사회 경제적 배경
저성장시대
• 모든 영역에서 치열해진 경쟁
• 기업의 평균 수명 단축
• 변화하는 환경에 빠르게 대응해야 함
ICT 기술의 일반화
• 모바일 디바이스 + 인터넷의 조합
• 일상생활의 깊은 곳까지 ICT 기술의 침투
• 개인 / machine 이 생성한 데이터 폭증
인구절벽
• 2016년을 정점으로 생산가능 인구 대폭 감소
• 소비가능 인구의 감소 —> 소비절벽
로봇과 AI
• 폭증하는 데이터를 활용한 Smart Machine
• Machine이 수동적인 도구가 아닌 능동적 주체
• cyber 영역 / physical 영역의 경계 모호
모든 조직은 변화하는 환경에 빠르게 적응해야 생존
빠른 적응 = 빠르고 정확한 의사결정
내재된 ICT 기술 역량 강화는 필수
2
3.
• 물류, 통신등 모든 제반환경의 효율성이 압도적으로 향상
• 발달된 네트워크를 통한 시장의 반응 역시 엄청나게 빨라짐
• 개인 고객들의 needs 까지 파악할 수 있을 정도로 데이터가 풍부해짐
• 이에 따라, 소비자 주도의 micro market에 정확하고 빠른 대응을 하는 기업이 시장을 주도함
—> 빠르고 정확한 의사결정이 기업 경쟁력의 핵심
Mass market - 공급자 주도 Micro market - 소비자 주도
3
21세기의 기업환경
4.
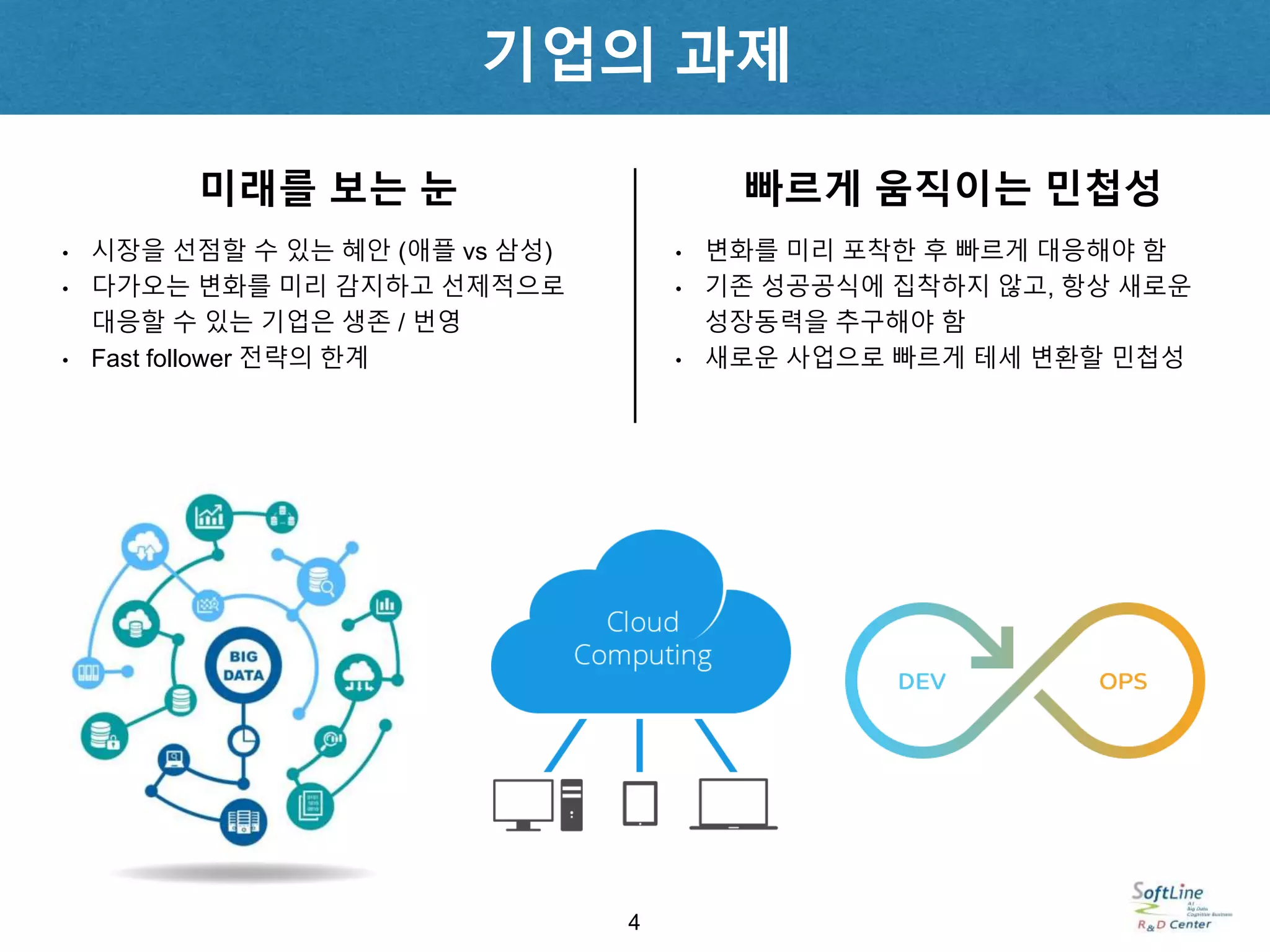
미래를 보는 눈빠르게 움직이는 민첩성
• 시장을 선점할 수 있는 혜안 (애플 vs 삼성)
• 다가오는 변화를 미리 감지하고 선제적으로
대응할 수 있는 기업은 생존 / 번영
• Fast follower 전략의 한계
• 변화를 미리 포착한 후 빠르게 대응해야 함
• 기존 성공공식에 집착하지 않고, 항상 새로운
성장동력을 추구해야 함
• 새로운 사업으로 빠르게 테세 변환할 민첩성
4
기업의 과제
5.
• 21세기에 부상하는선진기업들의 공통점
• 데이터 기반 경영 : 모든 의사결정은 데이터에 기반한다는 것을 기업문화로 정착
—> 데이터 주도형 기업 (Data-driven organization)
• 정확한 의사결정 : 개인의 직관이나 제한된 경험치에 의거하지 않고 데이터에 기반한 의사결정
—> 대용량 데이터 분석 (Massive data analysis)
• 빠른 의사결정 : 실시간으로 수집되는 데이터 기반해 D-1이 아닌 M-1 의사결정
—> 실시간 데이터 분석 (Real-time data analysis)
• 자동화된 의사결정 : 의사결정에 필요한 과정 중 상당 부분을 machine learning 으로 처리
—> 머신러닝 (Machine learning)
• 2016년 Harvard Business Review survey :
• 전사적인 data-driven culture 를 도입한 기업 중 70% 이상이 회계, 생산성, 위험관리,
빠른 의사결정 측면에서 큰 혜택을 보았다고 답변하였음
미래 기업의 경쟁력은 ‘데이터’ 를 어떻게 분석하고 그에 기반해 의사결정을 내리는가에 달려있다!!!!
5
데이터에 대한 재해석
6.
