Download as PDF, PPTX










![Copyright © 2018 BESPIN GLOBAL Co., Ltd. All rights reserved | Confidential
http://www.bespinglobal.com
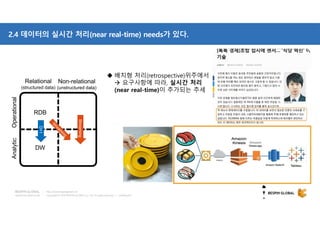
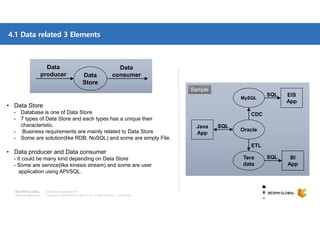
참고: Data store - AWS RDS
Custom
Application Glue
QuickSight
DMS
Producer Consumer
Producer & Consumer
AWS SDK (API) or Library 이용하여 개발 필요
개발 필요없이 AWS Console 또는 CLI 등 사용
[표기]
[QuickSight]
- Fast, easy-to-use business analytics
(SPICE : The Super-fast, Parallel, In-memory, Calculation Engine)
- RDS, Athena, Aurora, Redshift, Redshift Spectrum 지원
[Glue]
- Fully Managed ETL Service
- ETL 작업
- Metadata (테이블 정의, 스키마 등) Catalog 생성 : Athena/EMR/Redshift Spectrum 에서 사용
- 스케줄링 제공 : 종속성 확인, 작업 모니터링 및 알림 기능이 탑재
- Apache Spark 환경에서 실행
[Supported File]
- JSON, CVS, ORC, Apache Parquet, Avro
- gzip, bzip2, lz4
[DMS]
- DMS Source
: Oracle, MySQL, MS-SQL, MariaDB, PostgreSQL, Aurora for MySQL
- Target
: Oracle, MySQL, MS-SQL, MariaDB, PostgreSQL, Aurora for MySQL
: Redshift, S3](https://image.slidesharecdn.com/awsbigdatastrategyandrelatedservices-181210085127/85/AWS-BigData-AWS-20-320.jpg)
![Copyright © 2018 BESPIN GLOBAL Co., Ltd. All rights reserved | Confidential
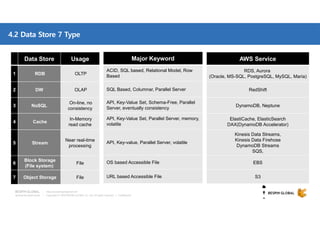
http://www.bespinglobal.com
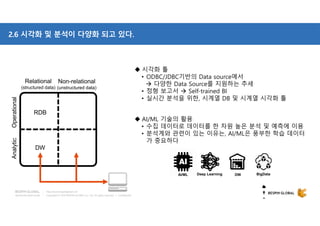
참고: Data store - AWS Redshift
S3
Apache SPARK
Glue
DMS
EMR
DynamoDB
Lambda
Kinesis Firehose
Producer Consumer
Producer & Consumer
Custom
Application
EMR Cluster 의 HDFS 안의 파일을 병렬로 Loading 함
AWS SDK (API) or Library 이용하여 개발 필요
개발 필요없이 AWS Console 또는 CLI 등 사용
[표기]
QuickSight
[Apache Spark]
- In-Memory 기반의 대용량 데이터 고속 처리 엔진, 범용의 분산 클러스터 컴퓨팅 프레임워크
- 정형화된 데이터 처리 (Spark SQL), 실시간 처리 (Spark Streaming), 머신러닝 (Mlib) 등 지원
- Big Data 차세대 구조 (Big Think) : HDFS + YARN + Spark 구조
[AWS EMR]
- Apache Hadoop, Spark 등 빅 데이터 프레임워크 실행을 간소화하는 관리형 클러스터 플랫폼
- Apache Hive 및 Apache Pig와 같은 관련 오픈 소스 프로젝트 지원 (분석, BI 처리)
- S3, DynamoDB 등과 양방향으로 데이터 변환 및 이동 처리](https://image.slidesharecdn.com/awsbigdatastrategyandrelatedservices-181210085127/85/AWS-BigData-AWS-21-320.jpg)
![Copyright © 2018 BESPIN GLOBAL Co., Ltd. All rights reserved | Confidential
http://www.bespinglobal.com
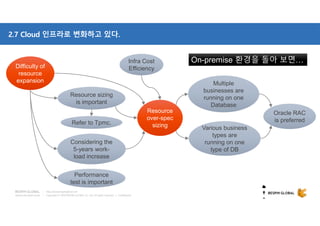
참고: Data store - AWS DynamoDB
AWS CLI
…
AWS SDK
(Application)
Apache Hadoop Apache Hive Apache Spark
EMR
Redshift
Redshift Copy
DynamoDB Streams
DynamoDB 의 Table Activity 로깅을 이용
- Cross-Region Replication Library 사용 (Region 간 복제 구현)
- DynamoDB Streams Kinesis Adapter (KCL 과 유사) 사용하여 Stream 데이터 처리
- DynamoDB Streams 의 이벤트를 자동으로 응답하는 Lambda 함수 구현 처리
DAX
(DynamoDB Accelerator)
사용자가 API 을 이용하여 Put/Get 구현
DynamoDB 전용 In-Memory Cache 임
DynamoDB API 호환
- App 코드 수정 없이 아래의 작업이 필요함
- Table 관리 작업 (DDL 등) 지원 안함
[작업 순서]
1. DAX Cluster 생성
2. DAX SDK (DynamoDB API 호환) 다운로드
3. DXA Client 사용하도록 App 을 rebuild
4. DAX Cluster End-Point 지정
[Caching Strategies]
- Read : Cache 누락 시 DynamoDB 에서 자동 검색
- Write : DynamoDB 에 기록 후 Cache 에 Update
(Write-Through Cache)
Lambda
Notification
