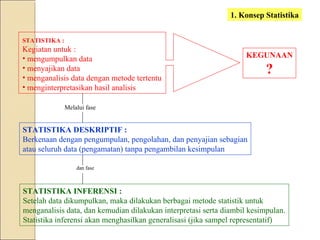
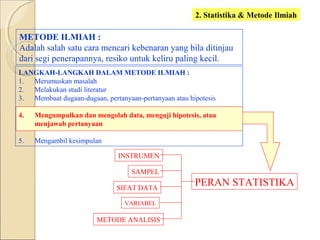
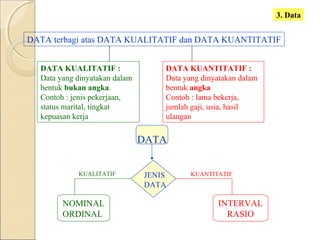
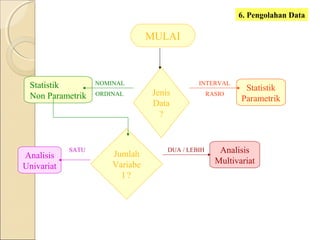
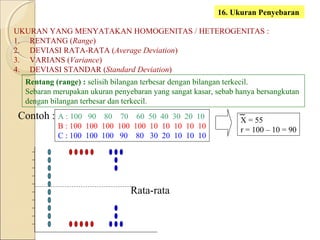
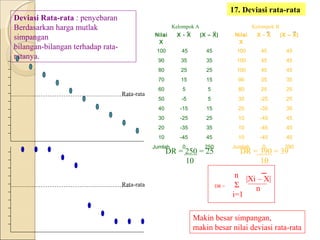
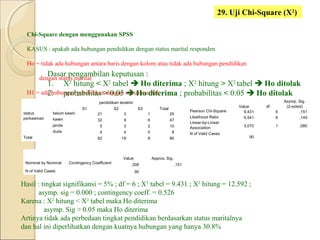
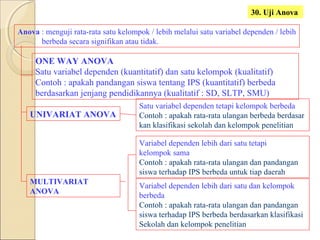
Dokumen ini menjelaskan statistik dasar, termasuk perbedaan antara statistik parametrik dan non-parametrik, serta teknik analisis data yang terkait. Selain itu, dibahas jenis data, metode pengolahan, dan pengujian hipotesis untuk menganalisis dan menginterpretasikan data. Contoh-contoh yang diberikan menjelaskan konsep seperti analisis univariat dan bivariat, serta ukuran penyebaran dan pengujian normalitas.