








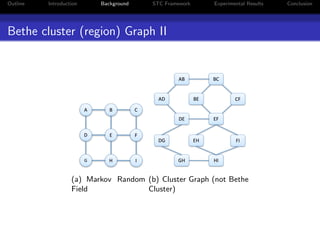
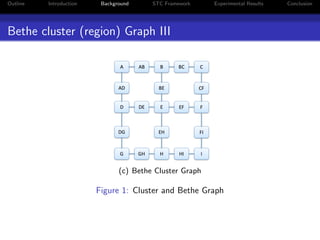

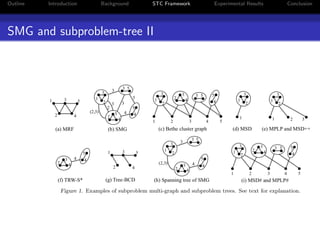











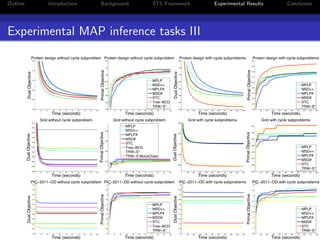


The document presents a unified approach to max-product message passing through the subproblem-tree calibration (STC) algorithm, which aims to improve MAP inference for Markov Random Fields (MRFs). By employing a flexible dual-decomposition strategy, the algorithm can achieve dual-optimality for various configurations of subproblem trees, subsuming existing algorithms like MPLP, MSD, and TRW-S. Experimental results demonstrate the effectiveness of STC across multiple benchmark tasks, highlighting its adaptability in message passing method design.










































































