How to correctly estimate the effect of online advertisement(About Double Machine Learning)
Double Machine Learning (Double ML) is a method for estimating treatment effects in high-dimensional data, such as online advertising data, that has many predictor variables. It involves using machine learning to first predict the outcome and treatment, and then regressing the treatment effect parameter on the residuals. This provides accurate estimates of treatment effects compared to methods like single equation regression. The document demonstrates Double ML through simulations using a large online advertising dataset, finding it outperforms other methods like naive averaging and standard lasso in estimating average treatment effects even in the presence of sampling bias.
How to correctly estimate the effect of online advertisement(About Double Machine Learning)
1.
How to correctlyestimate
the effect of online
advertisement
Introduction of Double Machine Lerning
2.
About me
● YusukeKaneko(@coldstart_p)
● CyberAgent, Inc.
● Studying: Econometrics, Causal Inference
3.
Main Theme
How toestimate correctly treatment effects in
high-dimensional data(such as advertising data)
4.
Original
1. Chernozhukov, Victor,et al. "Double/debiased/neyman machine learning of
treatment effects." American Economic Review 107.5 (2017): 261-65.
2. Belloni, A., Chernozhukov, V., Fernández‐Val, I., & Hansen, C. (2017).
Program evaluation and causal inference with high‐dimensional data.
Econometrica, 85(1), 233-298.
3. Chernozhukov, Victor, et al. "Double/debiased machine learning for treatment
