




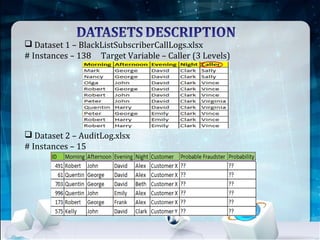


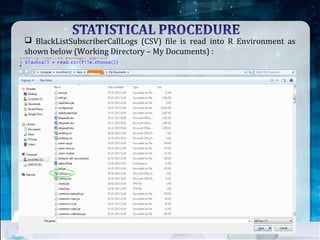
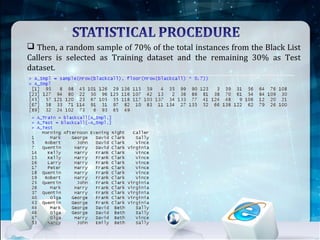





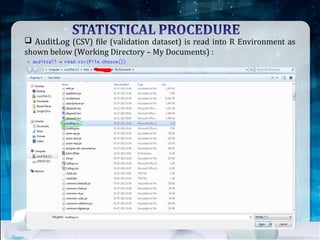

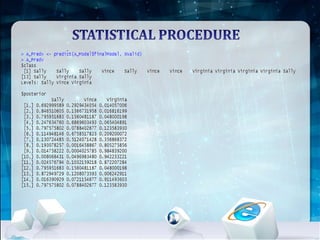

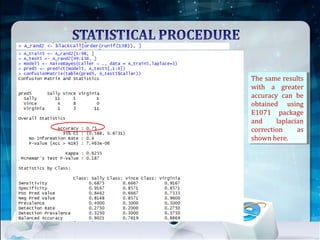


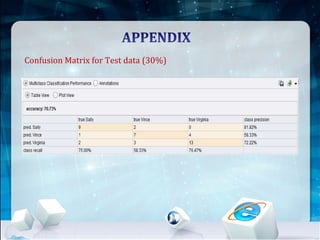
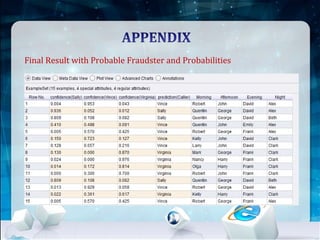


This document discusses using Naive Bayes classification to detect subscription fraud at a telecom company. It analyzes call detail records from known fraudsters to build a model to predict fraudulent subscribers. The model is trained on 70% of records from 3 known fraudsters and tested on 30% of records. It then uses the model to analyze an audit log of 15 subscribers and predicts which subscribers are most likely to be the known fraudsters Sally, Virginia or Vince, along with the probabilities. The document outlines the datasets, tools used including R and various R packages, data preprocessing steps, model building process using 10-fold cross validation, performance evaluation on test data and using the model to analyze the audit log dataset.
























![[IJET V2I5P15] Authors: V.Preethi, G.Velmayil](https://cdn.slidesharecdn.com/ss_thumbnails/ijet-v2i5p15-161107143444-thumbnail.jpg?width=640&height=640&fit=bounds)


























![PYTHON PROJECT[1] Online Fraud Fraud Detection Cybersecurity Anomaly Detec...](https://cdn.slidesharecdn.com/ss_thumbnails/pythonproject1-250421141954-bd5cebfc-thumbnail.jpg?width=640&height=640&fit=bounds)






























![[DSC Europe 25] Andrzej Kowalczyk - AI - how to start small and grow in the f...](https://cdn.slidesharecdn.com/ss_thumbnails/oy1zmo94qv6vpcqjvno2-andrzej-kowalczyk-ai-how-to-start-small-and-grow-in-the-future-1-260119121559-cf093b23-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Elena Menshikova - AI-Powered Operational Excellence: Revolut...](https://cdn.slidesharecdn.com/ss_thumbnails/es6nholbqy3zaao2c2yd-2-elena-menshikova-data-ai-in-decision-making-260115093812-4fba8b38-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Bojan Djuricic - Predictive Design Process.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/5awdrbedqdek3gqu2ezy-4-the-predictive-design-bojan-djuricic-260120105856-6c399e9b-thumbnail.jpg?width=640&height=640&fit=bounds)