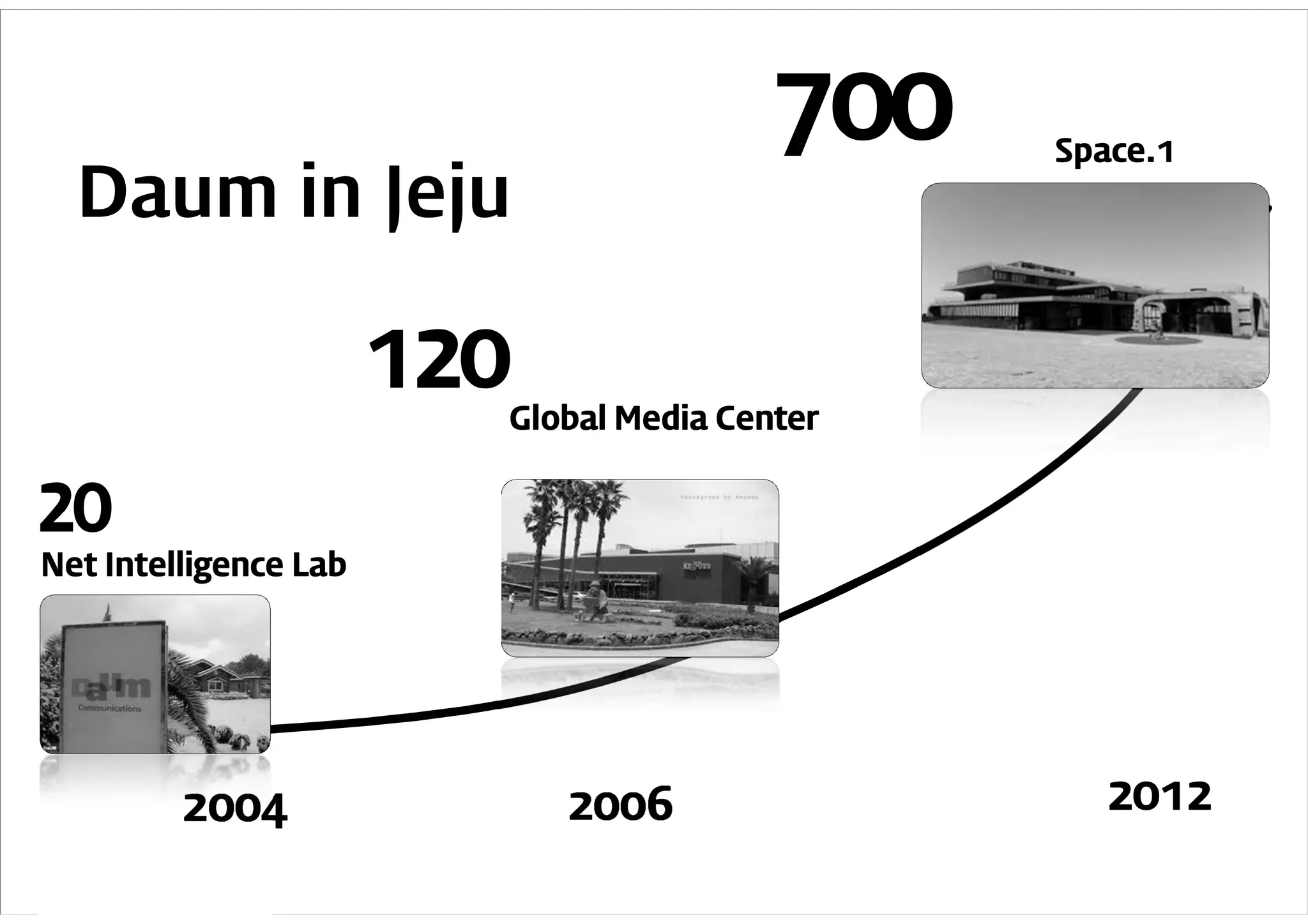
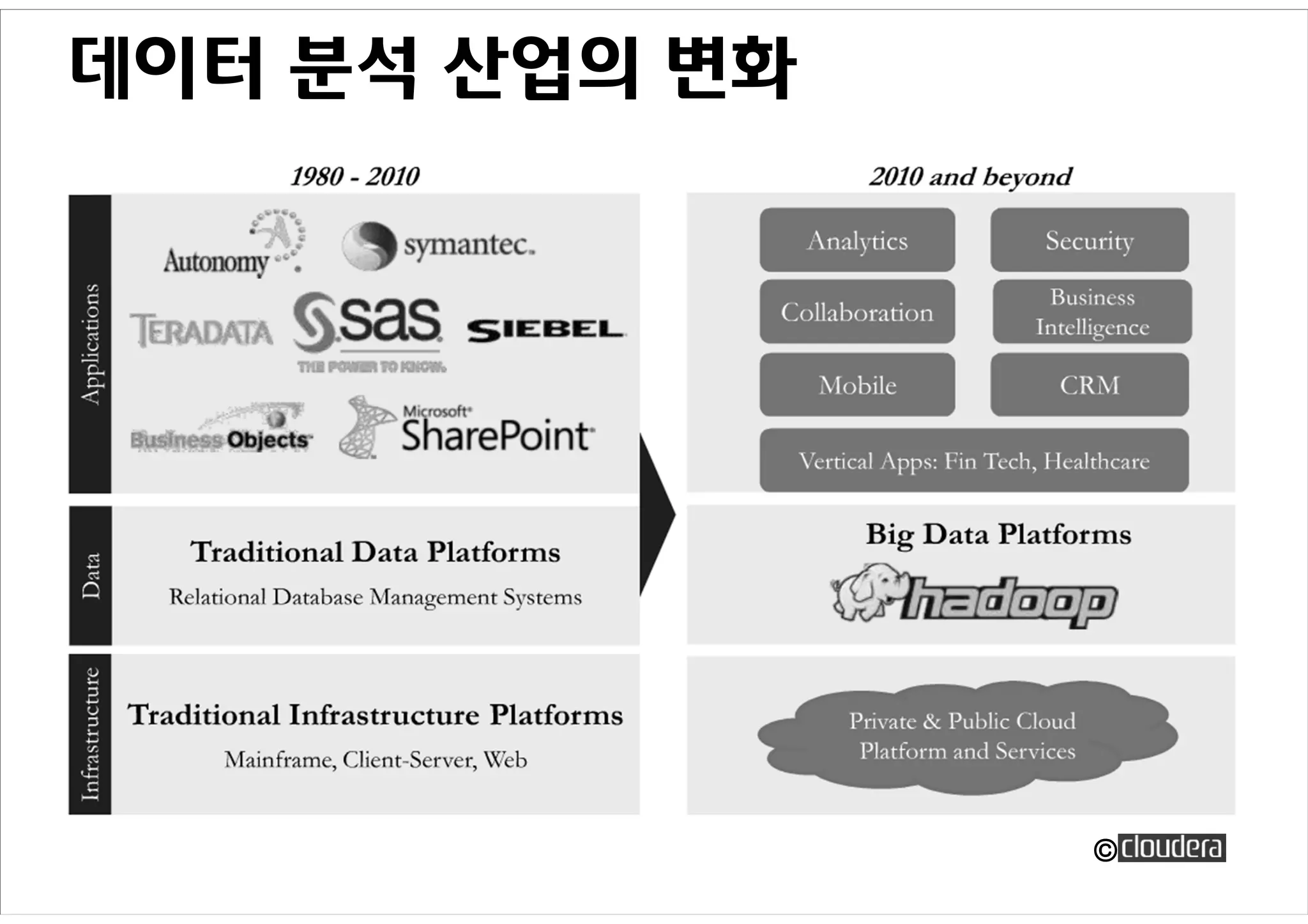
Daum의 Hadoop 이용사례
• 로그 분석 사례
– 전사 로그를 통한 통계 분석
– 광고 및 클릭 로그 분석을 통한 타켓팅
– 카페 로그 분석을 통한 사용자 카페 추천
– 검색 품질 랭킹 분석 및 개선
– 게임 서버 로그 분석 등
