More Related Content

PPTX
![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant... 
PDF

PPTX
Triplet Lossによる Person Re-identification 
PPTX
【DL輪読会】Toolformer: Language Models Can Teach Themselves to Use Tools ![[DL輪読会]Hindsight Experience Replay](https://cdn.slidesharecdn.com/ss_thumbnails/her-180105002310-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]Hindsight Experience Replay 
PPTX

PPTX
What's hot

PDF
Tech-Circle #18 Pythonではじめる強化学習 OpenAI Gym 体験ハンズオン 
PDF

PDF

PDF

PDF
【メタサーベイ】Video Transformer 
PDF
DQNからRainbowまで 〜深層強化学習の最新動向〜 
PDF
![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜 
PDF
分散型強化学習手法の最近の動向と分散計算フレームワークRayによる実装の試み 
PDF

PPTX
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners 
PDF
continual learning survey ![[DL輪読会]深層強化学習はなぜ難しいのか?Why Deep RL fails? A brief survey of recent works.](https://cdn.slidesharecdn.com/ss_thumbnails/20210115dlohta-210115054939-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]深層強化学習はなぜ難しいのか?Why Deep RL fails? A brief survey of recent works. 
PDF
Statistical Semantic入門 ~分布仮説からword2vecまで~ ![[DL輪読会]When Does Label Smoothing Help?](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20191227dl-191227001522-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]When Does Label Smoothing Help? 
PPTX

PDF
【Deep Learning】AlexNetの解説&実装 by PyTorch (colabリンク付き) 
PPTX
マルチエージェント強化学習 (MARL) と M^3RL 
PPTX
Generative Adversarial Imitation Learningの紹介(RLアーキテクチャ勉強会) 
PPTX
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 ) Similar to Tf勉強会(4)

PDF
Rainbow: Combining Improvements in Deep Reinforcement Learning (AAAI2018 unde... 
PDF
20180830 implement dqn_platinum_data_meetup_vol1 
PDF
introduction to double deep Q-learning 
PDF
強化学習とは (MIJS 分科会資料 2016/10/11) ![[CV勉強会]Active Object Localization with Deep Reinfocement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/20160204objectdetectionrl-160206032348-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[CV勉強会]Active Object Localization with Deep Reinfocement Learning 
PDF
introduction to Deep Q Learning 
PPTX
Batch Reinforcement Learning 
PPTX
Deep reinforcement learning for imbalanced classification 
PPTX

PPTX
Deep Recurrent Q-Learning(DRQN) for Partially Observable MDPs 
PDF
論文紹介:Dueling network architectures for deep reinforcement learning 
PPTX

PPTX
Decision Transformer: Reinforcement Learning via Sequence Modeling 
PPTX

PDF
深層強化学習の分散化・RNN利用の動向〜R2D2の紹介をもとに〜 
PDF
introduction to Dueling network ![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜 
PPTX

PDF

PDF
論文紹介: Offline Q-Learning on diverse Multi-Task data both scales and generalizes More from tak9029

PPTX

PPTX

PPTX

PPTX

PPTX

PPTX

PPTX

PPTX

PDF
Tensor flow勉強会 (ayashiminagaranotensorflow) Tf勉強会(4)
- 1.
- 2.
- 3.
3
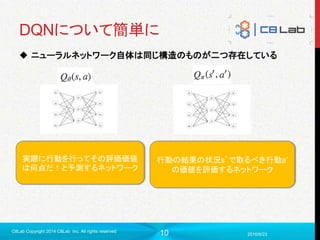
概要
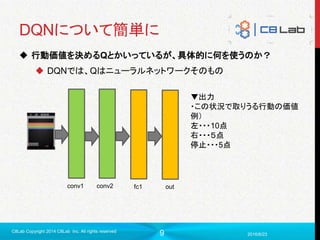
DQN
DeepQ Network (ヤンキーじゃないよ)
DeepLearning とQ Learningを組み合わせたもの
AlphaGoにも使われていたらしいやつ
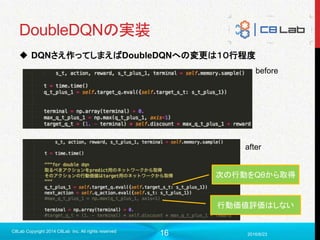
DoubleDQN
Double Deep Q Network(二人のヤンキーじゃないよ)
DeepMindが2015年12月に発表
同年2月にDQN出したばかりなのに。。。
DQNより精度いいよ(後述)
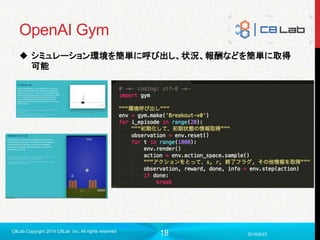
Gym
OpenAIが提供しているオープンソース
今年のどっかで出した
ゲームや物理エンジン向けのシミュレーション環境
まだβ版?
2016/6/23
C8Lab Copyright 2014 C8Lab Inc. All rights reserved
- 4.
- 5.
- 6.
6
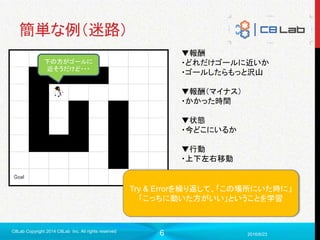
簡単な例(迷路)
2016/6/23
C8Lab Copyright 2014C8Lab Inc. All rights reserved
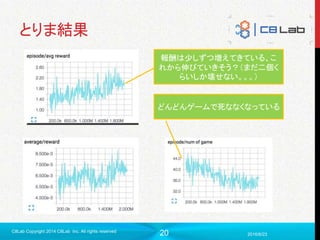
下の方がゴールに
近そうだけど・・・
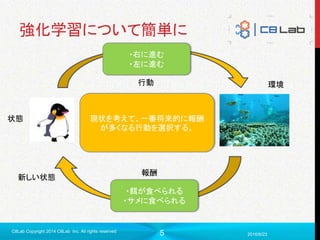
▼報酬
・どれだけゴールに近いか
・ゴールしたらもっと沢山
▼報酬(マイナス)
・かかった時間
▼状態
・今どこにいるか
▼行動
・上下左右移動
Try & Errorを繰り返して、「この場所にいた時に」
「こっちに動いた方がいい」ということを学習
- 7.
- 8.
- 9.
- 10.
- 11.
11
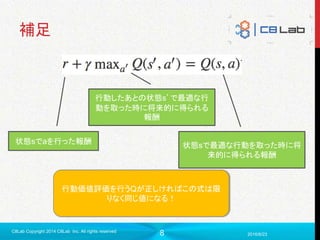
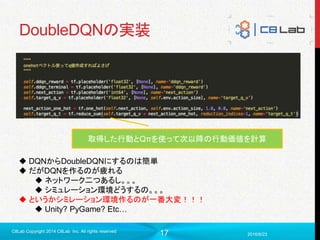
DQNのデータセット
とあるの状況(s)
その時撮った行動(a)
それによって得られた報酬(r)
その行動を取ったことによって生じた新しい状況(s’)
2016/6/23
C8Lab Copyright 2014 C8Lab Inc. All rights reserved
状況s 行動a
Qθ側のNNで決定
右に行
く!
報酬r
・ブロック崩してた:+1
・死んでた。。。:−1
新しい状況s’
学習する前に最初にこれらの情報をひたすら収集
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.