데이터시각화를 바라보는 데이터 사이언티스트, 엔지니어, 마케터간의 관점들이 서로 다릅니다.
이 슬라이드에서는 엔지니어 관점에서 중요시 하는 키워드들, 설계 관점에서의 데이터시각화,
그리고 비즈니스인텔리전스(Business Intelligence)에 대해서 소개드리고 있습니다.
이 발표자료는 데이터 야놀자에서 소개되었습니다.
데이터분석가를 위한 서비스도많습니다.
Jupyter with plotly shiny from R studio
10.
데이터 시각화를 바라보는관점
백엔드 개발자, 엔지니어
정형화? 비정형화?
groupby 하는가?
drilldown은 얼마나?
데이터의 양은 얼마나?
batch? ad-hoc? stream?
데이터를 어디로 넘겨주어야 하나
cache는 어디까지?
로그 어디다가 쌓을까요?
제플린 띄워서 날로 먹자
데이터 사이언티스트
matplotlib, numpy 짱짱맨
cluster 분포는 잘 되어있나?
각 step별 정확도 변화를
시각적으로 파악
실제 데이터와 예측된 데이터의
차이점을 시각적으로 파악
헠헠 라벨을 보자!
마케터
날짜별 DAU가 얼마지?
날짜별로 어뷰징 예상유저 비율은?
게임에서 딸기를 먹은 유저 모수가 필요해
A 광고에서 들어와서 게임을 설치하여
3스테이지까지 완료한 사용자의 평균 결제금액은
프론트 개발자
D3 쓸까 highchart 쓸까
canvas or svg?
raphael을 써야하나
이건 지원안해요 직접 만들어야 해요!!
11.
그들이 실제로 사용하는것
백엔드 개발자, 엔지니어
RDBMS, NoSQL, DW, Query
engine
Hadoop layer (cf. Spark, Impala,
Pig)
Cloud based database
ETL Process
Workflow
…
데이터 사이언티스트
iPython, Jupyter
TensorBoard
matplotlib, numpy
geoplotlib
seaborn
gleam
ggplot2
plotly
R
…
마케터
Tableau
PowerBI
Google Data Studio
…
프론트 개발자
D3, C3, NSD3
Raphael
Datatable
…
12.
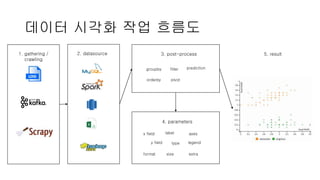
데이터 시각화 작업흐름도
x field
y field
size
legend
axes
extraformat
4. parameters
label
type
3. post-process
groupby
orderby
filter
pivot
prediction
5. result2. datasource1. gathering /
crawling
13.
1. gathering /crawling
• 의미있는 데이터의 최소단위로 중복 없이 끌어와야 함.
• 이미 로그파일이 있다면 Batch를 통해 의미있는 데이터 가공.
• 이미 데이터가 Database, Search Engine에 있다면 Workflow를 통해 수집.
• Phantom.js, Scrapy, Apache Mhaout 등의 오픈소스를 이용해 크롤링.
• 공유된 머신러닝 데이터 시트등을 직접 수집하여 업로드.
시각화할 데이터를 수집하는 단계
14.
2. data source
•중복 없는, 같은 포맷의 데이터
• 알려진 형식의 데이터파일 (CSV, TSV, JSON, …)
• field와 value로 구성된 dataframe (date: 2017-10-13, column1: 6.2)
• 원격 파일의 경우 알려진 프로토콜의 접근형식 (http, jdbc, thrift,
protobuf, …)
• 데이터소스가 데이터베이스라면 RDBMS인지 NoSQL인지, DW인지
파악이 필요
• 비정형화 데이터라면 데이터를 접근할 수 있는 metadata가 있는지 파악
시각화할 대상의 데이터
15.
3. post-process
• groupby:데이터 유사한 필드를 가진 여러 행을 하나의 행으로 묶는 과정 (ex. relational
chart)
• orderby: 특정 필드 기준으로 데이터 순서를 정렬하는 과정
• filter: 조건에 맞는 행만 추출하는 과정 (ex. interaction navigating chart)
• pivot: groupby와 유사하지만 유사한 필드를 가진 여러행을 묶어 각 열로 피벗
• prediction: 현재 가지고 있는 데이터를 바탕으로 예측되는 데이터를 만들어내어
Trendline 혹은 또 다른 축으로 추가 (linear, exponential)
데이터소스의 데이터를 후가공하는 과정
16.
4. parameters
• xfield:x 필드의 값 (line, area, scatter, matrix, bubble)
• yfield: y 필드의 값 (line, area, scatter, matrix, bubble)
• value: 일반적인 값
• size: 특정 좌표의 bullet의 가중치 (크기 혹은 색상의 진하기)
• format: 값의 형식 (number, date: yyyy-MM-dd, …)