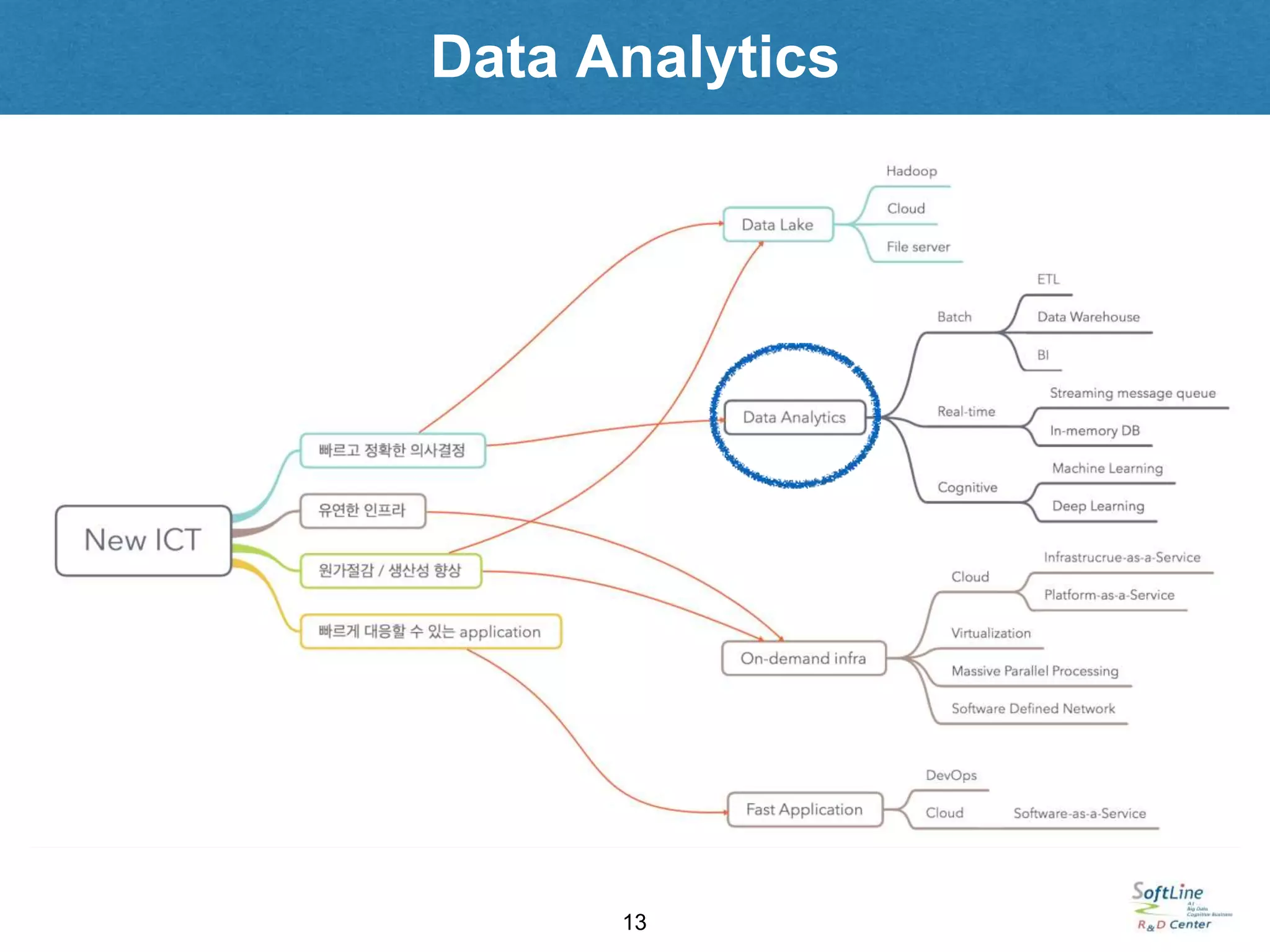
빠르고 정확한 의사결정
•데이터에 기반한 정확한 의사결정
—> 데이터 주도형 기업
—> 대용량 데이터 분석
• 시기적절한 빠른 의사결정
—> 실시간 데이터 분석
—> 머신러닝
유연한 application
• 기존 : 장기간 프로젝트를 통해 업무용
어플리케이션 개발
• DevOps : 작은 서비스 단위로 개발과
운영 단계를 빠르게 반복하며 업데이트
• SaaS : 제3자가 제공하는 서비스 이용
유연한 인프라
• 필요한 시점에 필요한 만큼의 인프라 자원을
활용할 수 있는 인프라 (on-demand, thin
provisioning, virtualization)
• 클라우드 인프라를 활용한 IaaS, PaaS
원가절감과 생산성 향상
• 기반기술을 벤더에 의존하던 방향에서 벗어나
오픈소스 기술을 활용
• 자체 보유 기술력을 점차적으로 높여 나감
• Smart machine 기반의 robotic agent
도입 및 활용
6