Producer Consumer
Producer & Consumer
DynamoDB Streams
- DynamoDB 와 DynamoDB Streams 의 End-Point 가 다름
- Logstach Plug-in 을 이용하여 Elastic Search 로 데이터 연동
Apache Hadoop/Hive/Spark 등 에서 AWS EMR Connector 사용
- AWS EMR 환경에서 HiveQL 을 사용하여 데이터 조회 및 저장 가능
AWS SDK (API) or Library 이용하여 개발 필요
개발 필요없이 AWS Console 또는 CLI 등 사용
[표기]
[DynamoDB]
- Fully Managed NoSQL Database Service
- 원활한 확장성으로 예측 가능한 (일관된) 성능 보장 (성능 지연 대신 요청 거부 : Throttling)
: RCU/WCU 설정 및 Strongly/Eventually Consistent Read 제공](https://image.slidesharecdn.com/awsbigdatastrategyandrelatedservices-181210085127/85/AWS-BigData-AWS-22-320.jpg)
![Copyright © 2018 BESPIN GLOBAL Co., Ltd. All rights reserved | Confidential
http://www.bespinglobal.com
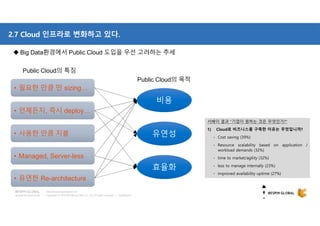
참고: Data store - AWS ElastiCache
AWS CLI
…
AWS SDK
(Application)
API
Java, PHP, Python, Ruby, .NET 용 SDK 존재
언어별 SDK 을 이용하여 API 사용하여 구현
API
Producer Consumer
Producer & Consumer
AWS SDK (API) or Library 이용하여 개발 필요
개발 필요없이 AWS Console 또는 CLI 등 사용
[표기]
[ElastiCache]
- Key/Value 기반 In-Memory Cache (Redis, Memcached 엔진 지원)
- Cache 선택 시 고려 사항 : 속도 및 비용, 데이터 및 액세스 패턴, 기한 경과
예) Session 정보 유지 및 Sticky Session 처리 시 사용](https://image.slidesharecdn.com/awsbigdatastrategyandrelatedservices-181210085127/85/AWS-BigData-AWS-23-320.jpg)
![Copyright © 2018 BESPIN GLOBAL Co., Ltd. All rights reserved | Confidential
http://www.bespinglobal.com
참고: Data store - AWS Kinesis Data Streams
Producer Consumer
Kinesis–enabled
Application
Kinesis–enabled
Application
Log4J Appender
Apache Flume
Apache Fluentd
Kinesis Agent
A
Kinesis Firehose
Lambda
EMR
Apache Storm
Producer & Consumer
Apache Log4j Appender 을 Kinesis Log4j Appender 로 변경하여 사용함
Apache Fluentd 에서 Kinesis Data Stream 을 위한 Plugin 사용함
Kinesis Connector Lib (KCL 필요)
DynamoDB Redshift S3 ElasticSearch
Kinesis Data Analytics
현재 Java, Python, Node.js, .NET 지원
단, Java 설치 필요
독립형 Java 프로그램 (설치,구성 및 시작 필요)
Java 만 지원 가능함
Stream 데이터를 표준 SQL 로 처리 및 분석 가능
(실시간 분석 생성, 실시간 대시보드 생성, 실시간 지표 생성)
처리 결과를 다른 Kinesis Streams 에 전달 가능
Kinesis 스트림을 읽고 분석
Hive의 경우 두 개의 다른 Kinesis 스트림을 Join 할 수 있음
AWS SDK (API) or Library 이용하여 개발 필요
개발 필요없이 AWS Console 또는 CLI 등 사용
[표기]
Pulg-in
[Fluentd]
- 데이터 수집, 소비를 위한 오픈 소스 엔진
- 다양한 로그에 대한 Filter, Buffer, Routing 처리
- 다양한 Plug-in 이 존재
[Apache Storm]
- 실시간 분산 클러스터 컴퓨팅 프레임워크
[Apache Flume]
- 분산 환경에서 대량의 로그 데이터를 효과적으로 수집, 처리, 전송할 수 있는 프레임워크
- 단순하며 유연한 Streaming Data Flow 아키텍처를 기반](https://image.slidesharecdn.com/awsbigdatastrategyandrelatedservices-181210085127/85/AWS-BigData-AWS-24-320.jpg)
![Copyright © 2018 BESPIN GLOBAL Co., Ltd. All rights reserved | Confidential
http://www.bespinglobal.com
참고: Data store - AWS Kinesis Data Firehose
Kinesis Agent
A독립형 Java 프로그램 (설치,구성 및 시작 필요)
Kinesis Data Analytics
IoT
Redshift
S3
Splunk
ElasticSearch
Lambda
Cloud Watch
Cloud Watch 의 Log 와 Event 데이터 처리 가능
Producer Consumer
Producer & Consumer
Kinesis Streams
A
Kinesis Stream 와 연결된 Firehose 는
Analytics 의 Producer 가 될 수 없음
Firehose Put API 사용
