Downloaded 46 times




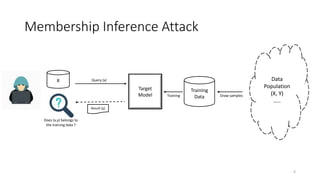

![Problem Statement
8
Training Data
(X,Y)
Target
Model
X Query (x = [xi, … xN])
Result (y = [p1, .. pk])
Data
Population
(X, Y)
…..
Draw samplesTraining
Black-box or Query
Access ONLY
Adversary does not know anything about the
model & its training procedure except the
format of X, Y and its possible values
Little or no knowledge about
the data population
Little : e.g. Knows the prior of the marginal
distribution of the features
Prediction
Vector/Confidence
ValuesAttack
Model
[x,y]
Result (a = in/out)
Attack model attempts to learn how
differently target model behave (y) for x in
training data vs x not in training data](https://image.slidesharecdn.com/memebershipinferenceattacksagaistmachinelearningmodels-190827112049/85/Memebership-inference-attacks-against-machine-learning-models-8-320.jpg)
![Shadow Training
9
Attack
Model
Training Data
([X,Y], A)Training Generate
Shadow
Model
Imitate the Behavior
of Target Model
Shadow
Training Data
(X,Y)
Training
Shadow
Test Data
(X,Y)
Shadow
Model
Shadow
Training Data
(X,Y)
Training
Shadow
Test Data
(X,Y)
…..
…..
…..
([X,Y], A = in)
([X,Y], A = out)](https://image.slidesharecdn.com/memebershipinferenceattacksagaistmachinelearningmodels-190827112049/85/Memebership-inference-attacks-against-machine-learning-models-9-320.jpg)


![Training Attack Model
12
Attack
Model 1
Training Data
([X,Y], A)
Training
Generate
Shadow
Model
Shadow
Training Data
(X,Y)
Training
Shadow
Test Data
(X,Y)
Shadow
Model
Shadow
Training Data
(X,Y)
Training
Shadow
Test Data
(X,Y)
…..
…..
…..
Training Data 1
([X,Y], A)
Training Data K
([X,Y], A)
…..
…..
….. Partition
Max_index(Y) = 1
Max_index(Y) = K
Attack
Model K Training
…..
…..
…..
During testing [x,y] is
applied to
Max_index(y)th
attack model](https://image.slidesharecdn.com/memebershipinferenceattacksagaistmachinelearningmodels-190827112049/85/Memebership-inference-attacks-against-machine-learning-models-12-320.jpg)



![[R1] Number of Classes & Training Set Size
16
K = 10 K = 100
[O1] As training data size target model
increases, attack model’s precision drops
[O2] As K increases, information leakage
is high (precision close to 1)](https://image.slidesharecdn.com/memebershipinferenceattacksagaistmachinelearningmodels-190827112049/85/Memebership-inference-attacks-against-machine-learning-models-16-320.jpg)
![[R2] Overfitting & Model Types
17
Overfitting
---------------
0.34
0.5
0.5
0.16 [O3] Google Prediction API leaks more compare Amazon ML or
NN
[O4] When the model is less over fitted, then leaks less. e.g. NN
model
[O5] Overfitting is not the ONLY reason for information leakage.
The model structure & architecture are also the reason for
information leakage.
E.g. Google P-API vs Amazon ML](https://image.slidesharecdn.com/memebershipinferenceattacksagaistmachinelearningmodels-190827112049/85/Memebership-inference-attacks-against-machine-learning-models-17-320.jpg)
![[R3] Performance with Noisy Data
18
[O6] With the increase in noise in attack model’s training data, it’s
performance drops
[O7] Even when the noise level is 20%, the attack model
outperforms baseline (0.5).
* This indicates that the proposed model is robust even when
the adversary’s assumption about target model’s training data is
not accurate](https://image.slidesharecdn.com/memebershipinferenceattacksagaistmachinelearningmodels-190827112049/85/Memebership-inference-attacks-against-machine-learning-models-18-320.jpg)
![[R4] Performance with Synthetic Data
19
[O8] There is a significant performance drop when marginal
based synthetic data is used
[O9] Attack using model-based synthetic data performs closer to
attack using real data except for classes with less training
examples in target model’s training data.
* Membership inference attack is possible only with black-box
access to target model without any knowledge about data
population
Less than 0.1 fraction of classes performs poor
These classes contributes under 0.6% of the
training data](https://image.slidesharecdn.com/memebershipinferenceattacksagaistmachinelearningmodels-190827112049/85/Memebership-inference-attacks-against-machine-learning-models-19-320.jpg)
![Performance in Six Datasets
20
Overfit/Performance Gap
------------------------
0
0.06
0.33
0.01
0.13
0.22
0.31
0.34
0.15
Attack performance is
low
1. [O2] K is low
2. [O4] Low Overfitting
Attack performance is
high
1. [O4] High Overfitting
Attack performance is low even with high
overfitting
[O5] Overfitting is not the ONLY reason for
information leakage](https://image.slidesharecdn.com/memebershipinferenceattacksagaistmachinelearningmodels-190827112049/85/Memebership-inference-attacks-against-machine-learning-models-20-320.jpg)
![[R5] Why does attack successful?
• Prediction Uncertainty vs Accuracy of Target Model
PU = Normalized entropy of the prediction vector
21
K = 10 K = 100
[O10] When PU is low, the accuracy of target model is
high
[O11] With the increase in K, PU increases & accuracy
of target model drops
[O12] As K increases, PU distribution is significantly
differ for member vs non-members
* Behavioral difference in target model for a member
vs non-member is utilized by the attack for successful
attack
Fractionoftestsample](https://image.slidesharecdn.com/memebershipinferenceattacksagaistmachinelearningmodels-190827112049/85/Memebership-inference-attacks-against-machine-learning-models-21-320.jpg)

![[R6] Effect of Mitigation Strategies
23
[O13] Precision drops significantly, when top 1 label
ONLY is returned or with high regularization
[O14] Accuracy drops significantly, when t=20 or
with high regularization
[O15] Target model’s performance is even increased
with required amount of regularization
[O16] High regularization may significantly reduce
the target model’s performance
[O17] Even with the mitigation strategies, attack
model outperforms baseline (0.5)
* Attack is robust](https://image.slidesharecdn.com/memebershipinferenceattacksagaistmachinelearningmodels-190827112049/85/Memebership-inference-attacks-against-machine-learning-models-23-320.jpg)



The document discusses membership inference attacks on machine learning models, highlighting their ability to determine if a specific data point was part of the model's training set. It details the attack methodology, evaluation of attack performance, and factors influencing information leakage, such as model overfitting and training data diversity. Mitigation strategies are also suggested, but the attacks demonstrate resilience, indicating potential privacy vulnerabilities in machine learning as a service.





















































![Lect 1 Number systems and base conversions. [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/lect1numbersystemsandbaseconversions-260111134109-67c2d865-thumbnail.jpg?width=640&height=640&fit=bounds)













