8
아파치 루씬 (ApacheLucene)
• Created by - Doug Cutting
• Written in - Java
• Apache Solr, Elasticsearch
9.
9
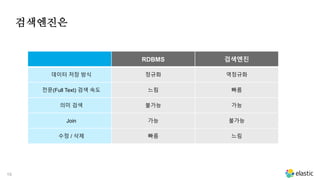
RDBMS 에서는 데이터를테이블 형태로 저장합니다.
열을 기준으로 인덱스를 만듭니다.
책의 맨 앞에 있는 제목 리스트와 같습니다.
DOC TEXT
1 The quick brown fox jumps over the lazy dog
2 Fast jumping rabbits
10.
10
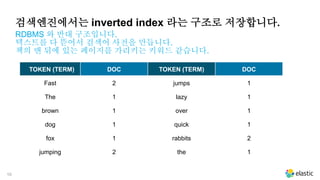
검색엔진에서는 inverted index라는 구조로 저장합니다.
RDBMS 와 반대 구조입니다.
텍스트를 다 뜯어서 검색어 사전을 만듭니다.
책의 맨 뒤에 있는 페이지를 가리키는 키워드 같습니다.
TOKEN (TERM) DOC TOKEN (TERM) DOC
Fast 2 jumps 1
The 1 lazy 1
brown 1 over 1
dog 1 quick 1
fox 1 rabbits 2
jumping 2 the 1
11.
11
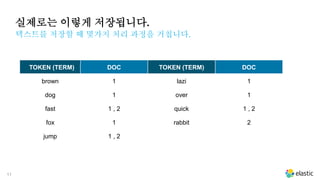
실제로는 이렇게 저장됩니다.
텍스트를저장할 때 몇가지 처리 과정을 거칩니다.
TOKEN (TERM) DOC TOKEN (TERM) DOC
brown 1 lazi 1
dog 1 over 1
fast 1 , 2 quick 1 , 2
fox 1 rabbit 2
jump 1 , 2
12.
12
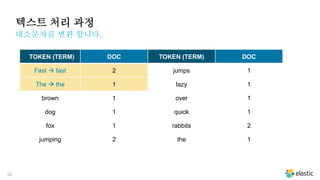
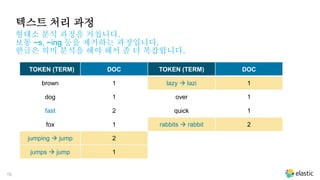
텍스트 처리 과정
대소문자를변환 합니다.
TOKEN (TERM) DOC TOKEN (TERM) DOC
Fast fast 2 jumps 1
The the 1 lazy 1
brown 1 over 1
dog 1 quick 1
fox 1 rabbits 2
jumping 2 the 1
13.
13
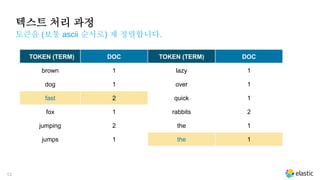
텍스트 처리 과정
토큰을(보통 ascii 순서로) 재 정렬합니다.
TOKEN (TERM) DOC TOKEN (TERM) DOC
brown 1 lazy 1
dog 1 over 1
fast 2 quick 1
fox 1 rabbits 2
jumping 2 the 1
jumps 1 the 1
14.
14
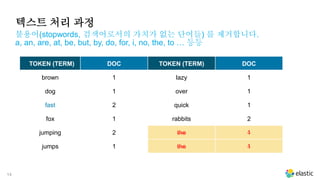
텍스트 처리 과정
불용어(stopwords,검색어로서의 가치가 없는 단어들) 를 제거합니다.
a, an, are, at, be, but, by, do, for, i, no, the, to … 등등
TOKEN (TERM) DOC TOKEN (TERM) DOC
brown 1 lazy 1
dog 1 over 1
fast 2 quick 1
fox 1 rabbits 2
jumping 2 the 1
jumps 1 the 1
15.
15
텍스트 처리 과정
형태소분석 과정을 거칩니다.
보통 ~s, ~ing 등을 제거하는 과정입니다.
한글은 의미 분석을 해야 해서 좀 더 복잡합니다.
TOKEN (TERM) DOC TOKEN (TERM) DOC
brown 1 lazy lazi 1
dog 1 over 1
fast 2 quick 1
fox 1 rabbits rabbit 2
jumping jump 2
