Downloaded 35 times











![Hashing
Key-value store
p-bit value i ∈ [0, 2p – 1]
Inner trunk hash table](https://image.slidesharecdn.com/trinity-130722055707-phpapp02/85/Trinity-A-Distributed-Graph-Engine-on-a-Memory-Cloud-14-320.jpg)
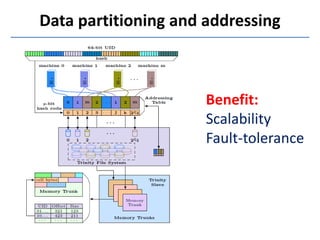








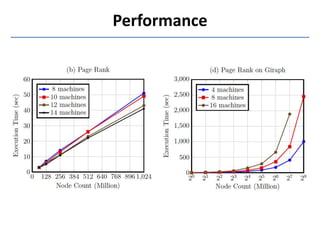
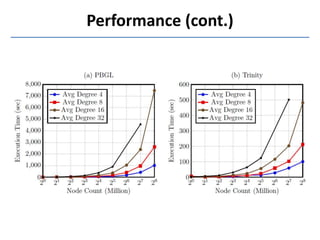

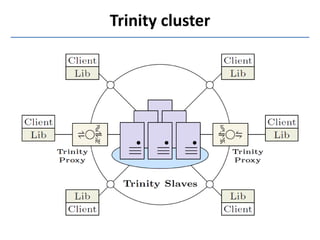
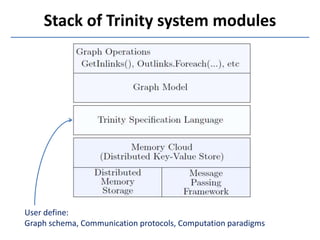
Trinity is a distributed graph engine that stores graphs entirely in memory across a cluster. It allows for both online query processing with low latency and offline graph analytics with high throughput. Trinity partitions graphs across memory trunks in its memory cloud for scalability, fault tolerance, and efficient random data access for online queries. It introduces new computation paradigms beyond traditional vertex-centric models to optimize offline analytics.























































