Downloaded 25 times





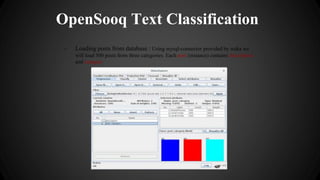
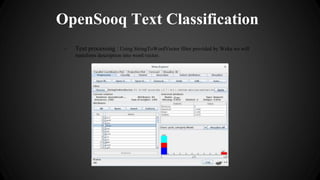




This document discusses using Weka, a machine learning toolkit, to perform text classification. It describes loading posts from a database, preprocessing the text by transforming it into word vectors, training two classification models (J48 decision tree and Naive Bayes) on the training data, evaluating the models on test data to measure accuracy, and using the best model via PyWeka to predict categories for new posts. The goal is to build a tool to automatically categorize product listings based on their descriptions.

![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt2740-thumbnail.jpg?width=640&height=640&fit=bounds)




















![[Eestec] Machine Learning online seminar 1, 12 2016](https://cdn.slidesharecdn.com/ss_thumbnails/eestecmachinelearningseminar1122016offline-161222133213-thumbnail.jpg?width=640&height=640&fit=bounds)
































































