More Related Content

PPTX
【DL輪読会】"Instant Neural Graphics Primitives with a Multiresolution Hash Encoding" 
PPTX
物体検出の歴史(R-CNNからSSD・YOLOまで) 
PPTX
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc) 
PDF
【DL輪読会】ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders 
PPTX
強化学習エージェントの内発的動機付けによる探索とその応用(第4回 統計・機械学習若手シンポジウム 招待公演) 
PDF
Skip Connection まとめ(Neural Network) 
PDF

PDF
モデルアーキテクチャ観点からのDeep Neural Network高速化 What's hot
![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder ![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant... 
PPTX
SegFormer: Simple and Efficient Design for Semantic Segmentation with Transfo... 
PDF

PDF
【DL輪読会】Egocentric Video Task Translation (CVPR 2023 Highlight) 
PDF

PPTX
【DL輪読会】時系列予測 Transfomers の精度向上手法 ![[DL輪読会]Temporal Abstraction in NeurIPS2019](https://cdn.slidesharecdn.com/ss_thumbnails/20191115-191112082849-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]Temporal Abstraction in NeurIPS2019 ![SSII2022 [OS3-04] Human-in-the-Loop 機械学習](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-04-220607021031-e69700d5-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
SSII2022 [OS3-04] Human-in-the-Loop 機械学習 
PDF
【メタサーベイ】基盤モデル / Foundation Models 
PPTX

PPTX
【DL輪読会】High-Resolution Image Synthesis with Latent Diffusion Models 
PDF

PDF

PDF

PPTX
You Only Look One-level Featureの解説と見せかけた物体検出のよもやま話 
PPTX

PPTX
近年のHierarchical Vision Transformer 
PDF

PPTX
Similar to TensorFlow Liteを使った組み込みディープラーニング開発
![[第2版]Python機械学習プログラミング 第14章](https://cdn.slidesharecdn.com/ss_thumbnails/14-190318023253-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[第2版]Python機械学習プログラミング 第14章 
PPTX
なにわTech20170218(tpu) tfug 
PPTX
Deep Learning基本理論とTensorFlow 
PPTX

PDF
Tensorflow Liteの量子化アーキテクチャ 
PPTX
AI入門「第4回:ディープラーニングの中身を覗いて、育ちを観察する」 
PDF
LIFULL HOME'S「かざして検索」リリースの裏側 
PPTX
みんなが知らない pytorch-pfn-extras ![[第2版]Python機械学習プログラミング 第13章](https://cdn.slidesharecdn.com/ss_thumbnails/13-190318023252-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[第2版]Python機械学習プログラミング 第13章 
PDF
Scikit-learn and TensorFlow Chap-14 RNN (v1.1) ![[第2版]Python機械学習プログラミング 第16章](https://cdn.slidesharecdn.com/ss_thumbnails/16-190318023255-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[第2版]Python機械学習プログラミング 第16章 
PPTX
JSAI's AI Tool Introduction - Deep Learning, Pylearn2 and Torch7 
PPTX
Tensor コアを使った PyTorch の高速化 
PDF
20141127 py datatokyomeetup2 
PPTX
Image net classification with Deep Convolutional Neural Networks ![[DL輪読会]Toward Multimodal Image-to-Image Translation (NIPS'17)](https://cdn.slidesharecdn.com/ss_thumbnails/20180427-180514071433-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]Toward Multimodal Image-to-Image Translation (NIPS'17) 
PDF
「ゼロから作るDeep learning」の畳み込みニューラルネットワークのハードウェア化 
PPTX

PDF
Deep learningの概要とドメインモデルの変遷 
PDF
More from Makoto Koike
![[オープンキャンプin南島原2020]深層学習を使ってキュウリ選別機作ってみた](https://cdn.slidesharecdn.com/ss_thumbnails/opencampminamishimabara-200523041547-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[オープンキャンプin南島原2020]深層学習を使ってキュウリ選別機作ってみた ![[PyConJP2019]Pythonで切り開く新しい農業](https://cdn.slidesharecdn.com/ss_thumbnails/pyconjp2019-190915165002-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[PyConJP2019]Pythonで切り開く新しい農業 
PDF

