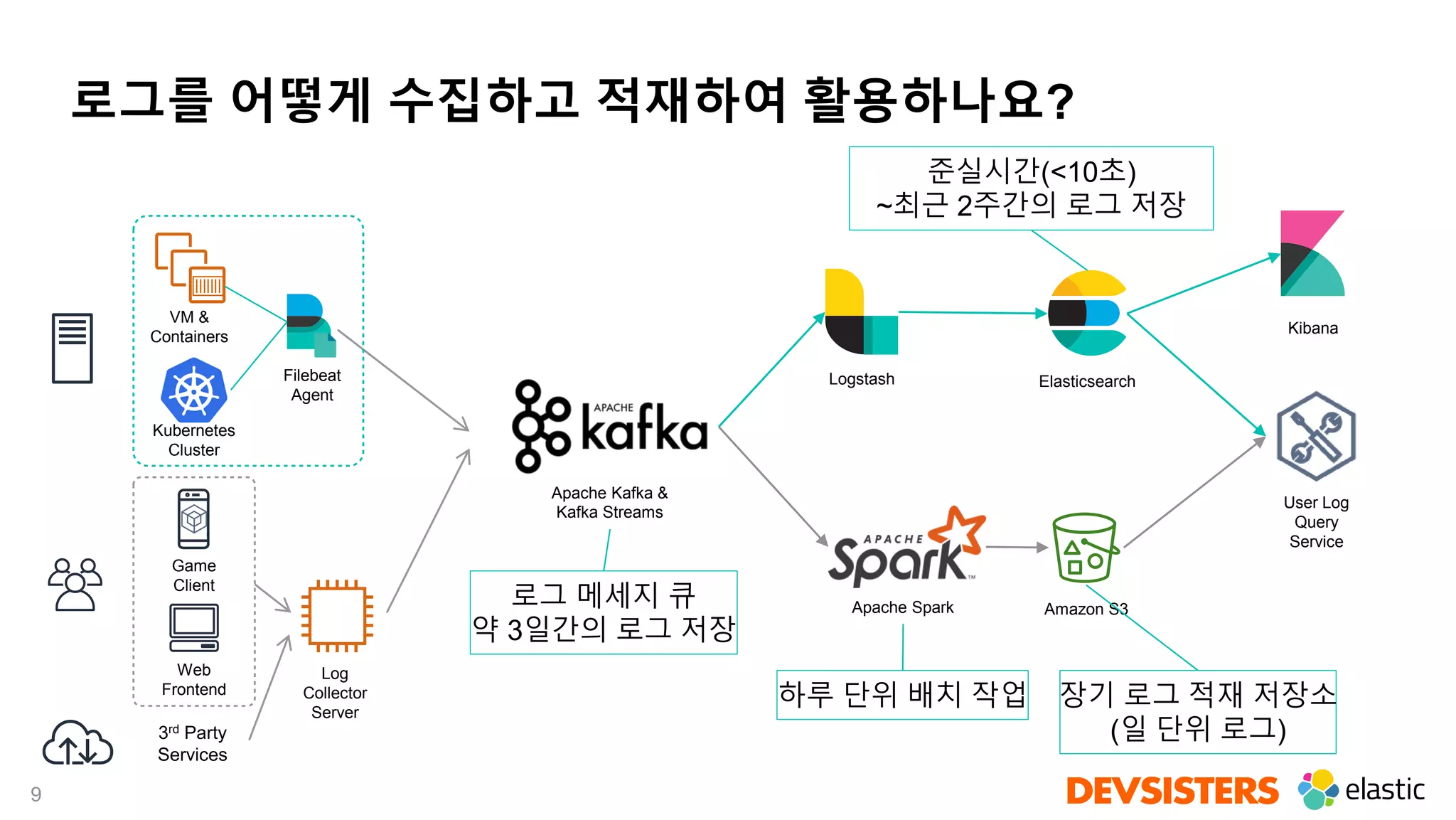
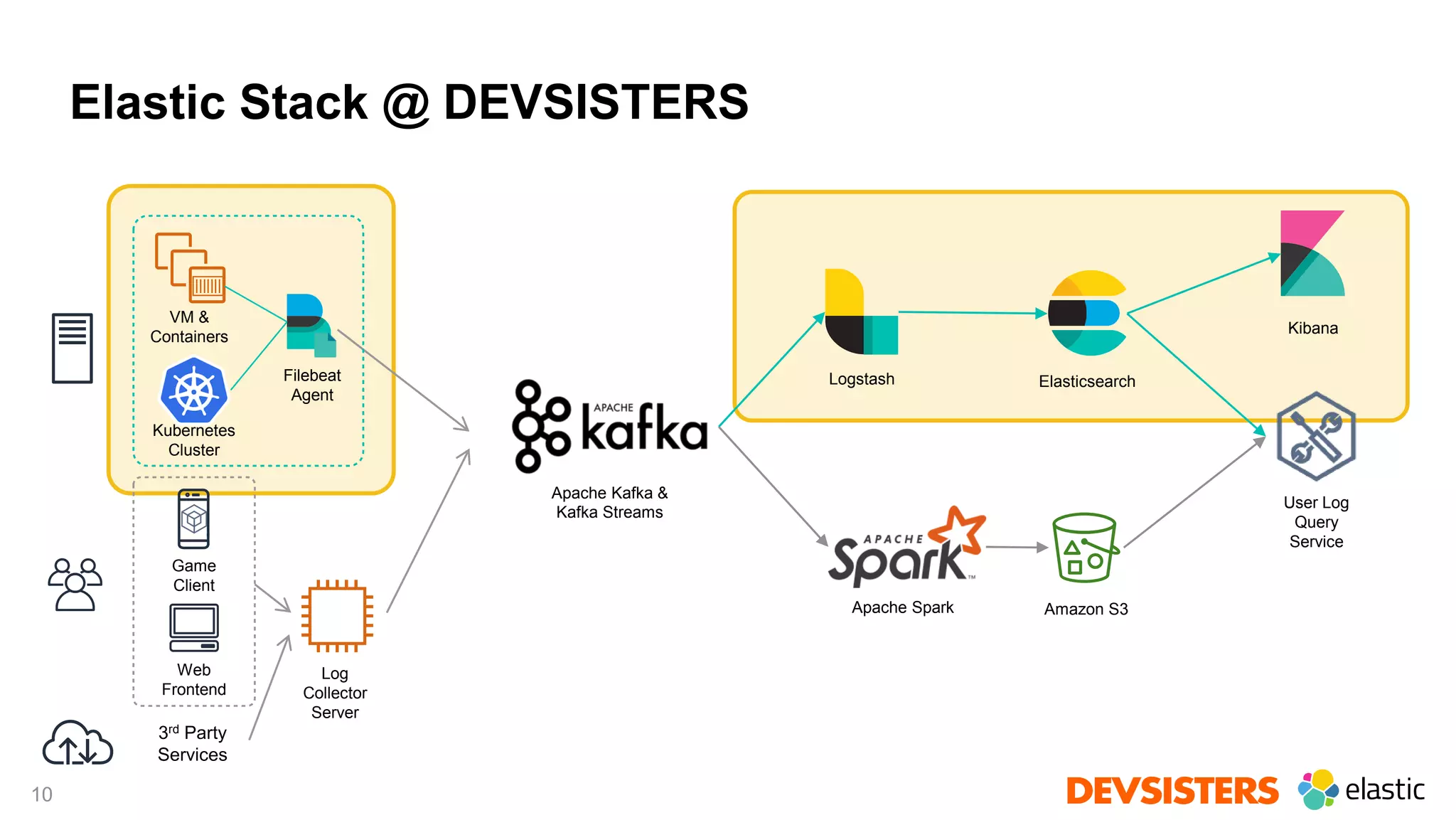