jumps jump 1
16.
16
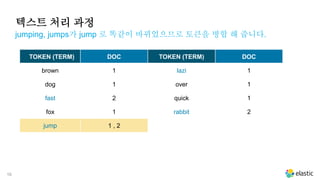
텍스트 처리 과정
jumping,jumps가 jump 로 똑같이 바뀌었으므로 토큰을 병합 해 줍니다.
TOKEN (TERM) DOC TOKEN (TERM) DOC
brown 1 lazi 1
dog 1 over 1
fast 2 quick 1
fox 1 rabbit 2
jump 1 , 2
17.
17
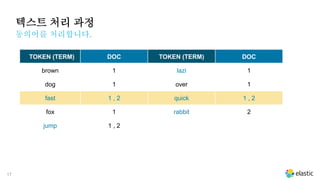
텍스트 처리 과정
동의어를처리합니다.
TOKEN (TERM) DOC TOKEN (TERM) DOC
brown 1 lazi 1
dog 1 over 1
fast 1 , 2 quick 1 , 2
fox 1 rabbit 2
jump 1 , 2
18.
18
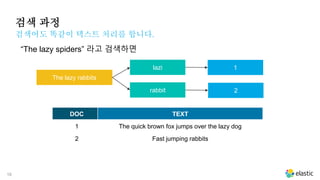
검색 과정
검색어도 똑같이텍스트 처리를 합니다.
“The lazy spiders” 라고 검색하면
The lazy rabbits
lazi
rabbit
1
DOC TEXT
1 The quick brown fox jumps over the lazy dog
2 Fast jumping rabbits
2
20
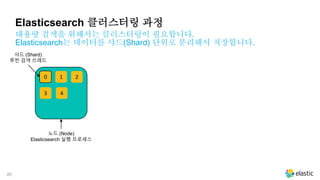
Elasticsearch 클러스터링 과정
대용량검색을 위해서는 클러스터링이 필요합니다.
Elasticsearch는 데이터를 샤드(Shard) 단위로 분리해서 저장합니다.
10 2
3 4
노드 (Node)
Elasticsearch 실행 프로세스
샤드 (Shard)
루씬 검색 쓰레드
22
20 1 43
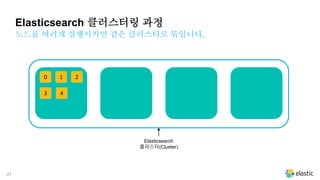
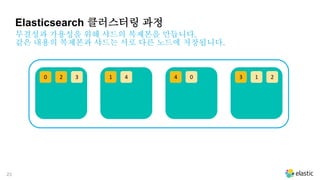
Elasticsearch 클러스터링 과정
샤드들은 각각의 노드들에 분배되어 저장됩니다.
23.
23
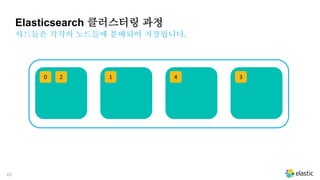
20 3 4104 13 2
무결성과 가용성을 위해 샤드의 복제본을 만듭니다.
같은 내용의 복제본과 샤드는 서로 다른 노드에 저장됩니다.
Elasticsearch 클러스터링 과정
24.
24
20 3 4104 13 2
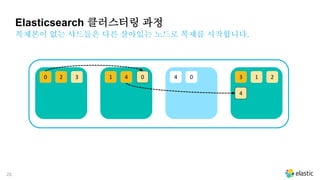
시스템 다운이나 네트워크 단절 등으로 유실된 노드가 생기면
Elasticsearch 클러스터링 과정
25.
25
20 3 4104 13 2
4
0
복제본이 없는 샤드들은 다른 살아있는 노드로 복제를 시작합니다.
Elasticsearch 클러스터링 과정
26.
26
20 3 4113 2
4
0
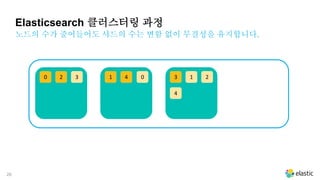
노드의 수가 줄어들어도 샤드의 수는 변함 없이 무결성을 유지합니다.
Elasticsearch 클러스터링 과정
27.
27
20 3 4113 2
4
0
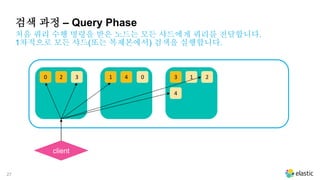
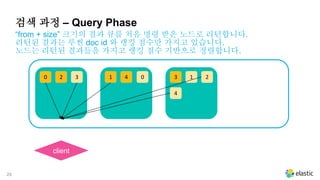
처음 쿼리 수행 명령을 받은 노드는 모든 샤드에게 쿼리를 전달합니다.
1차적으로 모든 샤드(또는 복제본에서) 검색을 실행합니다.
검색 과정 – Query Phase
client
28.
28
20 3 4113 2
4
0
“from + size” 크기의 결과 큐를 처음 명령 받은 노드로 리턴합니다.
리턴된 결과는 루씬 doc id 와 랭킹 점수만 가지고 있습니다.