• 데이터 분석 사례
– 다음 Top 토픽 분석 및 추천 서비스
– UCC 문서의 스팸 유저 필터링
– 사물 검색 이미지 역색인
– 자연어 처리 텍스트 분석
– 모바일 광고 데이터별 매체 분석 등
• 연구 개발 사례
– SemSearch: 대용량 시맨틱 웹 검색 엔진 개발
– VisualRank: 이미지 유사성 매칭 분석
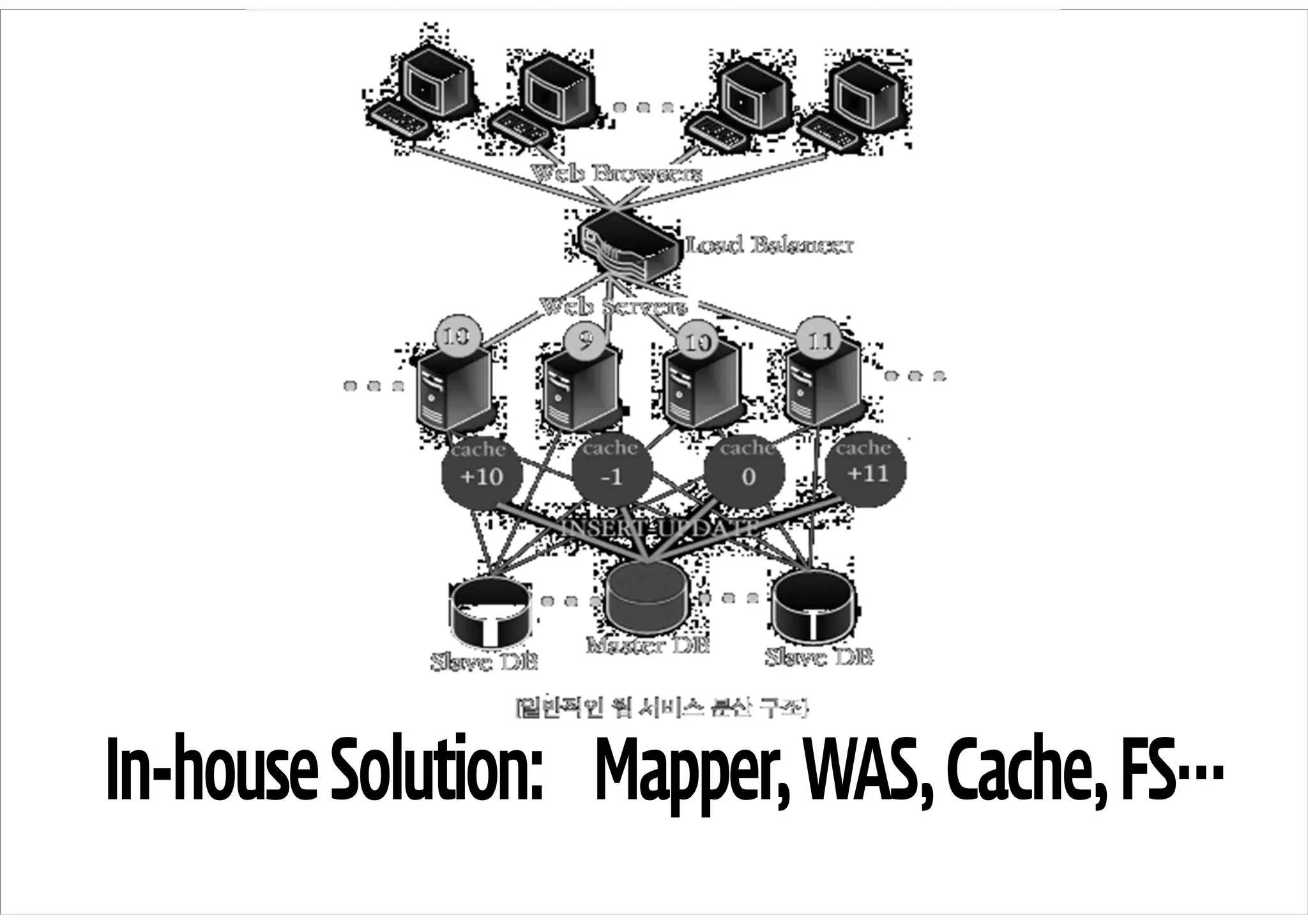