PDF

PDF

PDF
Tensor flowを使った キュウリの仕分け あれこれ Recently uploaded

PDF
krsk_aws_re-growth_aws_devops_agent_20251211 
PDF
2025/12/12 AutoDevNinjaピッチ資料 - 大人な男のAuto Dev環境 
PDF
音楽アーティスト探索体験に特化した音楽ディスカバリーWebサービス「DigLoop」|Created byヨハク技研 
PPTX
君をむしばむこの力で_最終発表-1-Monthon2025最終発表用資料-.pptx 
PDF
ソフトとハードの二刀流で実現する先進安全・自動運転のアルゴリズム開発【DENSO Tech Night 第二夜】 ー高精度な画像解析 / AI推論モデル ... 
PDF
ソフトウェアエンジニアがクルマのコアを創る!? モビリティの価値を最大化するソフトウェア開発の最前線【DENSO Tech Night 第一夜】 TensorFlow Liteを使った組み込みディープラーニング開発
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
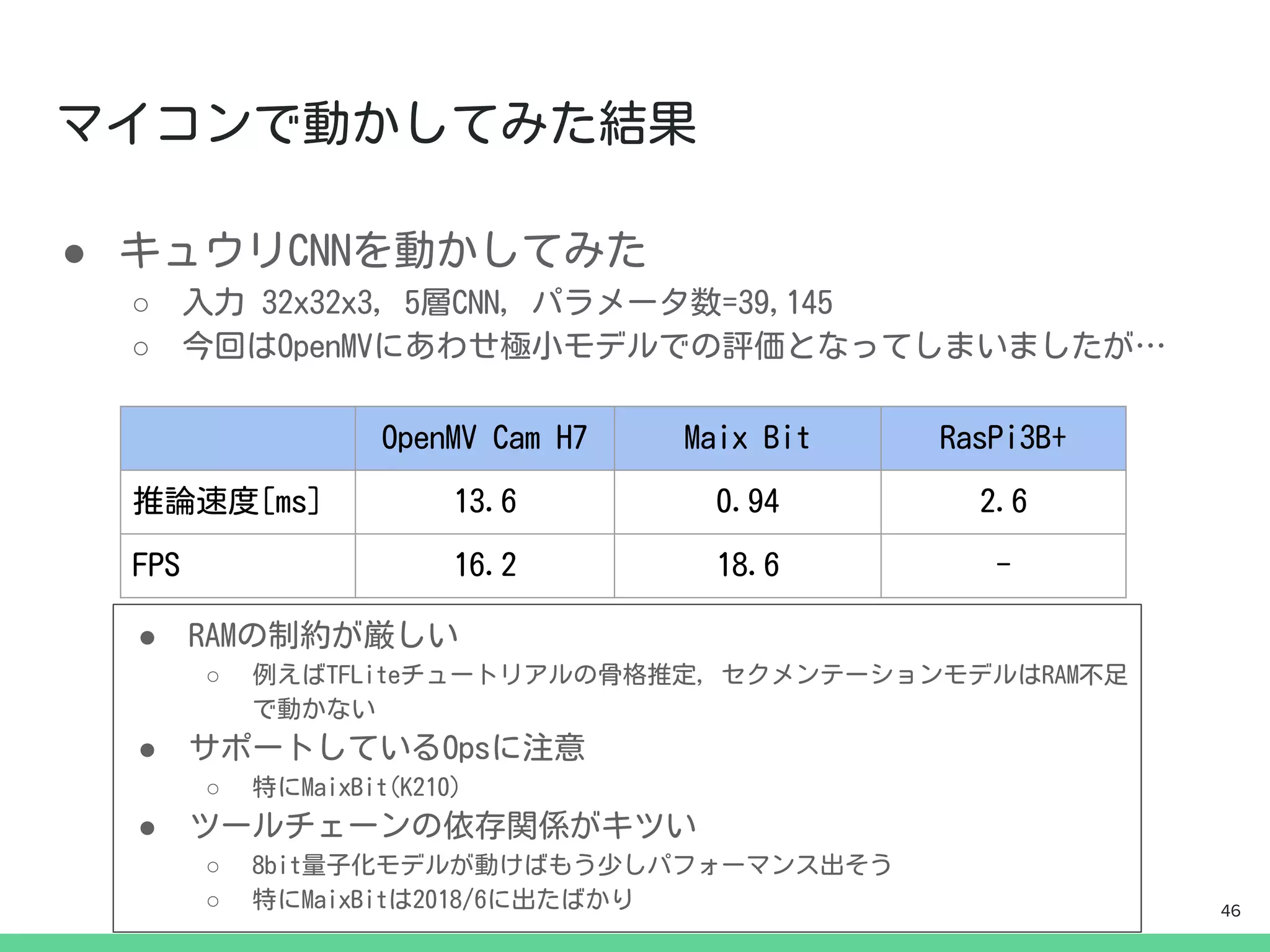
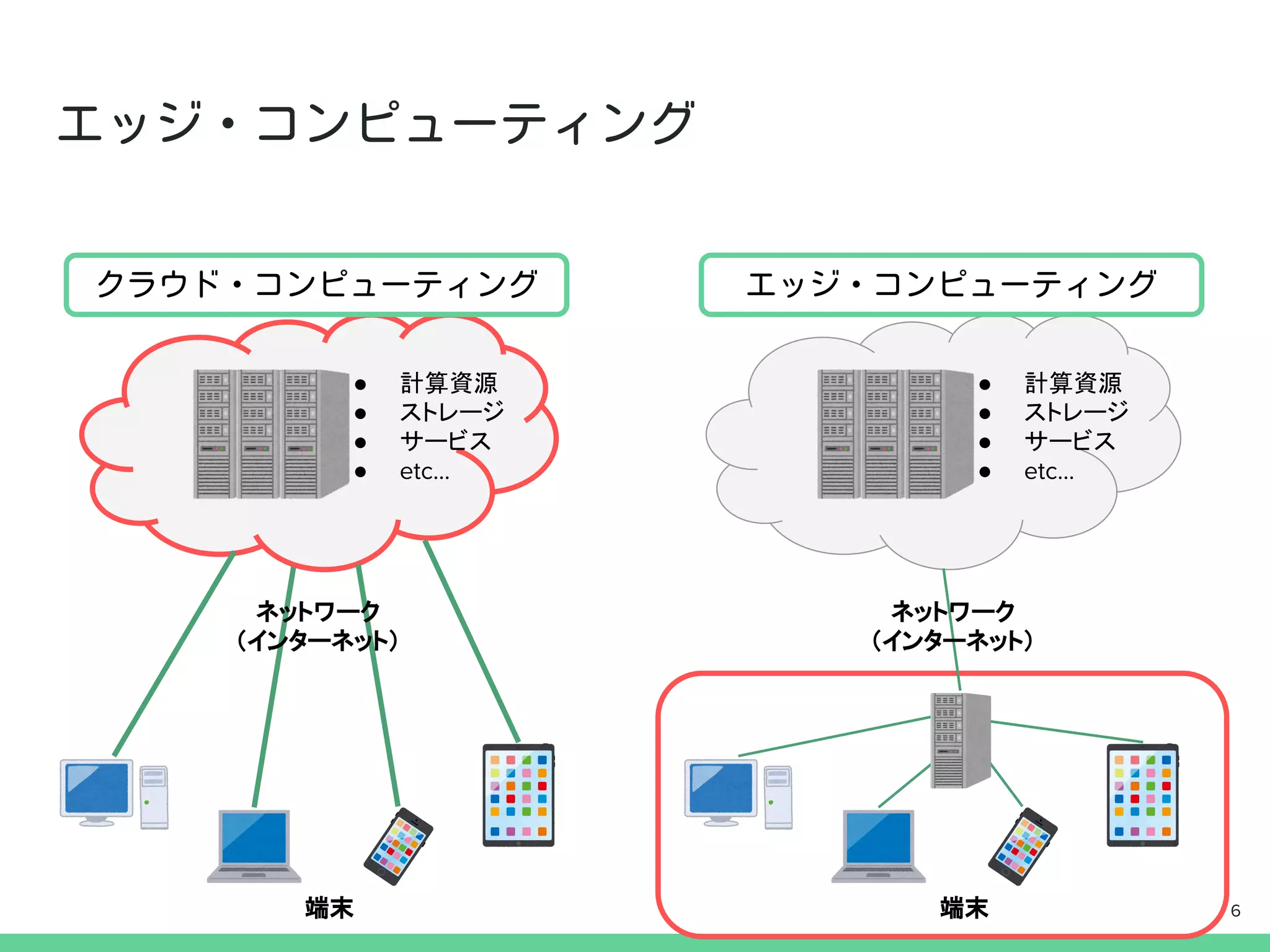
● 計算資源
● ストレージ
●サービス