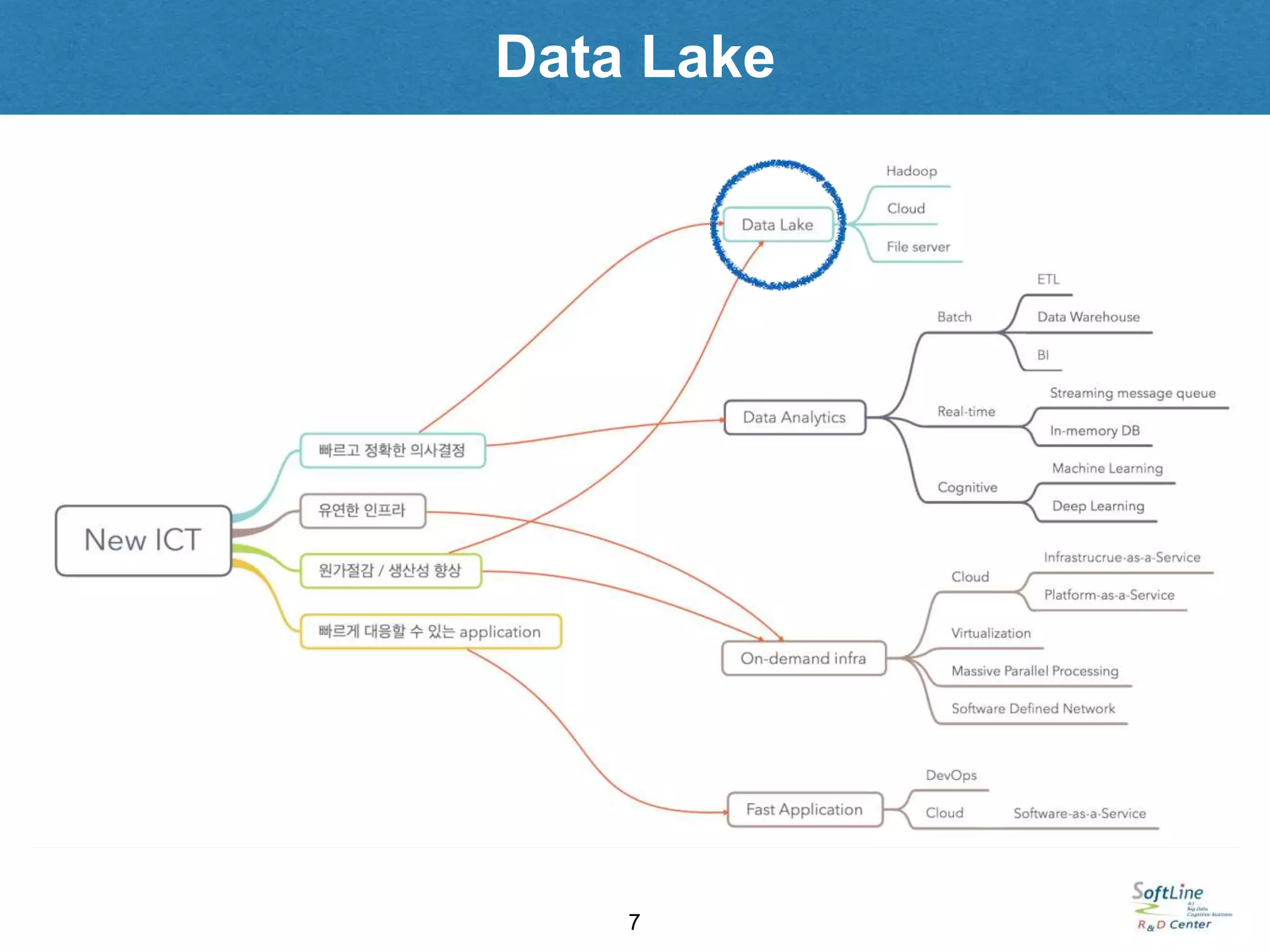
과제해결을 위한 ICT 요건
9
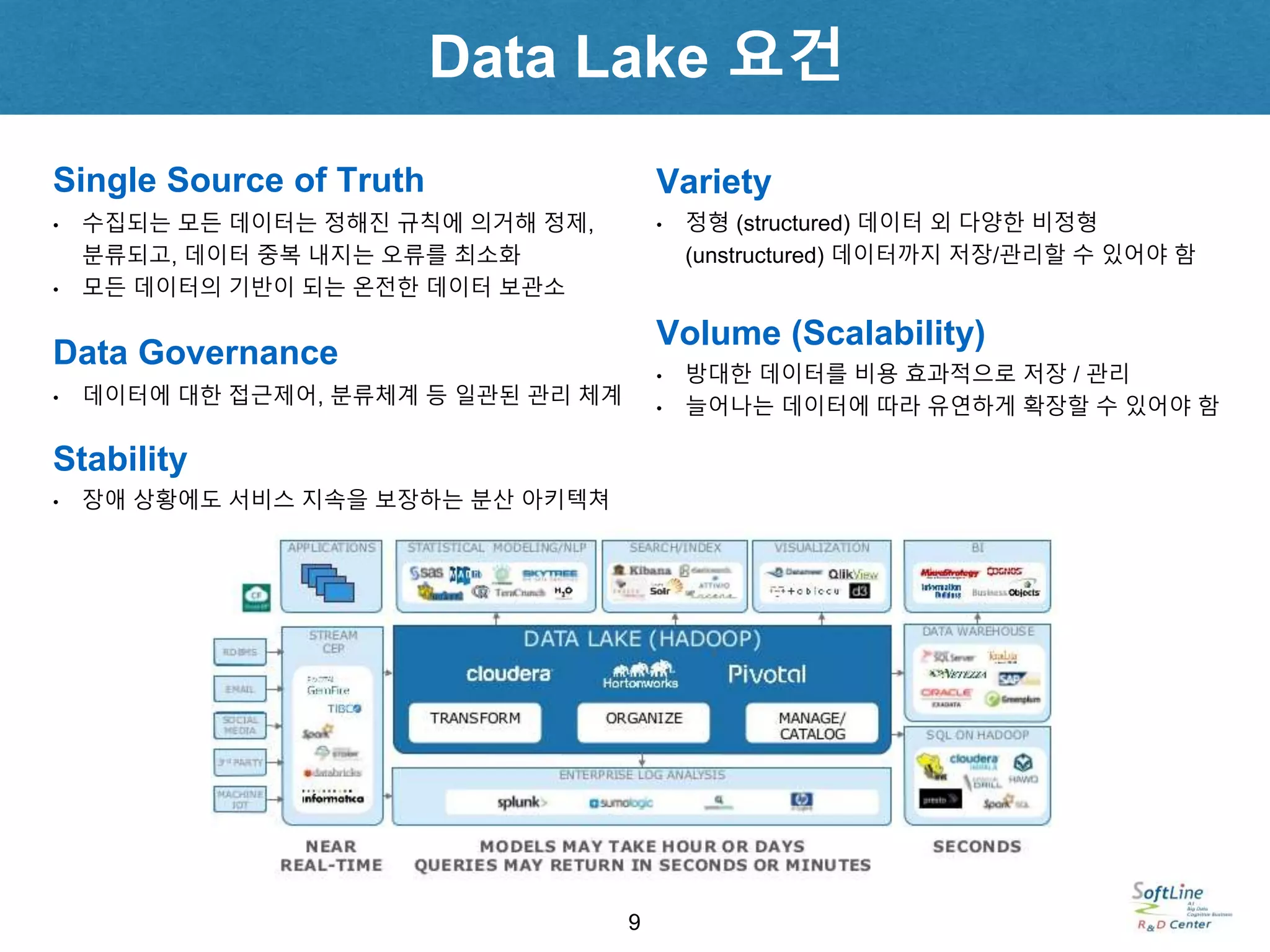
• 수집되는 모든데이터는 정해진 규칙에 의거해 정제,
분류되고, 데이터 중복 내지는 오류를 최소화
• 모든 데이터의 기반이 되는 온전한 데이터 보관소
Single Source of Truth
• 데이터에 대한 접근제어, 분류체계 등 일관된 관리 체계
Data Governance
• 방대한 데이터를 비용 효과적으로 저장 / 관리
• 늘어나는 데이터에 따라 유연하게 확장할 수 있어야 함
Volume (Scalability)
• 정형 (structured) 데이터 외 다양한 비정형
(unstructured) 데이터까지 저장/관리할 수 있어야 함
Variety
• 장애 상황에도 서비스 지속을 보장하는 분산 아키텍쳐
Stability
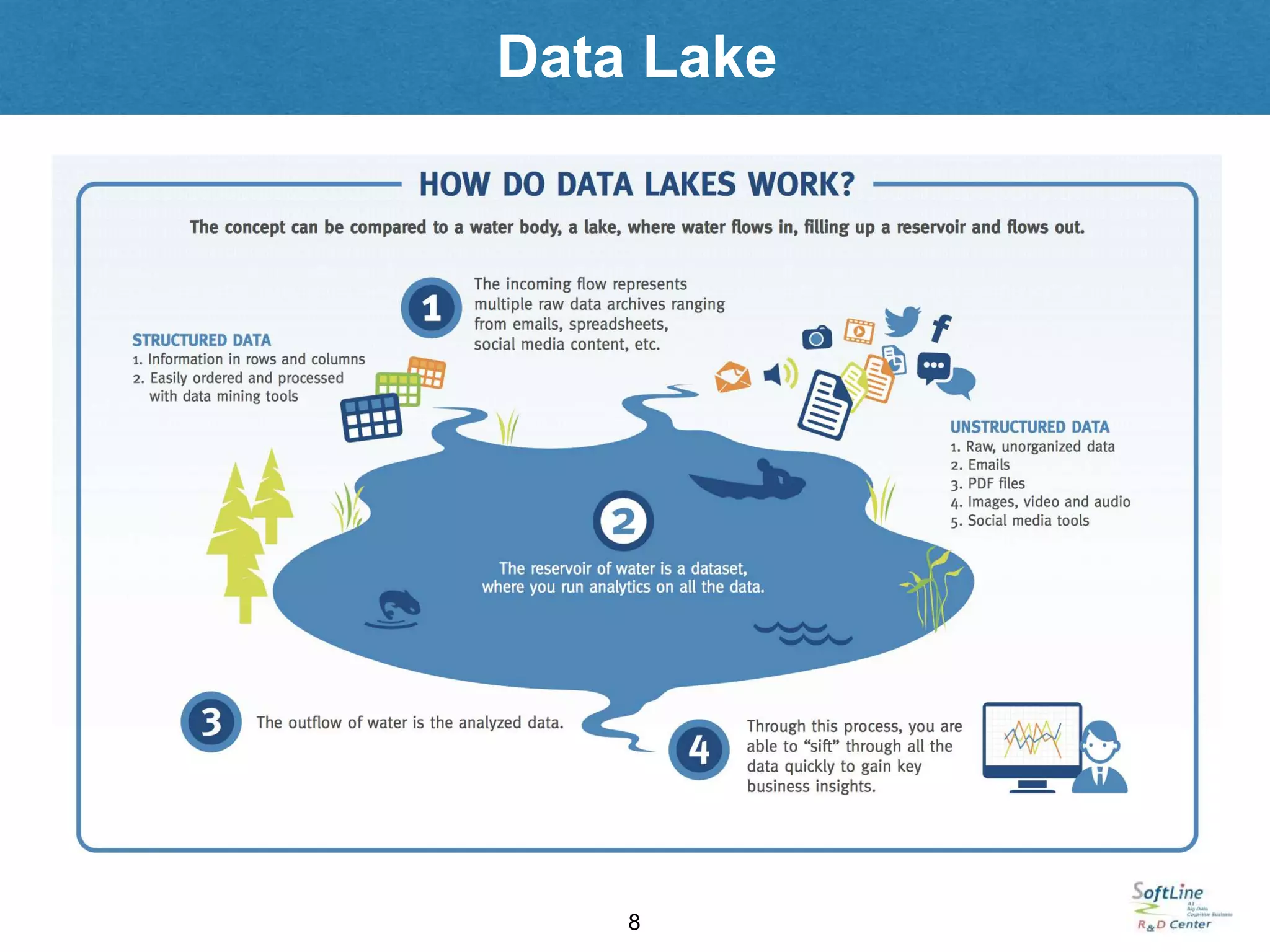
Data Lake 요건
10.
