Downloaded 39 times





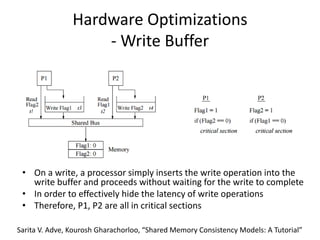
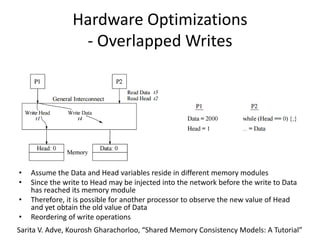
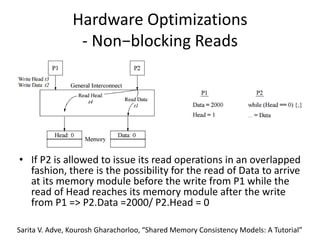





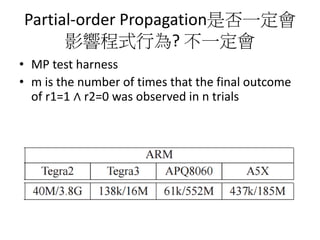
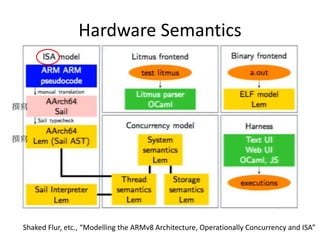





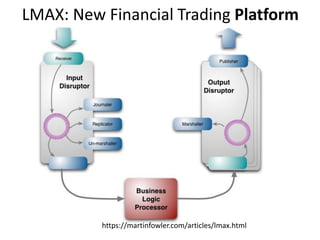
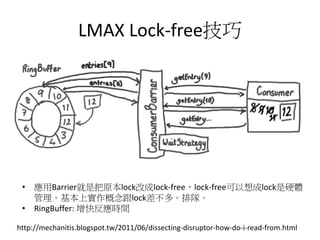

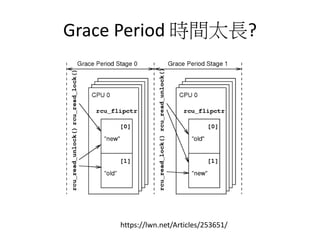
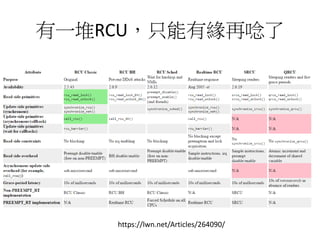
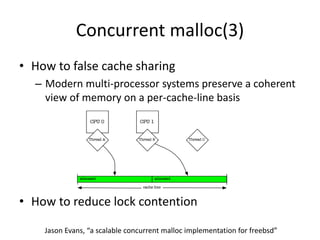

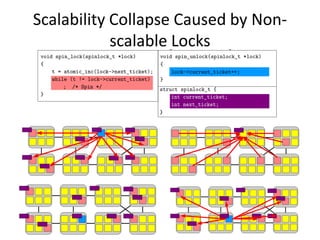












This document discusses challenges in writing concurrent programs and provides examples of concurrency techniques. It explains that hardware and compiler optimizations can result in unexpected program behaviors. It then describes memory model definitions, performance patterns like LMAX and RCU, and security issues such as timing side-channel attacks using Intel TSX. The goal is to understand how to write correct and efficient concurrent code despite relaxed memory consistency models.



















![[OpenStack Days Korea 2016] Track1 - All flash CEPH 구성 및 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/12skt-160226171513-thumbnail.jpg?width=640&height=640&fit=bounds)































![[若渴] A preliminary study on attacks against consensus in bitcoin](https://cdn.slidesharecdn.com/ss_thumbnails/apreliminarystudyonattacksagainstconsensusinbitcoin-180422134755-thumbnail.jpg?width=640&height=640&fit=bounds)
![[RAT資安小聚] Study on Automatically Evading Malware Detection](https://cdn.slidesharecdn.com/ss_thumbnails/automaticallyevadingmalwaredetection-180325081451-thumbnail.jpg?width=640&height=640&fit=bounds)
![[若渴] Preliminary Study on Design and Exploitation of Trustzone](https://cdn.slidesharecdn.com/ss_thumbnails/preliminarystudyondesignandexploitationoftrustzone-180324121935-thumbnail.jpg?width=640&height=640&fit=bounds)
![[若渴]Study on Side Channel Attacks and Countermeasures](https://cdn.slidesharecdn.com/ss_thumbnails/studyonsidechannelattacksandcountermeasures-180120164619-thumbnail.jpg?width=640&height=640&fit=bounds)
![[若渴計畫] Challenges and Solutions of Window Remote Shellcode](https://cdn.slidesharecdn.com/ss_thumbnails/challengesandsolutionsofwindowremoteshellcode-171118141605-thumbnail.jpg?width=640&height=640&fit=bounds)
![[若渴計畫] Introduction: Formal Verification for Code](https://cdn.slidesharecdn.com/ss_thumbnails/backgroudformalverificationforsystemcode-170714081746-thumbnail.jpg?width=640&height=640&fit=bounds)
![[若渴計畫] Studying ASLR^cache](https://cdn.slidesharecdn.com/ss_thumbnails/studyingaslrcache-170416163739-thumbnail.jpg?width=640&height=640&fit=bounds)
![[若渴計畫] Black Hat 2017之過去閱讀相關整理](https://cdn.slidesharecdn.com/ss_thumbnails/blackhat2017-170416150012-thumbnail.jpg?width=640&height=640&fit=bounds)

![[若渴計畫2015.8.18] SMACK](https://cdn.slidesharecdn.com/ss_thumbnails/smack-150723041910-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[SITCON2015] 自己的異質多核心平台自己幹](https://cdn.slidesharecdn.com/ss_thumbnails/random-150306082537-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[MOSUT20150131] Linux Runs on SoCKit Board with the GPGPU](https://cdn.slidesharecdn.com/ss_thumbnails/linuxrunsonsockitboardwiththegpgpu-150127112230-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[若渴計畫]由GPU硬體概念到coding CUDA](https://cdn.slidesharecdn.com/ss_thumbnails/mosutgpucodingcuda-140606072846-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[若渴計畫]64-bit Linux Return-Oriented Programming](https://cdn.slidesharecdn.com/ss_thumbnails/learnrop-140405071626-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[MOSUT] Format String Attacks](https://cdn.slidesharecdn.com/ss_thumbnails/aj-140116200425-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



