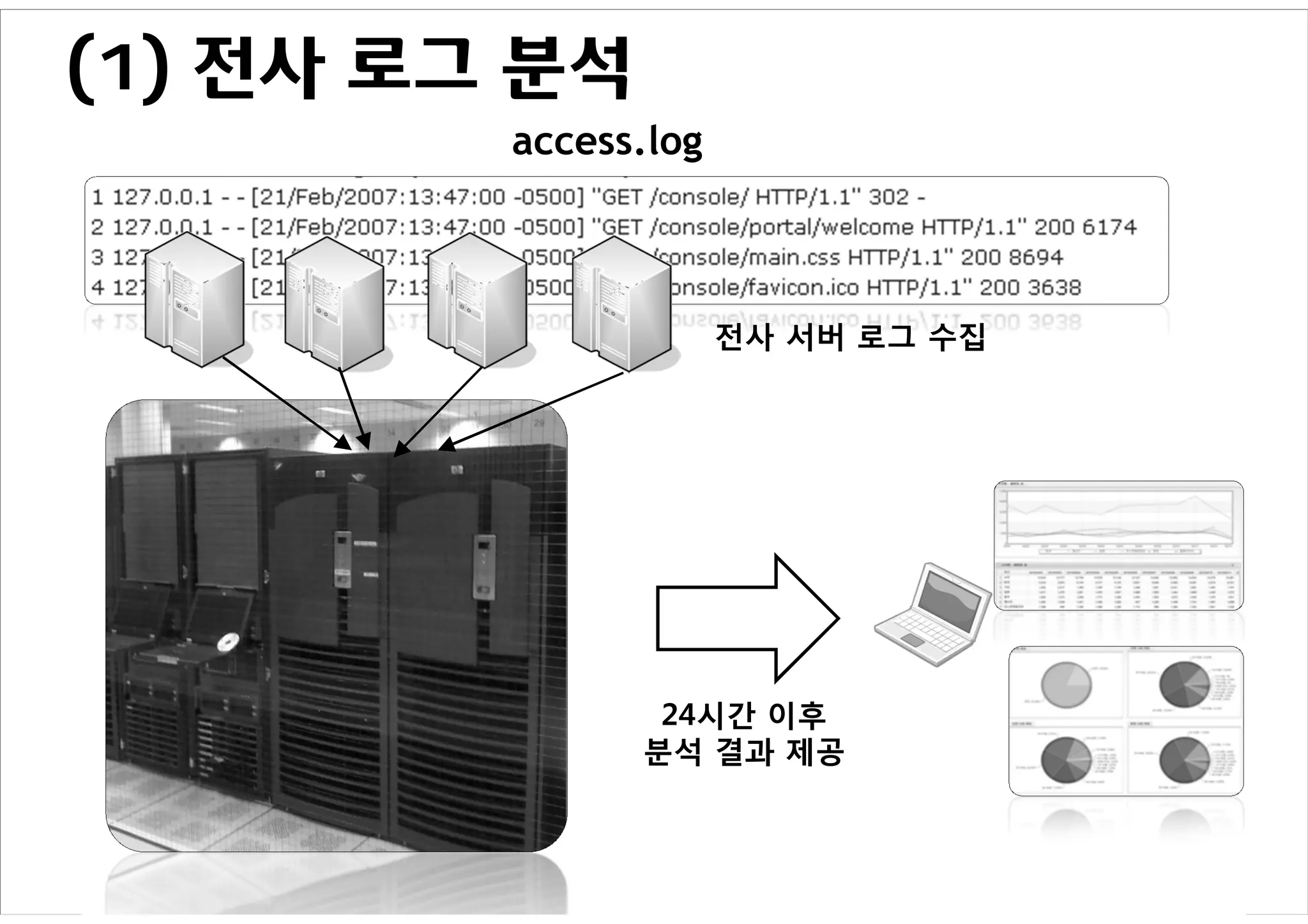
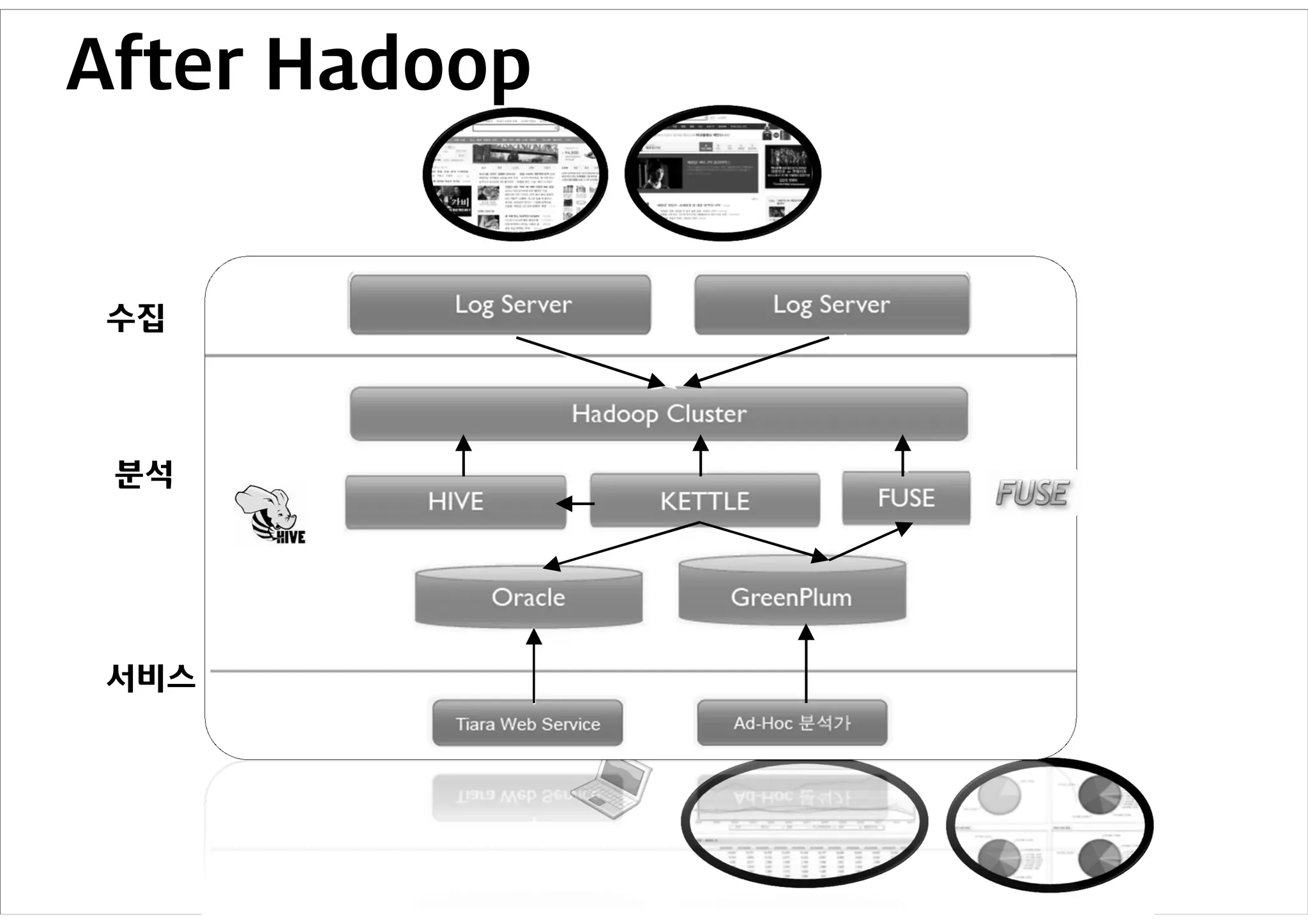
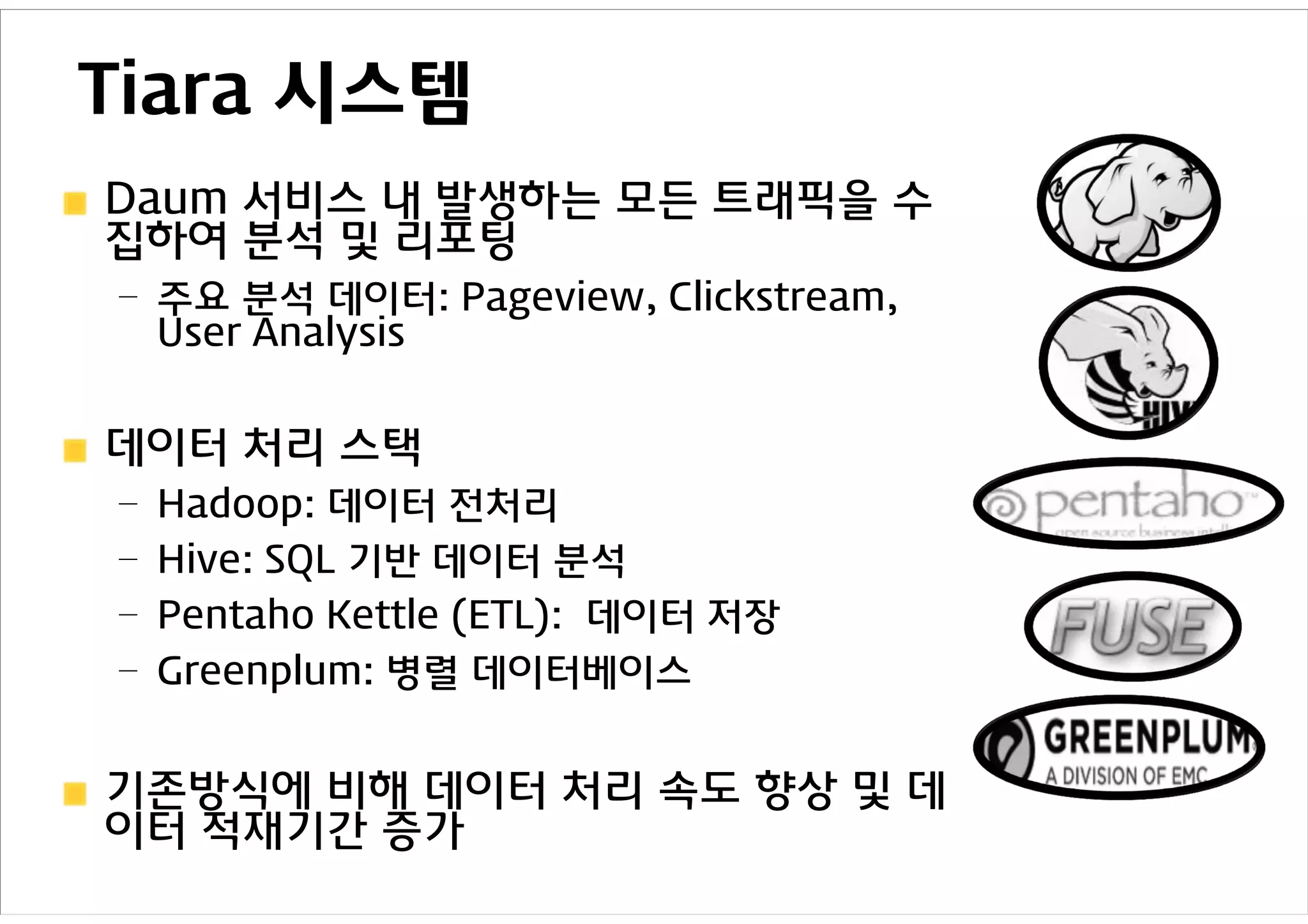
Tiara 시스템
Daum 서비스내 발생하는 모든 트래픽을 수
집하여 분석 및 리포팅
– 주요 분석 데이터: Pageview, Clickstream,