10
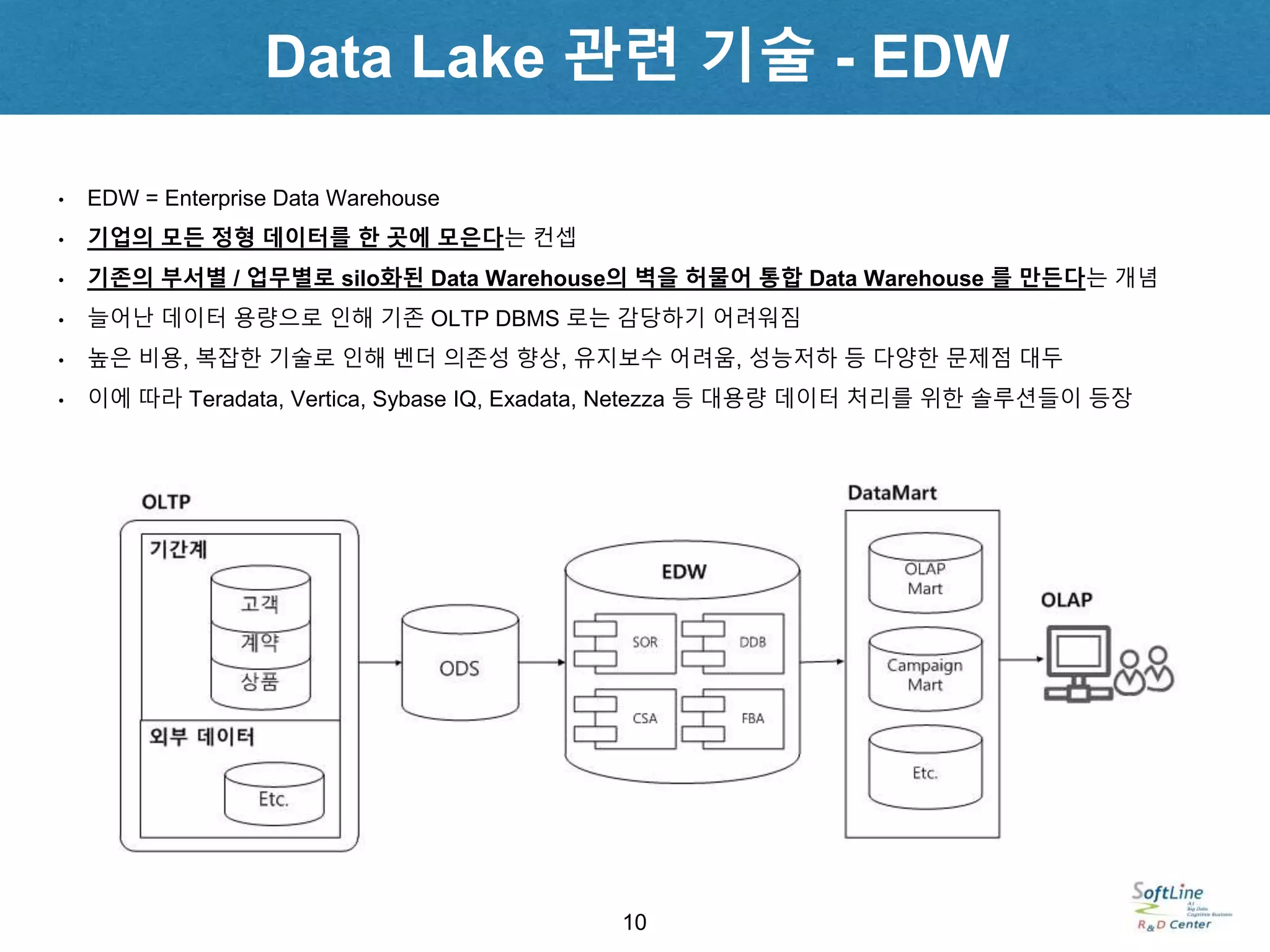
• EDW =Enterprise Data Warehouse
• 기업의 모든 정형 데이터를 한 곳에 모은다는 컨셉
• 기존의 부서별 / 업무별로 silo화된 Data Warehouse의 벽을 허물어 통합 Data Warehouse 를 만든다는 개념
• 늘어난 데이터 용량으로 인해 기존 OLTP DBMS 로는 감당하기 어려워짐
• 높은 비용, 복잡한 기술로 인해 벤더 의존성 향상, 유지보수 어려움, 성능저하 등 다양한 문제점 대두
• 이에 따라 Teradata, Vertica, Sybase IQ, Exadata, Netezza 등 대용량 데이터 처리를 위한 솔루션들이 등장
Data Lake 관련 기술 - EDW
11.
11
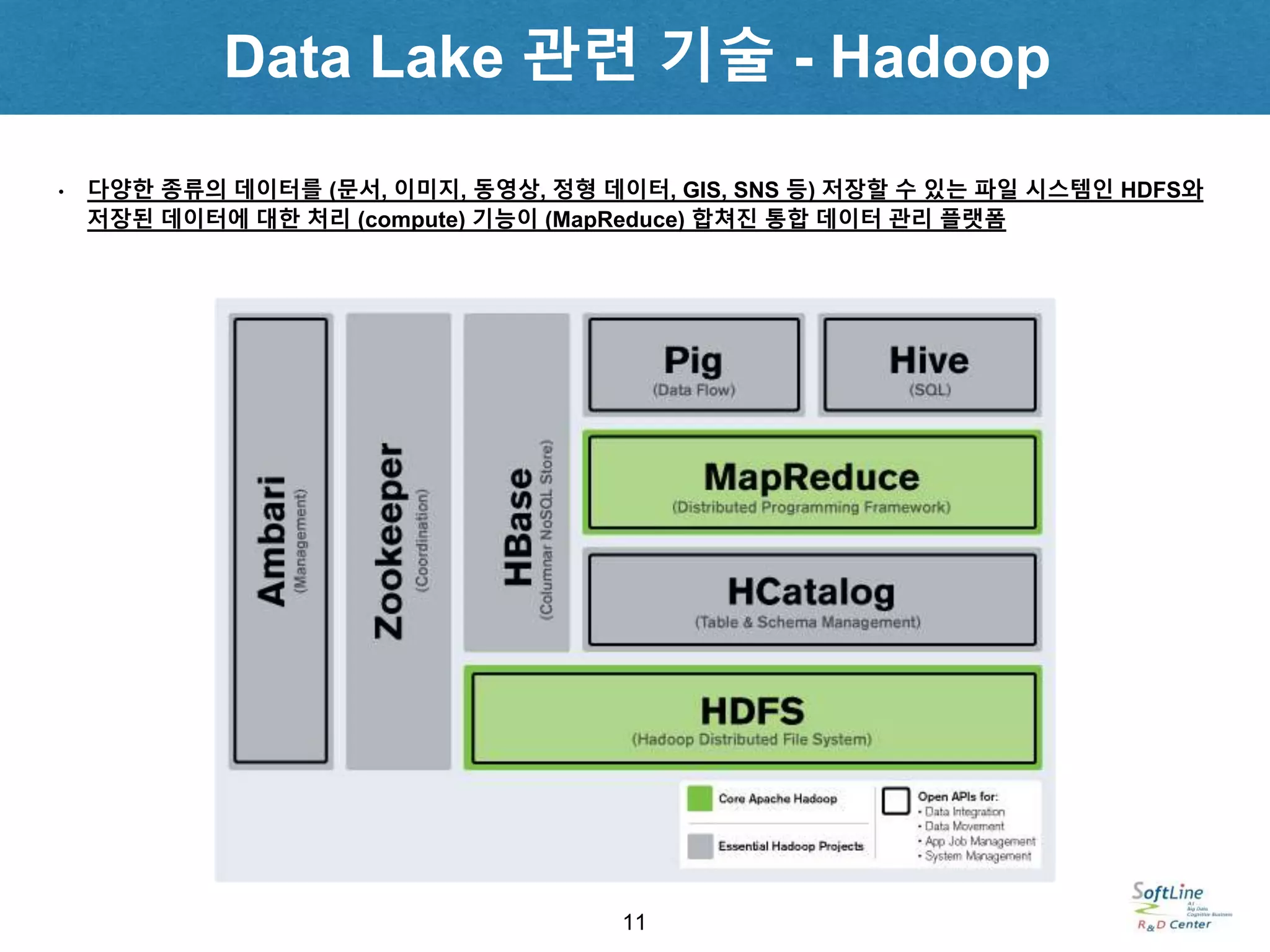
• 다양한 종류의데이터를 (문서, 이미지, 동영상, 정형 데이터, GIS, SNS 등) 저장할 수 있는 파일 시스템인 HDFS와
저장된 데이터에 대한 처리 (compute) 기능이 (MapReduce) 합쳐진 통합 데이터 관리 플랫폼
Data Lake 관련 기술 - Hadoop
12.
12
• 다양한 종류의데이터를 (문서, 이미지, 동영상, 정형 데이터, GIS, SNS 등) 저장할 수 있는 파일 시스템인 HDFS와
저장된 데이터에 대한 처리 (compute) 기능이 (MapReduce) 합쳐진 통합 데이터 관리 플랫폼
• 장점
• 상용 하드웨어 기반의 병렬 아키텍쳐를 지원하여 저렴한 인프라 비용으로 다양한 포맷의 대용량 데이터를 저
장 관리하기에 매우 효율적 —> HDFS의 장점
• 저장된 데이터에 대한 병렬 처리 layer 가 결합되어 저장된 데이터에 대한 활용도 제공 —> MapReduce의 역할
• 오픈소스 Apache 프로젝트로 공개되어 누구나 비용없이 구성 가능함
• Hadoop과 연관된 다양한 Apache 프로젝트 기술 연계활용 가능 (Hive, Spark 등)
• 단점
• Hadoop의 활용성 측면에서 MapReduce는 장애물.
