Downloaded 220 times















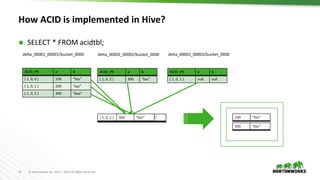

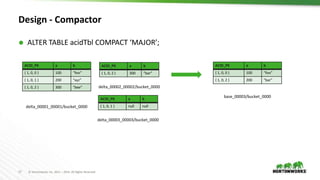





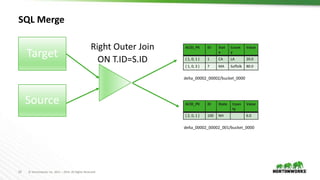


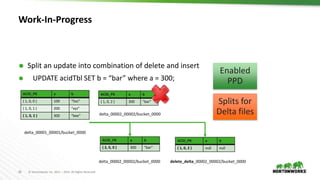

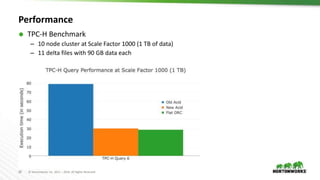





The document discusses the implementation of transactional operations in Apache Hive, emphasizing the use of ACID transactions to support insert, update, delete, and merge SQL operations. It describes the design, performance improvements, and roadmap for enhancing data management in Hive, including the introduction of a transaction manager, streaming ingest API, and compaction strategies to optimize data storage. The document also outlines user requirements and future enhancements, such as multi-statement transactions and better concurrency control.





















































































