Download as PDF, PPTX


















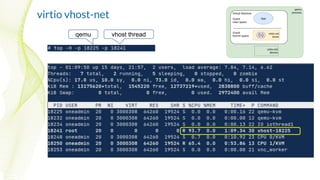
![virtio vhost-net
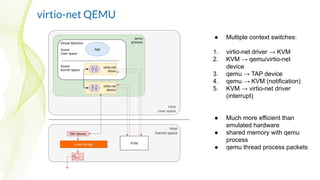
● Two context switches
(optional):
1. virtio-net driver → KVM
2. KVM → virtio-net driver
(interrupt)
● shared memory with the host
kernel (vhost protocol)
● Allows Linux Bridge Zero
Copy
● qemu / virtio-net device is on
the control path only
● kernel thread [vhost] process
packets](https://image.slidesharecdn.com/achievingtheultimateperformancewithkvm2020-10-07-201006171104/85/Achieving-the-Ultimate-Performance-with-KVM-22-320.jpg)






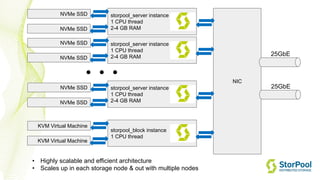

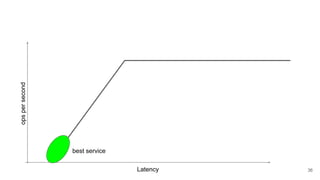
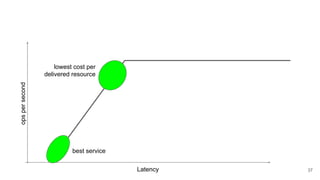
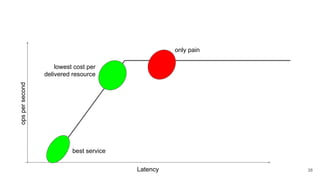
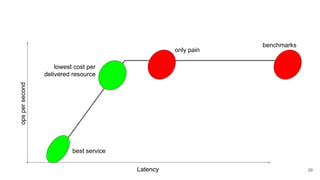
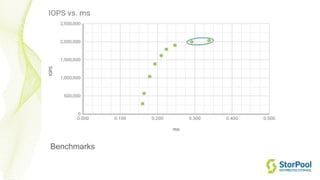
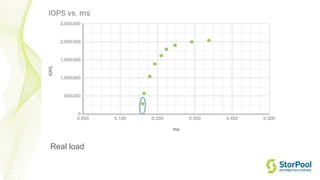
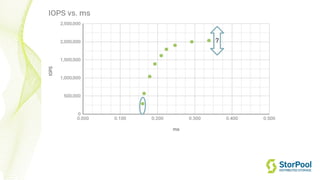
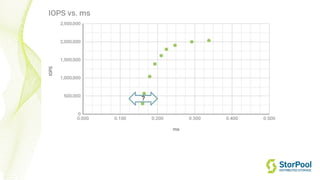



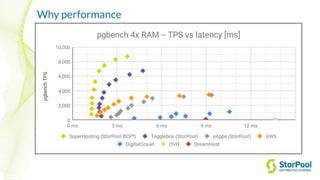

The webinar by Venko Moyankov focuses on achieving optimal performance with KVM and addresses various aspects of hardware, compute, networking, and storage for virtualization. Key topics include CPU and memory optimization, networking efficiencies, and the importance of performance benchmarks. The presentation emphasizes practical strategies for improving application performance and cost-effectiveness in cloud environments.















































![Thu 430pm solarflare_tolley_v1[1]](https://cdn.slidesharecdn.com/ss_thumbnails/thu430pmsolarflaretolleyv11-130618183538-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)




























![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)