왜? 디스크 기반 batch 처리가 기본이므로 성능 상의 문제
발생. Hadoop을 단순 저장공간 이외의 용도로 활용하기가
어려움
• 오픈소스로 공개된 내용을 자세히 이해하지 못하면 제대로
구축 / 활용할 수 없음
• Hadoop 엔지니어를 직접 채용하는 비용 혹은 상용
Hadoop을 쓰는 비용이 오히려 더 많이 들 수 있음
“비슷해 보이지만, 이녀석은 하둡으로 동
작해.”
Data Lake 관련 기술 - Hadoop
Data Analytics
14
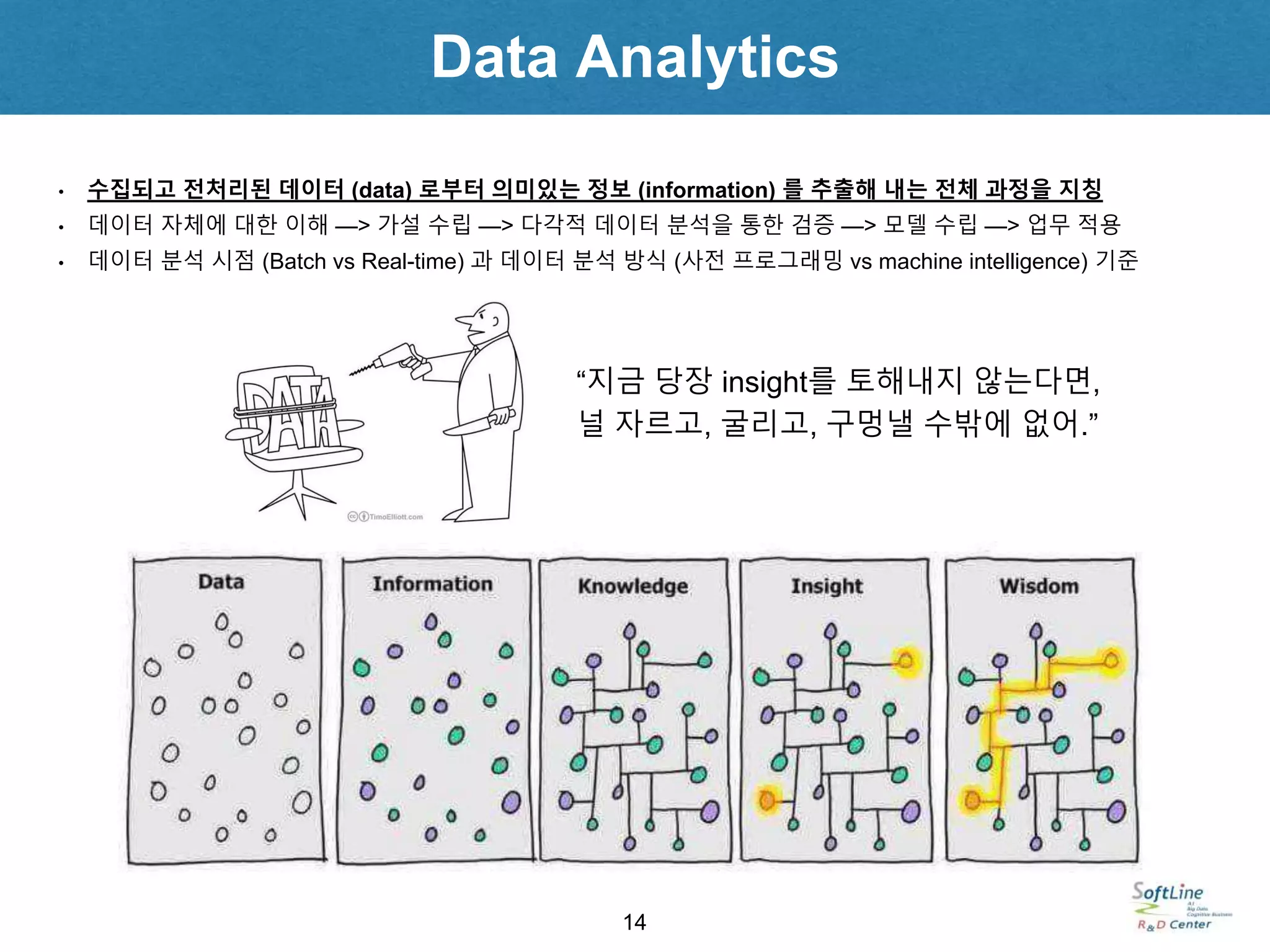
• 수집되고전처리된 데이터 (data) 로부터 의미있는 정보 (information) 를 추출해 내는 전체 과정을 지칭
• 데이터 자체에 대한 이해 —> 가설 수립 —> 다각적 데이터 분석을 통한 검증 —> 모델 수립 —> 업무 적용
• 데이터 분석 시점 (Batch vs Real-time) 과 데이터 분석 방식 (사전 프로그래밍 vs machine intelligence) 기준
“지금 당장 insight를 토해내지 않는다면,
널 자르고, 굴리고, 구멍낼 수밖에 없어.”
15.
Data Analytics -Batch
15
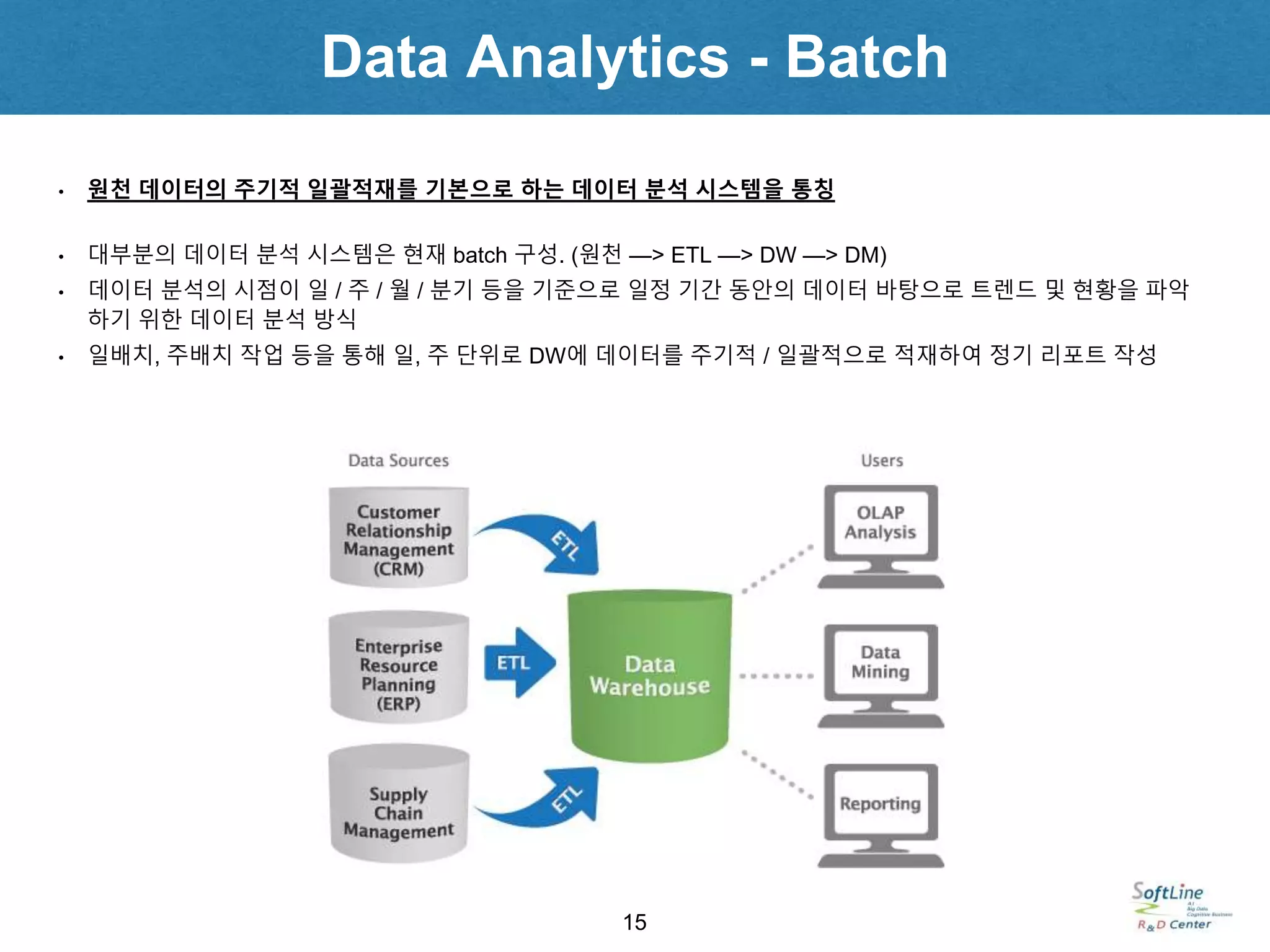
• 원천 데이터의 주기적 일괄적재를 기본으로 하는 데이터 분석 시스템을 통칭
• 대부분의 데이터 분석 시스템은 현재 batch 구성. (원천 —> ETL —> DW —> DM)
• 데이터 분석의 시점이 일 / 주 / 월 / 분기 등을 기준으로 일정 기간 동안의 데이터 바탕으로 트렌드 및 현황을 파악
하기 위한 데이터 분석 방식
• 일배치, 주배치 작업 등을 통해 일, 주 단위로 DW에 데이터를 주기적 / 일괄적으로 적재하여 정기 리포트 작성
16.