● etc...
● 計算資源
● ストレージ
● サービス
● etc...
ネットワーク
(インターネット)
ネットワーク
(インターネット)
端末 端末 6
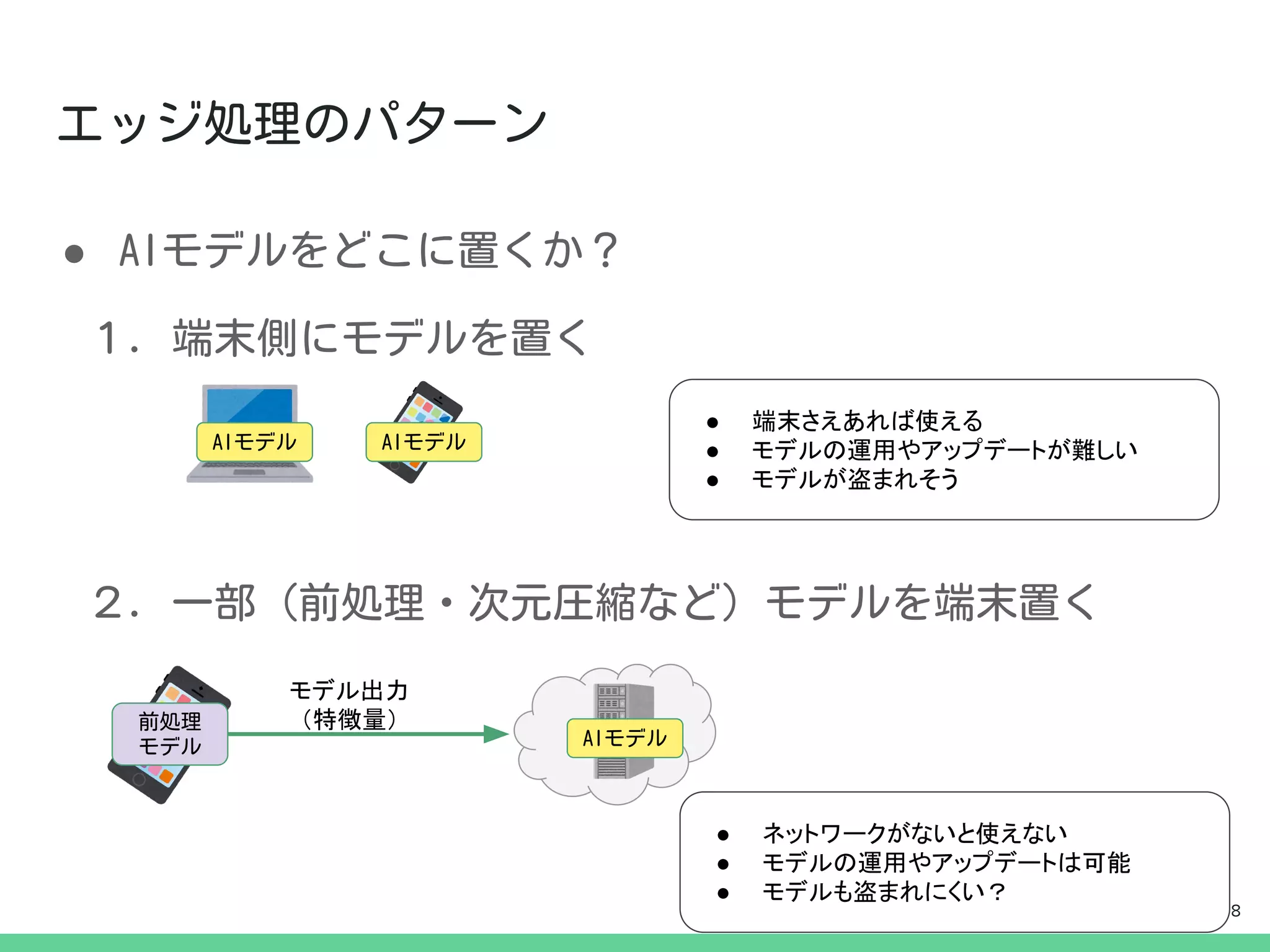
- 7.
- 8.
- 9.
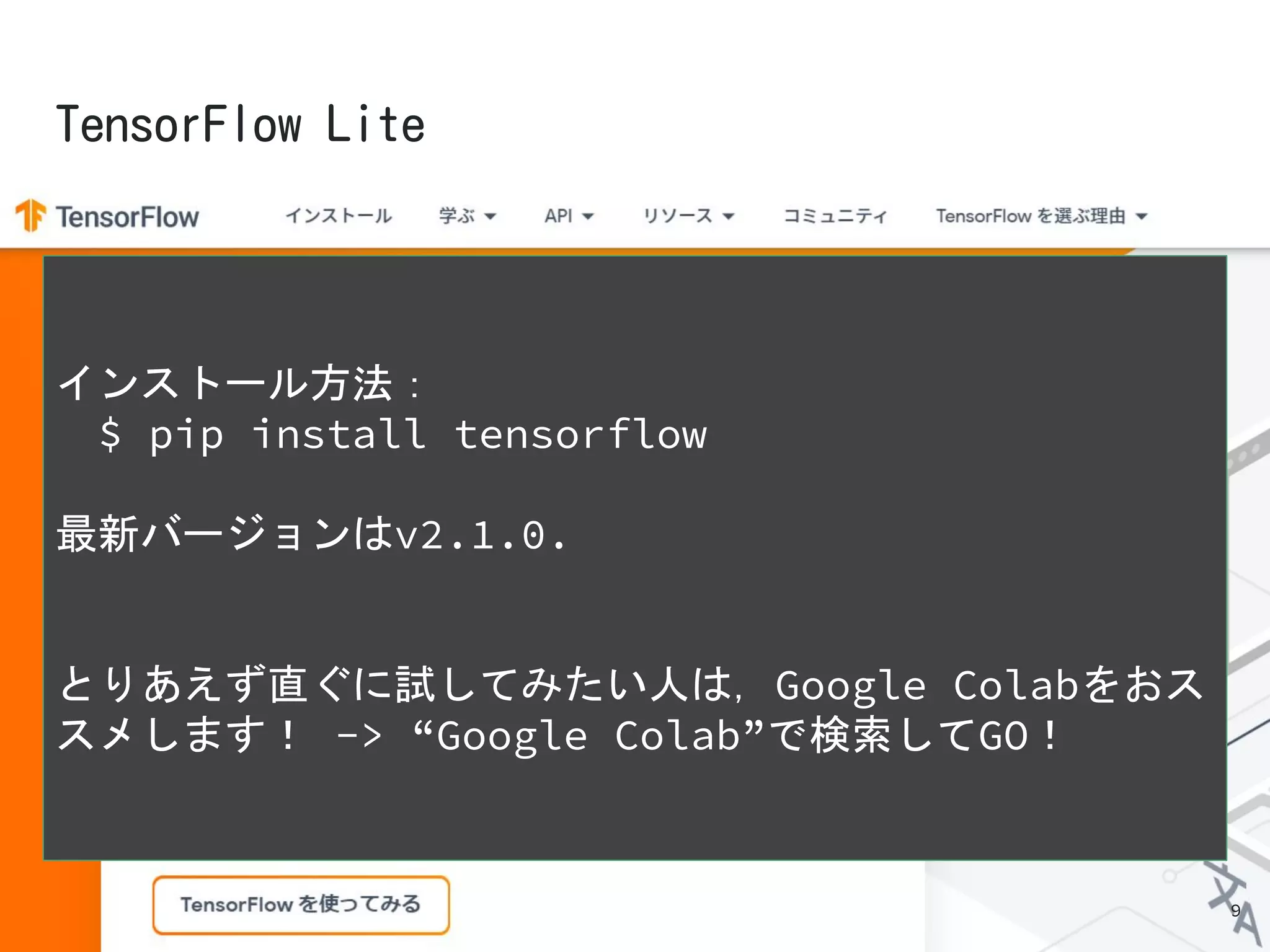
インストール方法:
$ pip installtensorflow
最新バージョンはv2.1.0.
とりあえず直ぐに試してみたい人は,Google Colabをおス
スメします! -> “Google Colab”で検索してGO!
9
- 10.
- 11.
- 12.
- 13.
- 14.
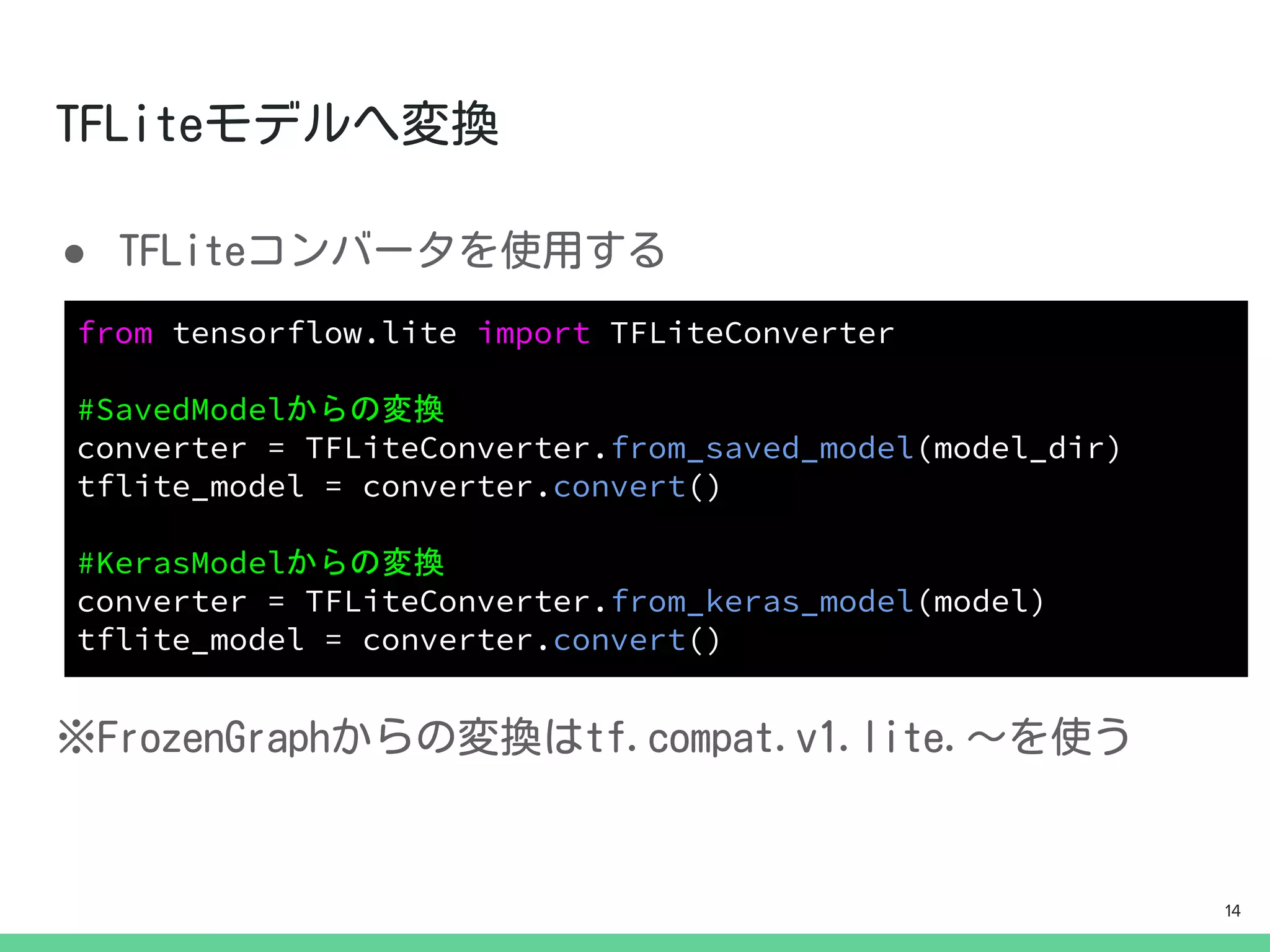
●
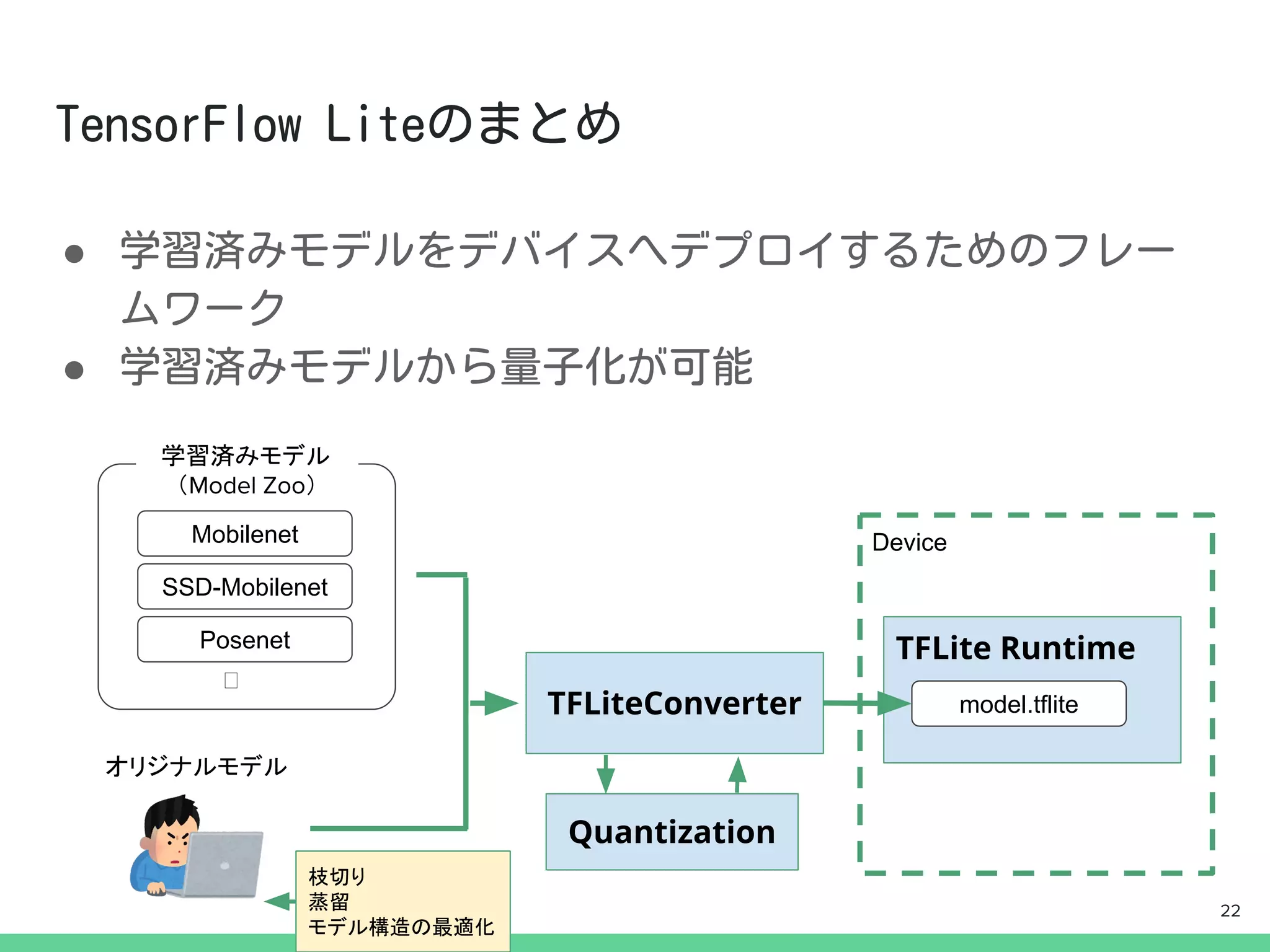
from tensorflow.lite importTFLiteConverter
#SavedModelからの変換
converter = TFLiteConverter.from_saved_model(model_dir)
tflite_model = converter.convert()
#KerasModelからの変換
converter = TFLiteConverter.from_keras_model(model)