- Java, Node.js, Python, Ruby 용 AWS SDK 이용
Apache Fluentd
Apache Fluentd 는 Fluentd Plugin 사용
(Kinesis Firehose API 사용)
Output Data 에 대한 Transform 처리
Kinesis Firehose
AWS SDK (API) or Library 이용하여 개발 필요
개발 필요없이 AWS Console 또는 CLI 등 사용
[표기]](https://image.slidesharecdn.com/awsbigdatastrategyandrelatedservices-181210085127/85/AWS-BigData-AWS-25-320.jpg)
![Copyright © 2018 BESPIN GLOBAL Co., Ltd. All rights reserved | Confidential
http://www.bespinglobal.com
참고: Data store - AWS ElasticSearch
Lambda
S3Kinesis Streams
S3, Kinesis, DynamoDB Streams 의 Event Handler 로 사용
DynamoDB Streams Cloud Watch
Cloud Trail
kibana
데이터 저장 영역으로 EBS 사용
Kinesis Firehose
Logstash
ElasticSearch 에 내장됨
ElasticSearch 에 내장됨
Kibana 을 위한 End-Point 가 제공됨
Producer Consumer
Producer & Consumer
AWS CLI
…
AWS SDK
API
AWS SDK (API) or Library 이용하여 개발 필요
개발 필요없이 AWS Console 또는 CLI 등 사용
[표기]
Apache Fluentd
[Logstash]
- 실시간 파이프라인 기능을 가진 오픈소스 데이터 수집 엔진
- 서로 다른 소스의 데이터를 탄력적으로 통합, 선택한 목적지로 데이터를 정규화 처리
- 다양한 Plug-in 이 존재
[Kibana]
- 강력하고 화려한 오픈 소스 데이터 시각화 플랫폼
- 다양한 시각화 도구를 사용자 지정 대시보드와 결합하여 데이터 통찰력 제공
- 데이터 Discovery/Visualize/Dashboard/Setting 기능 제공
[ElasticSearch]
- ElasticSearch 을 쉽게 배포/운영하고 확장 가능한 서비스
- 로그 분석, 전체 텍스트 검색 및 Application 모니터링 기능](https://image.slidesharecdn.com/awsbigdatastrategyandrelatedservices-181210085127/85/AWS-BigData-AWS-26-320.jpg)
![Copyright © 2018 BESPIN GLOBAL Co., Ltd. All rights reserved | Confidential
http://www.bespinglobal.com
참고: Data store - AWS EBS
AWS CLI
…
AWS SDK OS Command
Create, Delete, Describe, Attach, Detach 등 가능
Producer Consumer
Producer & Consumer
S3
EC2 Snapshot & Restore 시 사용됨
(현재 Incremental Backup 만 가능함)
AWS SDK (API) or Library 이용하여 개발 필요
개발 필요없이 AWS Console 또는 CLI 등 사용
[표기]](https://image.slidesharecdn.com/awsbigdatastrategyandrelatedservices-181210085127/85/AWS-BigData-AWS-27-320.jpg)
![Copyright © 2018 BESPIN GLOBAL Co., Ltd. All rights reserved | Confidential
http://www.bespinglobal.com
참고: Data store - AWS S3
DMS
Glue
EMR S3
Transfer Acceleration
Kinesis Firehose
Snowball
Edge/Mobile
Storage
Gateway
On Premise
(Data Center)
Athena
EBS
Redshift Spectrum
SNSSQSLambda
RedshiftUnload/Copy
Redshift
AWS CLI
…
AWS SDK
S3 API 사용
- Management, Data Operation 제공
- ls, cp, mv, sync, Upload/Download 기능 제공
S3 Select SDK 사용
- S3 레벨의 데이터 필터링 선 처리 (off-load 검색)
- AWS EMR 기반 Presto 이용한 ANSI SQL 쿼리
- Lambda, Java, Python 용 Select SDK 이용
대용량 S3 객체에 대한 빠른 전송 처리
객체의 변경 사항에 대한 이벤트 감지 후 호출
S3 데이터를 Redshift 에 로딩없이 S3 데이터 조회
S3 데이터를 Redshift 데이터와 같이 조회
Interactive Query Service
S3 데이터를 표준 SQL 로 조회
Producer Consumer
Producer & Consumer
QuickSight
AWS SDK (API) or Library 이용하여 개발 필요
개발 필요없이 AWS Console 또는 CLI 등 사용
[표기]
Apache Fluentd
[Presto]
- 짧은 지연 시간의 임시 데이터 분석용 오픈 소스 분산 SQL 쿼리 엔진
- 표준 ANSI SQL 지원
- HDFS 및 S3 데이터 지원
[S3]
- AWS 핵심 Service, AWS Big Data 전략의 핵심 Service](https://image.slidesharecdn.com/awsbigdatastrategyandrelatedservices-181210085127/85/AWS-BigData-AWS-28-320.jpg)
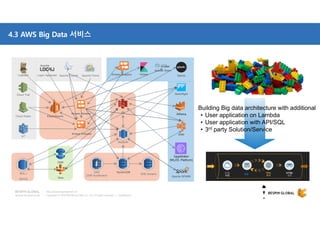