Data Analytics -Batch - ETL
16
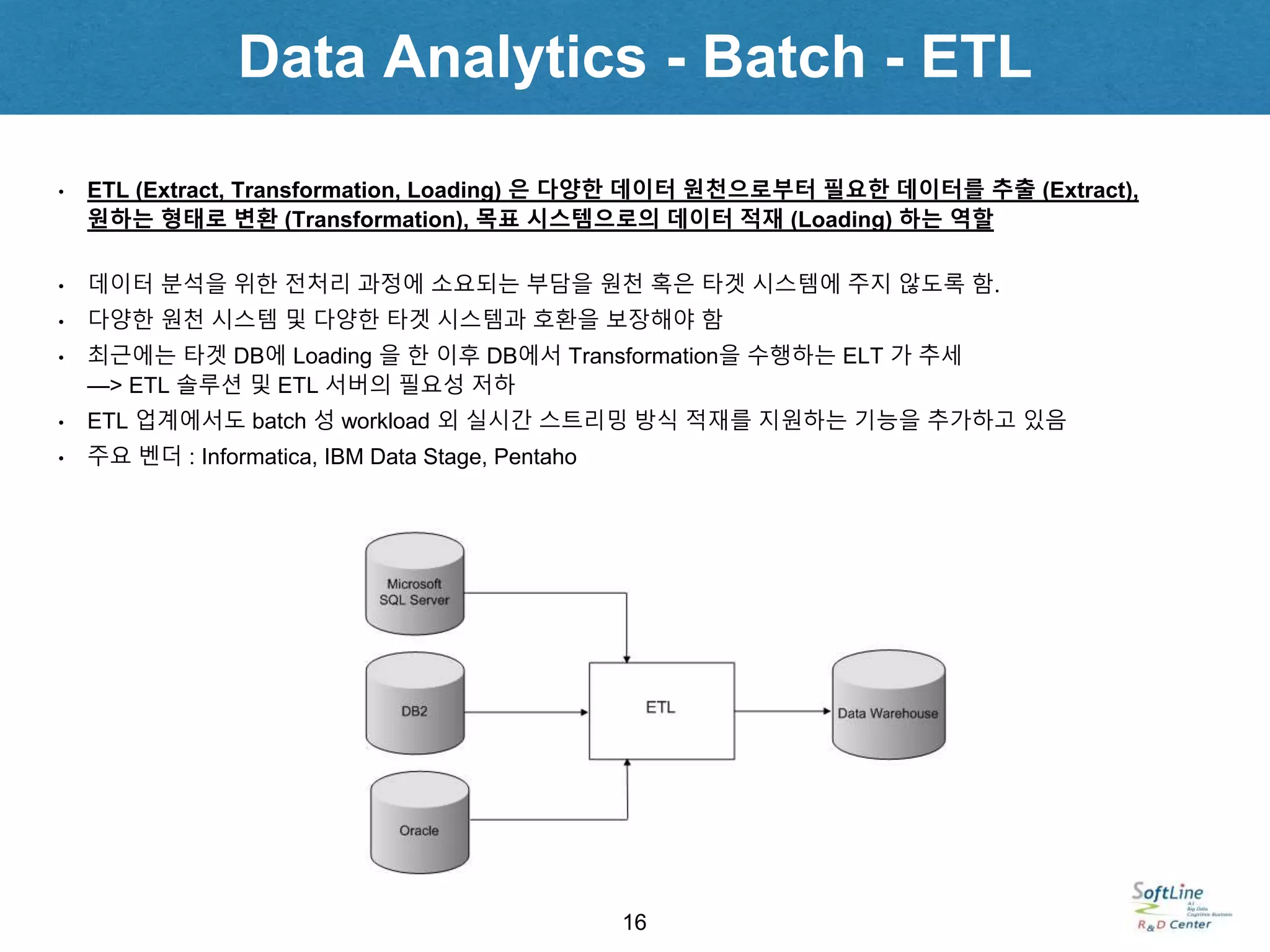
• ETL (Extract, Transformation, Loading) 은 다양한 데이터 원천으로부터 필요한 데이터를 추출 (Extract),
원하는 형태로 변환 (Transformation), 목표 시스템으로의 데이터 적재 (Loading) 하는 역할
• 데이터 분석을 위한 전처리 과정에 소요되는 부담을 원천 혹은 타겟 시스템에 주지 않도록 함.
• 다양한 원천 시스템 및 다양한 타겟 시스템과 호환을 보장해야 함
• 최근에는 타겟 DB에 Loading 을 한 이후 DB에서 Transformation을 수행하는 ELT 가 추세
—> ETL 솔루션 및 ETL 서버의 필요성 저하
• ETL 업계에서도 batch 성 workload 외 실시간 스트리밍 방식 적재를 지원하는 기능을 추가하고 있음
• 주요 벤더 : Informatica, IBM Data Stage, Pentaho
17.
Data Analytics -Batch - BI
17
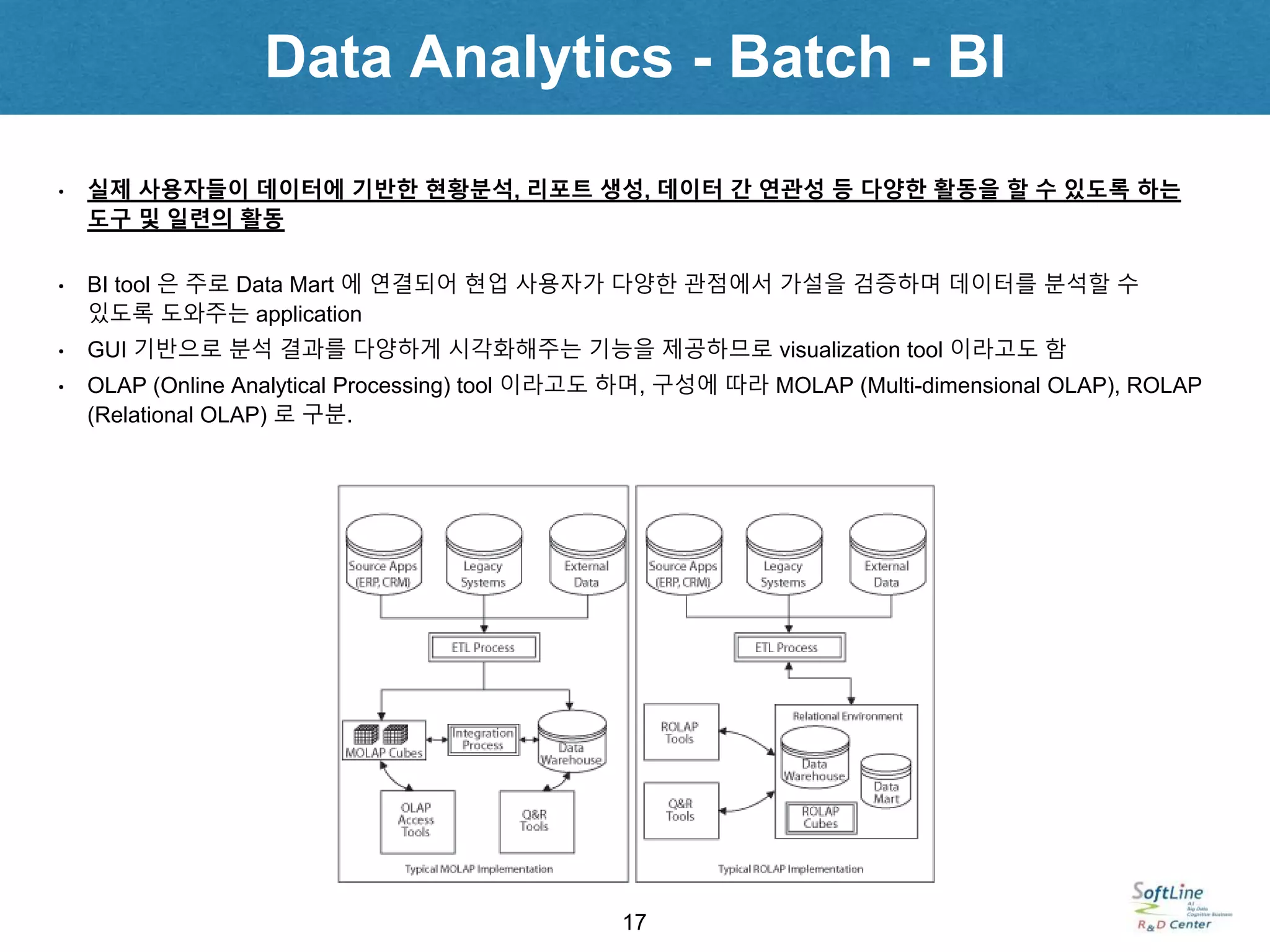
• 실제 사용자들이 데이터에 기반한 현황분석, 리포트 생성, 데이터 간 연관성 등 다양한 활동을 할 수 있도록 하는
도구 및 일련의 활동
• BI tool 은 주로 Data Mart 에 연결되어 현업 사용자가 다양한 관점에서 가설을 검증하며 데이터를 분석할 수
있도록 도와주는 application
• GUI 기반으로 분석 결과를 다양하게 시각화해주는 기능을 제공하므로 visualization tool 이라고도 함
• OLAP (Online Analytical Processing) tool 이라고도 하며, 구성에 따라 MOLAP (Multi-dimensional OLAP), ROLAP
(Relational OLAP) 로 구분.