tflite_model = converter.convert()
14
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
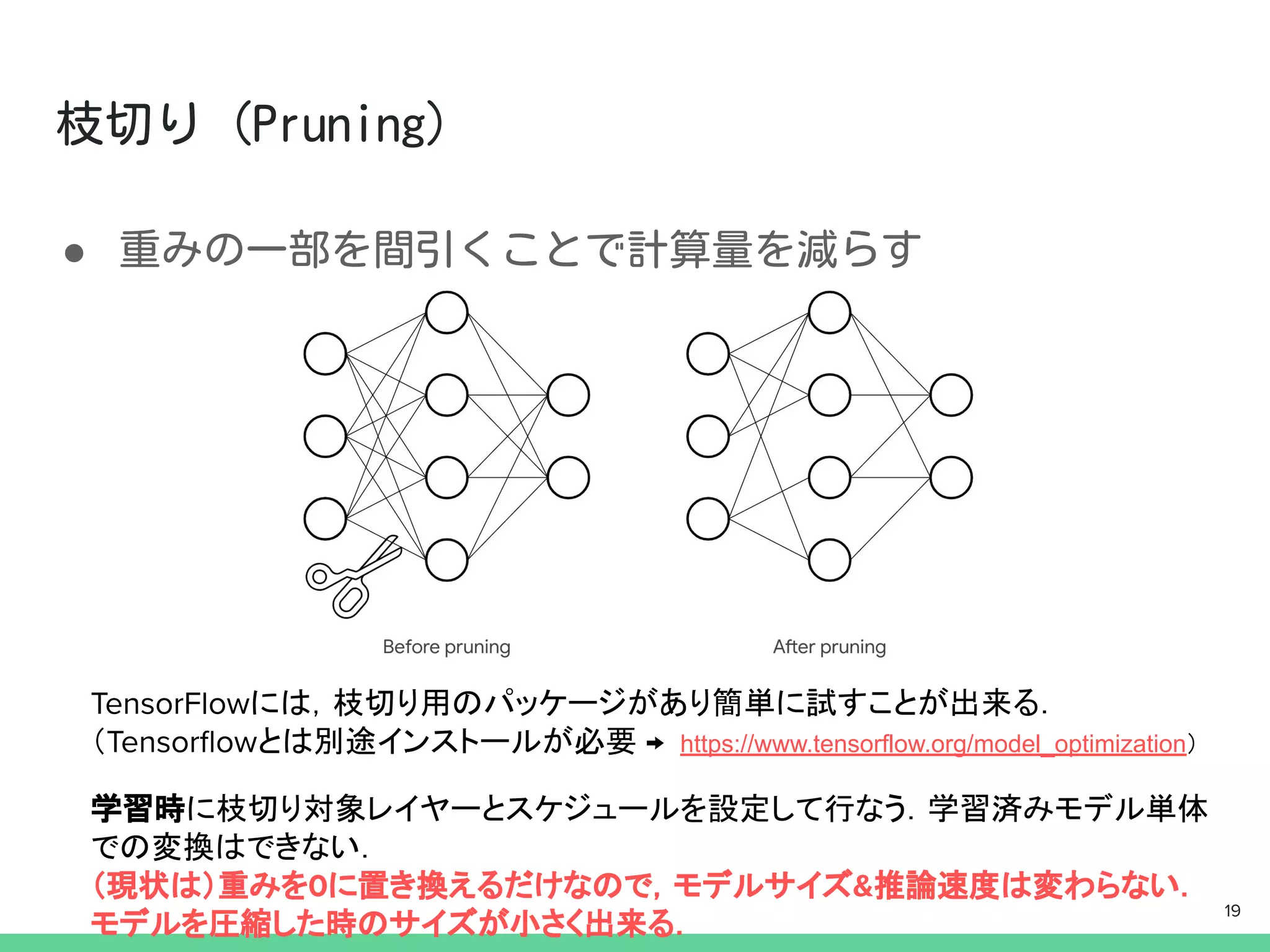
import tensorflow_model_optimization astfmot
params = {
‘pruning_schedule’: #ここでpruning_scheduleを定義
...(略)
}
model = Sequential([ #モデル定義 ...(略)])
model = tfmot.sparsity.keras.prune_low_magnitude(model,
**param)
model.compile(..略..)
callbacks = [ #コールバックに下記を追加
tfmot.sparsity.keras.UpdatePruningStep()
]
model.fit(...(略), callbacks=callbacks)
詳しくは→https://www.tensorflow.org/model_optimization 20
- 21.
- 22.
- 23.
- 24.
- 25.
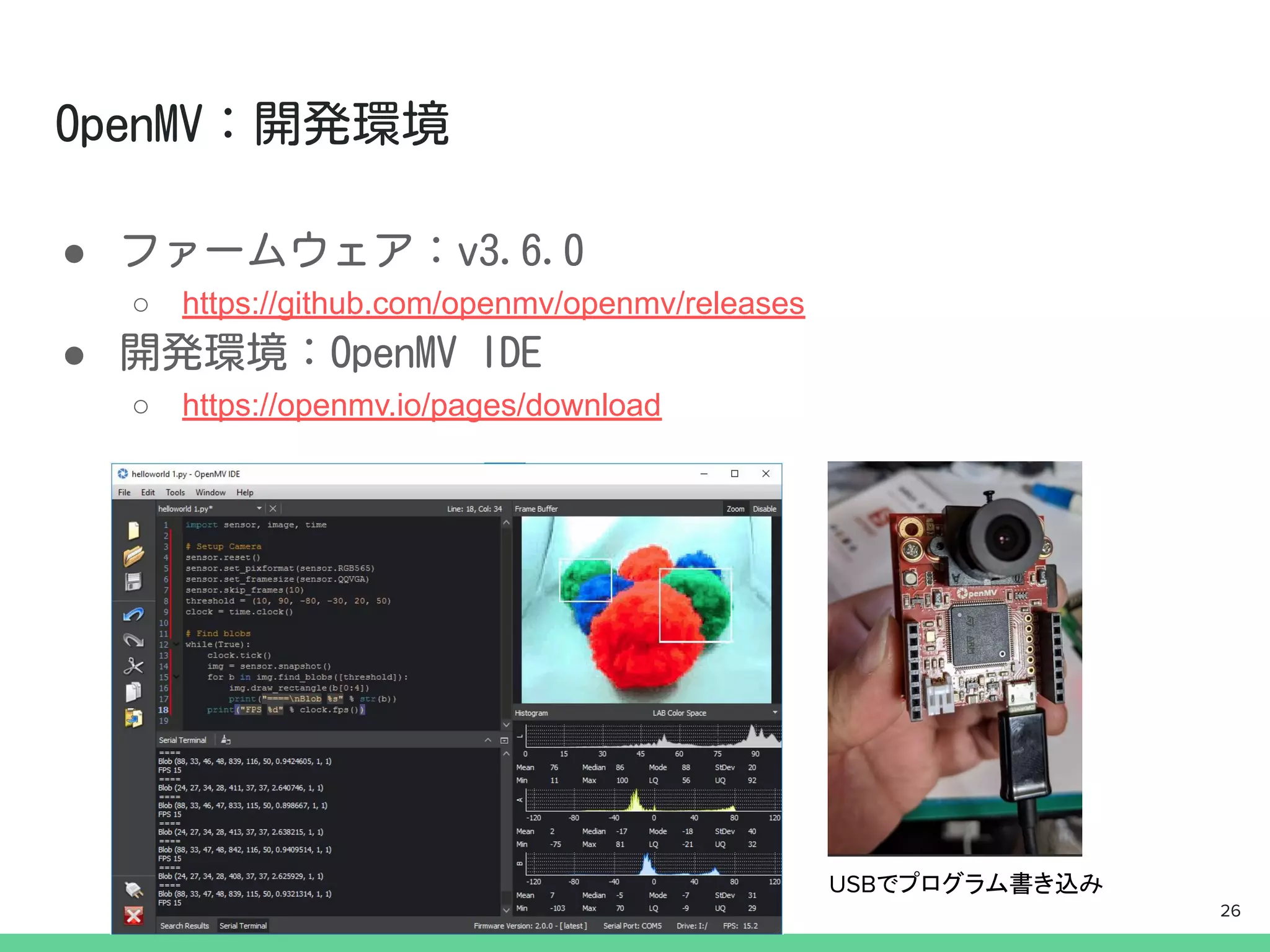
SoC : STM32H743VI
(CPUARM Cortex M7 32bit 480MHz)
