Downloaded 62 times













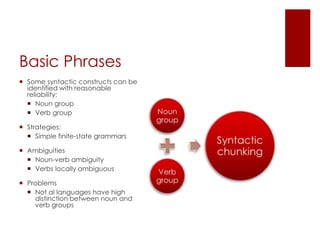












This document provides an overview of information extraction (IE). It describes IE as the process of scanning text to extract relevant entities, relations, and events. The document outlines common IE tasks like named entity recognition and discusses approaches to IE like using cascaded finite-state transducers and learning-based methods. It also addresses challenges in IE like measuring performance and how systems are progressing towards overcoming the 60% accuracy barrier.










































