and structural parameters." The Econometrics Journal 21.1 (2018): C1-C68.
5.
Problem
● Advertisement datahas a lot of variables. (= High-Dimensional Data)
example: Type of Advertisement , Time , History-data
→ Under such circumstances, it is known that low-dimensional parameters such
as treatment effects can not be estimated well by Machine Learning Methods
(The model and figure are on the slide later)
● Motivation: How to estimate treatment effects correctly ?
→ Use Double Machine Learning(Double ML) !
=( FLEXIBLE and SIMPLE Method)
● Double ML Code are on github(https://github.com/VC2015/DMLonGitHub/)
…(Double ML package does not exist yet. )
6.
Data
● Criteo UpliftModeling Dataset(EC Site AD Large Dataset for causal
inference)
Recently
Published
Dataset!
7.
Data
● Features areas follows
● Averege Visit Rate and Treatment Ratio
is on the right
8.
Model
● Partially LinearModel
Y: Outcome Variable(Whether user visited = visit)
D: Treatment Variable (Whether or not an ad has been delivered = treatment)
Z: Vector of covariates(such as history data = f0 f1 ...)
θ0: “lift” parameter(Treatment Effect parameter)
● D is expressed by the following equation
D is conditionally exogenous
9.
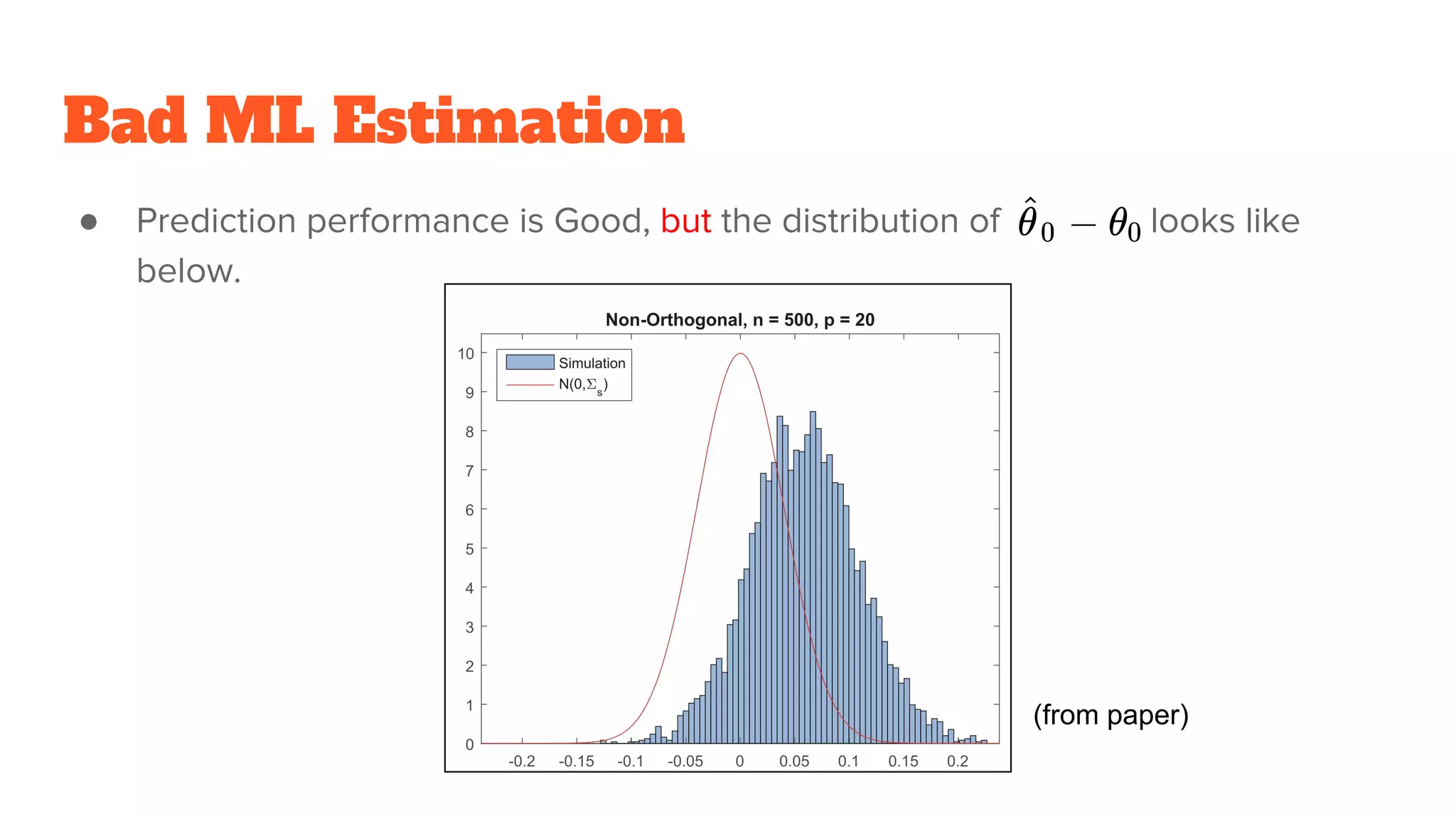
Bad ML Estimation
●Predict Y using D and Z, then obtain
(Example)
1. Run Random Forest and get
2. and get
3. Repeat 1. and 2. until convergence
10.
Bad ML Estimation
●Prediction performance is Good, but the distribution of looks like
below.
(from paper)
11.
Double ML
1. PredictY and D using Z by
obtained using ML methods(Lasso , Random Forest etc... )
2. Residualize
3. Regress and get
12.