(RAM 1MB , FlashROM 2MB)
カメラ:OV7725 (max 640x480)
SDカード:μSDスロットあり30GBまで
消費電力:110mA〜170mA@3.3V
特徴:
オープンソースのファームウェア上でMicroPythonが動
く.pythonヒープ領域が230KBぐらいしか使えない・・・
SoC : Kendryte K210
(CPU RISC-V 64bit 400-800MHz)
(RAM 8MB, FlashROM 16MB)
(KPU : CNNアクセラレータ)
カメラ:OV2640/OV7740
SDカード:μSDスロットあり
消費電力:>600mA@5V?
特徴:
コスパかなり良い.RISC-Vだからか?
畳み込みや活性化関数などのアルゴリズムがハード実装
されている.ただ,いろいろ制約あり.
https://openmv.io/collections/cams/products/openmv-
cam-h7
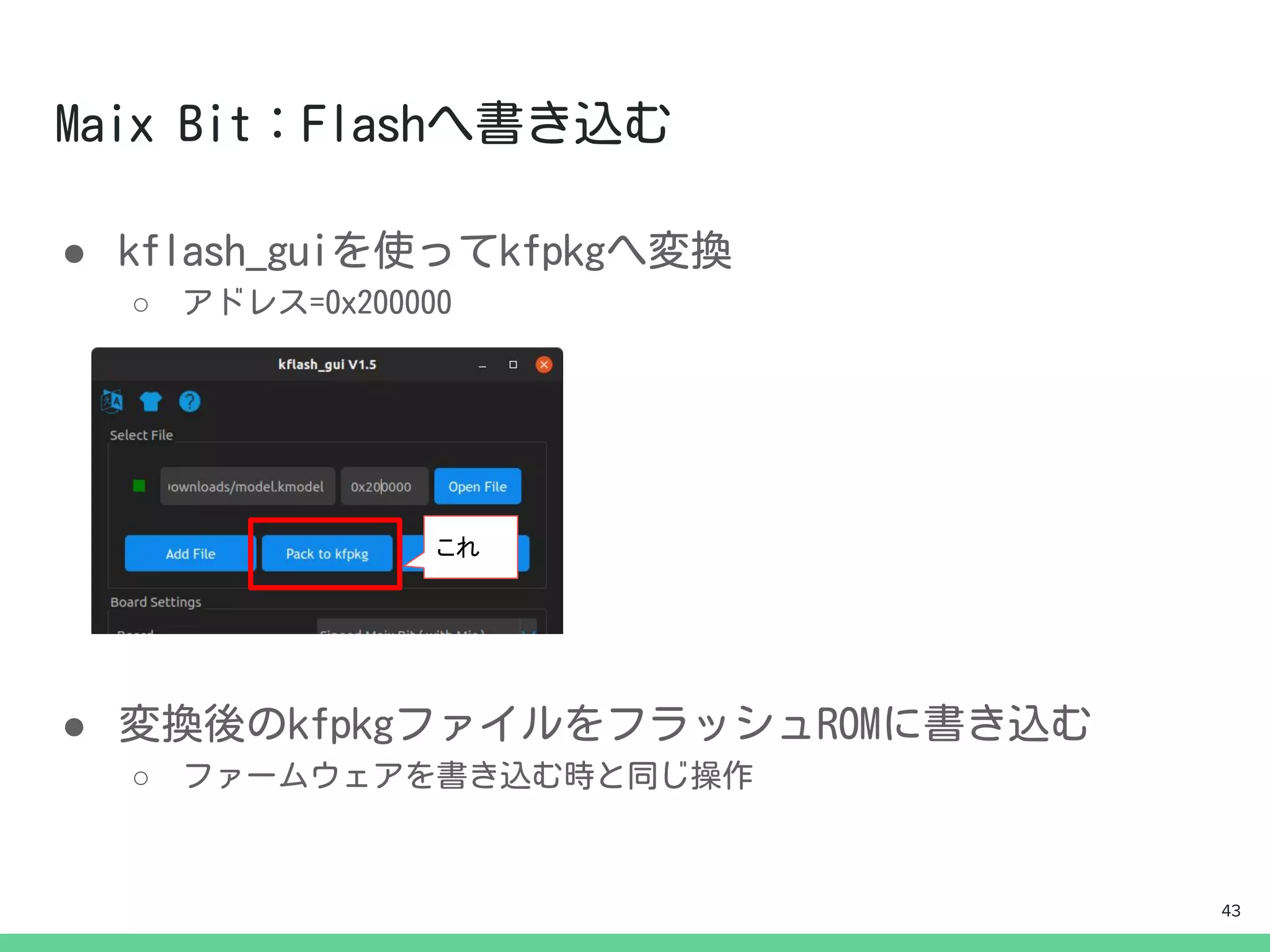
https://wiki.sipeed.com/en/maix/board/bit.html
25
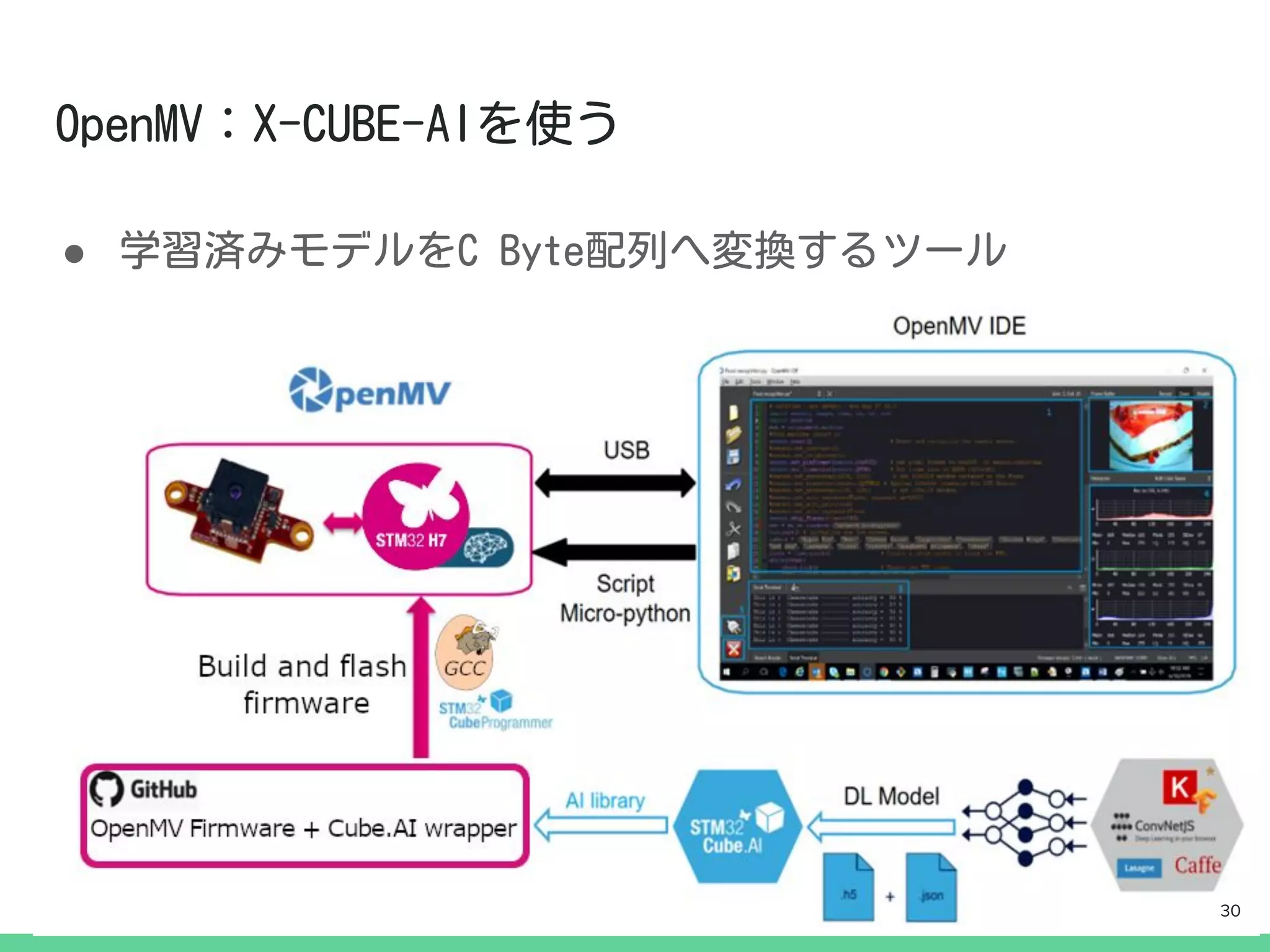
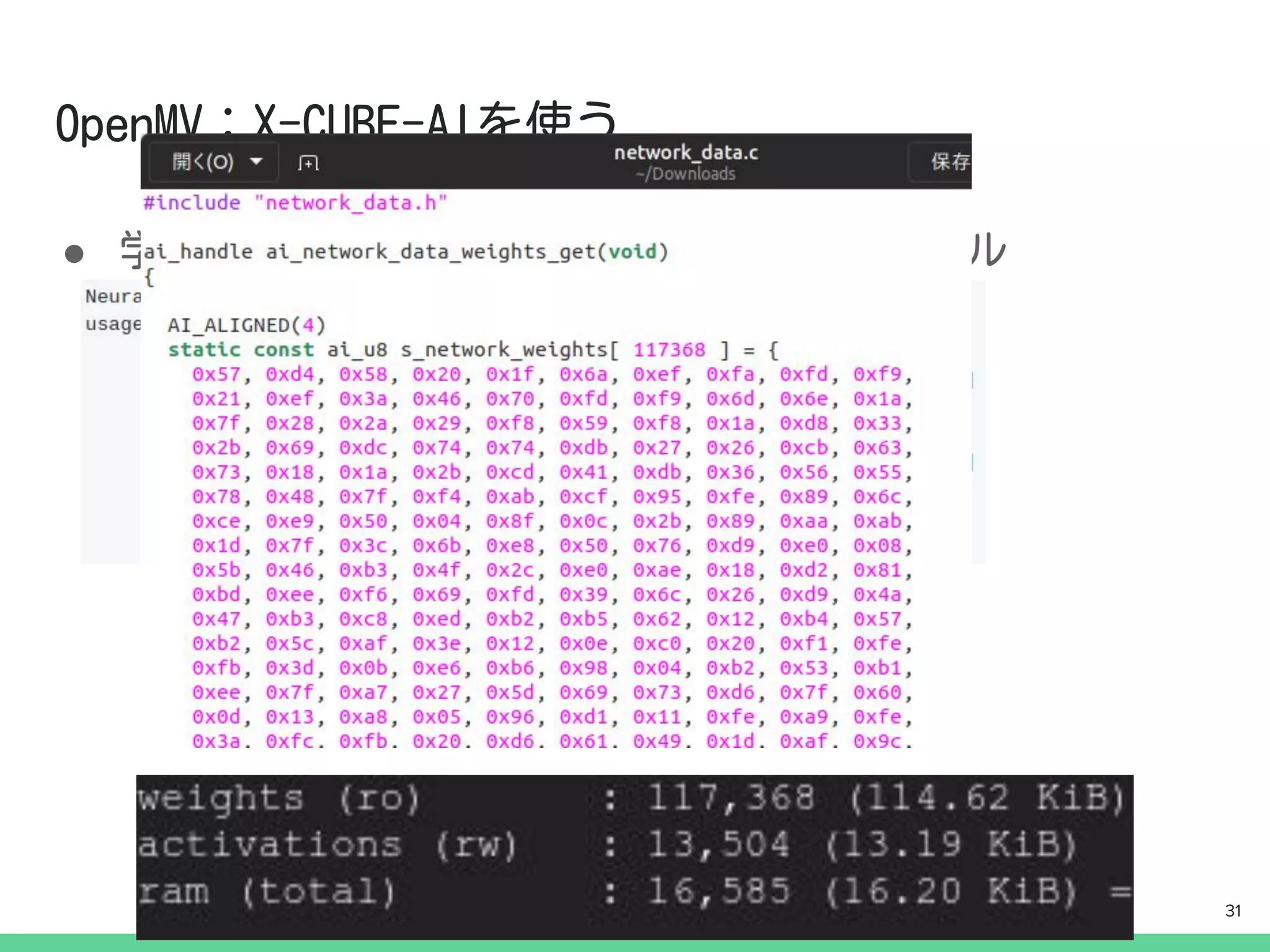
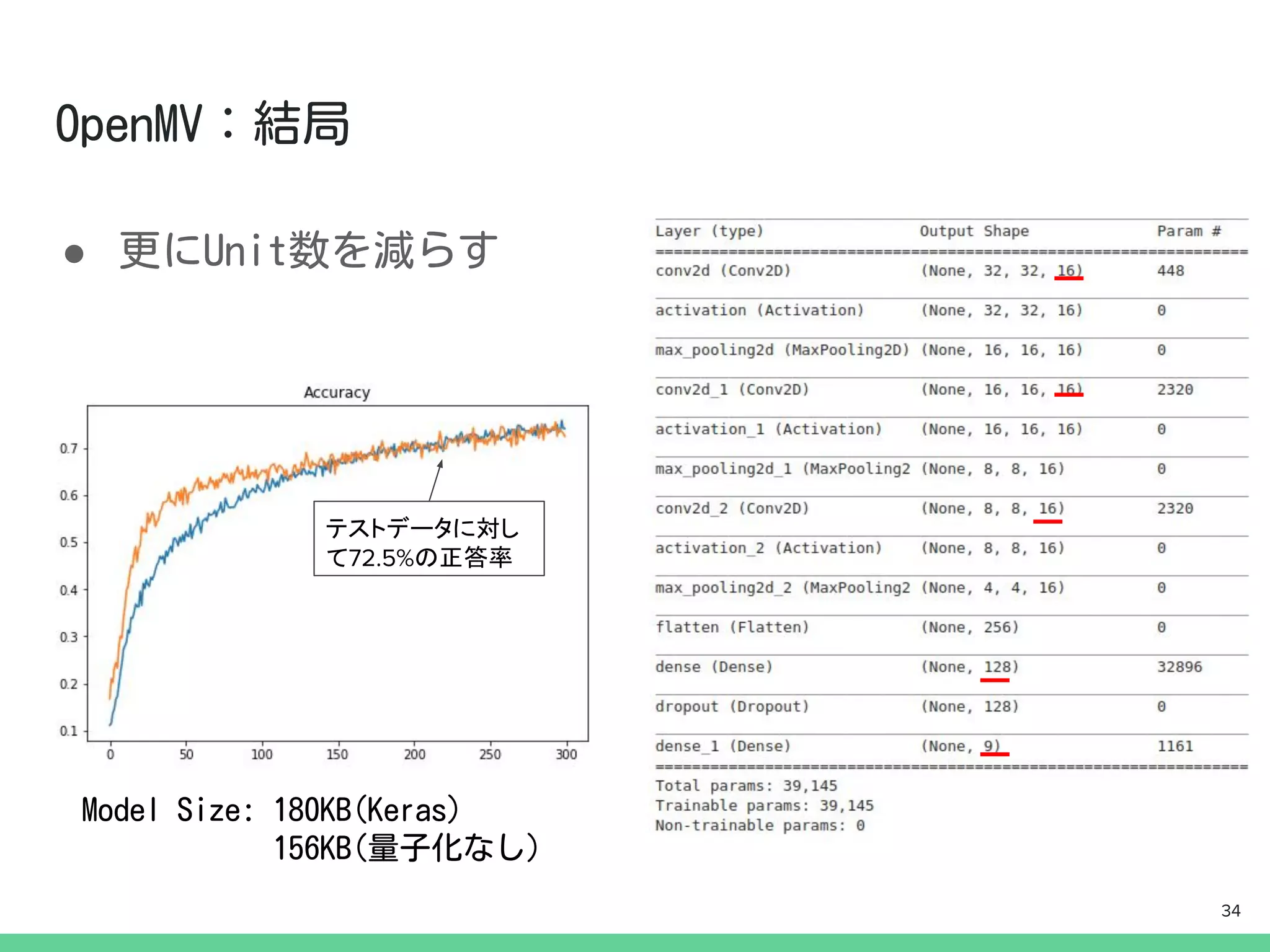