User Analysis
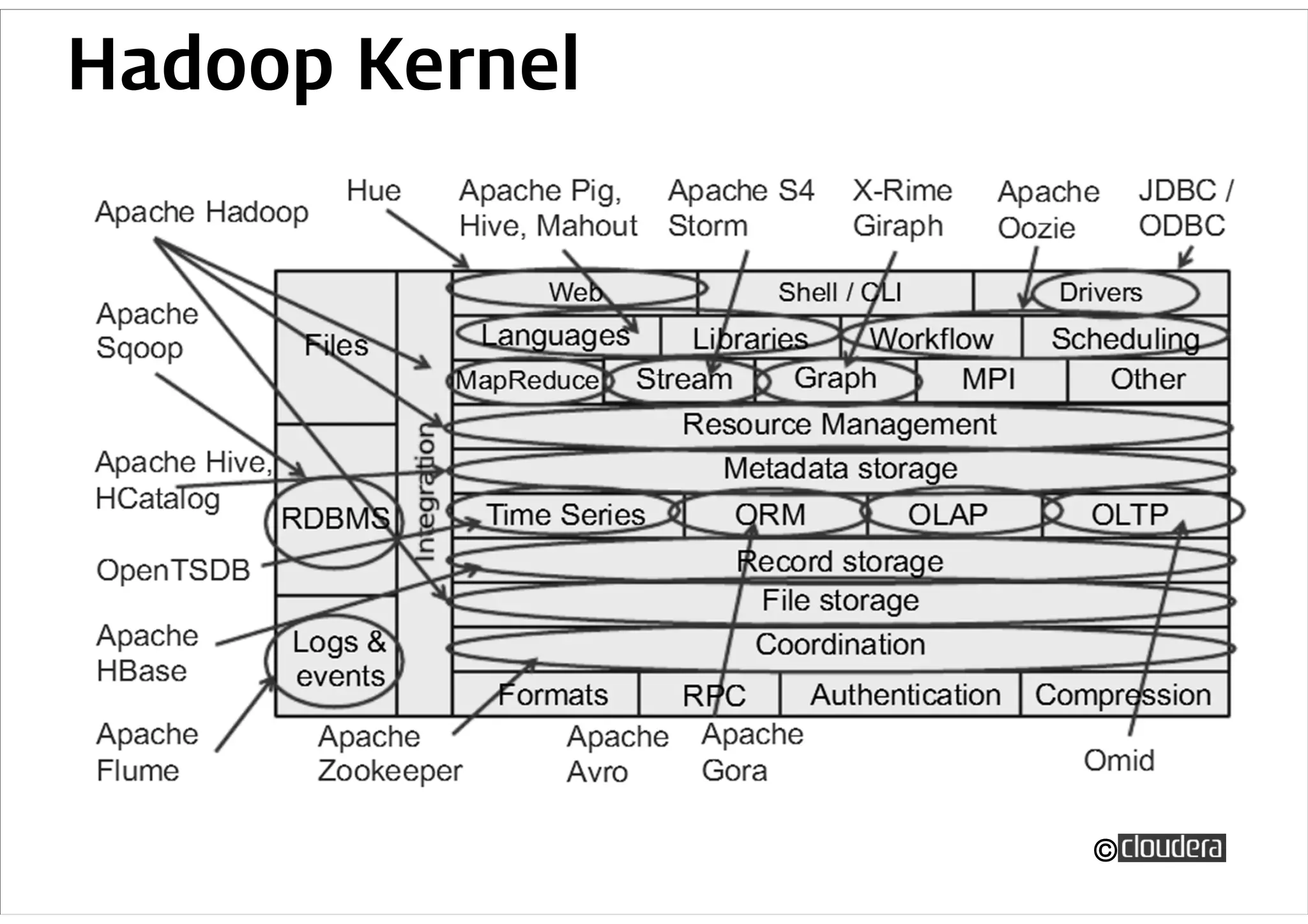
데이터 처리 스택
– Hadoop: 데이터 전처리
– Hive: SQL 기반 데이터 분석
– Pentaho Kettle (ETL): 데이터 저장
– Greenplum: 병렬 데이터베이스
기존방식에 비해 데이터 처리 속도 향상 및 데
이터 적재기간 증가
28.