노드는 리턴된 결과들을 가지고 랭킹 점수 기반으로 정렬합니다.
검색 과정 – Query Phase
client
29.
29
20 3 4113 2
4
0
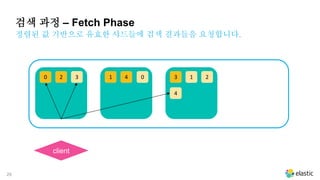
정렬된 값 기반으로 유효한 샤드들에 검색 결과들을 요청합니다.
검색 과정 – Fetch Phase
client
30.
30
20 3 4113 2
4
0
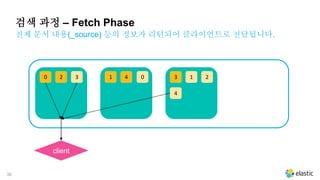
전체 문서 내용(_source) 등의 정보가 리턴되어 클라이언트로 전달됩니다.
검색 과정 – Fetch Phase
client
33
TF / IDF
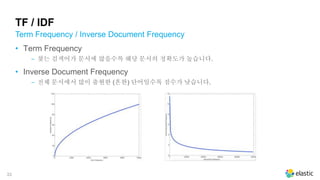
•Term Frequency
‒ 찾는 검색어가 문서에 많을수록 해당 문서의 정확도가 높습니다.
• Inverse Document Frequency
‒ 전체 문서에서 많이 출현한 (흔한) 단어일수록 점수가 낮습니다.
Term Frequency / Inverse Document Frequency
34.
34
검색 랭킹이 중요한이유
• 사용자들은 대부분 처음 나온 결과만 봅니다.
• 결과값이 큰 내용을 fetch 하는 것은 상당히 부하가 큽니다.
• 1~1,000 을 fetch 하는 것이나 990~1,000 을 fetch 하는 것이나 쿼리 작업
규모가 비슷합니다.
• 구글도 랭킹이 중요하긴 마찬가지…
2017 데이터야 놀자
35.
35
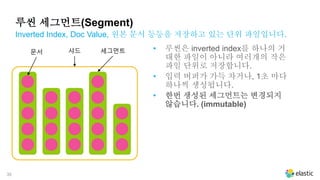
루씬 세그먼트(Segment)
Inverted Index,Doc Value, 원본 문서 등등을 저장하고 있는 단위 파일입니다.
샤드 세그먼트문서
• 루씬은 inverted index를 하나의 거
대한 파일이 아니라 여러개의 작은
파일 단위로 저장합니다.
• 입력 버퍼가 가득 차거나, 1초 마다
하나씩 생성됩니다.
• 한번 생성된 세그먼트는 변경되지
않습니다. (immutable)
36.
36
문서 변경/삭제 과정
•update는 없습니다. 모두 delete & insert 입니다.
• 문서를 삭제하면 삭제되었다는 상태만 표시하고 검색에서 제외합니다.
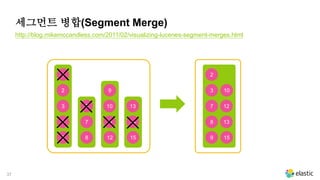
• 나중에 세그먼트 병합 과정에서 삭제된 문서를 빼고 나머지 문서들을 모아
새로운 세그먼트를 만듭니다.
‒ 그래서 문서를 삭제 하더라도 세그먼트 병합을 하기 전 까지 스토리지 용량은 줄어들지 않
습니다.
• 세그먼트 병합은 비용이 큰 동작입니다.
‒ 디스크 I/O 작업입니다.
‒ 시스템이 느려집니다.
‒ 가능하면 사용자들이 적은 시간에 하는것이 좋습니다.
한먼 생성된 세그먼트는 변경되지 않습니다.
#3 저는 현재 Elastic 이라는 오픈소스 검색엔진 회사에서 Tech Evangelist 로 일을 하고 있습니다.
Tech Evangelist 를 딱히 정의하기는 어려운데, 저는 입개발자 라고 보통 이야기 하고요, 해당 기술을 잘 모르던 사람에게 해당 기술 또는 제품에 대한 흥미를 불어넣어 주는 것이 가장 중요한 역할이라고 할 수 있을 것 같습니다. 영업, 기술영업들과는 약간 다른데요, 영업들은 보통 숫자(돈, 기간 등)를 가지고 이야기를 하고요, 저희는 보통 그런것을 배제하고 코어 기술들에 대한 이야기들을 합니다. 그래서 커뮤니티 밋업 이나 컨퍼런스 같은 곳에서 발표를 하는 것이 중요한 Action Item 입니다.
