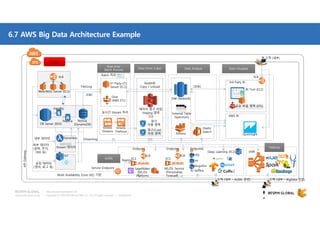

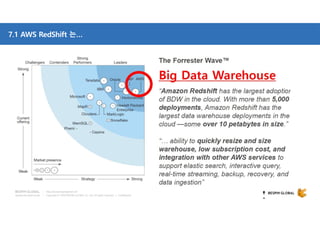
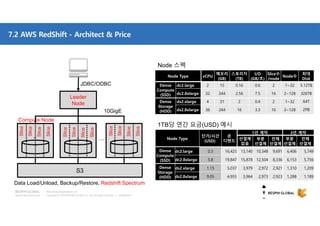
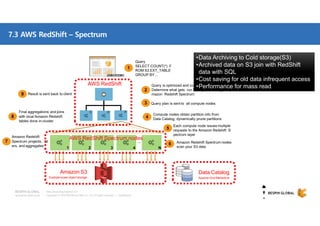

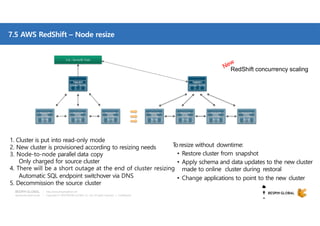

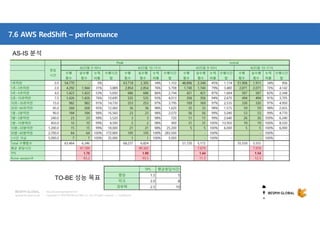
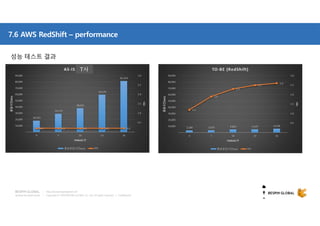