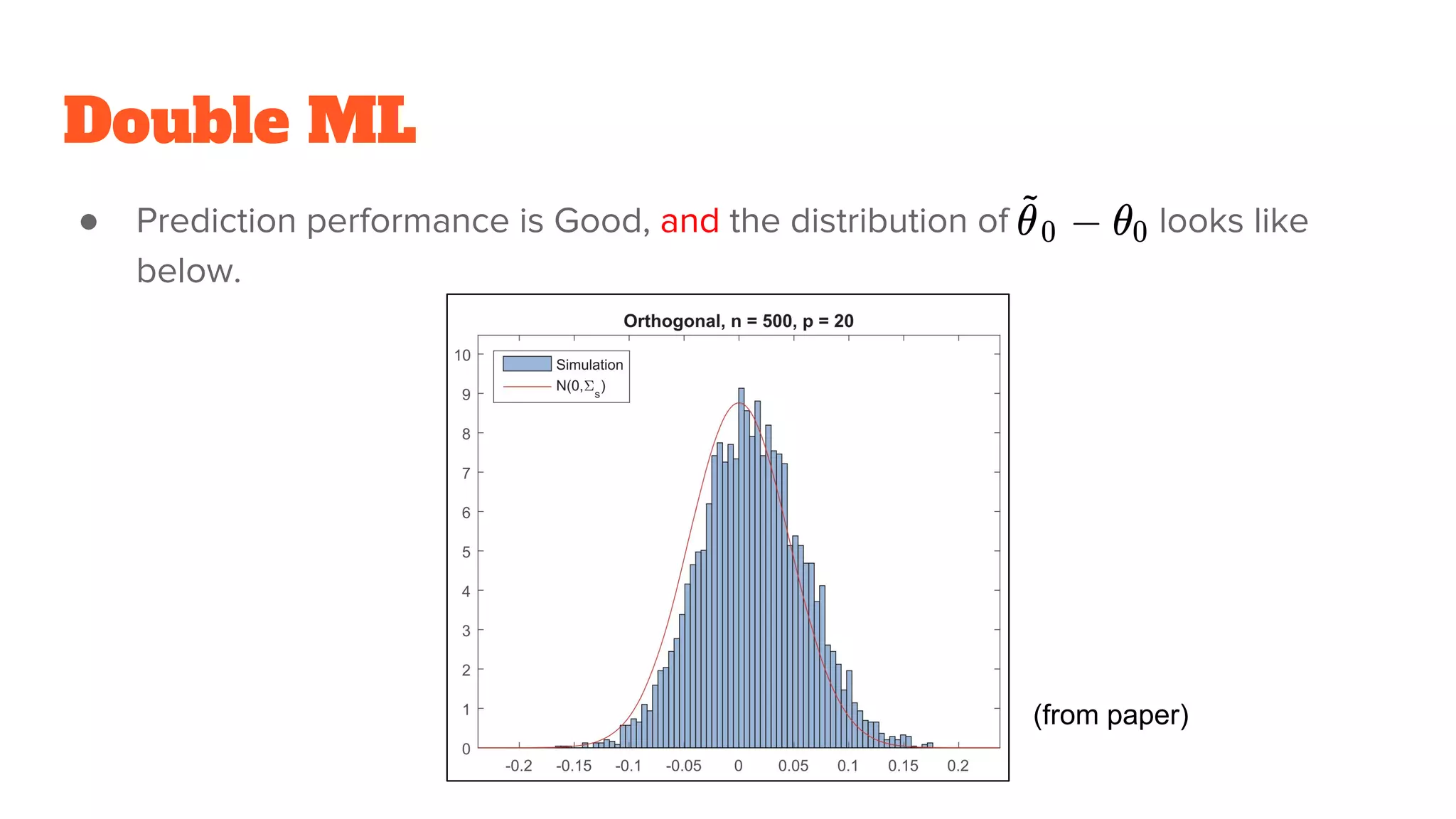
Double ML
● Predictionperformance is Good, and the distribution of looks like
below.
(from paper)
13.
