Download as PDF, PPTX





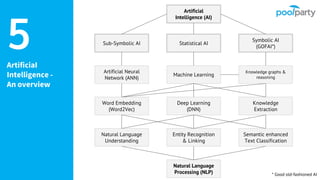

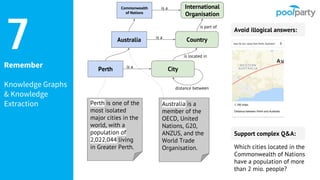





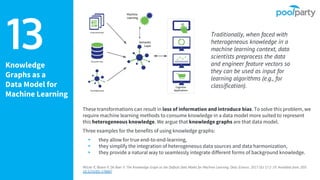

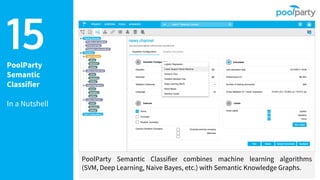
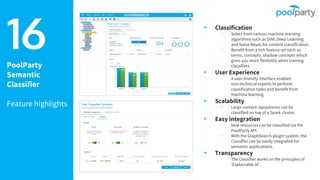


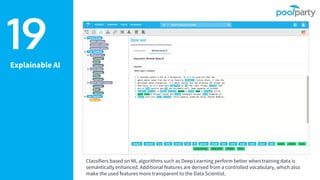
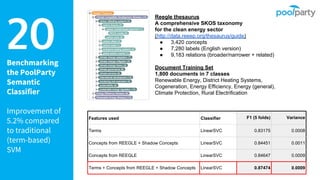
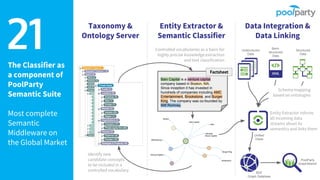




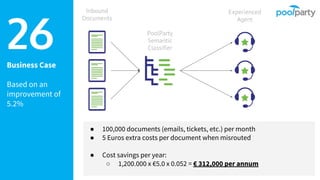





The document provides an overview of the Semantic Web Company, highlighting its Poolparty Semantic Suite, which integrates machine learning, natural language processing (NLP), and knowledge graphs. It outlines the capabilities and benefits of the Poolparty Semantic Classifier, including its features, performance benchmarks, and various use cases such as news classification and sentiment analysis. Additionally, it discusses the relationship between artificial intelligence and semantic models and examines the business case for enhanced data processing efficiency.










































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)










