Downloaded 31 times




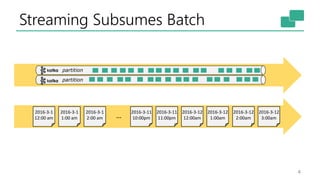
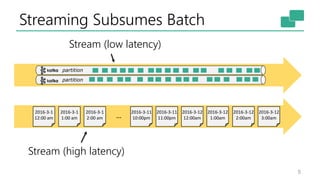
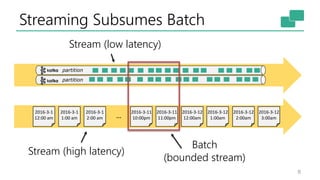
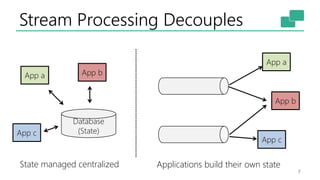
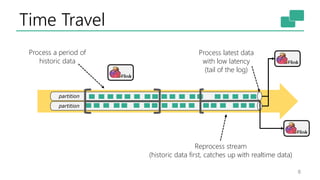
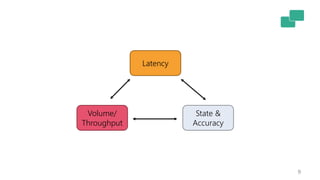
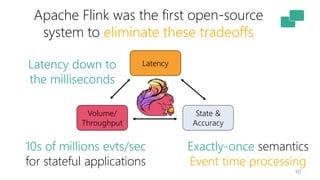
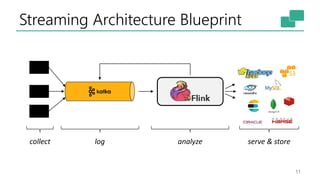
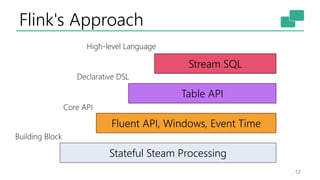
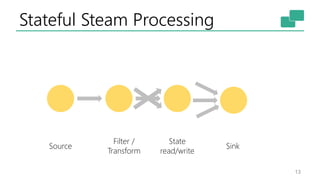
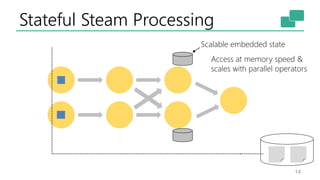
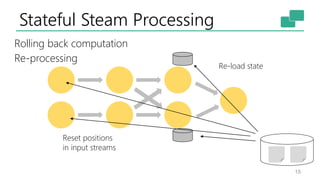
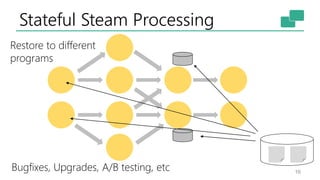
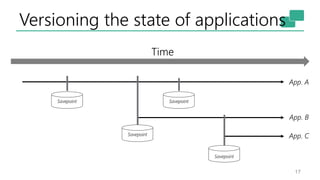
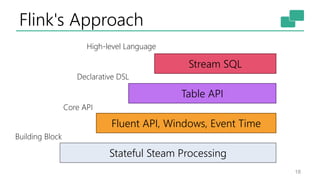
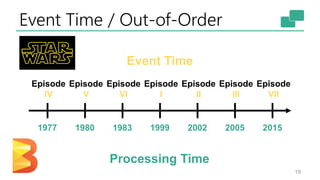
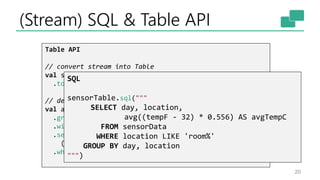

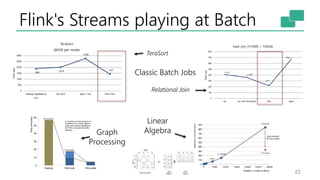

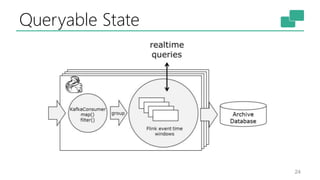
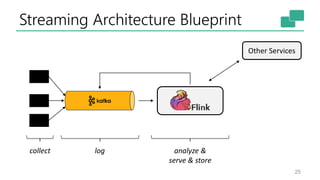

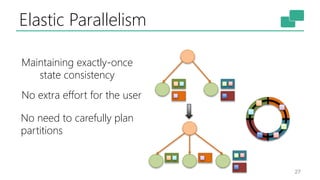



The document discusses Apache Flink's approach to stream processing, emphasizing its capability for continuous data handling and elimination of trade-offs commonly faced in stateful applications. It outlines key features such as exactly-once semantics, event time processing, and a fluent API for building stateful applications while maintaining high throughput and low latency. Additionally, it highlights Flink's architecture and performance metrics, showcasing its daily processing capabilities across various use cases.
































































