18.
Data Analytics -Real-time
18
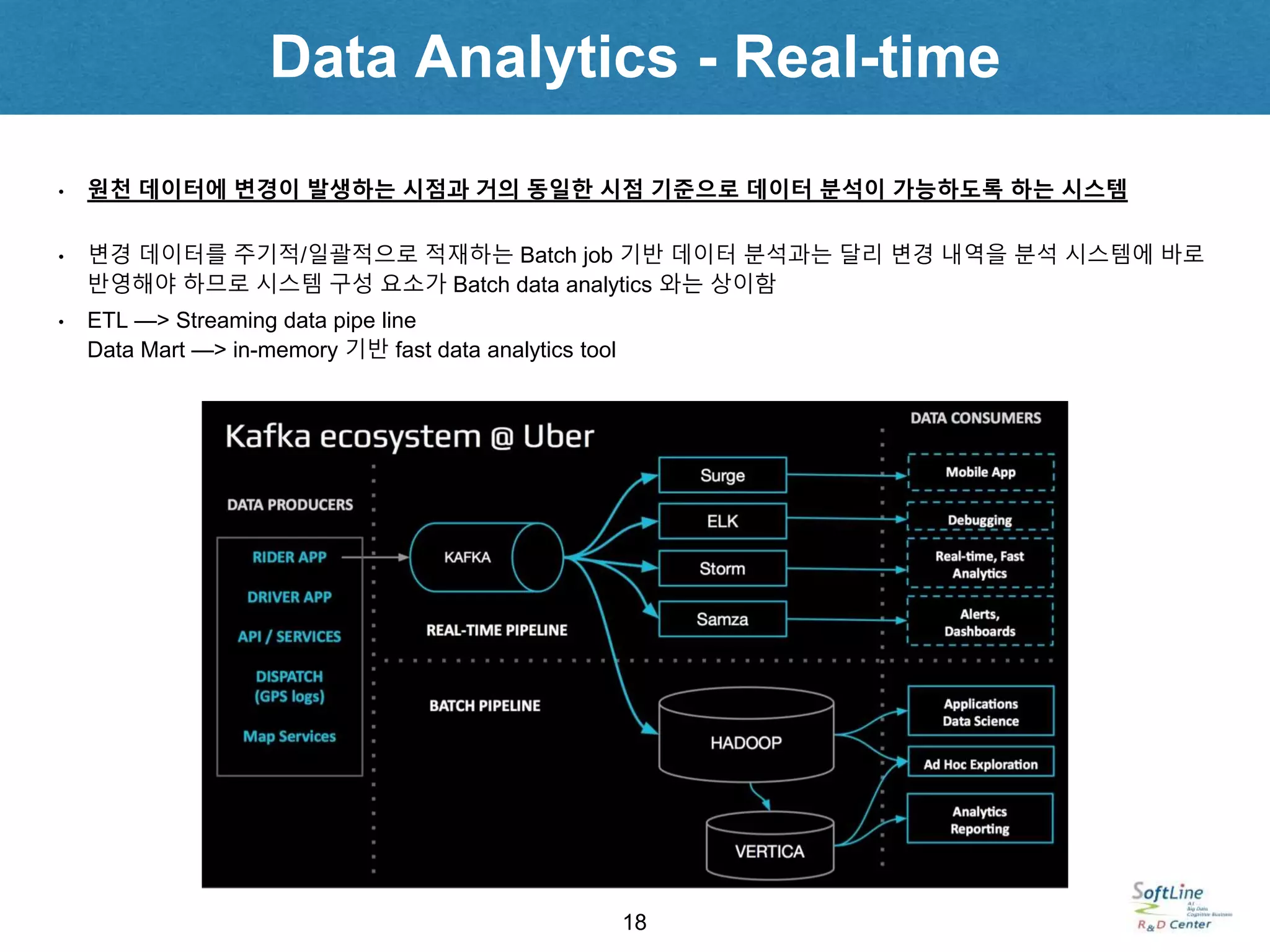
• 원천 데이터에 변경이 발생하는 시점과 거의 동일한 시점 기준으로 데이터 분석이 가능하도록 하는 시스템
• 변경 데이터를 주기적/일괄적으로 적재하는 Batch job 기반 데이터 분석과는 달리 변경 내역을 분석 시스템에 바로
반영해야 하므로 시스템 구성 요소가 Batch data analytics 와는 상이함
• ETL —> Streaming data pipe line
Data Mart —> in-memory 기반 fast data analytics tool
19.
Data Analytics -Real-time - Streaming
19
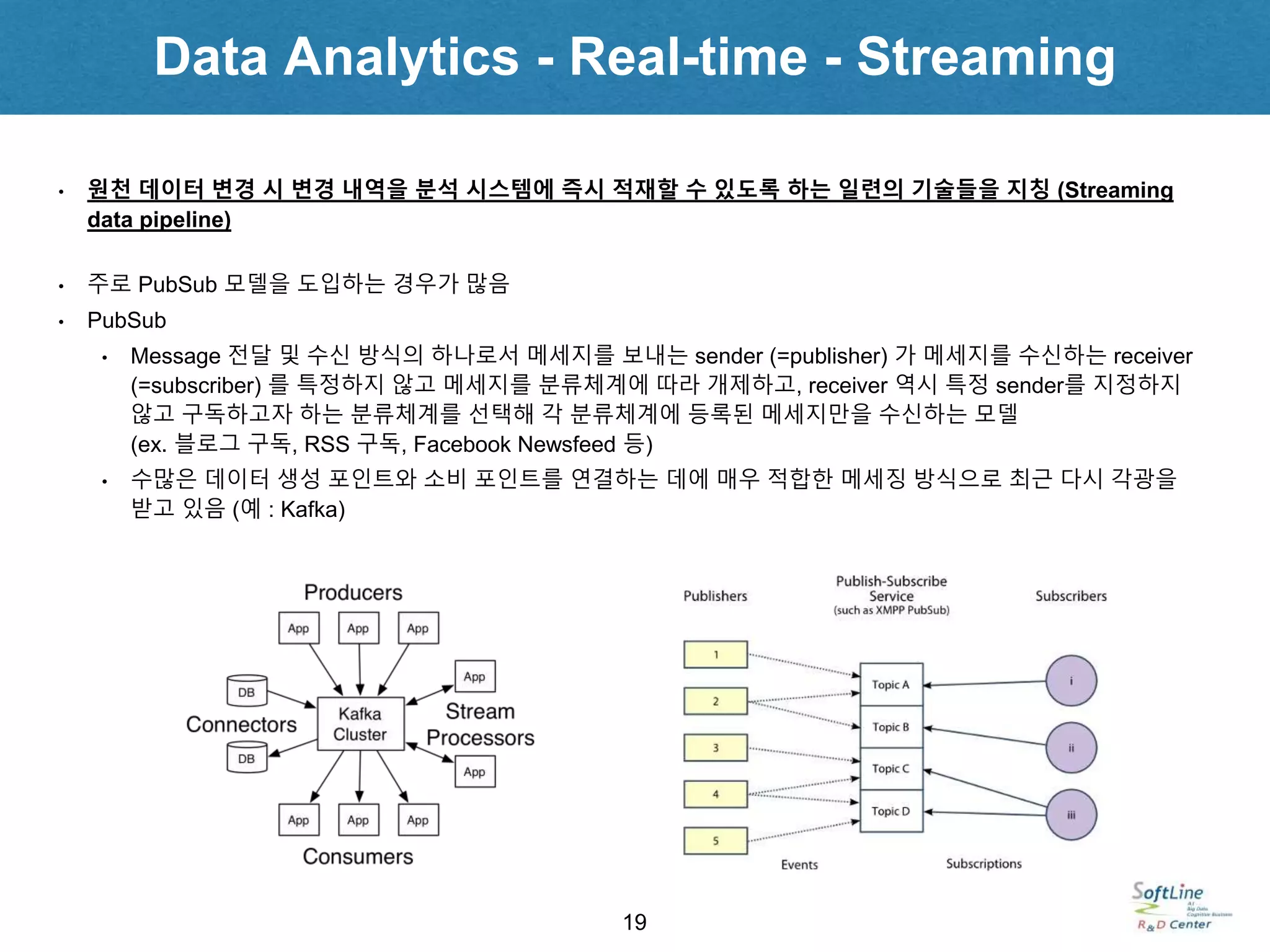
• 원천 데이터 변경 시 변경 내역을 분석 시스템에 즉시 적재할 수 있도록 하는 일련의 기술들을 지칭 (Streaming
data pipeline)
• 주로 PubSub 모델을 도입하는 경우가 많음
• PubSub
• Message 전달 및 수신 방식의 하나로서 메세지를 보내는 sender (=publisher) 가 메세지를 수신하는 receiver
(=subscriber) 를 특정하지 않고 메세지를 분류체계에 따라 개제하고, receiver 역시 특정 sender를 지정하지
않고 구독하고자 하는 분류체계를 선택해 각 분류체계에 등록된 메세지만을 수신하는 모델
(ex. 블로그 구독, RSS 구독, Facebook Newsfeed 등)
• 수많은 데이터 생성 포인트와 소비 포인트를 연결하는 데에 매우 적합한 메세징 방식으로 최근 다시 각광을
받고 있음 (예 : Kafka)
20.
