Downloaded 629 times





















This document discusses text mining and provides an outline of the topic. It defines text mining as the analysis of natural language text data and explains why it is useful given the large amount of unstructured data. The document then describes the basic text mining process, which includes steps like filtering, segmentation, stemming, eliminating excessive words, and clustering. Several applications of text mining are mentioned like call centers, anti-spam, and market intelligence. Challenges of text mining like dealing with unstructured data and large collections of documents are also outlined.
Overview of text mining and its importance; outlines the agenda including definitions and applications.
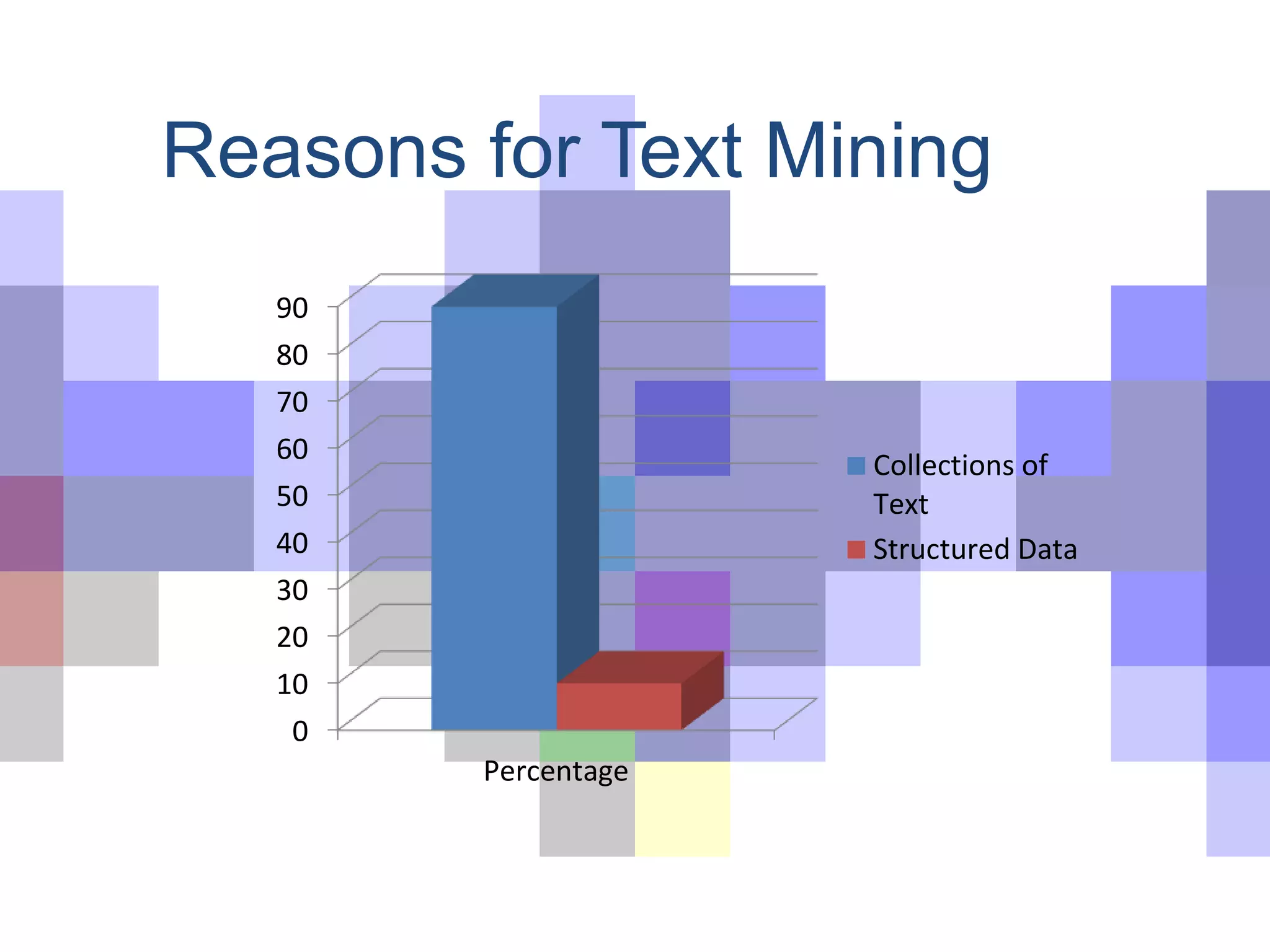
Highlights the exponential growth of unstructured data and examples, emphasizing the need for text mining.