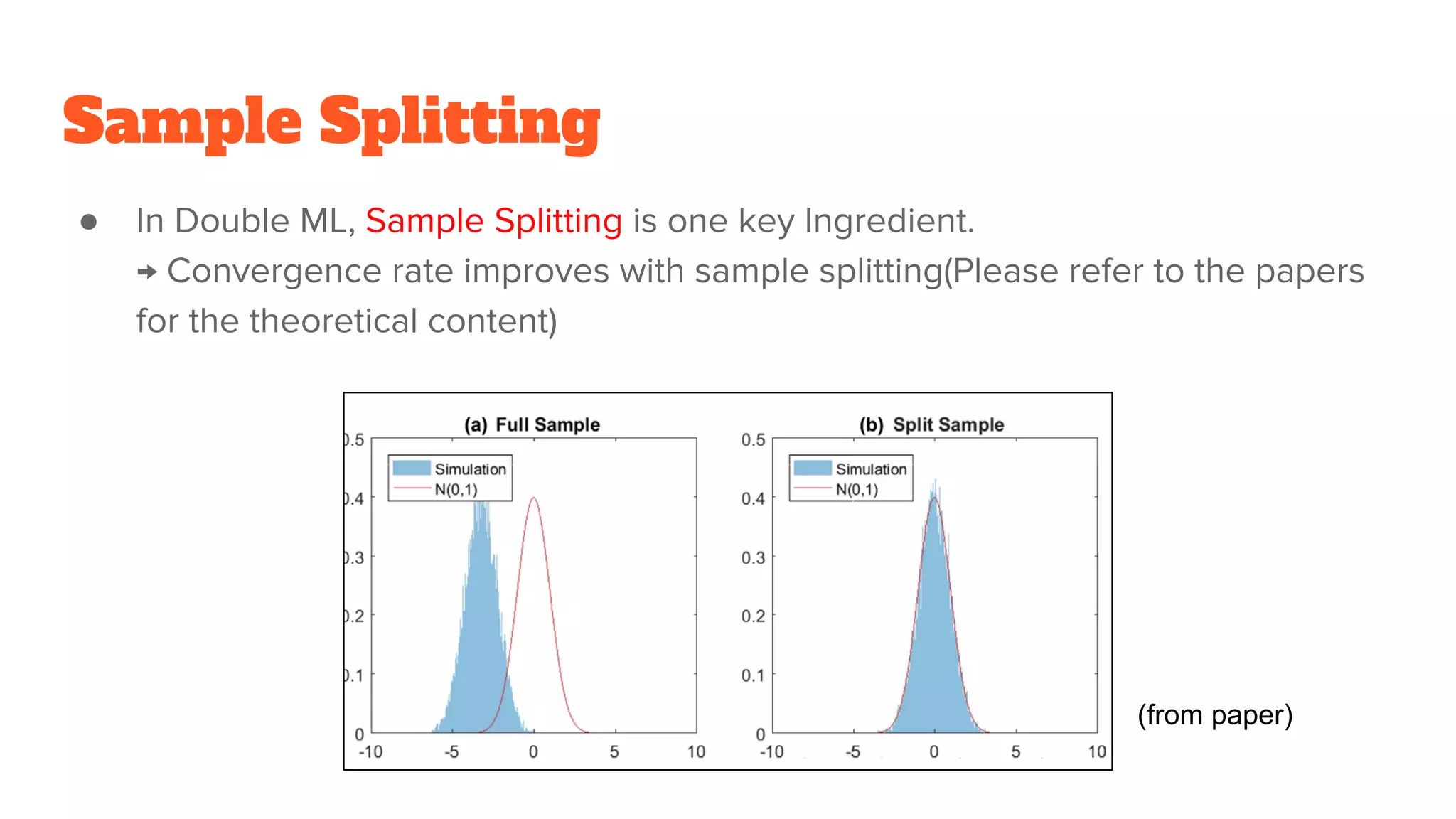
Sample Splitting
● InDouble ML, Sample Splitting is one key Ingredient.
→ Convergence rate improves with sample splitting(Please refer to the papers
for the theoretical content)
(from paper)
14.