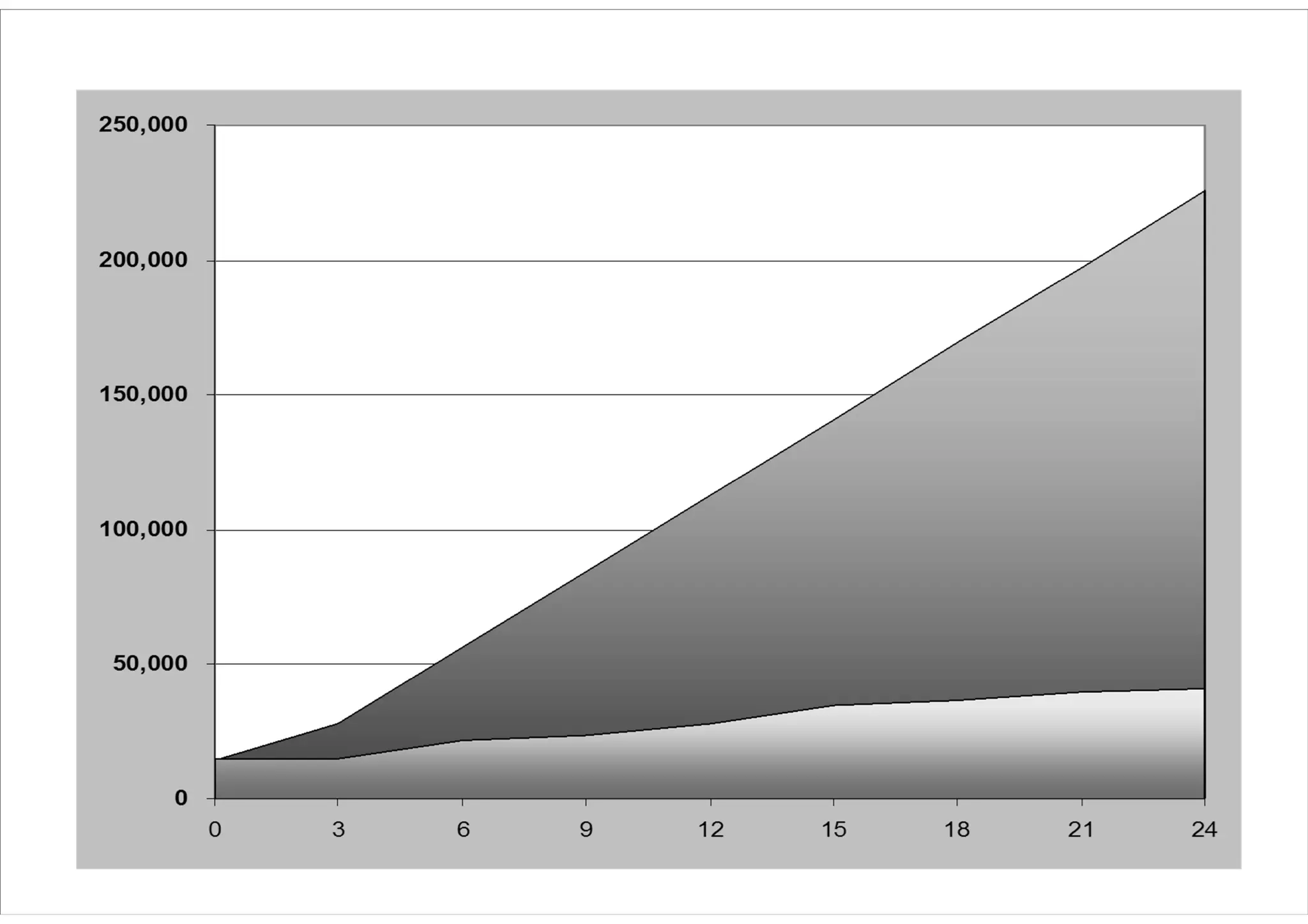
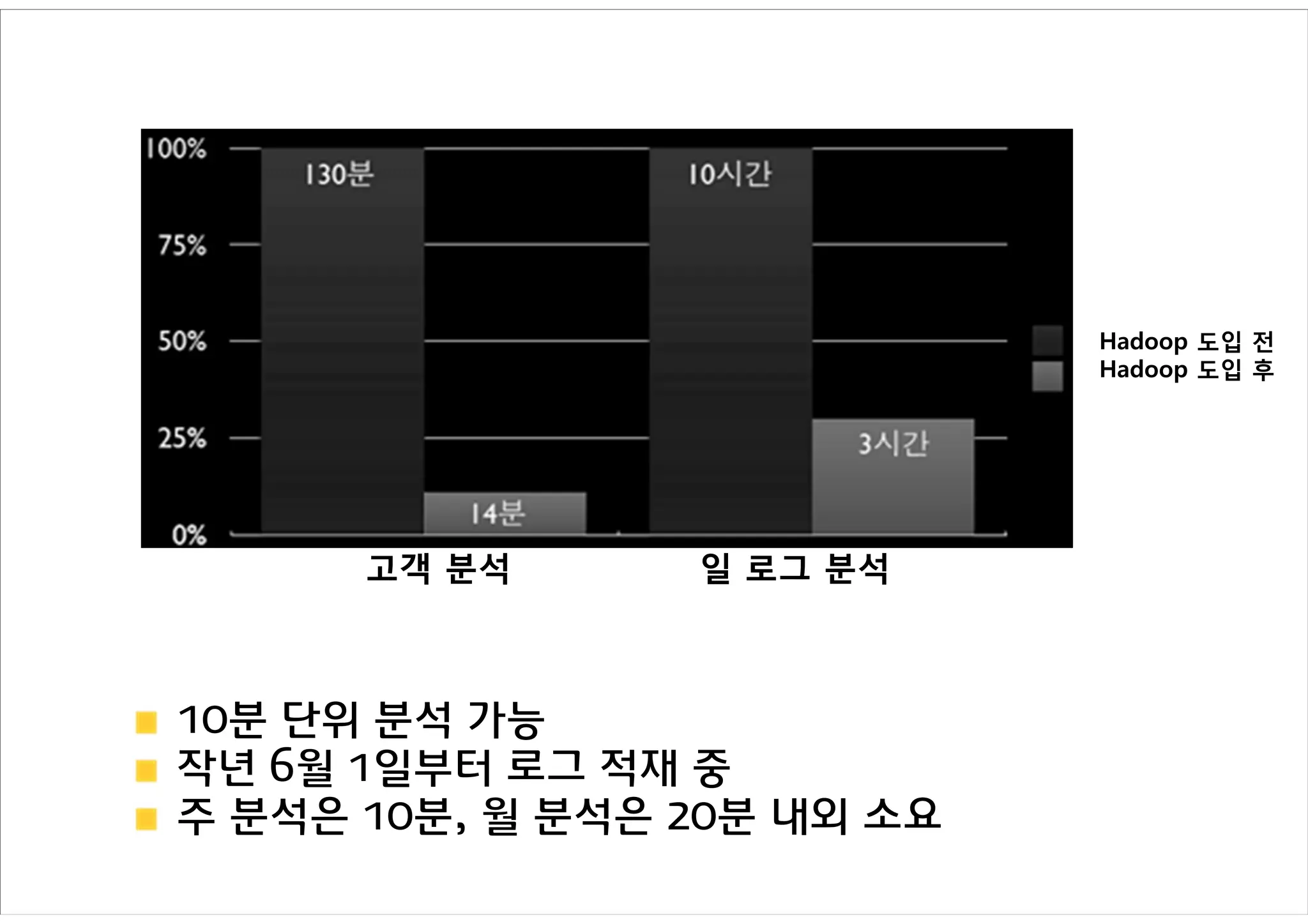
Hadoop 도입 전
Hadoop 도입 후
고객 분석 일 로그 분석
10분 단위 분석 가능
작년 6월 1일부터 로그 적재 중
주 분석은 10분, 월 분석은 20분 내외 소요
(2) 광고 로그분석 시스템
광고 로그 및 통계 처리, 매체 토픽 분류 및 과거 로그 데이터를 기반으로
광고 집행 타켓팅 분석
• input: 과거 집행(노출, 클릭) 로그 데이터 ( 필요에 따라 일, 주, 월 단위
로그 사용)
• output 광고에 대한 사용자별 노출 내역 통계 처리
10분에서, 시간당, 일 단위로 다양한 데이터 산출하여 타게팅 광고 효과 향
상
(1) 다음 Top토픽 분석
Top 화면에 제공할 콘텐츠의 토픽 분석
Hadoop 기반의 머신러닝 도구인 mahout
이용
33.
