Downloaded 118 times








![17 / 66
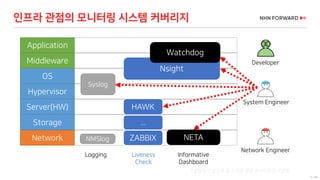
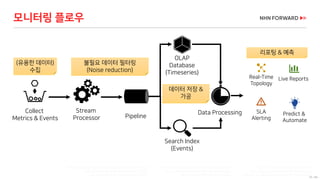
메트릭 (Metrics)
어떤 일이 일어나는가? , Not 왜 일어나고 있는가?(분석)
특정 시점에서 시스템과 관련된 값을 캡처
정의된 주기로 수집하여 시계열 데이터베이스(TSDB)에 저장
[bucket 1234, response:OK, method: read] {(Wed 2:00pm, 3), (Wed 2:05pm, 2), (Wed 2:10pm, 8), ...}
[bucket 1234, response:OK, method: write] {(Wed 2:01pm, 1), (Wed 2:04pm, 2), (Wed 2:09pm, 7), ...}
[bucket 1234, response:FAIL, method: write] {(Wed 2:01pm, 1), (Wed 2:04pm, 0), (Wed 2:09pm, 0), ...}
[bucket 9876, response:OK, method: read] {(Wed 1:59pm, 2), (Wed 2:05pm, 4), (Wed 2:10pm, 3), ...}](https://image.slidesharecdn.com/cloudinfra02-190131073314/85/2018-NHN-for-17-320.jpg)




![29 / 66
if [type] == "proxy_log" {
grok {
add_tag => ["swift", "proxy"]
patterns_dir => ["/etc/logstash/patterns"]
match => { 'message' => '%{SYSLOGTIMESTAMP:node_tz} %{HOSTNAME:hostname} %{NOTSPACE:swift_service}: %{NOTSPACE:client_ip} %
{NOTSPACE:remote_addr} %{SWIFT_PROXY_DATETIME:datetime} %{WORD:request_method} %{URIPATHPARAM:request_path} HTTP/%{NUMBER:httpversion}
%{NUMBER:status_int:int} %{NOTSPACE:referer} %{NOTSPACE:user_agent} %{NOTSPACE:auth_token} %{NOTSPACE:bytes_recvd:int} %{NOTSPACE:byte
s_sent:int} %{NOTSPACE:client_etag} %{NOTSPACE:transaction_id} %{NOTSPACE:headers} %{NUMBER:request_time:float} %{NOTSPACE:api_source}
%{NOTSPACE:log_info} %{NUMBER:request_start_time} %{NUMBER:request_end_time} %{NOTSPACE:policy_index:int}' }
}
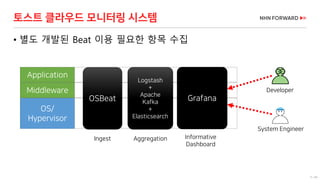
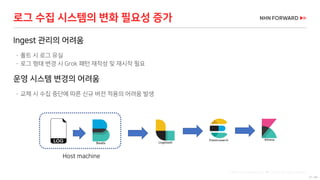
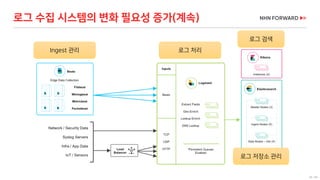
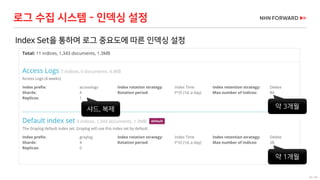
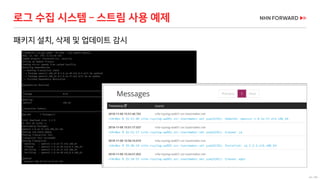
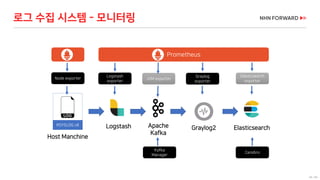
로그 처리 - 복잡도 증가
로그 필드 추출을 위한 GROK 구문 예
로그 수집 시스템의 변화 필요성 증가(계속)](https://image.slidesharecdn.com/cloudinfra02-190131073314/85/2018-NHN-for-29-320.jpg)












![63 / 66
Nagios/Icinga/Zabbix
• Disk Used : 92.00% (/home1)
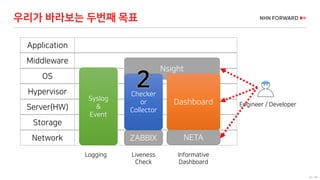
Prometheus vs General NMS
Prometheus
• Disk would be usable for the next 12 hours
- name: node.rules
rules:
- alert: DiskWillFillIn12Hours
expr: predict_linear(node_filesystem_free_bytes{mountpoint="/rootfs"}[1h], 12*3600) < 0
for: 5m
labels: severity: page](https://image.slidesharecdn.com/cloudinfra02-190131073314/85/2018-NHN-for-63-320.jpg)