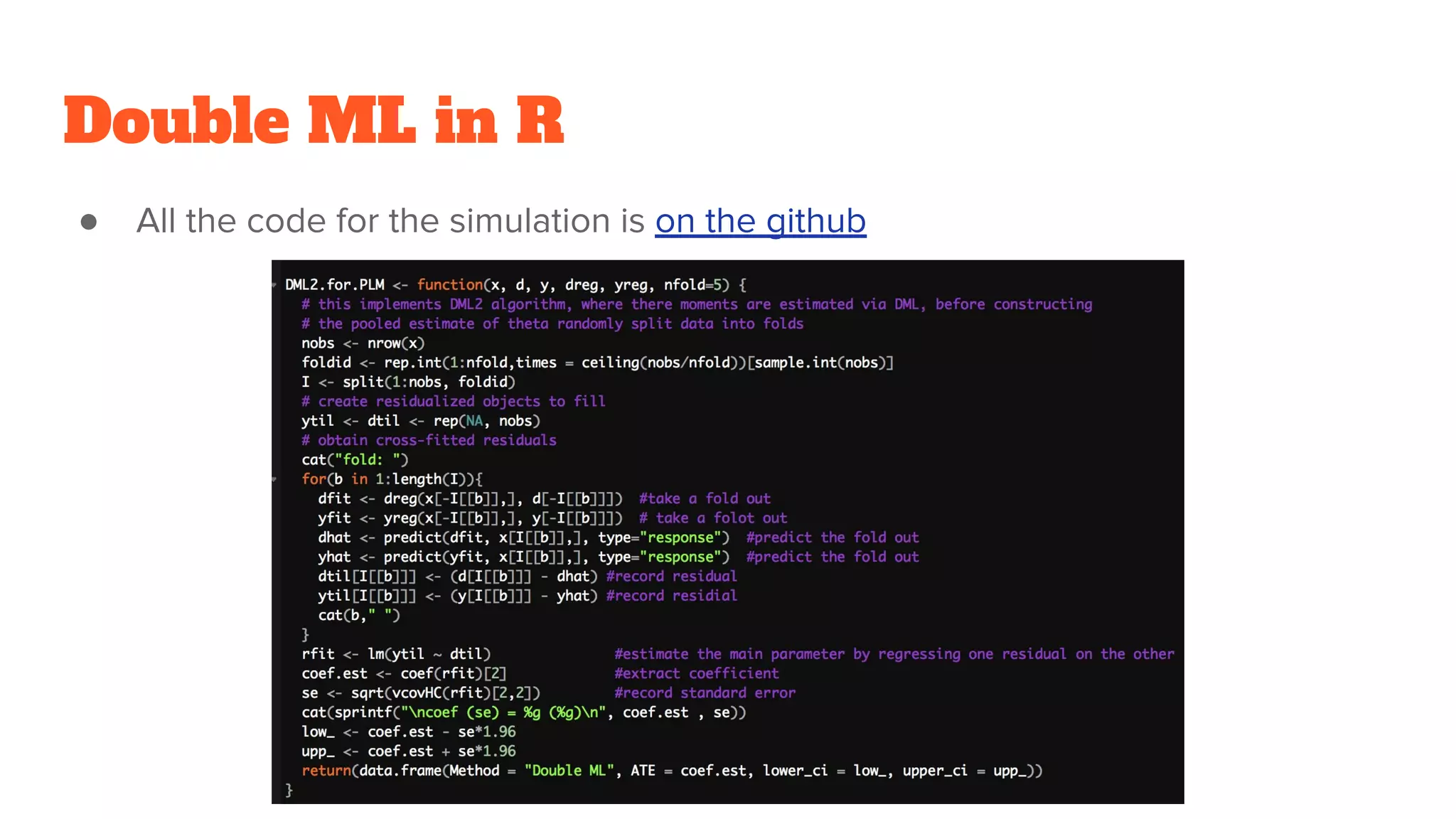
Double ML inR
● All the code for the simulation is on the github
15.