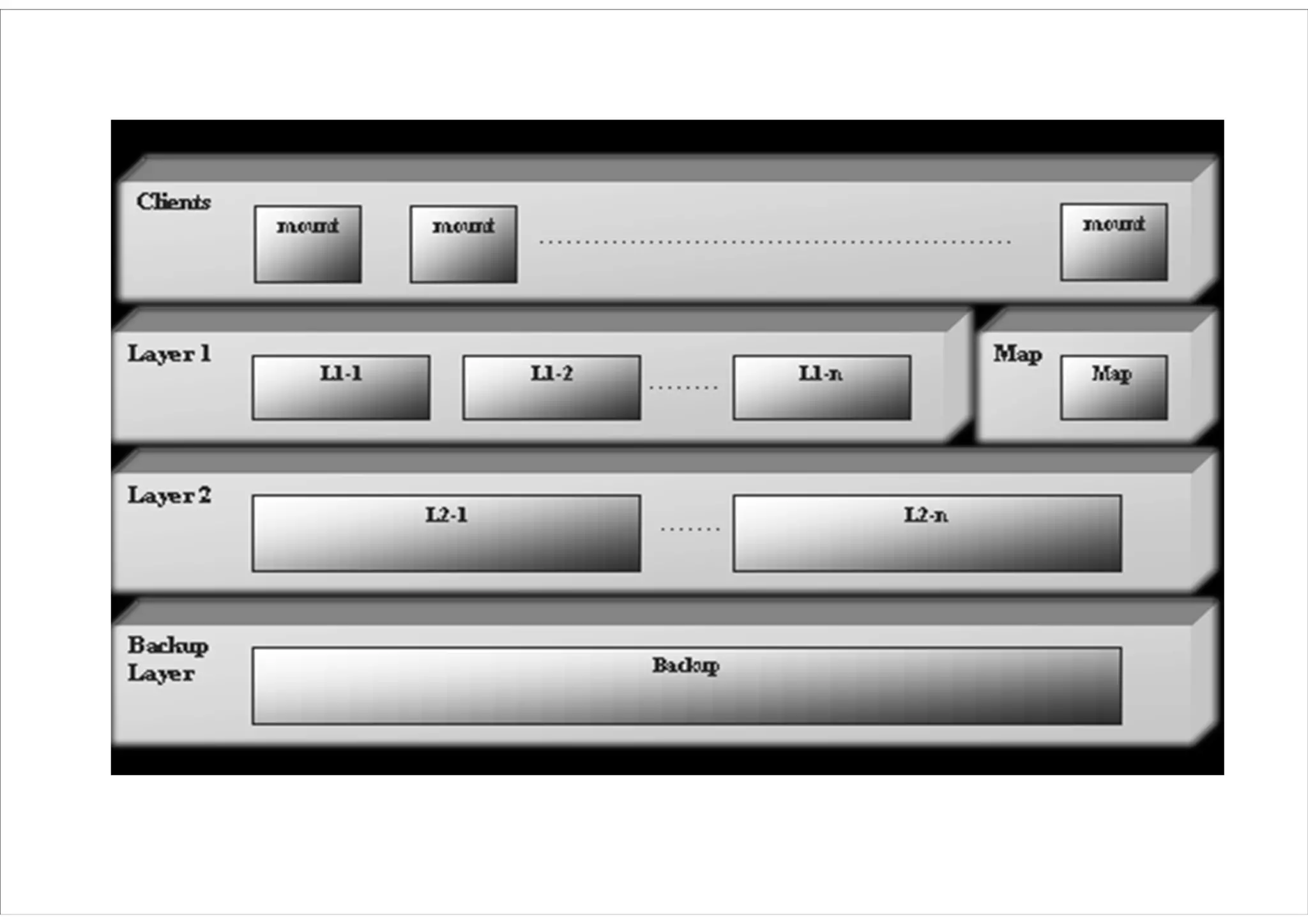
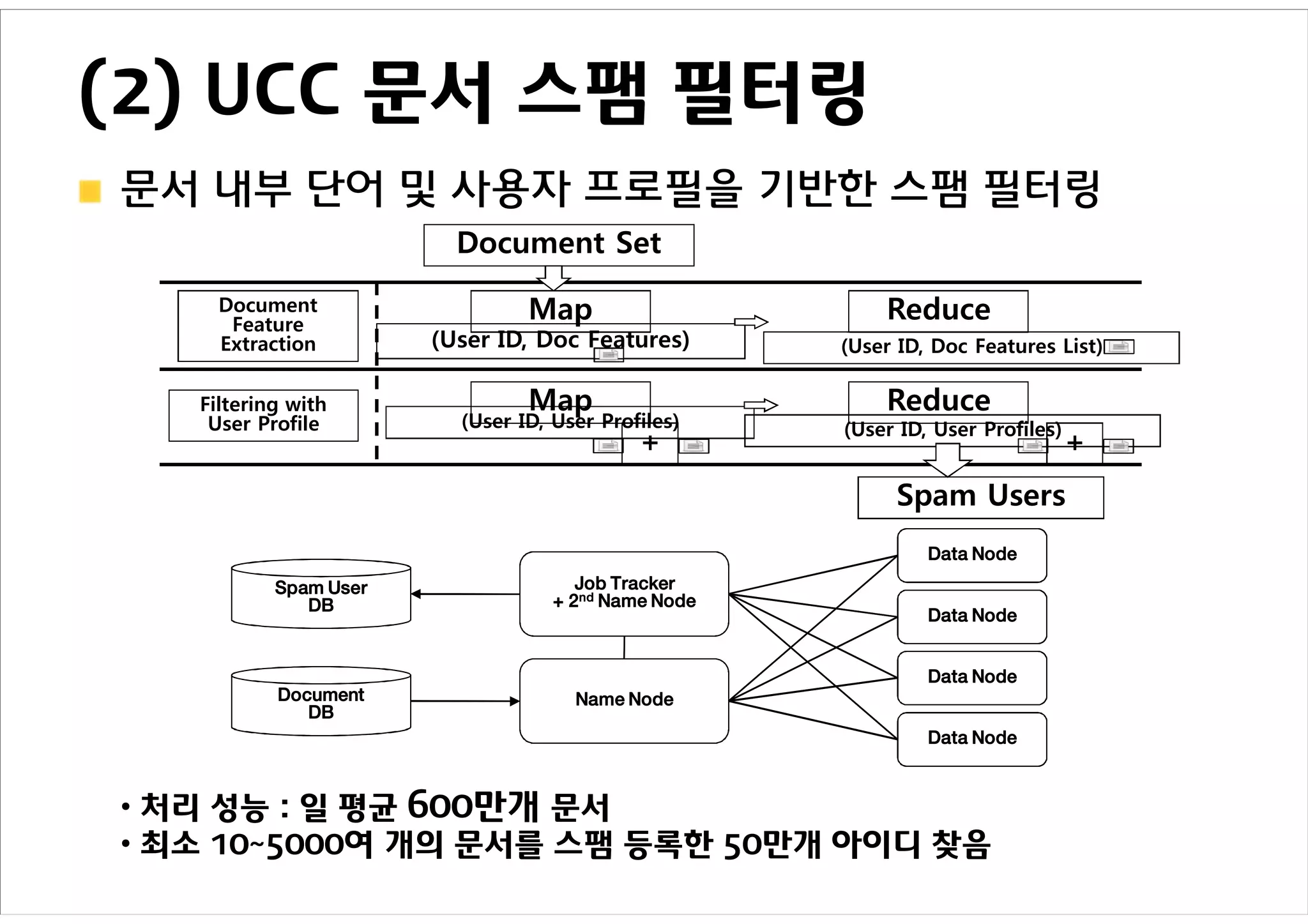
(2) UCC 문서스팸 필터링
문서 내부 단어 및 사용자 프로필을 기반한 스팸 필터링
Document Set
Document
Feature
Map Reduce
Extraction (User ID, Doc Features) (User ID, Doc Features List)
Filtering with Map Reduce
User Profile (User ID, User Profiles) (User ID, User Profiles)
+ +
Spam Users
Data Node
Spam User Job Tracker
DB + 2nd Name Node
Data Node
Data Node
Document Name Node
DB
Data Node
• 처리 성능 : 일 평균 600만개 문서
• 최소 10~5000여 개의 문서를 스팸 등록한 50만개 아이디 찾음
34.