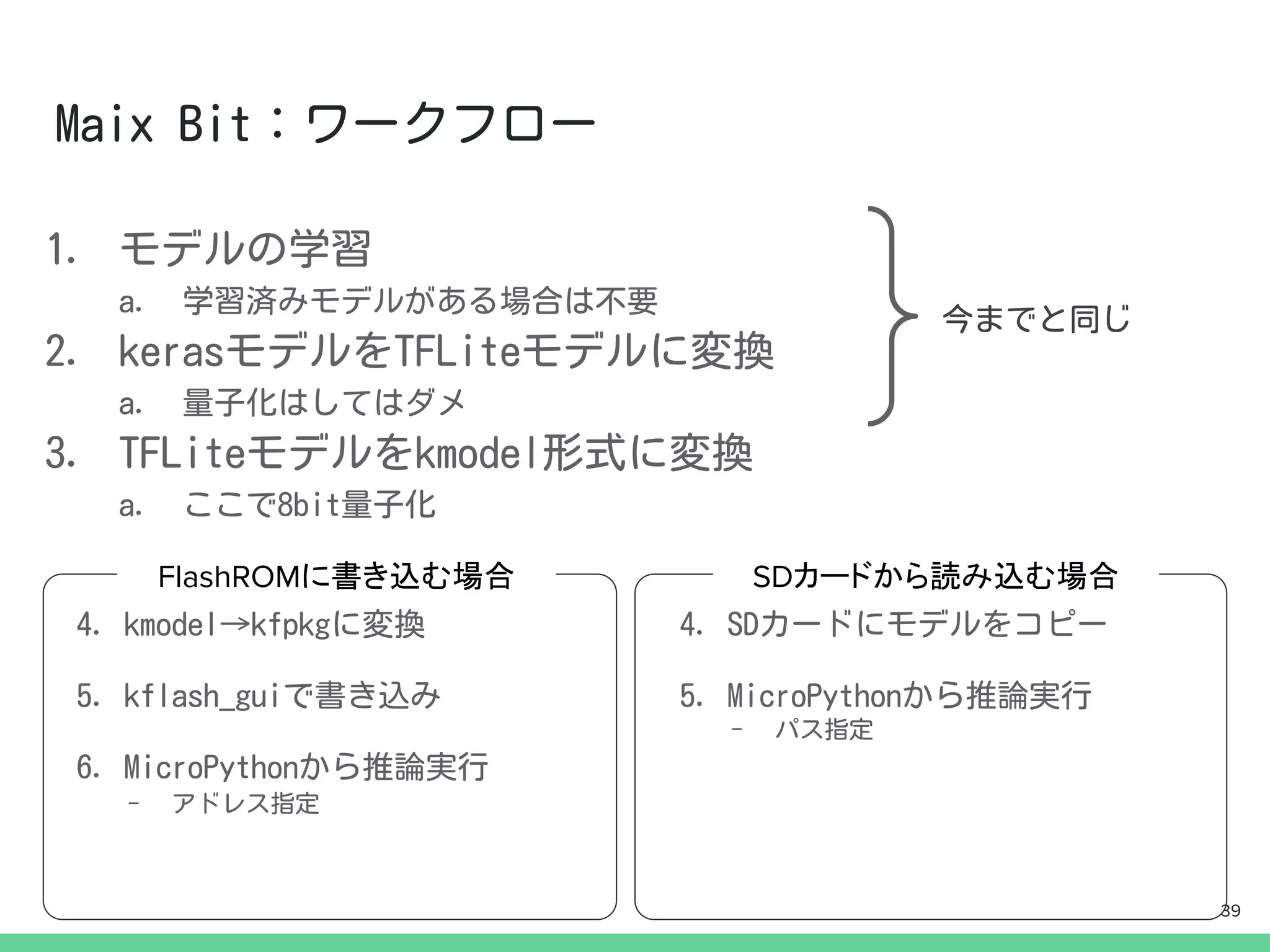
一般的にカメラにはイメージセンサ制御のための
マイコンが搭載されています.
今回は,そのマイコンの上でディープ・ラーニング
の推論も動かしてしまおうという試みです.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
●
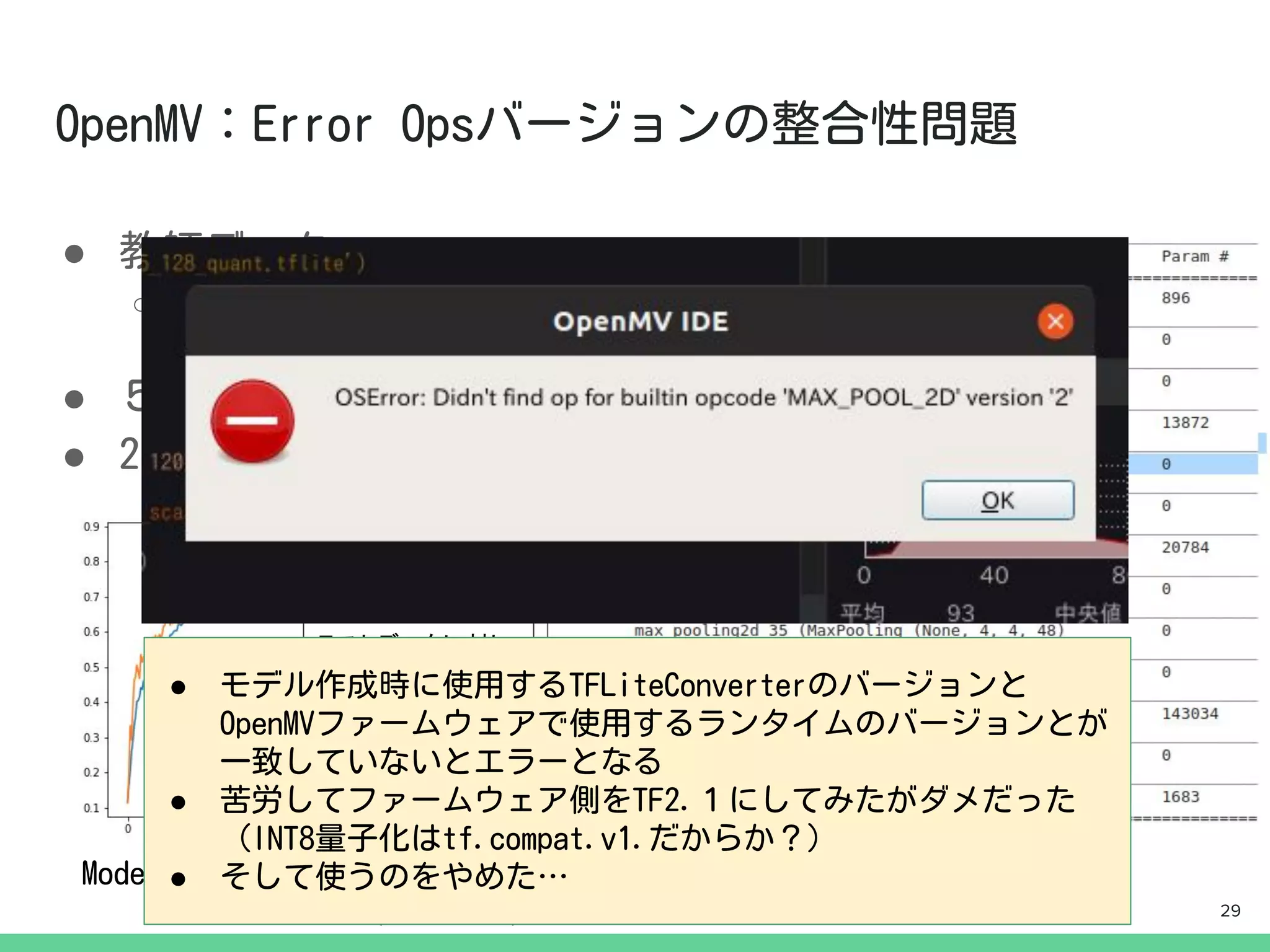
import KPU askpu
task = kpu.load(0x200000)
img = img.resize(INPUT_SIZE, INPUT_SIZE)
img.pix_to_ai()
fmap = kpu.forward(task, img)
plist = fmap[:]
pred = plist.index(max(plist))
現時点でドキュメントには
載ってないがこれでリサ
イズできる
現時点でドキュメントには
載ってないおまじない.
(RBG565->RBG888に
変換してるぽい)
44
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
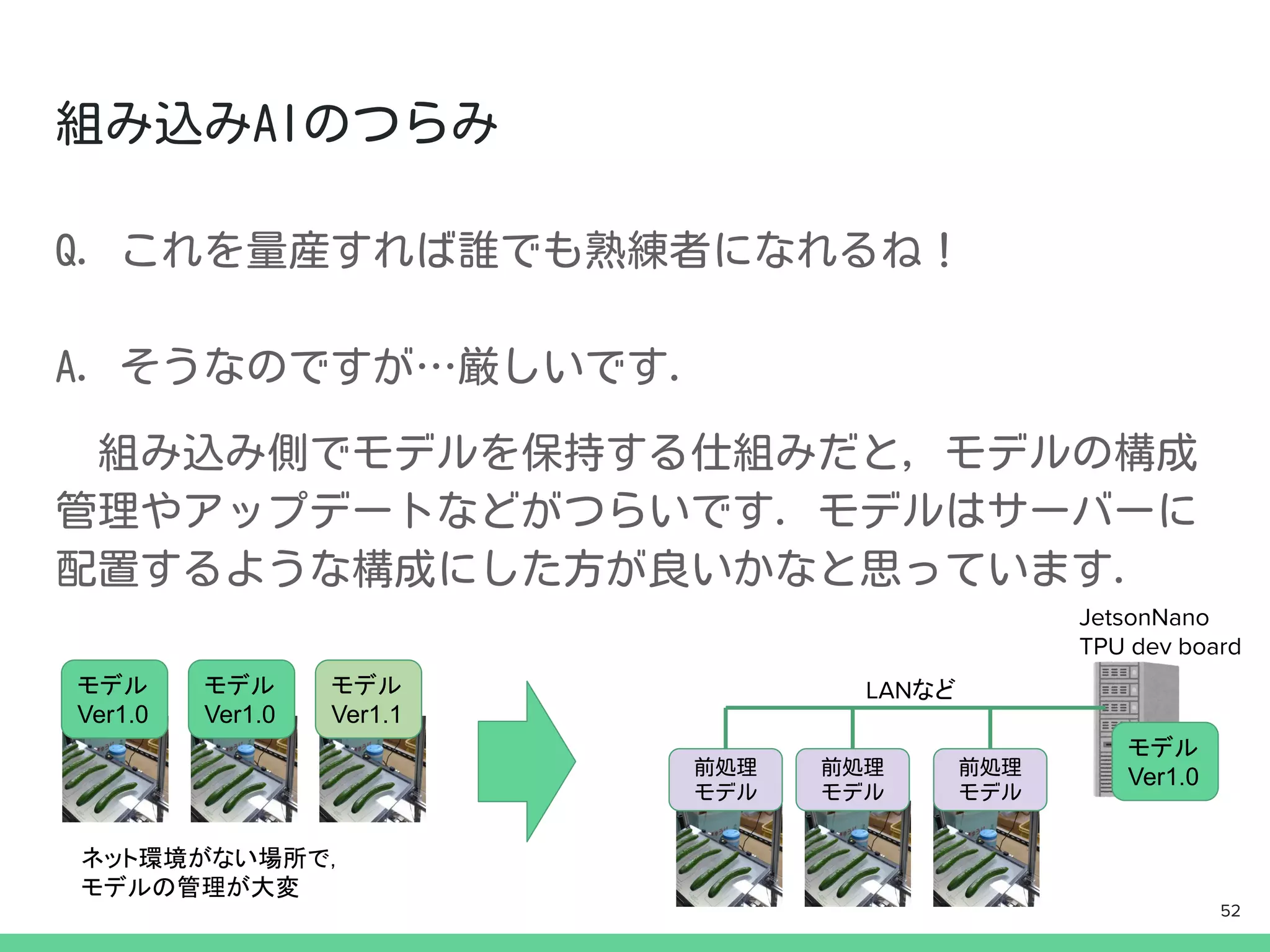
- 51.
- 52.
- 53.
- 54.
- 55.