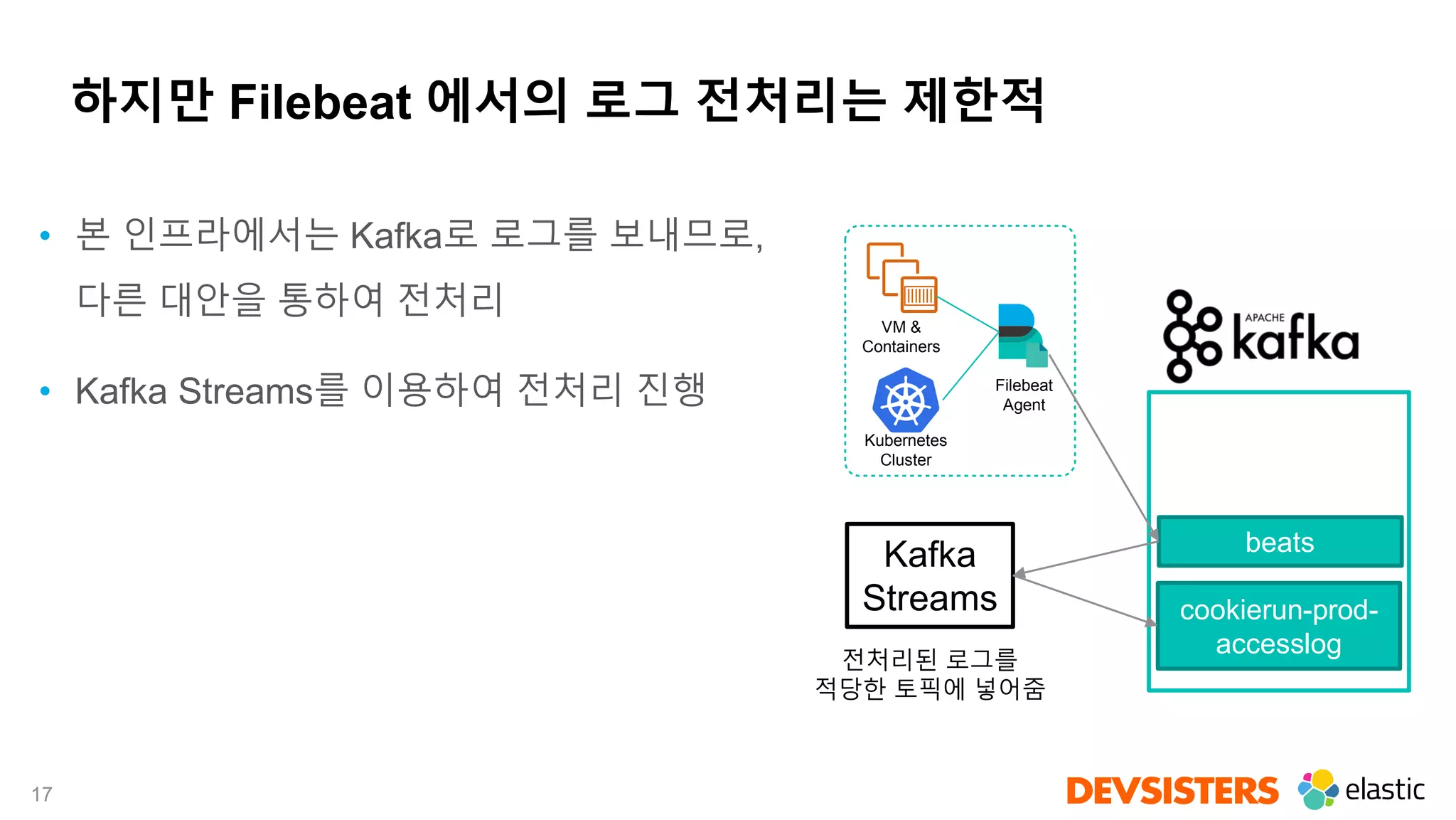
Downloaded 27 times