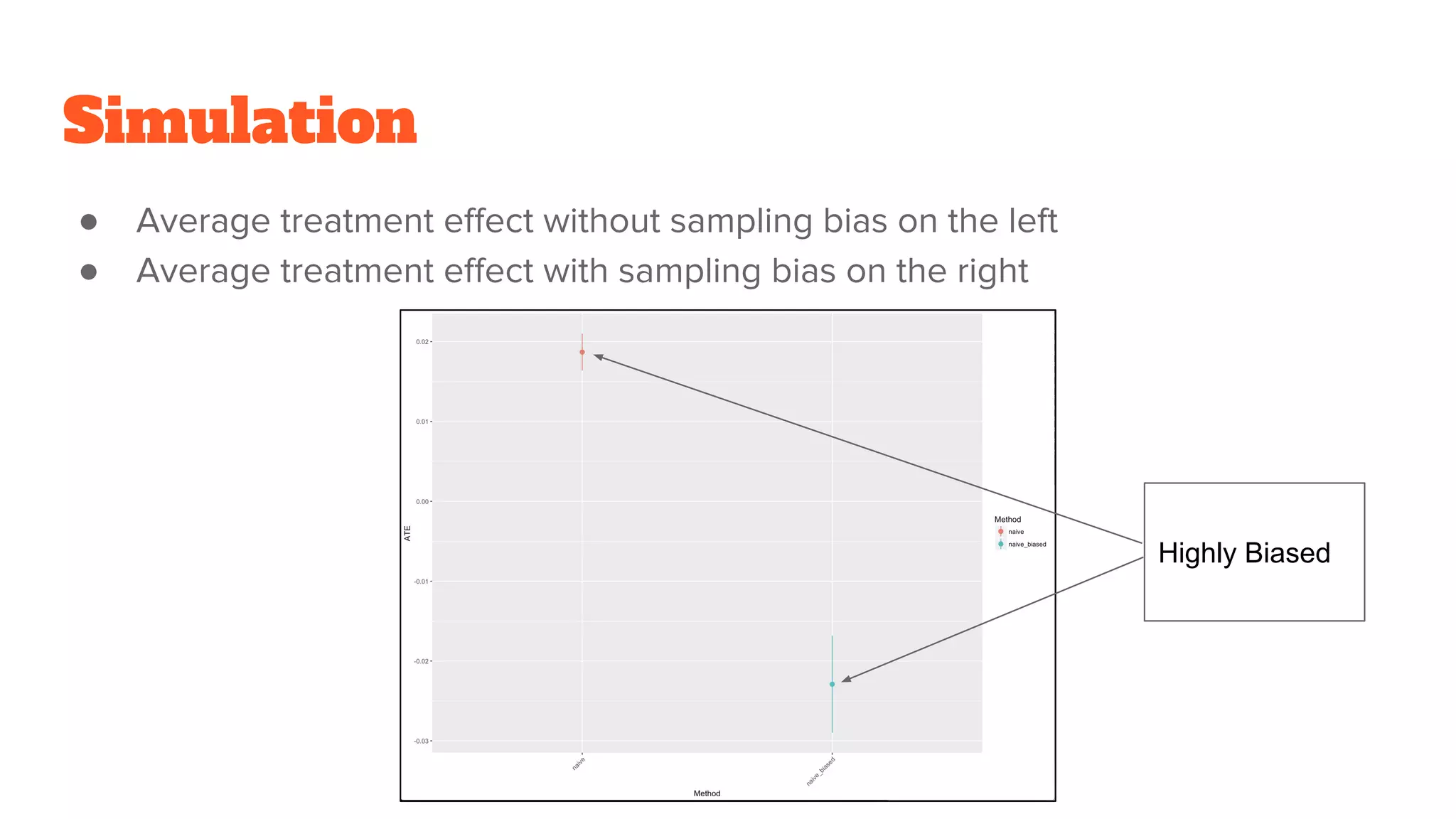
Simulation
● Since CriteoDataset is too large , I made overall sampling first (about 2%)
● Introduce Sampling Bias( Since we are using data coming from a randomized
experiment)
16.
Naive ATE Method
●Unbiased ATE(Average Treatment Effect) estimation is possible with this
technique if there is no sampling bias
17.
Simulation
● Average treatmenteffect without sampling bias on the left
● Average treatment effect with sampling bias on the right
Highly Biased
18.
