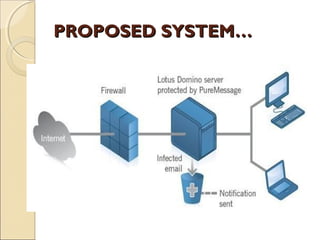
The document discusses a seminar on data leakage detection, focusing on the challenges faced by data distributors when sharing sensitive information with third parties. It proposes innovative data allocation strategies and techniques to identify and assess the likelihood of data leaks without altering the original data. The proposed system aims to improve detection mechanisms and develop algorithms for distributing data effectively to mitigate leakage risks.