Contrasts the processes of data mining and text mining focusing on identifying and analyzing data versus documents.
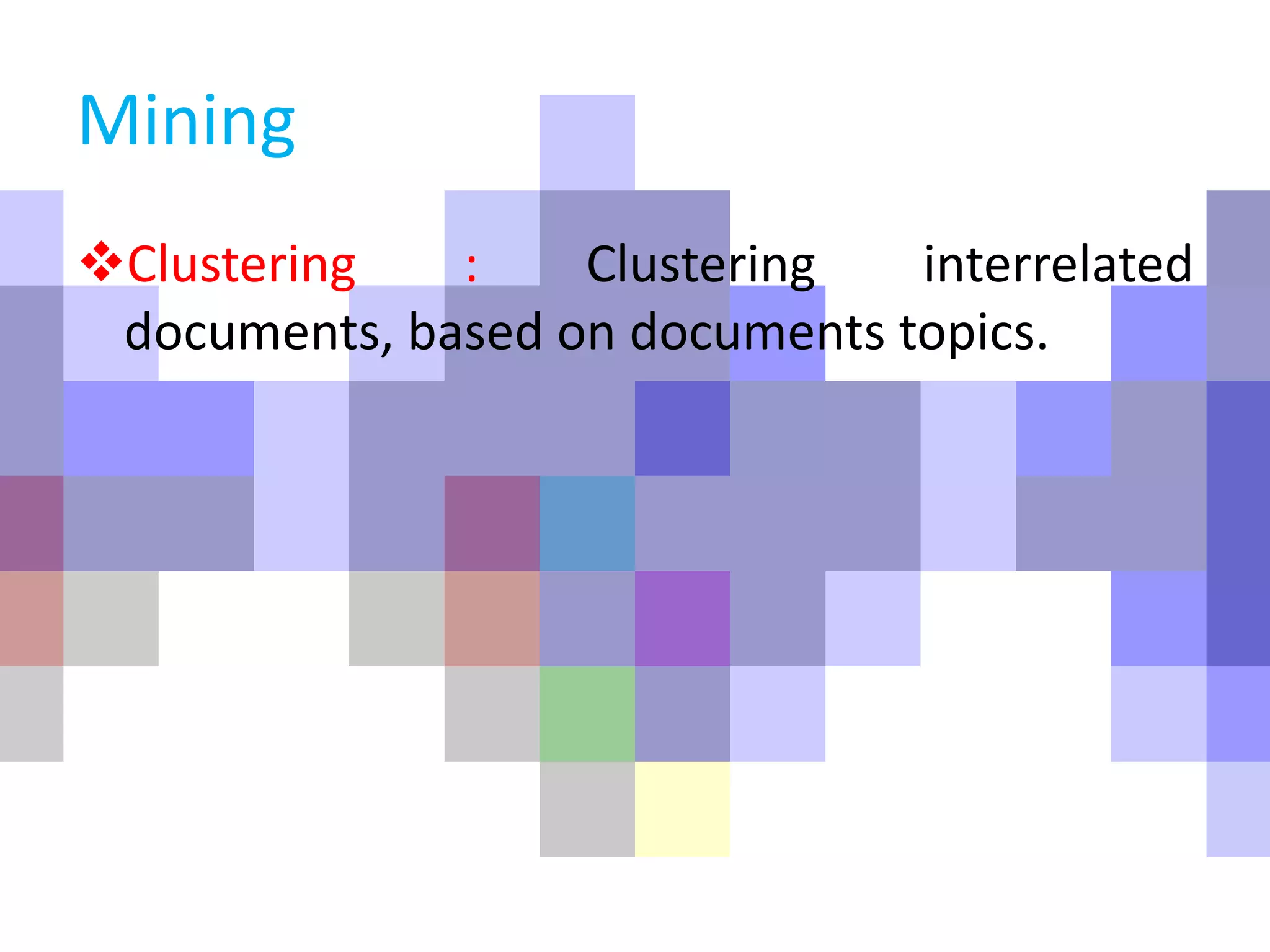
Describes essential text mining techniques such as filtering, stemming, and clustering, aiding in effective data analysis.
Discusses practical applications of text mining in various fields, including healthcare and religious texts.
Examines the difficulties in text mining including data accessibility, skill requirements, and software costs.
Summarizes the current state of text mining, noting its research phase and limited but promising applications.




















































