클라우드 기반 데이터 웨어하우스(DW)에 대한 사장의 선택지가 풍부해지고 있습니다. DW 구축과 운영방식을 송두리째 바꿀 클라우드 DW의 기술적 특징과 시장에서 주목하는 AWS RedShift에 대해 살펴보세요. 목차 1. 시작하면서 1) Database 아키텍처와 고려사항 2) 최근까지의 7가지 트렌드 3) Big Data 도전 과제 2. AWS Big Data 전략 4) Data Store 관점에서의 AWS 서비스 5) Big Data Architecting process 6) AWS Big data 서비스 3. AWS RedShift 소개
![[AWS & 베스핀글로벌 - 스타트업, 클라우드에 날개를 달자! 세미나] 효과적으로 클라우드 사용하기](https://cdn.slidesharecdn.com/ss_thumbnails/session02bespinglobalhowtousecloudeffectively062818-180702075745-thumbnail.jpg?width=640&height=640&fit=bounds)



![[IDG Tech Webinar] “클라우드 비용, 더 아낄 수 있다” 실전 클라우드 비용 최적화 가이드](https://cdn.slidesharecdn.com/ss_thumbnails/idgtvopsnowwebinarbespinglobal-180712014609-thumbnail.jpg?width=640&height=640&fit=bounds)



![[VDI on Azure] DaaS 구축과 운영, 신화와 현실](https://cdn.slidesharecdn.com/ss_thumbnails/daasseminar-200410015013-thumbnail.jpg?width=640&height=640&fit=bounds)
![[AWSxBespin Startup Webinar] AWS, 스타트업의 비즈니스에 날개를 달다.](https://cdn.slidesharecdn.com/ss_thumbnails/wellarchitedtedreview-200907051223-thumbnail.jpg?width=640&height=640&fit=bounds)




![[AWS & 베스핀글로벌 - 스타트업, 클라우드에 날개를 달자! 세미나] Why Startup loves Cloud](https://cdn.slidesharecdn.com/ss_thumbnails/session01awswhystartupslovecloud062818thanks-180702075744-thumbnail.jpg?width=640&height=640&fit=bounds)
![[웨비나] 교육, 클라우드로 혁신하다](https://cdn.slidesharecdn.com/ss_thumbnails/aws-webinar-0611-200612080331-thumbnail.jpg?width=640&height=640&fit=bounds)






![[AWS & 베스핀글로벌, 바이오∙헬스케어∙제약사를 위한 세미나] 클라우드 소개 및 도입 로드맵](https://cdn.slidesharecdn.com/ss_thumbnails/biohealthcareseminarsession02-180614105441-thumbnail.jpg?width=640&height=640&fit=bounds)


![[AWS & 베스핀글로벌, 바이오∙헬스케어∙제약사를 위한 세미나] 클라우드 컴퓨팅 정부 규제 관련 사항 안내 & AWS Case Stud...](https://cdn.slidesharecdn.com/ss_thumbnails/biohealthcareseminarsession05-180614105850-thumbnail.jpg?width=640&height=640&fit=bounds)




![[E-commerce & Retail Day] Data Freedom을 위한 Database 최적화 전략](https://cdn.slidesharecdn.com/ss_thumbnails/datafreedomdatabase-171027021754-thumbnail.jpg?width=640&height=640&fit=bounds)








![[Games on AWS 2019] AWS 입문자를 위한 초단기 레벨업 트랙 | AWS 레벨업 하기! : 데이터베이스 - 박주연 AWS 솔...](https://cdn.slidesharecdn.com/ss_thumbnails/04gamesonawsawsdatabase-191014082829-thumbnail.jpg?width=640&height=640&fit=bounds)







![[Keynote] 슬기로운 AWS 데이터베이스 선택하기 - 발표자: 강민석, Korea Database SA Manager, WWSO, A...](https://cdn.slidesharecdn.com/ss_thumbnails/d3s01aws-230704014400-3eeae447-thumbnail.jpg?width=640&height=640&fit=bounds)

![[웨비나] 다중 AWS 계정에서의 CI/CD 구축](https://cdn.slidesharecdn.com/ss_thumbnails/200617-aws-webinar-200622035651-thumbnail.jpg?width=640&height=640&fit=bounds)










