Download to read offline






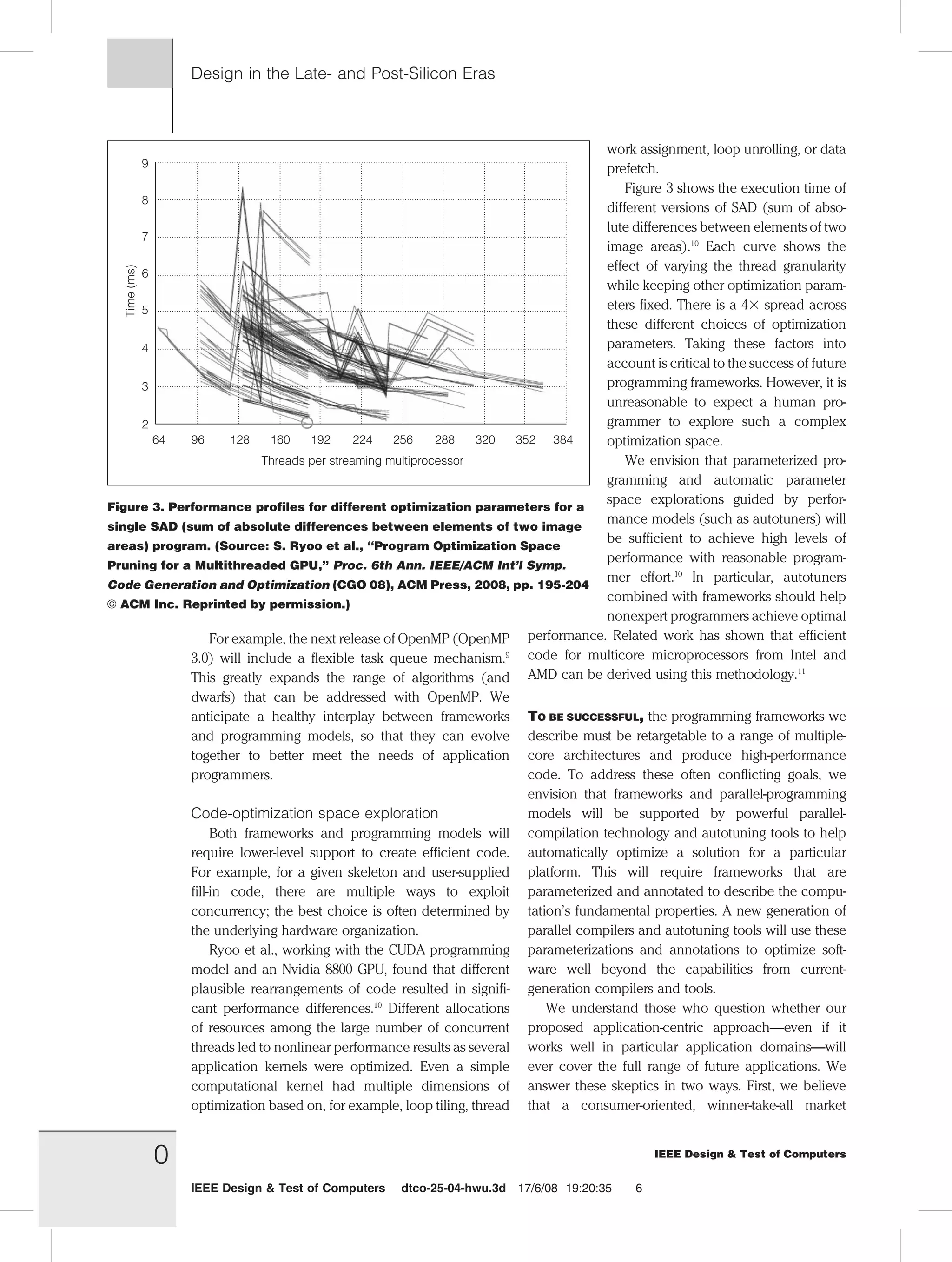



The document discusses the challenges of parallel programming in the context of multicore and many-core microprocessor design, emphasizing the need for software to adapt to leverage the increasing computational power. It identifies fundamental issues such as complexity, nondeterminism, and the necessity for application-centric programming environments to assist developers in effectively utilizing concurrency. The authors propose that solutions must be driven by established engineering principles to enhance the usability and performance of parallel systems.







































































