BP-1: ”Streaming” Data Lake
• Using Stream Processing tools to
perform processing on ”data in
motion” instead of in batch
• Can consume from multiple sources
• Works well if no or limited history is
needed
• Queryable State Stores, aka.
Interactive Queries or Pull Queries
[5] Streaming Machine Learning with Tiered Storage and Without a Data Lake – by Kai Waehner22](https://image.slidesharecdn.com/s060guidoschmutzkafka-as-a-datalake-200910044735/75/Kafka-as-your-Data-Lake-is-it-Feasible-Guido-Schmutz-Trivadis-Kafka-Summit-2020-14-2048.jpg)
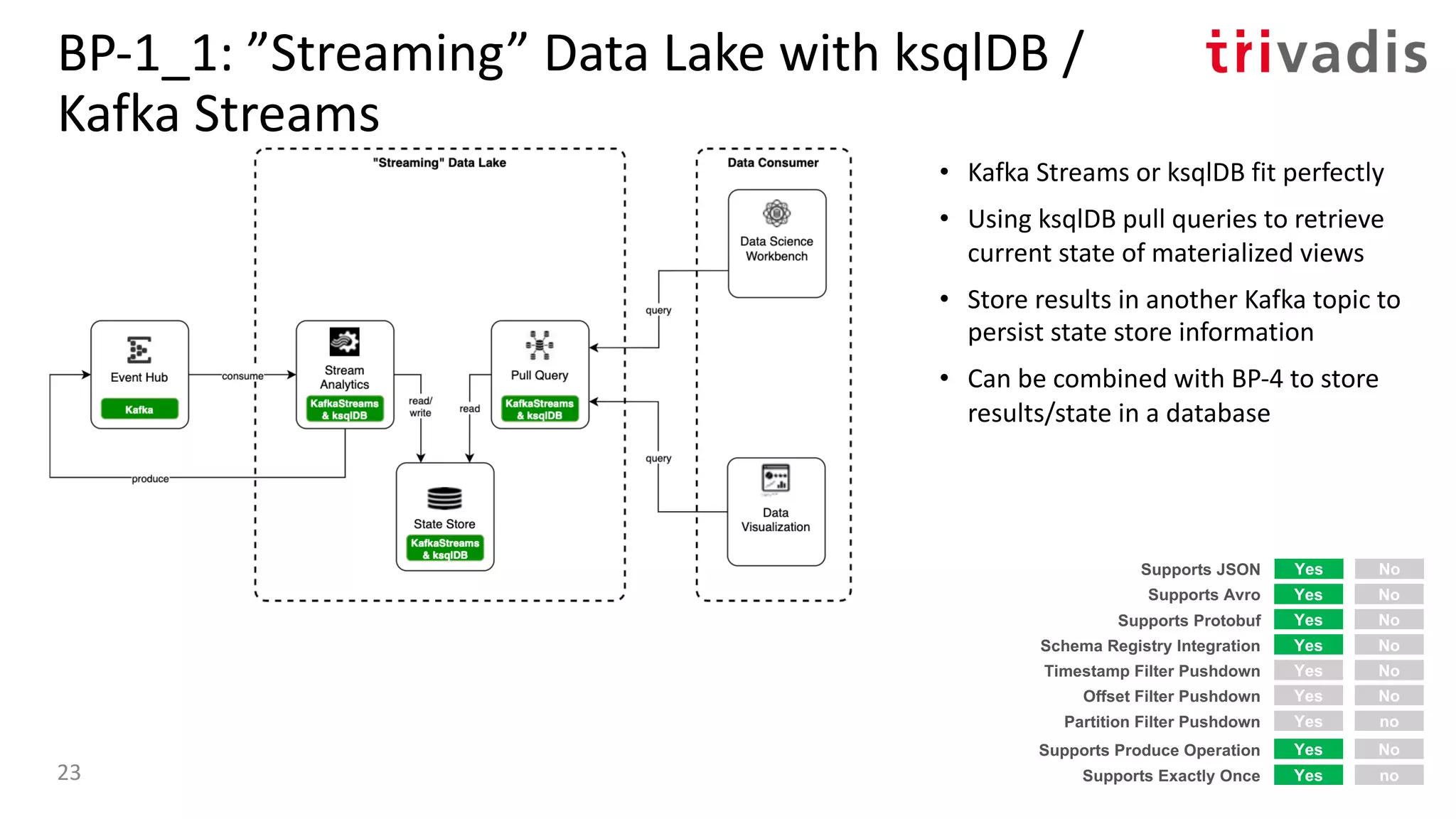