![14
filebeat.inputs:
- type: docker
containers.ids:
- "*"
processors:
- add_docker_metadata:
host: "unix:///var/run/docker.sock"
- drop_event:
when.not.equals:
docker.container.labels.logging: "enabled"
processors:
- add_cloud_metadata: ~
output.kafka:
hosts: ["..."]
version: "..."
topic: "beats"
...
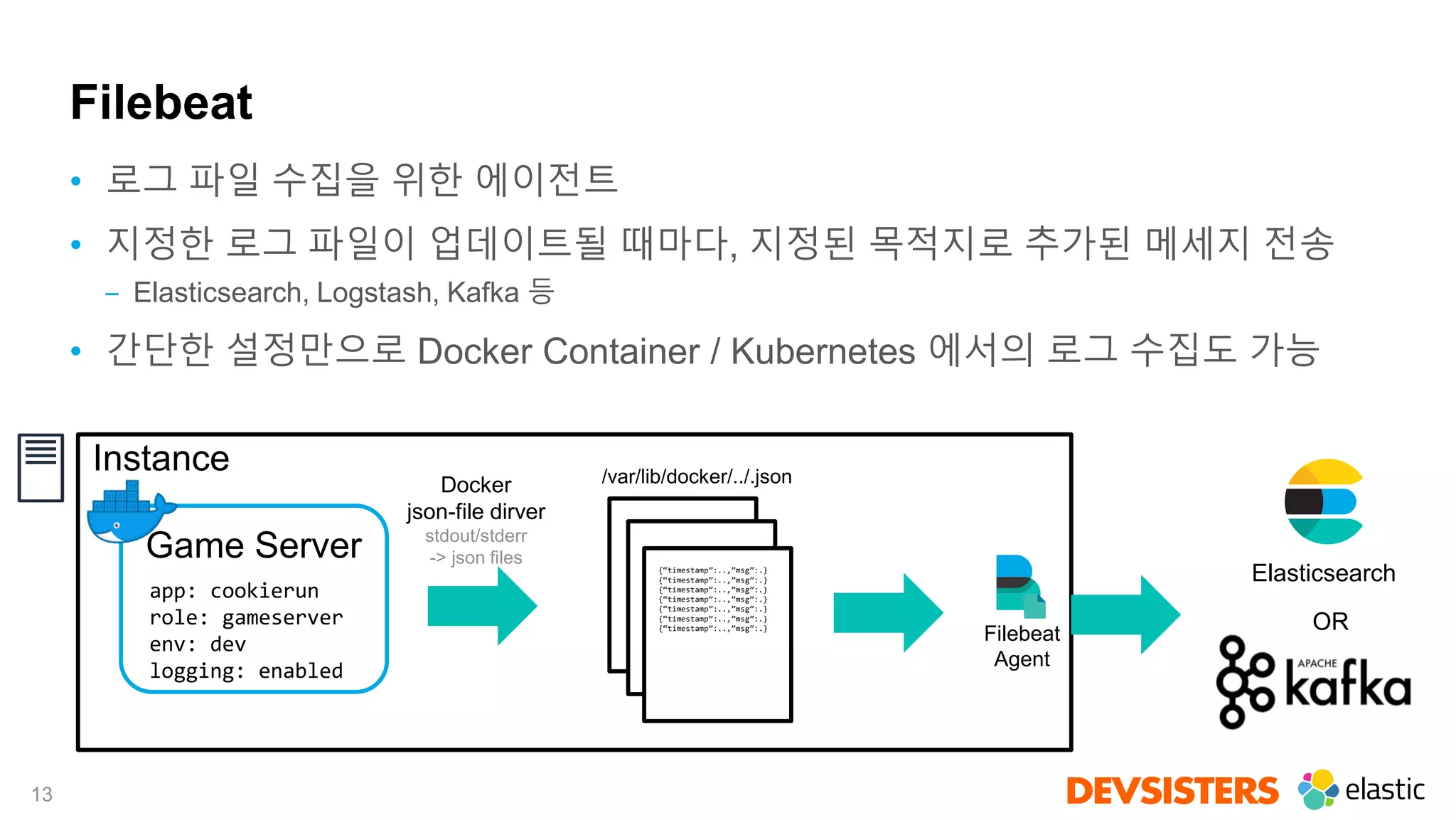
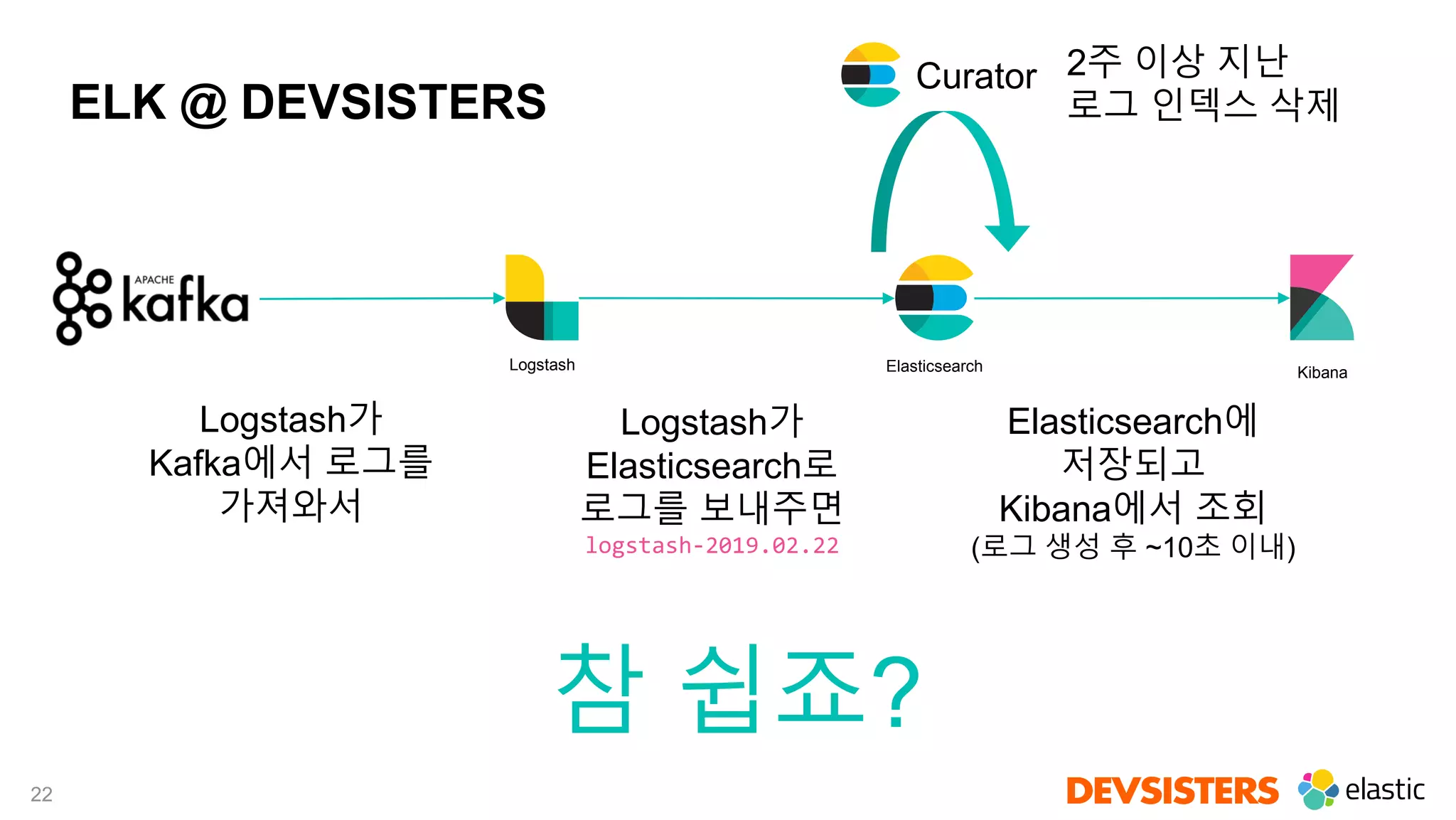
Filebeat를 이용한 컨테이너 로그 수집
Filebeat
Agent
Host / Container
관련 필드 추가
Docker Input 설정
수집 대상
이외 로그 제외
Kafka Output 설정](https://image.slidesharecdn.com/2019elasticondevsisters-2-190803233319/75/Elastic-Stack-elastic-on-2019-Seoul-14-2048.jpg)





















