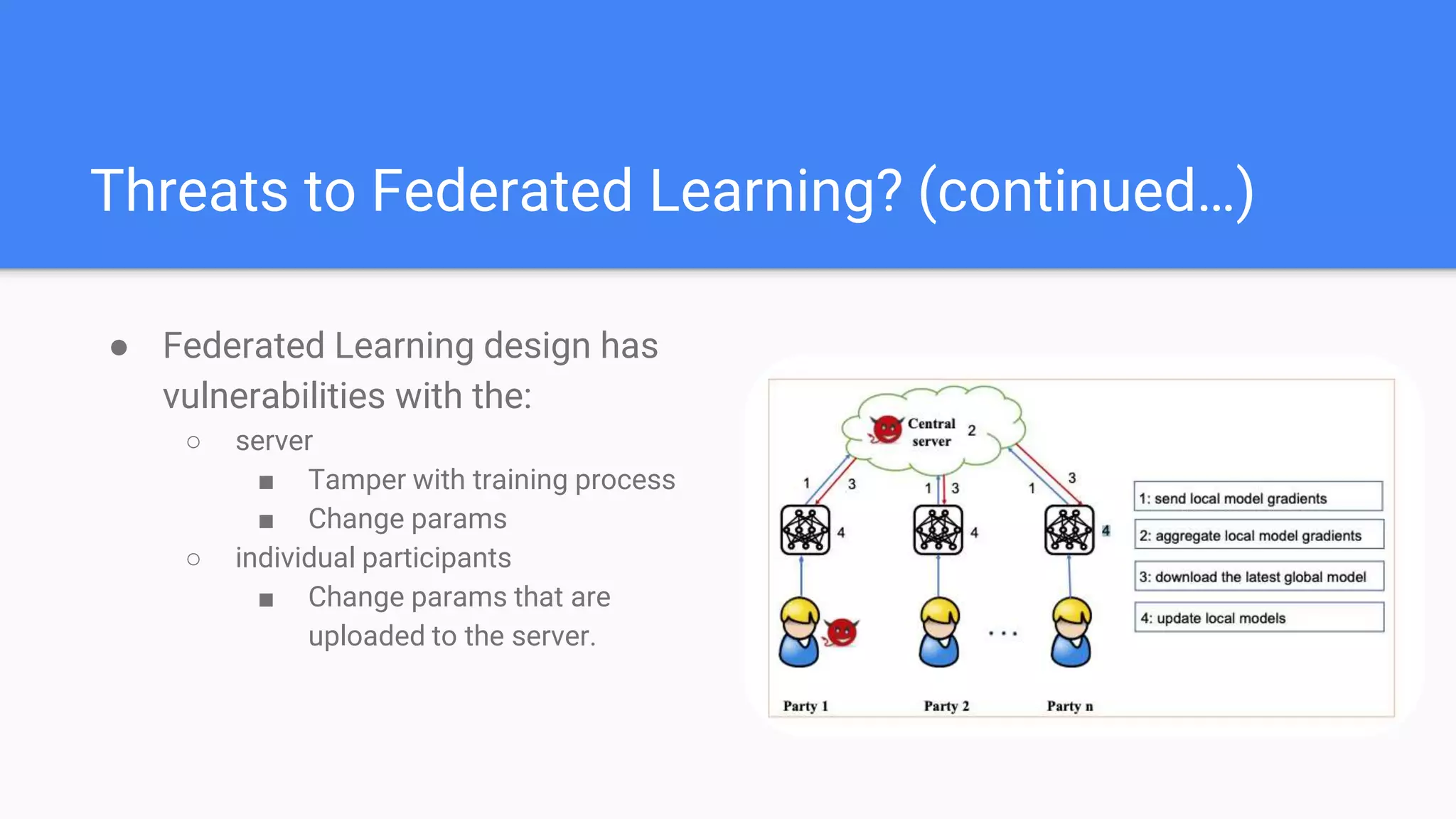
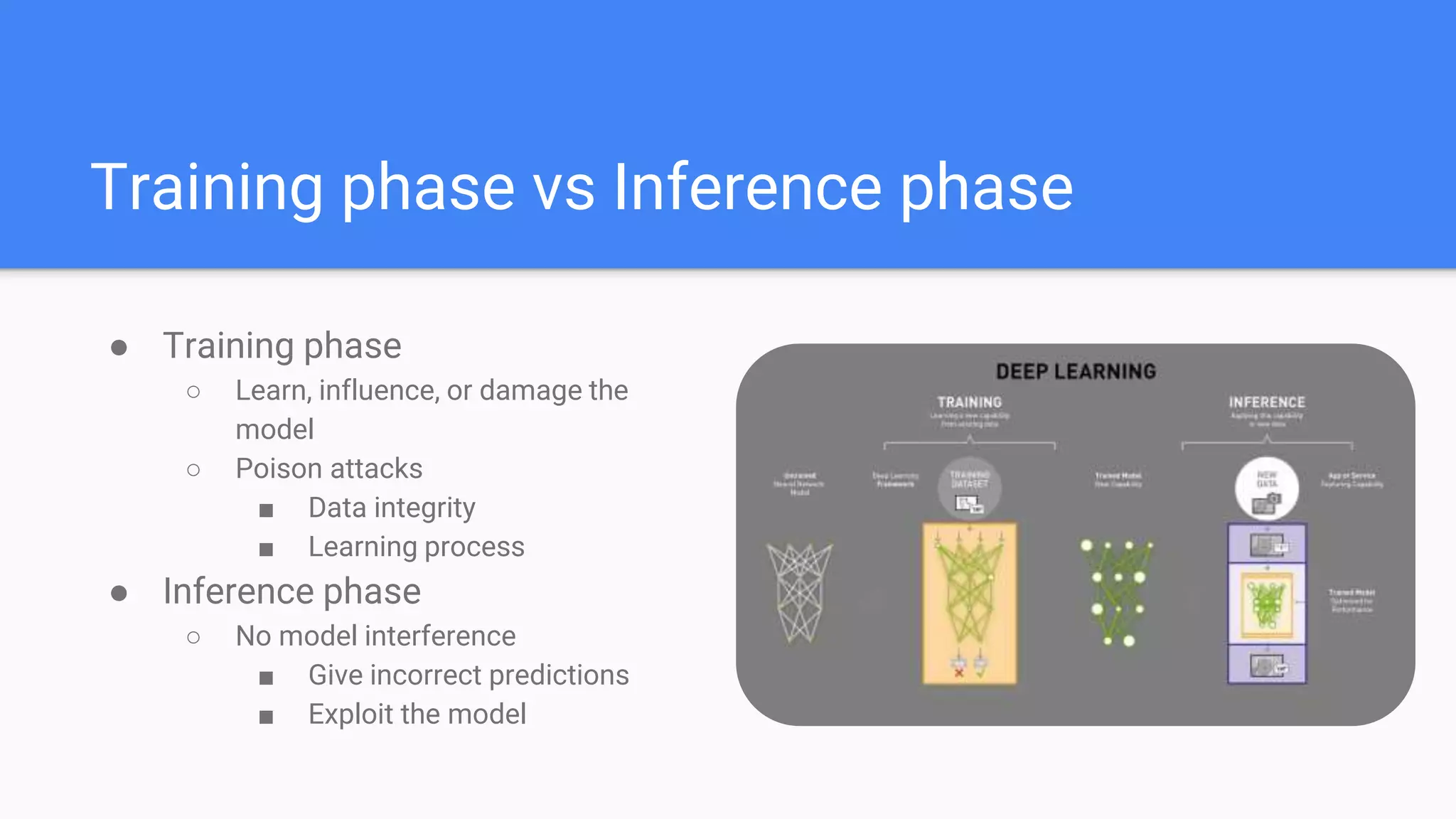
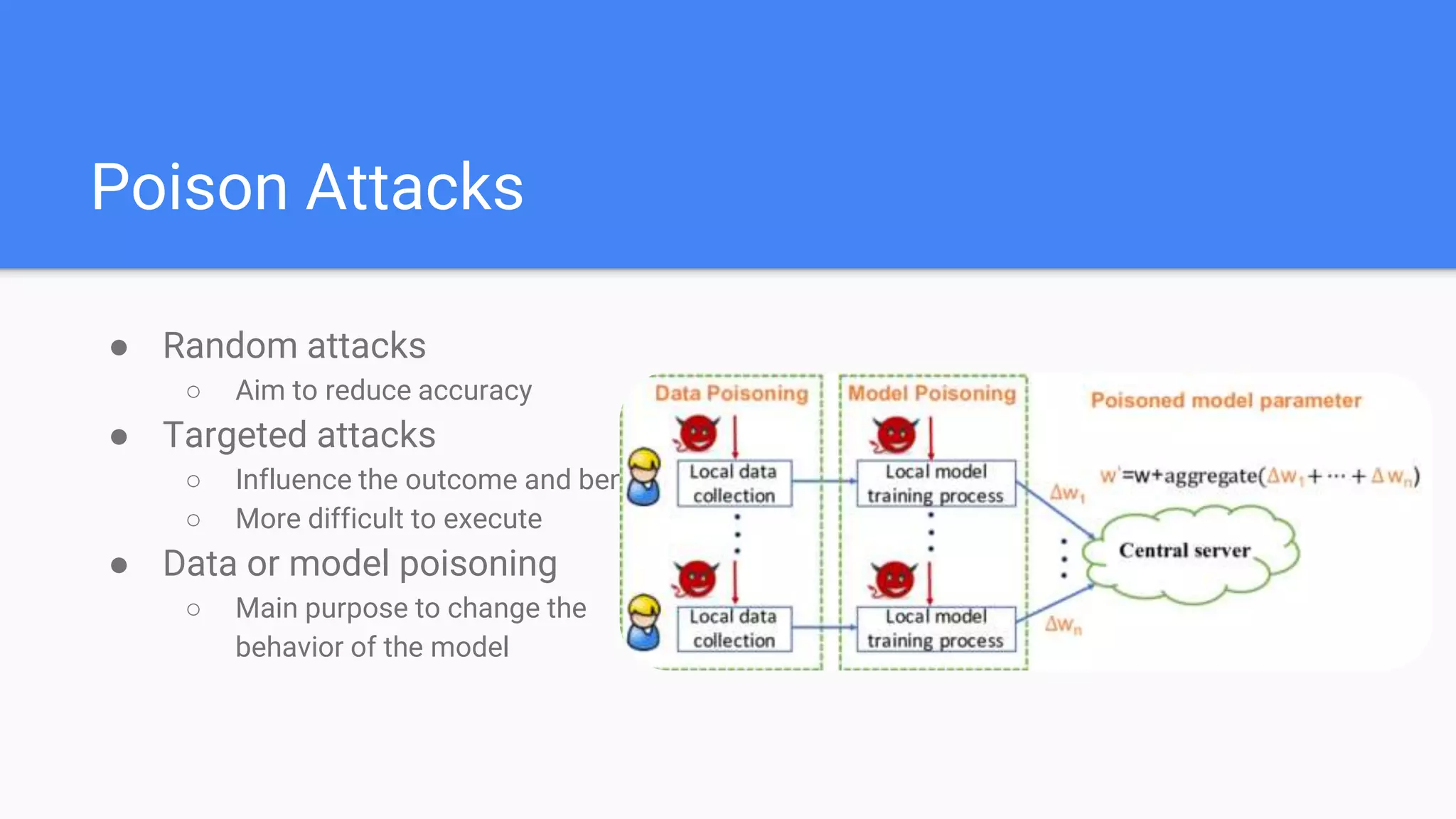
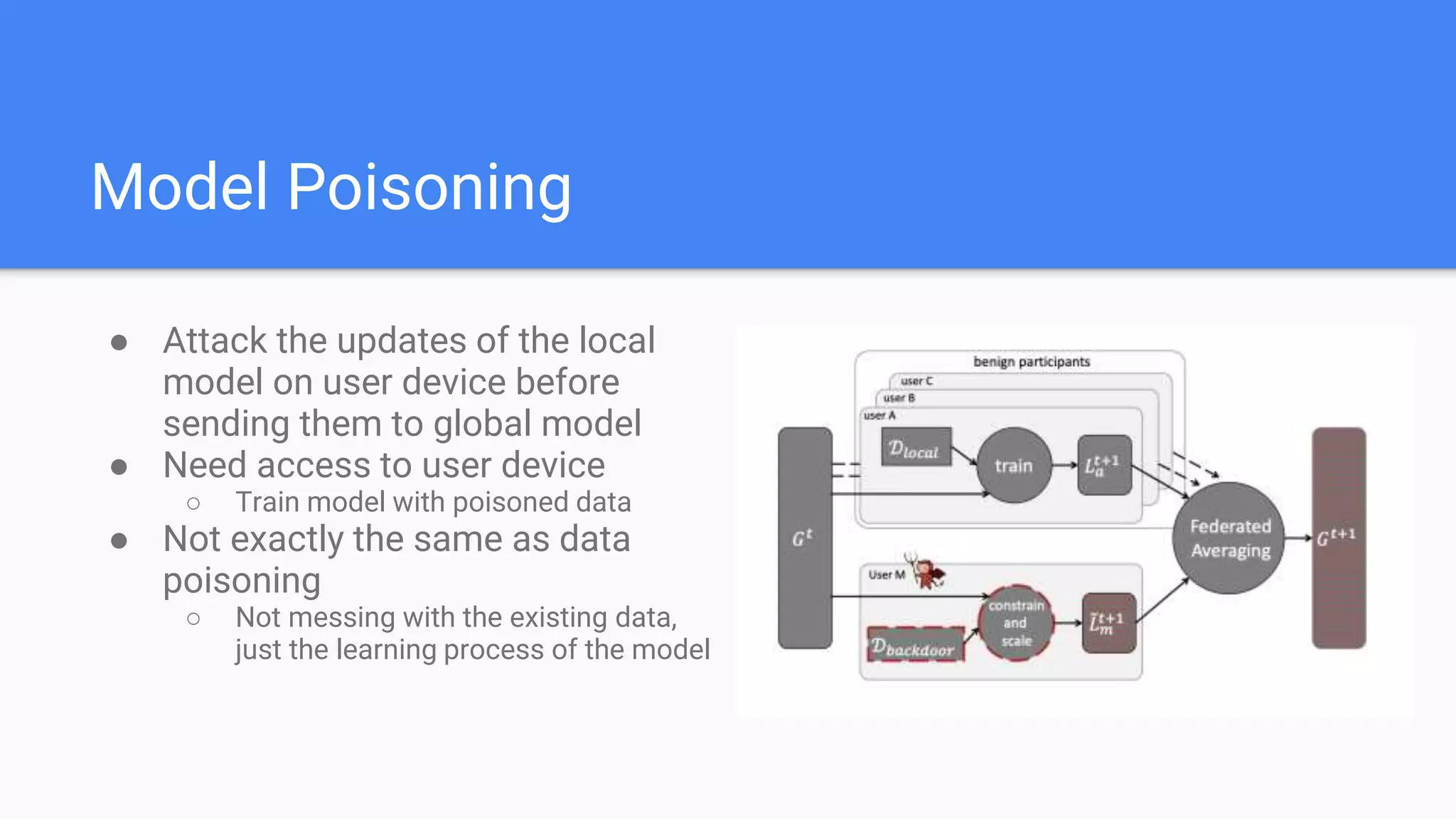
This document summarizes a survey paper on threats to federated learning. It describes federated learning as a privacy-preserving approach to training models where user data stays on individual devices rather than being sent to a central server. It outlines different types of federated learning and then discusses various threat models and attacks during the training and inference phases, including data poisoning, model poisoning, and inference attacks that aim to reveal private user information based on model updates. Defenses discussed include sharing less sensitive information during training and implementing differential privacy.