![詳しくは
→https://www.tensorflow.org/lite/performance/post_training_quantization
from tensorflow.lite import TFLiteConverter, Optimize
#KerasModelからの変換 + Weight Quantization
converter = TFLiteConverter.from_keras_model(model)
converter.optimizations = [Optimize.OPTIMIZE_FOR_SIZE] #これ
tflite_model = converter.convert()
16](https://image.slidesharecdn.com/tfl-200229031012/75/TensorFlow-Lite-16-2048.jpg)
![量子化なし Weight
Quantization
Full Integer
Quantization
mobilenet Size[MB] 17.0 4.1 4.5
Speed[ms] 285.7 555.5 263.2
mnist
※Dense2層
※極小NN
Size[MB] 0.4 0.1 0.1
Speed[ms] 0.83 0.12 0.14
モデル量子化によるモデルサイズと平均推論速度
17](https://image.slidesharecdn.com/tfl-200229031012/75/TensorFlow-Lite-17-2048.jpg)
![量子化なし Weight
Quantization
Full Integer
Quantization
mobilenet Size[MB] 17.0 4.1 4.5
Speed[ms] 285.7 555.5 263.2
mnist Size[MB] 0.4 0.1 0.1
Speed[ms] 0.83 0.12 0.14
モデル量子化によるモデルサイズと平均推論速度
● モデルサイズ縮小に効果大
● 推論速度はよくわからない
○ 実行環境のRAM容量による?
○ モデルのアーキテクチャによる?
● 【補足】Accuracyの低下はほぼ無かった 18](https://image.slidesharecdn.com/tfl-200229031012/75/TensorFlow-Lite-18-2048.jpg)
![import tensorflow_model_optimization as tfmot
params = {
‘pruning_schedule’: #ここでpruning_scheduleを定義
...(略)
}
model = Sequential([ #モデル定義 ...(略)])
model = tfmot.sparsity.keras.prune_low_magnitude(model,
**param)
model.compile(..略..)
callbacks = [ #コールバックに下記を追加
tfmot.sparsity.keras.UpdatePruningStep()
]
model.fit(...(略), callbacks=callbacks)
詳しくは→https://www.tensorflow.org/model_optimization 20](https://image.slidesharecdn.com/tfl-200229031012/75/TensorFlow-Lite-20-2048.jpg)
![枝切り
なし
枝切り
50%
枝切り
80%
キュウリ
CNN
File Size[MB]
*
(圧縮率)
0.84
(100%)
0.64
(76.2%)
0.35
(41.2%)
Accuracy[%] 82.2 82.0 76.6
Speed[ms] 41.7 40.0 48.7
枝切りによる圧縮ファイルサイズ,正答率,平均推論速度
*:
weight quantization +
zip圧縮したサイズ
通常のtfliteファイルサ
イズは4.8MB 21](https://image.slidesharecdn.com/tfl-200229031012/75/TensorFlow-Lite-21-2048.jpg)