elastic{on} 2019 Seoul 에서 발표한 데브시스터즈(Devsisters Corp.) 의 Elastic Stack 기반 게임 서비스 통합 로깅 플랫폼 소개 발표 자료입니다. 발표 영상은 https://www.elastic.co/kr/elasticon/tour/2019/seoul/devsisters-game-service-integration-logging-platform-using-elastic-stack 에서 보실 수 있습니다.

![[NDC17] Kubernetes로 개발서버 간단히 찍어내기](https://cdn.slidesharecdn.com/ss_thumbnails/ndc-170529041601-thumbnail.jpg?width=640&height=640&fit=bounds)

![쿠키런: 킹덤 대규모 인프라 및 서버 운영 사례 공유 [데브시스터즈 - 레벨 200] - 발표자: 용찬호, R&D 엔지니어, 데브시스터즈 ...](https://cdn.slidesharecdn.com/ss_thumbnails/t3s3-221108102039-c0f48289-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NDC18] 야생의 땅 듀랑고의 데이터 엔지니어링 이야기: 로그 시스템 구축 경험 공유](https://cdn.slidesharecdn.com/ss_thumbnails/ndc2018-1-180430181759-thumbnail.jpg?width=640&height=640&fit=bounds)
![오딘: 발할라 라이징 MMORPG의 성능 최적화 사례 공유 [카카오게임즈 - 레벨 300] - 발표자: 김문권, 팀장, 라이온하트 스튜디오...](https://cdn.slidesharecdn.com/ss_thumbnails/t3s1-221108101729-c6b32f4f-thumbnail.jpg?width=640&height=640&fit=bounds)