![[236] 카카오의데이터파이프라인 윤도영](https://cdn.slidesharecdn.com/ss_thumbnails/236-161025031702-thumbnail.jpg?width=640&height=640&fit=bounds)

![[NDC18] 야생의 땅 듀랑고의 데이터 엔지니어링 이야기: 로그 시스템 구축 경험 공유](https://cdn.slidesharecdn.com/ss_thumbnails/ndc2018-1-180430181759-thumbnail.jpg?width=640&height=640&fit=bounds)

![Naver속도의, 속도에 의한, 속도를 위한 몽고DB (네이버 컨텐츠검색과 몽고DB) [Naver]](https://cdn.slidesharecdn.com/ss_thumbnails/naver-190916181334-thumbnail.jpg?width=640&height=640&fit=bounds)


![[2D1]Elasticsearch 성능 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/2d1elasticsearch-140929192211-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)






![[MLOps KR 행사] MLOps 춘추 전국 시대 정리(210605)](https://cdn.slidesharecdn.com/ss_thumbnails/mlops-basic-210605064957-thumbnail.jpg?width=640&height=640&fit=bounds)





![신입 개발자 생활백서 [개정판]](https://cdn.slidesharecdn.com/ss_thumbnails/random-170208062532-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Spring Camp 2018] 11번가 Spring Cloud 기반 MSA로의 전환 : 지난 1년간의 이야기](https://cdn.slidesharecdn.com/ss_thumbnails/201804springcamp11stmsafinalpubslideshare-180527051608-thumbnail.jpg?width=640&height=640&fit=bounds)


![[NDC18] 야생의 땅 듀랑고의 데이터 엔지니어링 이야기: 로그 시스템 구축 경험 공유 (2부)](https://cdn.slidesharecdn.com/ss_thumbnails/ndc2018-2-180430180517-thumbnail.jpg?width=640&height=640&fit=bounds)










![[215]네이버콘텐츠통계서비스소개 김기영](https://cdn.slidesharecdn.com/ss_thumbnails/215-161025030904-thumbnail.jpg?width=640&height=640&fit=bounds)
![[4차]구글 알고리즘 분석(151106)](https://cdn.slidesharecdn.com/ss_thumbnails/4-151106-160217170051-thumbnail.jpg?width=640&height=640&fit=bounds)


![제 17회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [중고책나라] : 실시간 데이터를 이용한 Elasticsearch 클러스터 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/random-230220154251-7145ba84-thumbnail.jpg?width=640&height=640&fit=bounds)






![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [If Lab] : 실시간 투표 커뮤니티 서비스 기반 데이터 파이프라인 구축 및 성능 검증](https://cdn.slidesharecdn.com/ss_thumbnails/2-1boaz23rdconferenceiflab-260203101556-e51663dd-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [F4] : 시켜줘, 금잔디 명예 플로리스트](https://cdn.slidesharecdn.com/ss_thumbnails/3-3boaz23rdconferencef4-260204011323-1cb48ec9-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [어벤정스] : ToonP](https://cdn.slidesharecdn.com/ss_thumbnails/2-2boaz23rdconference-260203102006-3a01358e-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [픽미] : 디저트 큐레이팅 플랫폼, 딸기로픽을 위한 데이터 기반 의사결정 프로세스 구축](https://cdn.slidesharecdn.com/ss_thumbnails/3-2boaz23rdconference-260203102931-15458767-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [북적북적] : 데이터 기반 독립출판사,서점 경영지원 대시보드](https://cdn.slidesharecdn.com/ss_thumbnails/1-1boaz23rdconference-260203093712-78abc1a0-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [백 투 더 엔지] : 분산환경 주문 이벤트 처리 플랫폼](https://cdn.slidesharecdn.com/ss_thumbnails/1-2boaz23rdconference-260203100241-73ce0aa8-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [JJAI] : Re:Buy - 고객 행동 패턴 기반 재구매 시점 예측 개인화 CRM 시스템](https://cdn.slidesharecdn.com/ss_thumbnails/1-3boaz23rdconferencejjai-260203100705-ab1ce027-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [OnLog]: Real-time Edge-to-Cloud Data Pipeline fo...](https://cdn.slidesharecdn.com/ss_thumbnails/3-4boaz23rdconferenceonlog-260204093729-11983ba7-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [셋이어때] : 헬퍼잇](https://cdn.slidesharecdn.com/ss_thumbnails/2-3boaz23rdconference-260203102432-6c8c7ed6-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [SimAI] : Omni_모든 콘텐츠 운영을 하나로](https://cdn.slidesharecdn.com/ss_thumbnails/1-4boaz23rdconferencesimai-260203101225-d673a594-thumbnail.jpg?width=640&height=640&fit=bounds)