Download to read offline




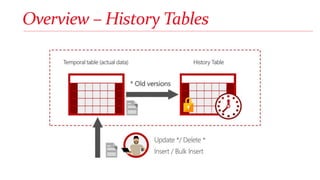
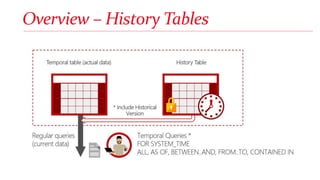


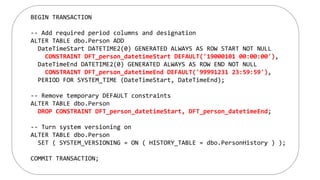













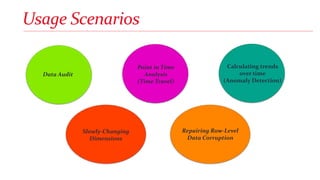





Arthur Luz is a data insights consultant at Microsoft who gave a presentation on SQL Server 2016 temporal tables. The presentation included an overview of history tables, demonstrations of creating temporal tables and manipulating historical data, considerations for using temporal tables regarding resources, and differences between change data capture and temporal tables. New features for temporal tables include support for in-memory tables which allow for hybrid transactional/analytical processing scenarios.















































