인프라 모니터링을 위한 시스템을 구축하고 운영하는 데 있어, 다이내믹한 인프라 변화는 어려움으로 다가오고 있습니다. 본 세션에서는 인프라를 운영하는 팀 혹은 운영자 관점에서 바라본 미래 지향적 인프라 모니터링 시스템의 방향성과 이를 구현하기 위해 필요한 구성들을 공유하고자 합니다. 목차 1. NHN 모니터링의 현재 2. 모니터링의 변화 3. 모니터링 방법론 4. 모니터링 절차 5. NHN 모니터링의 미래 대상 - 인프라를 운영하는 시스템 엔지니어 - 인프라 모니터링 시스템에 관심이 있는 분

![[오픈소스컨설팅]Day #1 MySQL 엔진소개, 튜닝, 백업 및 복구, 업그레이드방법](https://cdn.slidesharecdn.com/ss_thumbnails/day1mysqlintroduction-141212003401-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)









![[MeetUp][1st] 오리뎅이의_쿠버네티스_네트워킹](https://cdn.slidesharecdn.com/ss_thumbnails/3-191024235922-thumbnail.jpg?width=640&height=640&fit=bounds)
























![[MeetUp][3rd] Prometheus 와 함께하는 모니터링 및 시각화](https://cdn.slidesharecdn.com/ss_thumbnails/prometheus-200424015637-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [백 투 더 엔지] : 분산환경 주문 이벤트 처리 플랫폼](https://cdn.slidesharecdn.com/ss_thumbnails/1-2boaz23rdconference-260203100241-73ce0aa8-thumbnail.jpg?width=640&height=640&fit=bounds)

![[열린기술공방] Container기반의 DevOps - 클라우드 네이티브](https://cdn.slidesharecdn.com/ss_thumbnails/sharingtechnologylabskubernetesapplicationcicd00-200217075019-thumbnail.jpg?width=640&height=640&fit=bounds)


![[252] 증분 처리 플랫폼 cana 개발기](https://cdn.slidesharecdn.com/ss_thumbnails/225cana-150915052201-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)



![[244]네트워크 모니터링 시스템(nms)을 지탱하는 기술](https://cdn.slidesharecdn.com/ss_thumbnails/244nms-171017030833-thumbnail.jpg?width=640&height=640&fit=bounds)

![[2019] 패션 시소러스 기반 상품 특징 분석 시스템](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201900-200123073101-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2019] 스몰 스텝: Android 렛츠기릿!](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201935-200123072807-thumbnail.jpg?width=640&height=640&fit=bounds)


![[2019] GIF 스티커 만들기: 스파인 2D를 이용한 움직이는 스티커 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201934-200123071121-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2019] 전기 먹는 하마의 다이어트 성공기 클라우드 데이터 센터의 에너지 절감 노력과 사례](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201919-200123023945-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2019] 스몰 스텝: Dooray!를 이용한 업무 효율화/자동화(고객문의 시스템 구축)](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201933-200122100333-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2019] 아직도 돈 주고 DB 쓰나요? for Developer](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201932-200122100331-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2019] 아직도 돈 주고 DB 쓰나요 for DBA](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201931-200122100329-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2019] 비주얼 브랜딩: Basic system](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201930-200122100316-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2019] PAYCO 매거진 서버 Kotlin 적용기](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201929-200122100007-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2019] 벅스 5.0 (feat. Kotlin, Jetpack)](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201928-200122095924-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2019] Java에서 Fiber를 이용하여 동시성concurrency 프로그래밍 쉽게 하기](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201927-200122095808-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2019] PAYCO 쇼핑 마이크로서비스 아키텍처(MSA) 전환기](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201926-200122093003-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2019] 비식별 데이터로부터의 가치 창출과 수익화 사례](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201925-200122092831-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2019] 게임 서버 대규모 부하 테스트와 모니터링 이렇게 해보자](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201924-200122092752-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2019] 200만 동접 게임을 위한 MySQL 샤딩](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201923-200122092657-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2019] 언리얼 엔진을 통해 살펴보는 리플렉션과 가비지 컬렉션](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201922-200122092627-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2019] 글로벌 게임 서비스 노하우](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201921-200122092626-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2019] 배틀로얄 전장(map) 제작으로 알아보는 슈팅 게임 레벨 디자인](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201920-200122092612-thumbnail.jpg?width=640&height=640&fit=bounds)