(3) 사물 검색데이터 색인
대용량의 이미지 데이터를 최소한의 시간으
로 분석하여 역 색인과 검색에 필요한 데이터
를 추출
사물검색 대상 이미지의 특징을 분석할 수 있
는 시스템 구축
– 책/음악 앨범/영화 포스터 등 약 150만개
– 각 이미지에서 특징점 추출(260GB)
– 빠르고 안정적인 데이터 분석, 역 색인 데이터
생성
기존 방식 보다 1/10 정도 시간 단축
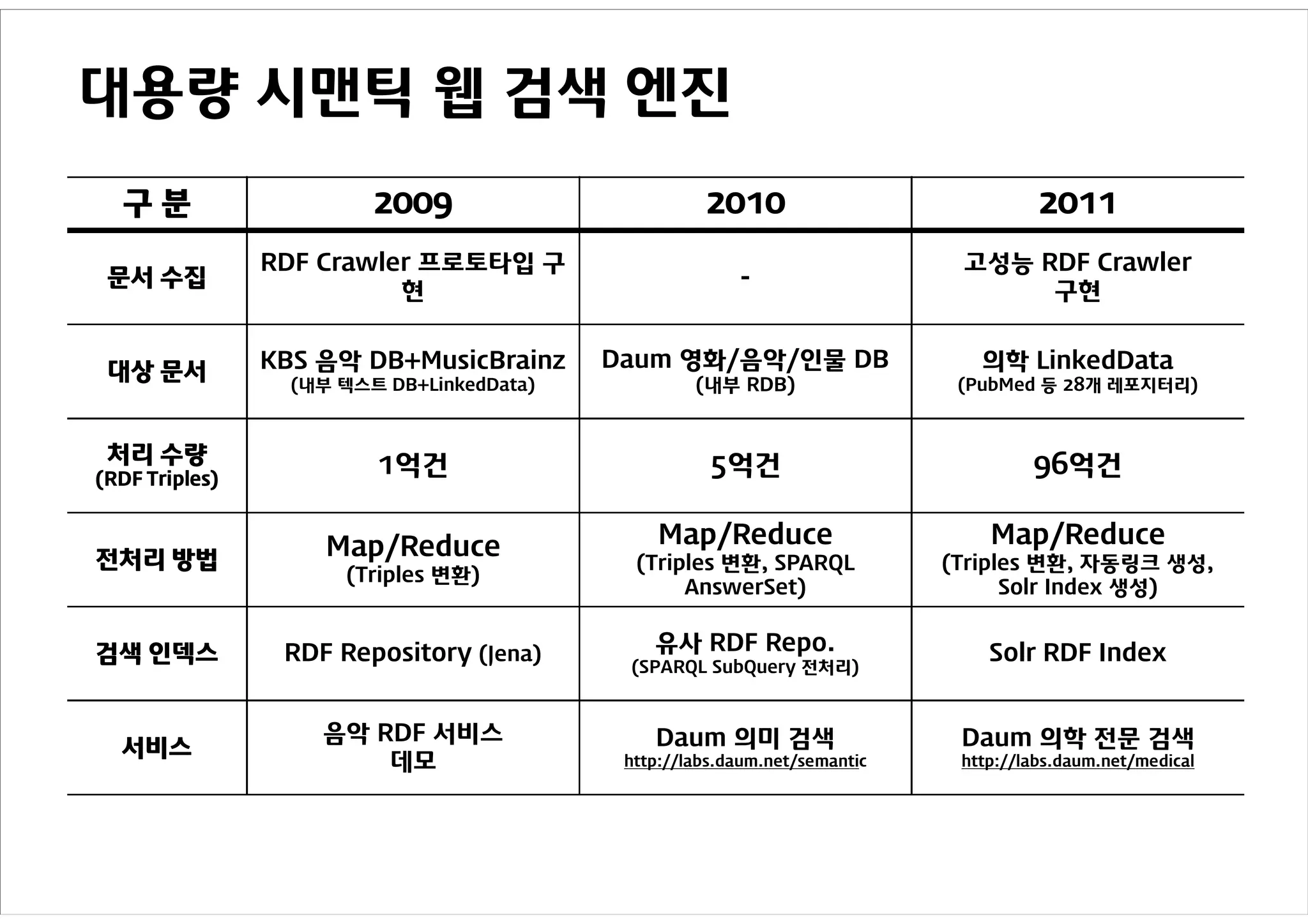
대용량 시맨틱 웹검색 엔진
구분 2009 2010 2011
RDF Crawler 프로토타입 구 고성능 RDF Crawler
문서 수집 -
현 구현
대상 문서 KBS 음악 DB+MusicBrainz Daum 영화/음악/인물 DB 의학 LinkedData
(내부 텍스트 DB+LinkedData) (내부 RDB) (PubMed 등 28개 레포지터리)
처리 수량
(RDF Triples)
1억건 5억건 96억건
Map/Reduce Map/Reduce Map/Reduce
전처리 방법 (Triples 변환, SPARQL (Triples 변환, 자동링크 생성,
(Triples 변환)
AnswerSet) Solr Index 생성)
검색 인덱스 RDF Repository (Jena) 유사 RDF Repo. Solr RDF Index
(SPARQL SubQuery 전처리)
음악 RDF 서비스 Daum 의미 검색 Daum 의학 전문 검색
서비스
데모 http://labs.daum.net/semantic http://labs.daum.net/medical
37.
