論文情報
タイトル
Stacked Semantic-Guided AttentionModel for Fine-
Grained Zero-Shot Learning
著者
Ji, Zhong and Fu, Yanwei and Guo, Jichang and Pang,
Yanwei and Zhang, Zhongfei
出典
Advances in Neural Information Processing Systems 2018
概要
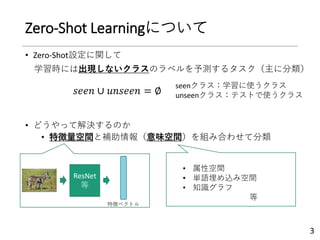
Zero-Shot Learningにおける画像の局所領域へ重み付け
するためのattention map生成手法の提案
2
①
②
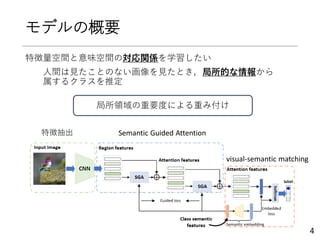
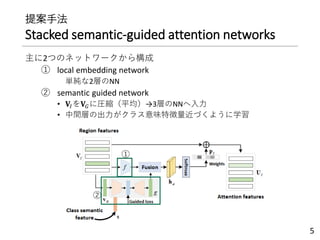
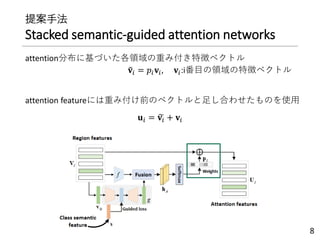
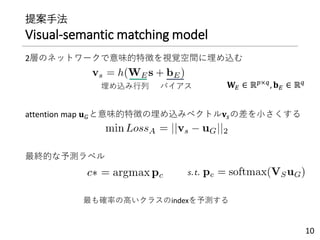
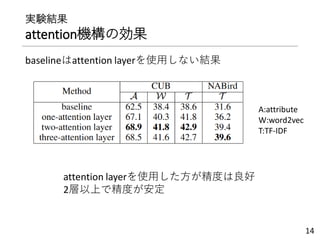
提案手法
Stacked semantic-guided attentionnetworks
主に2つのネットワークから構成
① local embedding network
単純な2層のNN
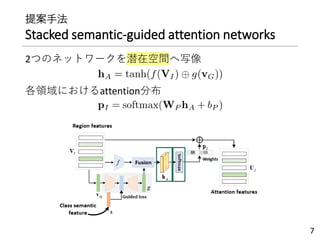
② semantic guided network
• 𝐕𝐼を𝐕𝐺に圧縮(平均)→3層のNNへ入力
• 中間層の出力がクラス意味特徴量近づくように学習
5





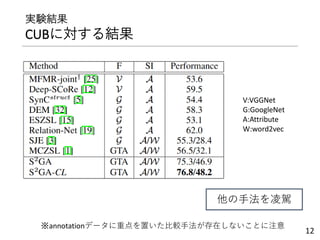
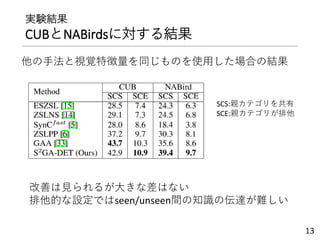
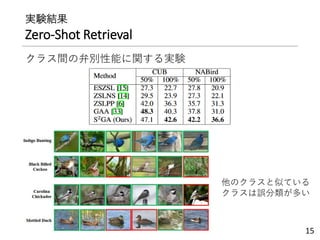
![実験設定
• データセットはCUBとNABirdsの2種類
• 鳥類のデータセット
• 属性,局所領域へのアノテーションつき
• 局所領域へのアノテーション(7属性分(NABirdsは6属性))
画像特徴量の扱い方で2種類
• GTA(Grand-Truthを使用)
• DET(SPDA-CNNフレームワーク[1])
• クラス意味特徴量
• 属性を使用
• Word2vec,TF-IDFでも実験
次元数はPCAである程度の大きさに削減
11
[1]:Zhang, Han, et al. "Spda-cnn: Unifying semantic part detection and abstraction for
fine-grained recognition." Proceedings of the IEEE Conference on Computer Vision and
Pattern Recognition. 2016.](https://image.slidesharecdn.com/stackedsemantic-guidedattentionmodelforfine-grainedzero-shotlearning-201203144329/85/Stacked-Semantic-Guided-Attention-Model-for-Fine-Grained-Zero-Shot-Learning-11-320.jpg)


![[DL輪読会]A Higher-Dimensional Representation for Topologically Varying Neural R...](https://cdn.slidesharecdn.com/ss_thumbnails/ahigher-dimensionalrepresentationfortopologicallyvaryingneuralradiancefields1-210924021911-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metr...](https://cdn.slidesharecdn.com/ss_thumbnails/181214dlpointnet-181214053349-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Meta-Learning Probabilistic Inference for Prediction](https://cdn.slidesharecdn.com/ss_thumbnails/20181214dl-181218052422-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination](https://cdn.slidesharecdn.com/ss_thumbnails/20200313furutav2-200313025657-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Graph R-CNN for Scene Graph Generation](https://cdn.slidesharecdn.com/ss_thumbnails/graphr-cnnforscenegraphgenerationkobayashi1130-181130001547-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Adversarial Learning for Zero-shot Domain Adaptation](https://cdn.slidesharecdn.com/ss_thumbnails/20200925lin-200925035639-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Object-Centric Learning with Slot Attention](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0717-200717023021-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Reasoning-RCNN: Unifying Adaptive Global Reasoning into Large-scale Ob...](https://cdn.slidesharecdn.com/ss_thumbnails/20190726-190725235641-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Dl輪読会]semi supervised learning with context-conditional generative adversari...](https://cdn.slidesharecdn.com/ss_thumbnails/dlsemi-supervisedlearningwithcontext-conditionalgenerativeadversarialnetworks-161111054049-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL Hacks]Self-Attention Generative Adversarial Networks](https://cdn.slidesharecdn.com/ss_thumbnails/self-attentiongenerativeadversarialnetworks-180730075733-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]High-Fidelity Image Generation with Fewer Labels](https://cdn.slidesharecdn.com/ss_thumbnails/190315dlseminargan-190315004124-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170728-170728025901-thumbnail.jpg?width=640&height=640&fit=bounds)