Simulation
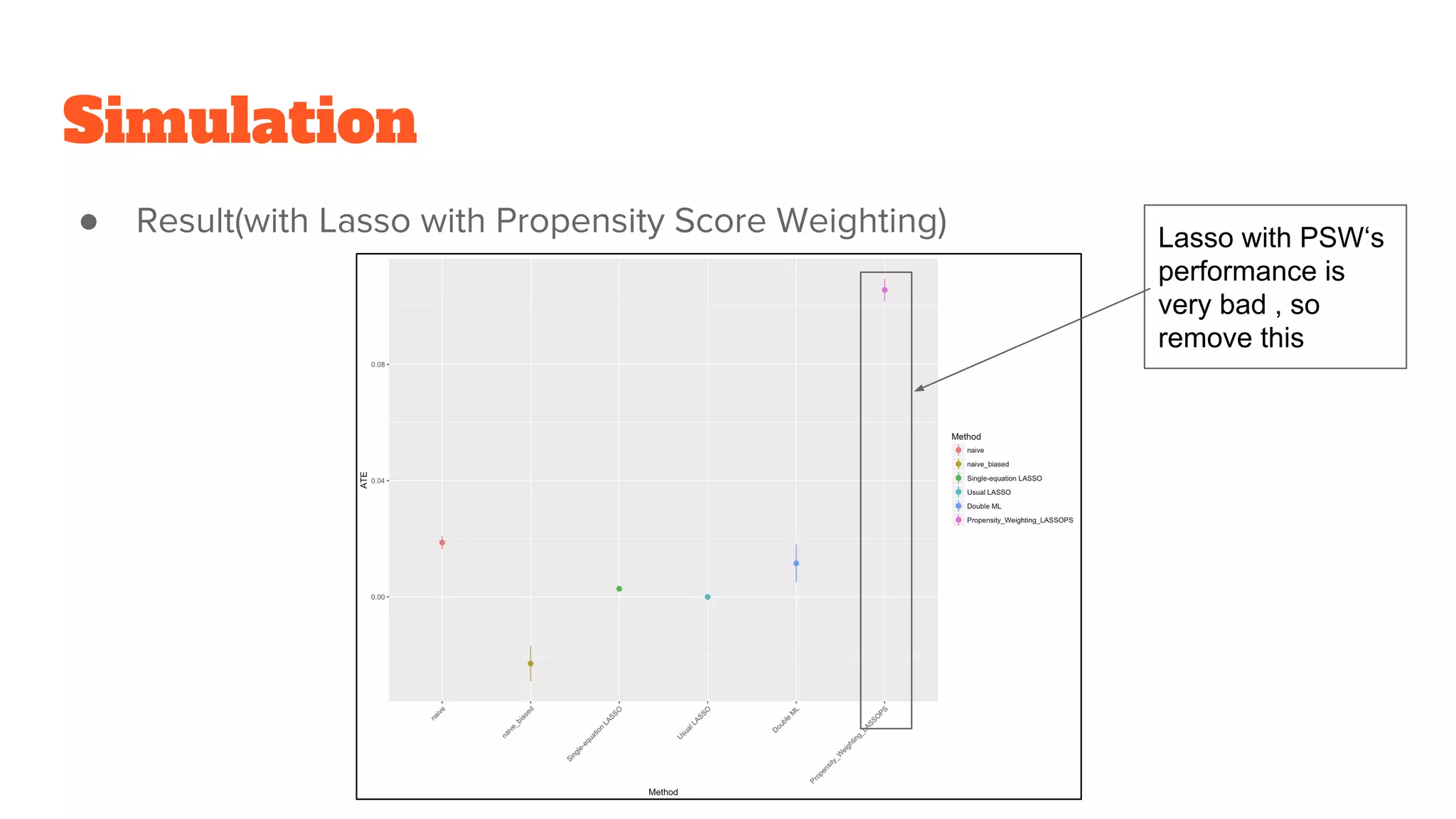
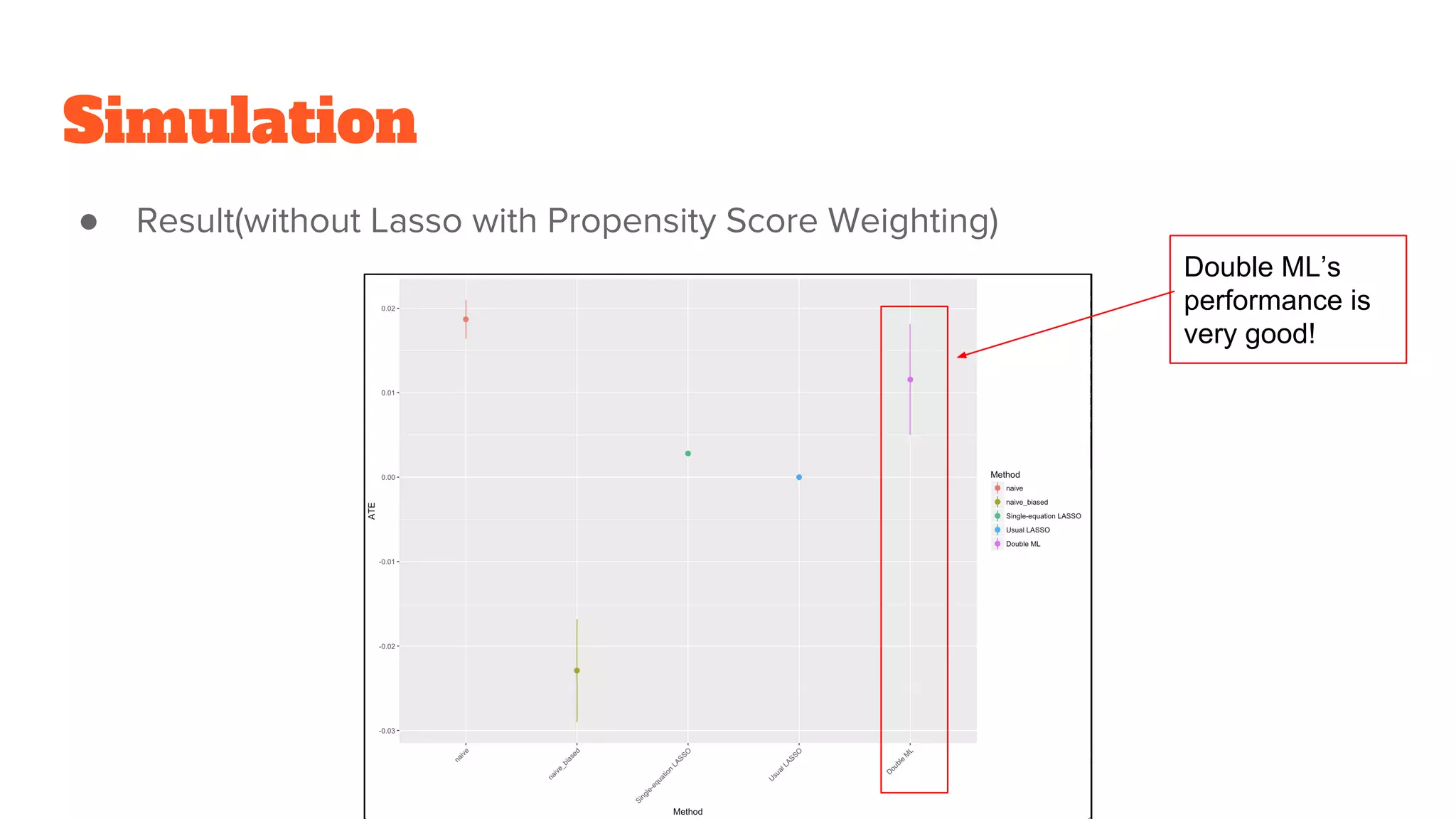
● Use approach:Double ML with Lasso(You can use RandomForest instead of
Lasso)
→ Counter approach: Naive ATE, Single equation Lasso , Usual Lasso , Lasso
with Propensity Score Weighting
19.
Simulation
● Result(with Lassowith Propensity Score Weighting) Lasso with PSW‘s
performance is
very bad , so
remove this







































![[DL輪読会]Parallel WaveNet: Fast High-Fidelity Speech Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/0105-180105000252-thumbnail.jpg?width=640&height=640&fit=bounds)




























![[DSC Europe 25] Vid Stimac - Policy Parsimony: Between Oversimplifying and Ov...](https://cdn.slidesharecdn.com/ss_thumbnails/eqlepagzqp2rhg3gbluh-dsc-stimac-251120-251205090438-059e7f54-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Boris Perkovic - Lost in performance.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/uq5hrp7vsuahqkxzifux-1-251204082258-fd2ee09d-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)