• legend: 범례
• label: 특정 좌표의 bullet의 text
• axes: 차트의 축
• extra: 추가적인 정보들 (각 영역별 관계, 순서, z 값, …)
차트 타입별로 요구되는 각각의 속성들
17.
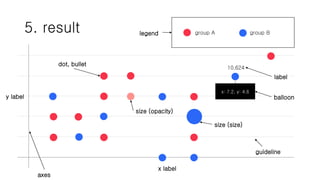
5. result legendgroup A group B
x label
y label
axes
dot, bullet
size (size)
size (opacity)
x: 7.2, y: 4.6
balloon
10.624
label
guideline
BI (Business Intelligence)
•앞서 보셨듯이 데이터에서 의미있는 값을 도출해내는 과정이 복잡함.
• 이 과정을 조금 더 쉽게하는 도구를 만듦.
• 그것이 Business Intelligence.
Apache incubator project Superset
21.
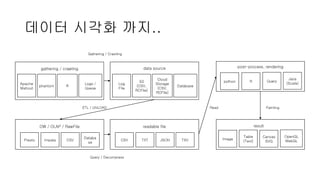
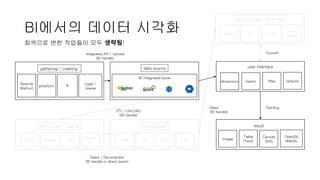
BI에서의 데이터 시각화
datasource
BI integrated store
ETL / UNLOAD
(BI handle)
readable file
CSV TXT JSON TSV
Read
(BI handle)
user interface
dimension metric filter options
Painting
result
Image
Table
(Text)
Canvas
SVG
OpenGL
WebGL
gathering / crawling
Apache
Mahout
phantom R
Logs /
Queue
Integrated API / Upload
(BI handle)
DW / OLAP / RawFile
Presto Impala CSV
Databa
se
Query / Decompress
(BI handle or direct query)
post-process, rendering
python R Query
Java
(Scala)
Convert
회색으로 변한 작업들이 모두 생략됨!
22.
증말 편해요
여러분이 많이쓰시는제플린도 Business Intelligence 입니다.
Apache project Zeppelin
23.
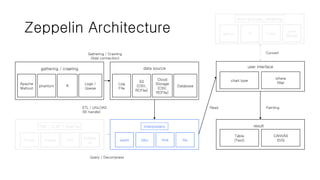
Zeppelin Architecture
data source
Log
File
S3
(CSV,
RCFile)
Cloud
Storage
(CSV,
RCFile)
Database
ETL/ UNLOAD
(BI handle)
interpreters
spark jdbc flink file
Read Painting
result
gathering / crawling
Apache
Mahout
phantom R
Logs /
Queue
Gathering / Crawling
(Add connection)
DW / OLAP / RawFile
Presto Impala CSV
Databa
se
Query / Decompress
user interface
where
filter
post-process, rendering
python R Query
Java
(Scala)
Convert
chart type
CANVAS
SVG
Table
(Text)
런칭을 앞둔 BI
런칭이한달도 남지 않은 Business Intelligence 솔루션
Campaign Intelligence from IGAWorks
26.
고군분투
• 반복된 일로고단한 불쌍한 마케터를 위한 BI를 설계함.
• 그러면서도 개발자를 위해 Query, data append API를 열어둠.
• 여러 데이터소스 타입을 지원하기 위해 추상체를 쌓아올림.
27.
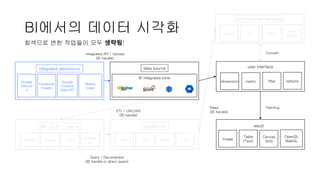
BI에서의 데이터 시각화
ETL/ UNLOAD
(BI handle)
readable file
CSV TXT JSON TSV
Read
(BI handle)
user interface
dimension metric filter options
Painting
result
Image
Table
(Text)
Canvas
SVG
OpenGL
WebGL
integrated datasource
Google
Adword
s
Facebook
Insight
Google
Youtube
Data API
Mobile
Index
Integrated API / Upload
(BI handle)
DW / OLAP / RawFile
Presto Impala CSV
Databa
se
Query / Decompress
(BI handle or direct query)
post-process, rendering
python R Query
Java
(Scala)
Convert
회색으로 변한 작업들이 모두 생략됨!
data source
BI integrated store










































