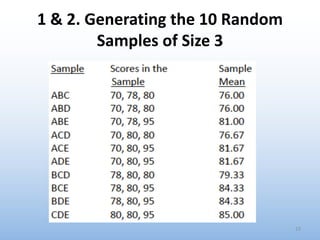
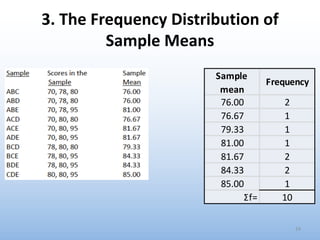
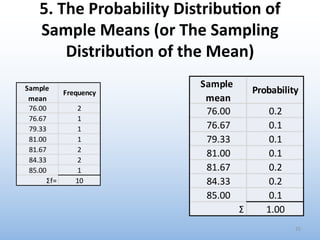
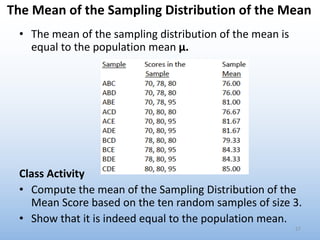
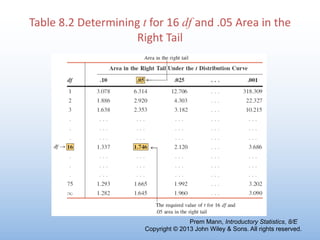
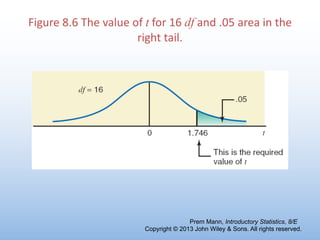
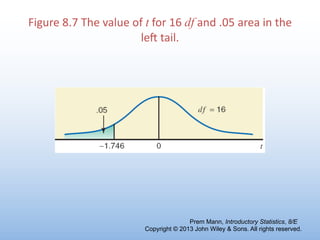
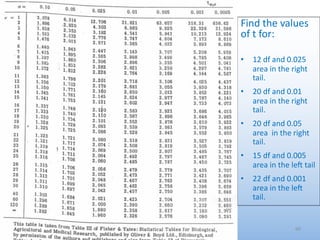
The document provides an overview of key concepts related to estimation in statistics, including:
- Estimation involves using sample data to estimate unknown population parameters. Common estimators include the sample mean, proportion, and standard deviation.
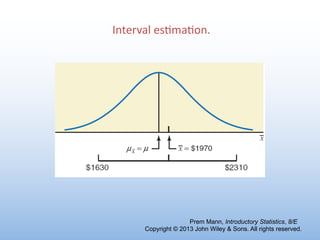
- There are two main types of estimates - point estimates and interval estimates. Point estimates are single values while interval estimates specify a range.
- The process of estimation involves identifying the parameter, selecting a random sample, choosing an estimator, and calculating the estimate.
- Estimates can differ from the true population value due to sampling error and non-sampling error. Bias occurs when the expected value of the estimate differs from the true parameter value.






![THE ESTIMATION PROCESS
1. Iden'fy the Unknown Popula'on Parameter
2. Decide on the Size of the Random Sample: n
3. Select the Random Sample of Size n
4. Choose an Appropriate Sample Sta's'c [Es#mator]
5. Subs'tute the Sample Data into the Sample Sta's'c
6. Calculate the es'mate and interpret
7](https://image.slidesharecdn.com/lr9estimation-231027221113-f8fdf5bb/85/LR-9-Estimation-pdf-7-320.jpg)