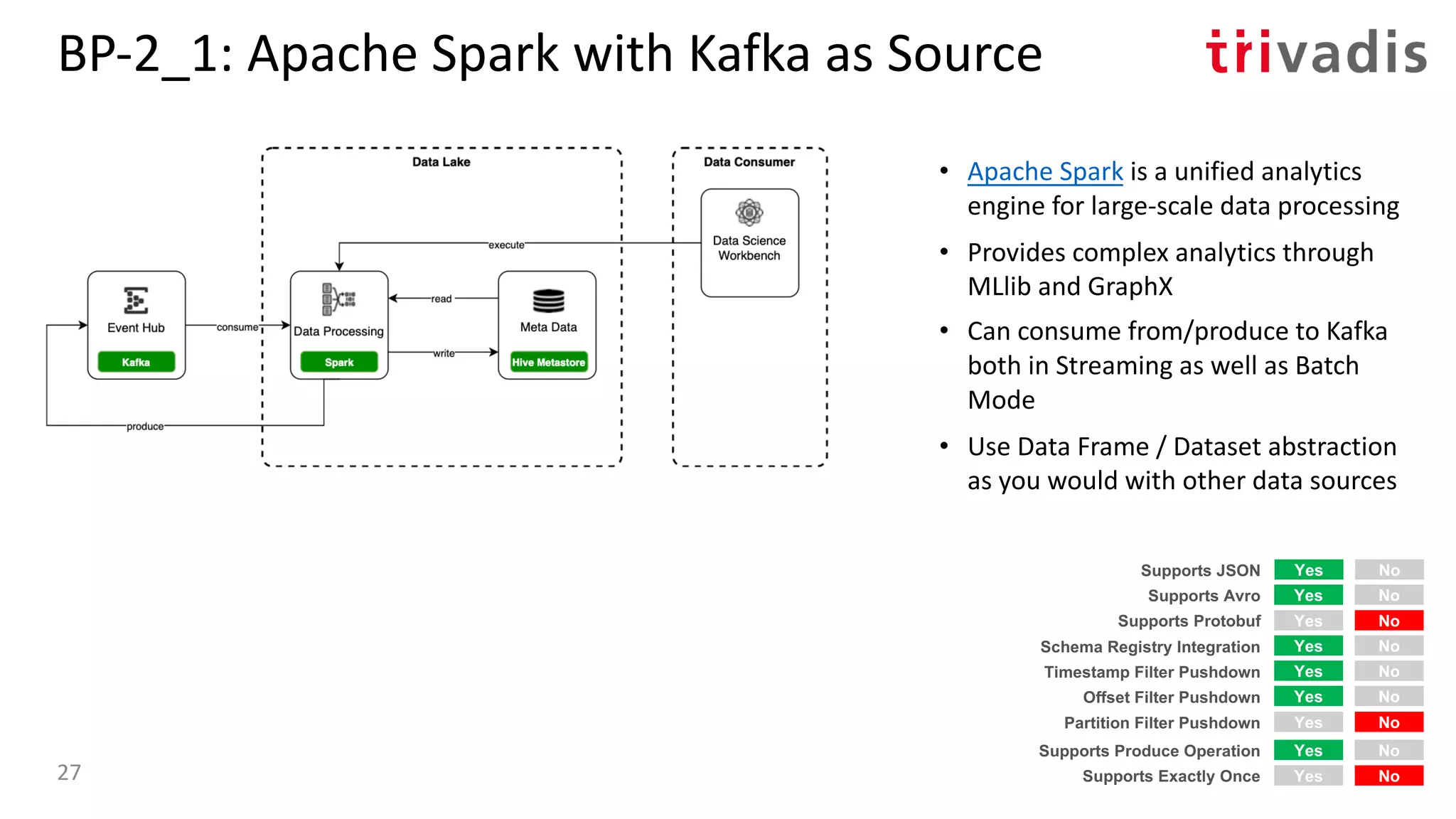

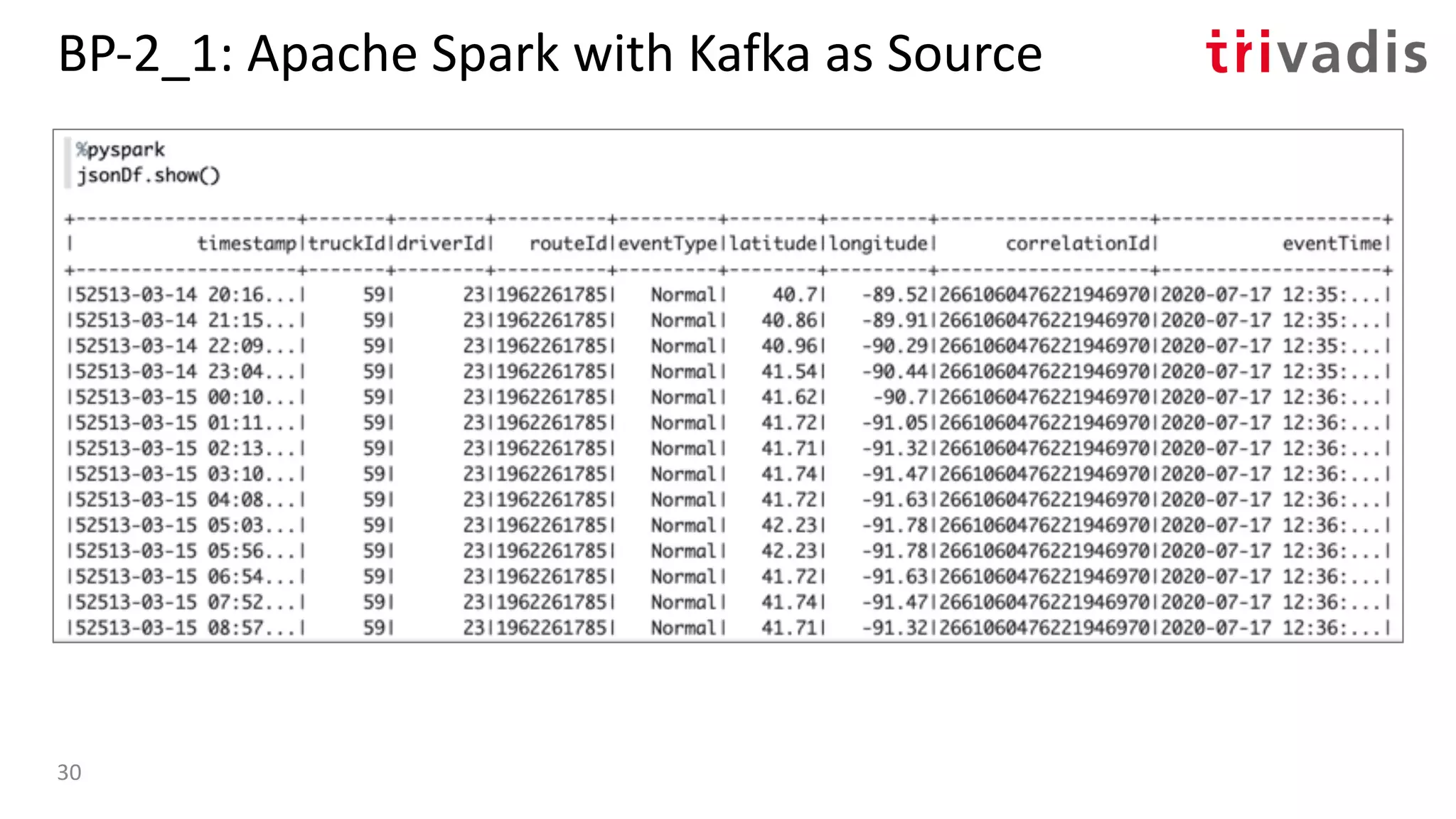
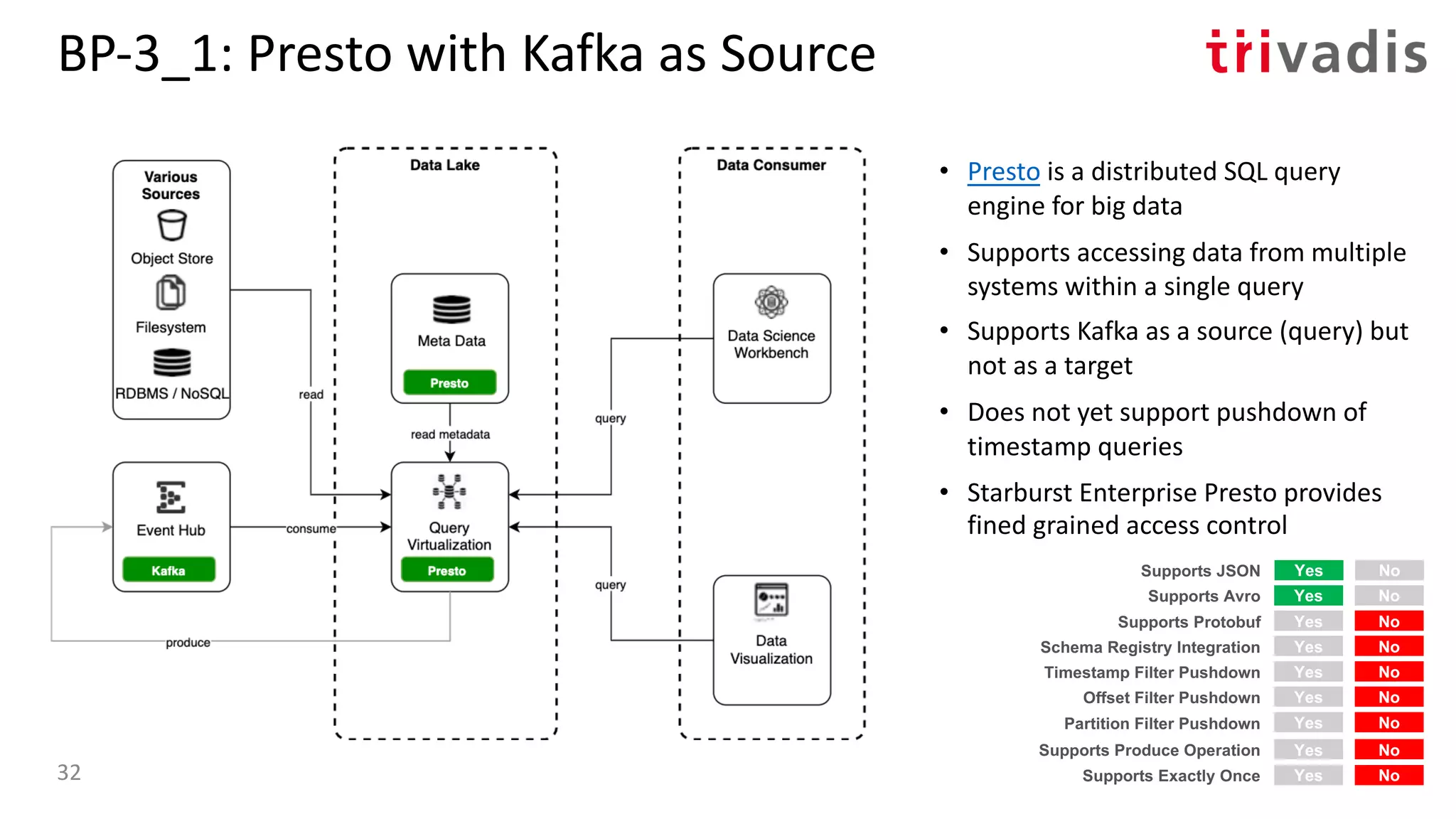
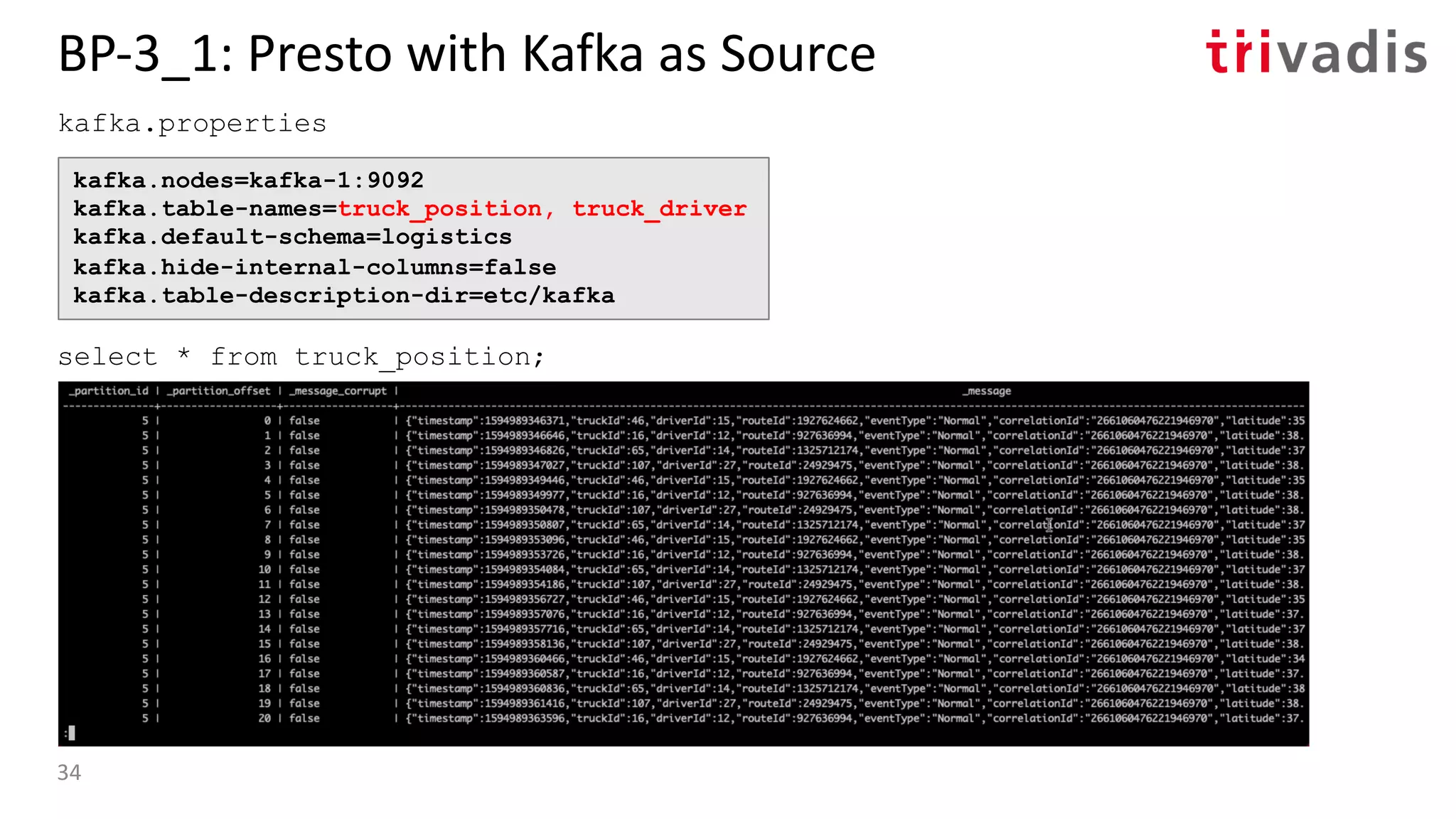
![BP-3_1: Presto with Kafka as Source
{
"tableName": "truck_position",
"schemaName": "logistics",
"topicName": "truck_position",
"key": {
"dataFormat": "raw",
"fields": [
{
"name": "kafka_key",
"dataFormat": "BYTE",
"type": "VARCHAR",
"hidden": "false"
}
]
},
"message": {
"dataFormat": "json",
"fields": [
{
"name": "timestamp",
"mapping": "timestamp",
"type": "BIGINT"
},
{
"name": "truck_id",
"mapping": "truckId",
"type": "BIGINT"
},
...