![[Td 2015]틱틱대도 써야 하는 windows 10 앱 개발, c# tips & tricks(송기수)](https://cdn.slidesharecdn.com/ss_thumbnails/td2015windows10ctipstricks-151104053021-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)




![[Pgday.Seoul 2018] Greenplum의 노드 분산 설계](https://cdn.slidesharecdn.com/ss_thumbnails/02-20181103pgdayseminarv1-181112041352-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Pgday.Seoul 2019] Advanced FDW](https://cdn.slidesharecdn.com/ss_thumbnails/tarantulav2-191218044914-thumbnail.jpg?width=640&height=640&fit=bounds)













![[경북] I'mcloud openlight](https://cdn.slidesharecdn.com/ss_thumbnails/imcloudopenlight-151105091914-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[AWSKRUG] 데이터 얼마까지 알아보셨어요?](https://cdn.slidesharecdn.com/ss_thumbnails/aa-190614060527-thumbnail.jpg?width=640&height=640&fit=bounds)

![[AWS Summit 2019] 데이터의 힘, 스타트업 생존을 넘어 성장으로](https://cdn.slidesharecdn.com/ss_thumbnails/awssummitseoul2019kmongrevisedcraig190416finalscriptformatted-190828020916-thumbnail.jpg?width=640&height=640&fit=bounds)
![NDC 2016, [슈판워] 맨땅에서 데이터 분석 시스템 만들어나가기](https://cdn.slidesharecdn.com/ss_thumbnails/ndc-2016-160429031551-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DDC 2018] Metatron 오픈소스화 및 생태계 구축 (SKT 이정룡, 김지호)](https://cdn.slidesharecdn.com/ss_thumbnails/ddc2018session1-181126012837-thumbnail.jpg?width=640&height=640&fit=bounds)














![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [백 투 더 엔지] : 분산환경 주문 이벤트 처리 플랫폼](https://cdn.slidesharecdn.com/ss_thumbnails/1-2boaz23rdconference-260203100241-73ce0aa8-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [JJAI] : Re:Buy - 고객 행동 패턴 기반 재구매 시점 예측 개인화 CRM 시스템](https://cdn.slidesharecdn.com/ss_thumbnails/1-3boaz23rdconferencejjai-260203100705-ab1ce027-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [북적북적] : 데이터 기반 독립출판사,서점 경영지원 대시보드](https://cdn.slidesharecdn.com/ss_thumbnails/1-1boaz23rdconference-260203093712-78abc1a0-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [픽미] : 디저트 큐레이팅 플랫폼, 딸기로픽을 위한 데이터 기반 의사결정 프로세스 구축](https://cdn.slidesharecdn.com/ss_thumbnails/3-2boaz23rdconference-260203102931-15458767-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [셋이어때] : 헬퍼잇](https://cdn.slidesharecdn.com/ss_thumbnails/2-3boaz23rdconference-260203102432-6c8c7ed6-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [어벤정스] : ToonP](https://cdn.slidesharecdn.com/ss_thumbnails/2-2boaz23rdconference-260203102006-3a01358e-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [OnLog]: Real-time Edge-to-Cloud Data Pipeline fo...](https://cdn.slidesharecdn.com/ss_thumbnails/3-4boaz23rdconferenceonlog-260204093729-11983ba7-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [SimAI] : Omni_모든 콘텐츠 운영을 하나로](https://cdn.slidesharecdn.com/ss_thumbnails/1-4boaz23rdconferencesimai-260203101225-d673a594-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [If Lab] : 실시간 투표 커뮤니티 서비스 기반 데이터 파이프라인 구축 및 성능 검증](https://cdn.slidesharecdn.com/ss_thumbnails/2-1boaz23rdconferenceiflab-260203101556-e51663dd-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [F4] : 시켜줘, 금잔디 명예 플로리스트](https://cdn.slidesharecdn.com/ss_thumbnails/3-3boaz23rdconferencef4-260204011323-1cb48ec9-thumbnail.jpg?width=640&height=640&fit=bounds)