![[2019] PAYCO 쇼핑 마이크로서비스 아키텍처(MSA) 전환기](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201926-200122093003-thumbnail.jpg?width=640&height=640&fit=bounds)





![[오픈소스컨설팅] 스카우터 사용자 가이드 2020](https://cdn.slidesharecdn.com/ss_thumbnails/2020scouteruserguide-200122014357-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DEVIEW 2021] 1000만 글로벌 유저를 지탱하는 기술과 사람들](https://cdn.slidesharecdn.com/ss_thumbnails/1000-deview-220204010915-thumbnail.jpg?width=640&height=640&fit=bounds)

![PUBG: Battlegrounds 라이브 서비스 EKS 전환 사례 공유 [크래프톤 - 레벨 300] - 발표자: 김정헌, PUBG Dev...](https://cdn.slidesharecdn.com/ss_thumbnails/t3s2-221108101842-328d500f-thumbnail.jpg?width=640&height=640&fit=bounds)


![[오픈소스컨설팅]쿠버네티스를 활용한 개발환경 구축](https://cdn.slidesharecdn.com/ss_thumbnails/opensourceconsutingkubernetesv0-191010000815-thumbnail.jpg?width=640&height=640&fit=bounds)






![[215] Druid로 쉽고 빠르게 데이터 분석하기](https://cdn.slidesharecdn.com/ss_thumbnails/215druid-181012071910-thumbnail.jpg?width=640&height=640&fit=bounds)
![[215]네이버콘텐츠통계서비스소개 김기영](https://cdn.slidesharecdn.com/ss_thumbnails/215-161025030904-thumbnail.jpg?width=640&height=640&fit=bounds)


![[2018] NHN 모니터링의 현재와 미래 for 인프라 엔지니어](https://cdn.slidesharecdn.com/ss_thumbnails/cloudinfra02-190131073314-thumbnail.jpg?width=640&height=640&fit=bounds)
![[오픈소스컨설팅]openstack_monitoring_session](https://cdn.slidesharecdn.com/ss_thumbnails/openmon-180315100420-thumbnail.jpg?width=640&height=640&fit=bounds)













![[AWSKRUG] 모바일게임 하이브 런칭기 (2018)](https://cdn.slidesharecdn.com/ss_thumbnails/awskrugawsformobilegame-190419125248-thumbnail.jpg?width=640&height=640&fit=bounds)