etc/kafka/truck_position.json etc/kafka/truck_driver.json
{
"tableName": "truck_position",
"schemaName": "logistics",
"topicName": "truck_position",
"key": {
"dataFormat": "raw",
"fields": [
{
"name": "kafka_key",
"dataFormat": "BYTE",
"type": "VARCHAR",
"hidden": "false"
}
]
},
"message": {
"dataFormat": "json",
"fields": [
{
"name": "timestamp",
"mapping": "timestamp",
"type": "BIGINT"
},
{
"name": "truck_id",
"mapping": "truckId",
"type": "BIGINT"
},
...
35](https://image.slidesharecdn.com/s060guidoschmutzkafka-as-a-datalake-200910044735/75/Kafka-as-your-Data-Lake-is-it-Feasible-Guido-Schmutz-Trivadis-Kafka-Summit-2020-27-2048.jpg)

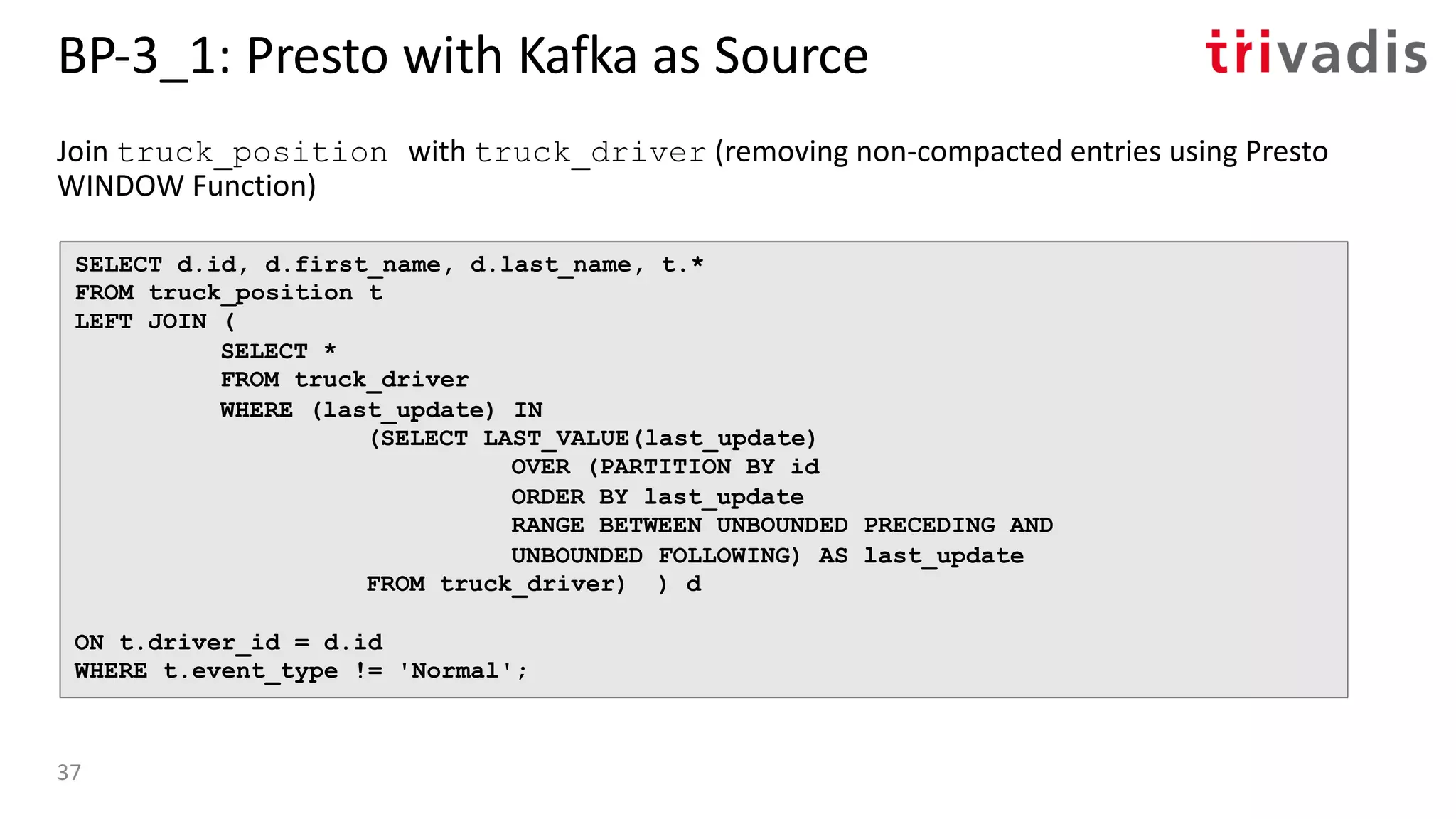
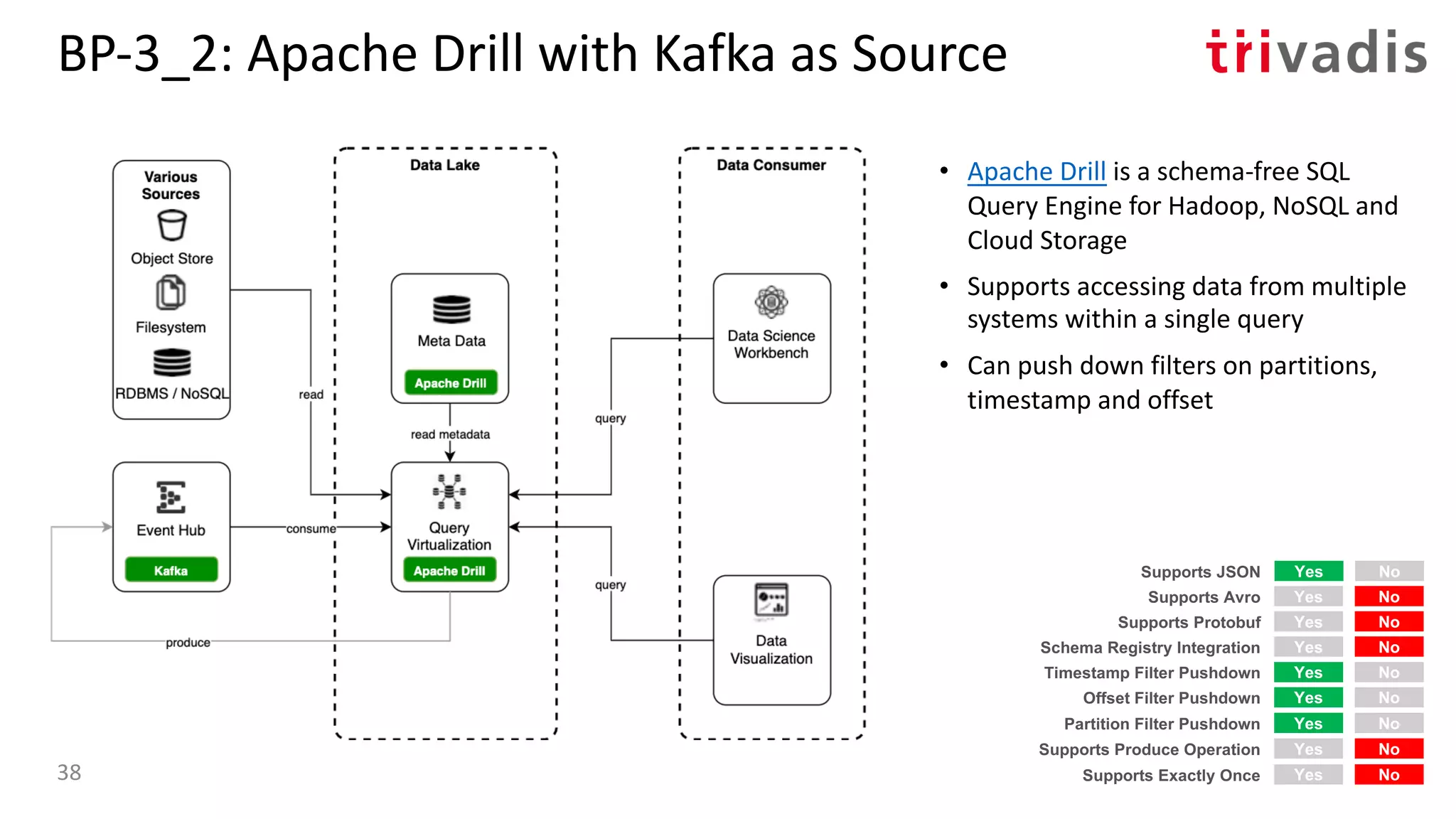
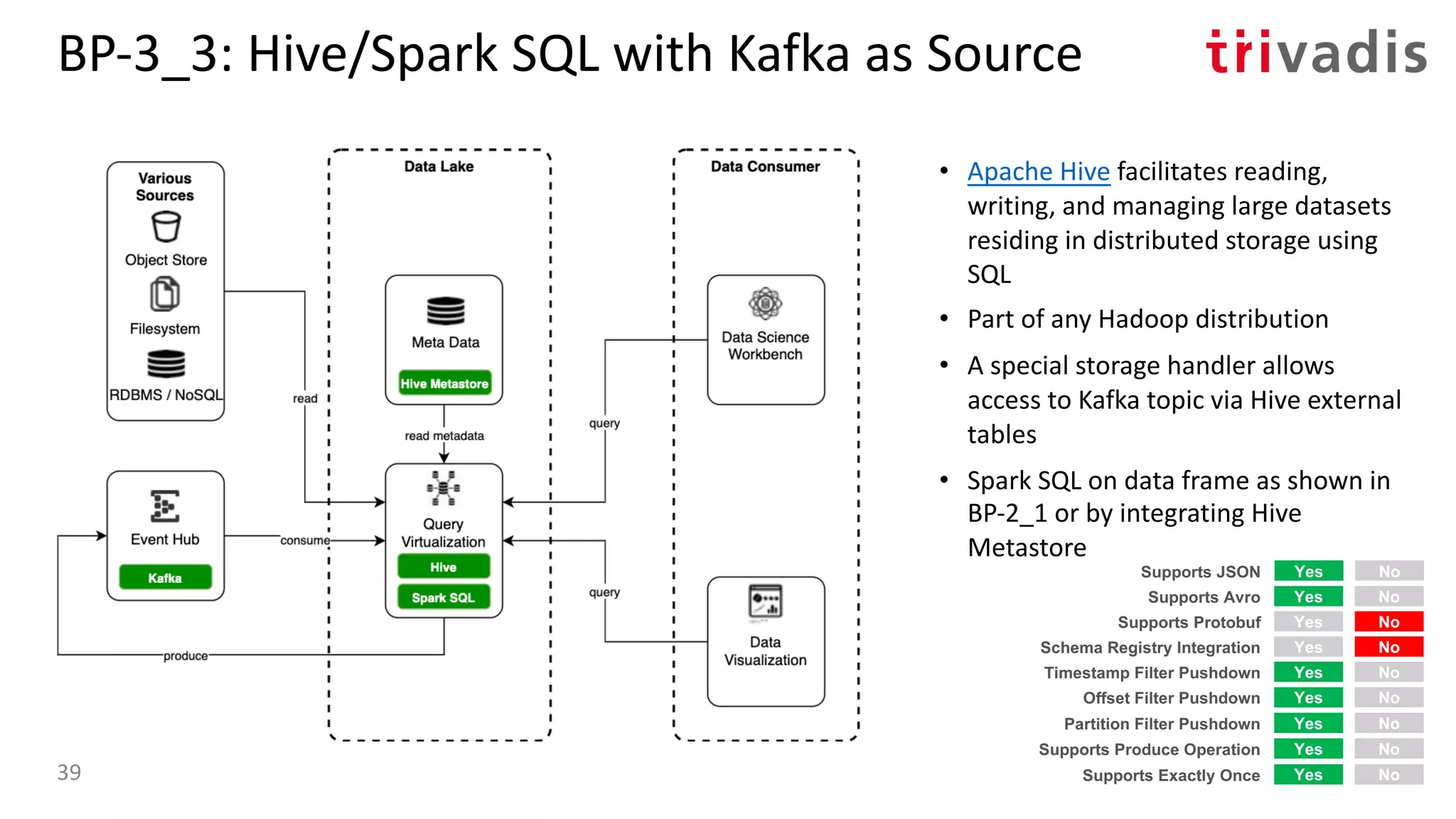
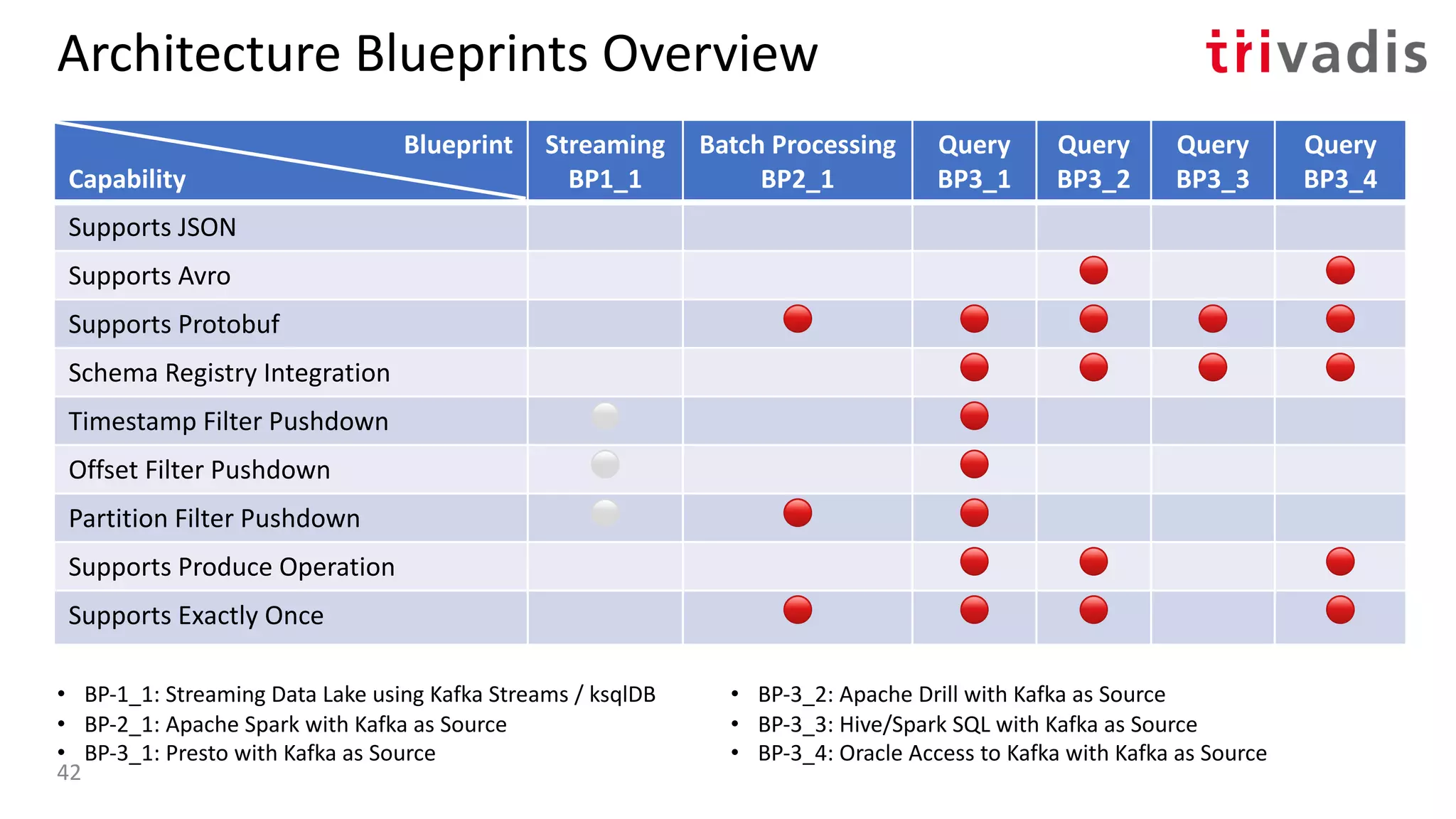
![BP-3_4: Oracle Access to Kafka with Kafka as
Source
• Oracle SQL Access to Kafka is a PL/SQL
package that enables Oracle SQL to
query Kafka topics via DB views and
underlying external tables [6]
• Runs in the Oracle database
• Supports Kafka as a source (query) but
not (yet) as a target
• Use Oracle SQL to access the Kafka
topics and optionally join to RDBMS
tables
Yes No
Yes No
Yes No
Supports Protobuf
Timestamp Filter Pushdown
Offset Filter Pushdown
Yes NoSupports Avro
Yes NoSupports JSON
Yes NoSchema Registry Integration
Yes NoPartition Filter Pushdown
Yes NoSupports Produce Operation
Yes NoSupports Exactly Once40](https://image.slidesharecdn.com/s060guidoschmutzkafka-as-a-datalake-200910044735/75/Kafka-as-your-Data-Lake-is-it-Feasible-Guido-Schmutz-Trivadis-Kafka-Summit-2020-32-2048.jpg)





The document discusses the feasibility of treating Kafka as a data lake, providing an overview of data lake architecture and the potential of Kafka in data storage and processing. It introduces various architecture blueprints for processing data streams and batch processes, highlighting Kafka's role as a centralized source of truth while integrating with other storage solutions. It also emphasizes the importance of moving analytics from batch to stream processing, supported by Confluent's tiered storage capabilities.


















































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)