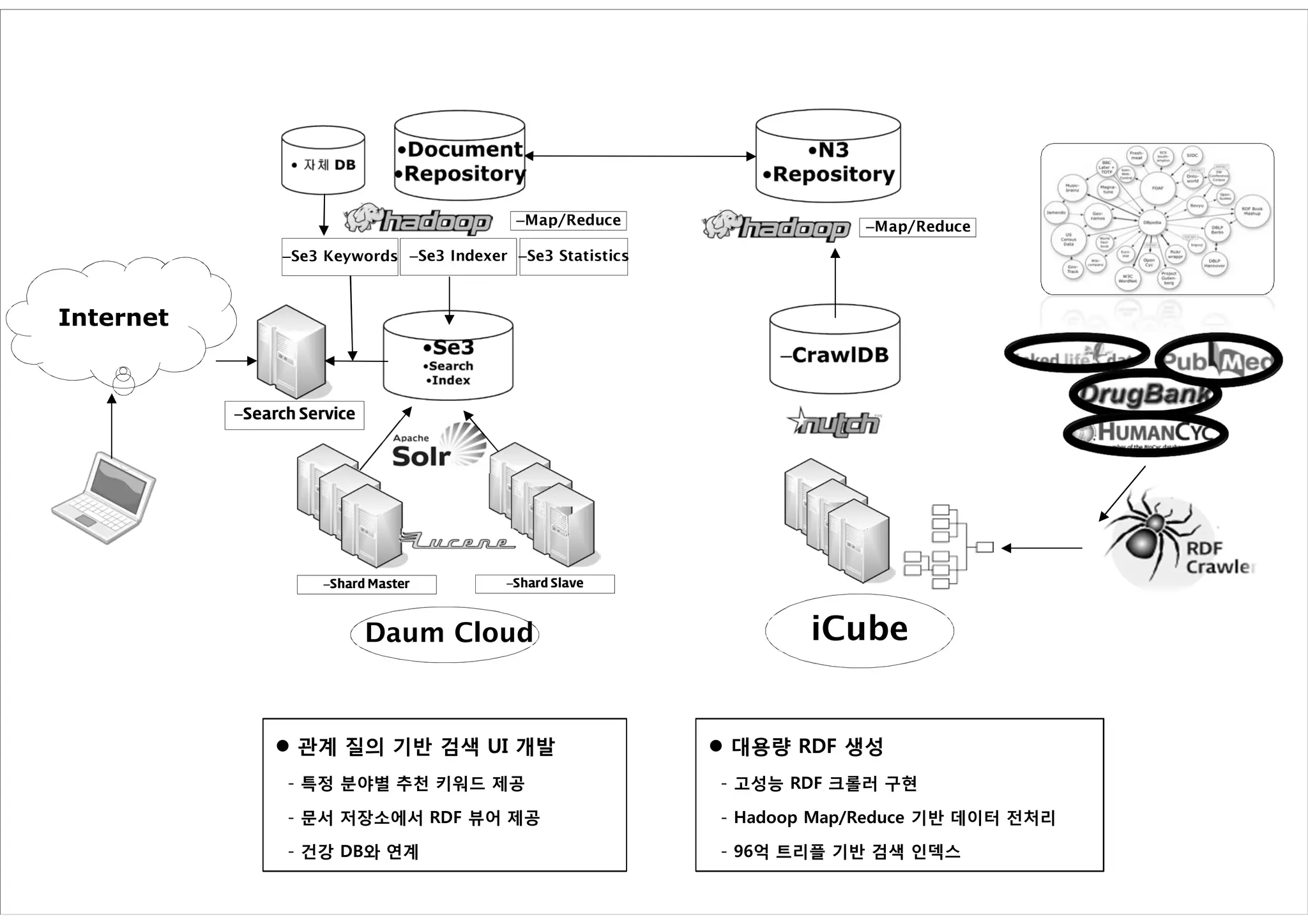
–Map/Reduce –Map/Reduce
–Se3 Keywords –Se3 Indexer –Se3 Statistics
Internet
–Search Service
–Shard Master –Shard Slave
Daum Cloud iCube
관계 질의 기반 검색 UI 개발 대용량 RDF 생성
- 특정 분야별 추천 키워드 제공 - 고성능 RDF 크롤러 구현
- 문서 저장소에서 RDF 뷰어 제공 - Hadoop Map/Reduce 기반 데이터 전처리
- 건강 DB와 연계 - 96억 트리플 기반 검색 인덱스
38.
Daum의 빅데이터 기술전략
사내 기술 코디네이션
– 각 개발자가 Hadoop을 다양하게 활용할 아이디어 개발 및 실험 실행
– Hadoop을 테스트 해 볼 수 있는 클라우드 플랫폼 제공
– 실 서비스 투입 시 기존 운영팀으로 부터 노하우 전수
• 사내 세미나 및 교육 프로그램 운영
• Hadoop Expert를 중심으로 필요 시 노하우 제공
개발자 데이터 접근성 향상
– 데이터 분석가가 아닌 개발자가 직접 데이터에 접근
– 데이터가 있는 곳에서 바로 분석
– 기획자와 비즈니스에서 바로 의사 결정 가능
때로 콘트롤 타워가 진입 장벽과 아이디어 고갈을 가져온다!
– 기술에 따라 어떤 접근을 할지 선택이 중요
Lessons for BigData
기술 내재화가 중요 (No Vendors!)
– 개발자들이 직접 Hadoop을 활용할 수 있는 환경 필요
– 오픈 소스의 적극 활용 및 개발 잉여력 제공
데이터 분석 및 처리의 역할 파괴 (No Data Scientist!)
– 개발자들이 직접 실시간 분석을 위한 Hive 활용
– 문서, 이미지 등 다양한 형태의 데이터 처리를 위한 토대 마련
Small Data를 활용 강화 (No Big Mistakes!)
– Small Data라도 실시간으로 저렴하게 데이터를 처리하고,
– 처리된 데이터를 더 빠르고 쉽게 분석하도록 하여,
– 이를 비즈니스 의사결정에 바로 이용하는 것
– 이것이 바로 BigData 기술을 바른 활용임!






























![[경북] I'mcloud information](https://cdn.slidesharecdn.com/ss_thumbnails/imcloudinformation-151105091525-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[Open Technet Summit 2014] 쓰기 쉬운 Hadoop 기반 빅데이터 플랫폼 아키텍처 및 활용 방안](https://cdn.slidesharecdn.com/ss_thumbnails/open-technet-summit-2014-140313001107-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[경북] I'mcloud opensight](https://cdn.slidesharecdn.com/ss_thumbnails/imcloudopensight-151105092004-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)







![Daum devday 13 [bap]](https://cdn.slidesharecdn.com/ss_thumbnails/daumdevday13-bap-130225010411-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)