![●
○
○
●
○
○
■ https://github.com/kendryte/nncase/blob/master/docs/tflite_ops.md
■ (v0.1.0-rc5)https://github.com/kendryte/nncase/tree/v0.1.0-rc5
Maix_Toolbox(nncase v0.1.0-rc5)の場合
[Maix Toolbox使用]
nncase v0.1.0-rc5 nncase v0.2.0 Beta2
量子化なし 8bit量子化 量子化なし 8bit量子化
[TF2.1]
TFLiteConverter
量子化なしモデル
○:推論実行可能 ✕: MaixPyファームウェアv0.5.0では実行できない
41](https://image.slidesharecdn.com/tfl-200229031012/75/TensorFlow-Lite-41-2048.jpg)

![●
import KPU as kpu
task = kpu.load(0x200000)
img = img.resize(INPUT_SIZE, INPUT_SIZE)
img.pix_to_ai()
fmap = kpu.forward(task, img)
plist = fmap[:]
pred = plist.index(max(plist))
現時点でドキュメントには
載ってないがこれでリサ
イズできる
現時点でドキュメントには
載ってないおまじない.
(RBG565->RBG888に
変換してるぽい)
44](https://image.slidesharecdn.com/tfl-200229031012/75/TensorFlow-Lite-44-2048.jpg)