Data Analytics -Real-time - In-memory DB
20
• 데이터 분석 지연 시간을 최소화 하기 위해 처리성능이 뛰어난 메모리 상에 데이터를 적재하고 분석하는 시스템
• 대표기술 및 제품: Spark, SAP HANA, Altibase, SunDB, VoltDB, Oracle 12c 등
• 컨셉 자체는 이미 시장에 등장한지 오래 되었으나 높은 메모리 가격으로 인한 과다한 인프라 비용이 필요하여
실용성이 높지 않은 상황이었음.
• 하지만, 메모리 가격 하락과 더불어 비용압박은 나아진 상황이며, 장기적으로 in-memory를 활용한 데이터 처리는
그 영역이 넓어질 것으로 예상
• 특히, 실시간 데이터 분석에 대한 요건은 거의 모든 기업들이 현재도 가지고 있으며 직관적으로도 그 필요성이
쉽게 납득이 되므로 관련 기술의 시장 파급력은 클 것으로 예상
21.
Data Analytics -Cognitive
21
• 데이터의 양과 종류가 폭증하여 인력만으로 데이터로부터 ‘정보’ 를 뽑아내는 것이 매우 어려워짐
• 엄청난 양의 다양한 종류의 데이터에서 가치를 추출하기 위해서는 인력만으로는 효율성이 보장되지 않음
(데이터 정제, 분류, 패턴인식)
• 더불어 기존에는 어려웠던 비정형 데이터에 대한 machine에 의한 분석 역시 상용화 수준으로 발전하고 있음
(텍스트, 이미지, 동영상 분석)
• 데이터 정제 / 분류 / 패턴인식, 텍스트 / 이미지 / 영상 분석 등을 인지능력을 갖춘 Smart machine 이 능동적으로
수행할 수 있도록 하는 것이 Data Analytics에서 cognitive solution의 역할
• Cognitive solution 과 관련해서는 AI, machine learning, deep learning 등 유사하면서도 다양한 용어 및 개념이
복합적으로 쓰이고 있으므로 이에 대한 정리가 우선시 되어야 함.
Data Analytics -Cognitive - Smart Machine
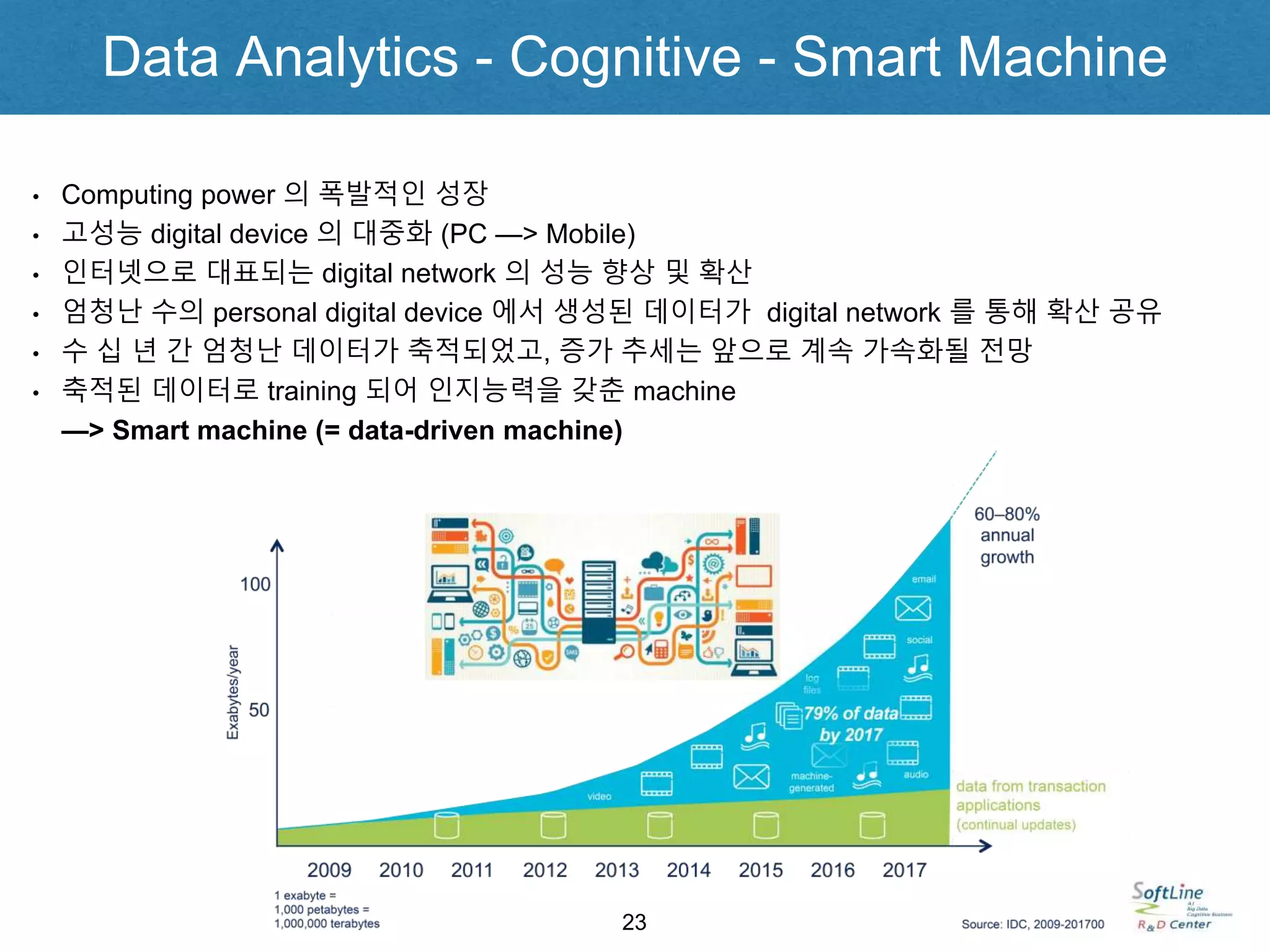
• Computing power 의 폭발적인 성장
• 고성능 digital device 의 대중화 (PC —> Mobile)
• 인터넷으로 대표되는 digital network 의 성능 향상 및 확산
• 엄청난 수의 personal digital device 에서 생성된 데이터가 digital network 를 통해 확산 공유
• 수 십 년 간 엄청난 데이터가 축적되었고, 증가 추세는 앞으로 계속 가속화될 전망
• 축적된 데이터로 training 되어 인지능력을 갖춘 machine
—> Smart machine (= data-driven machine)
23
24.
Data Analytics -Cognitive - AI
24
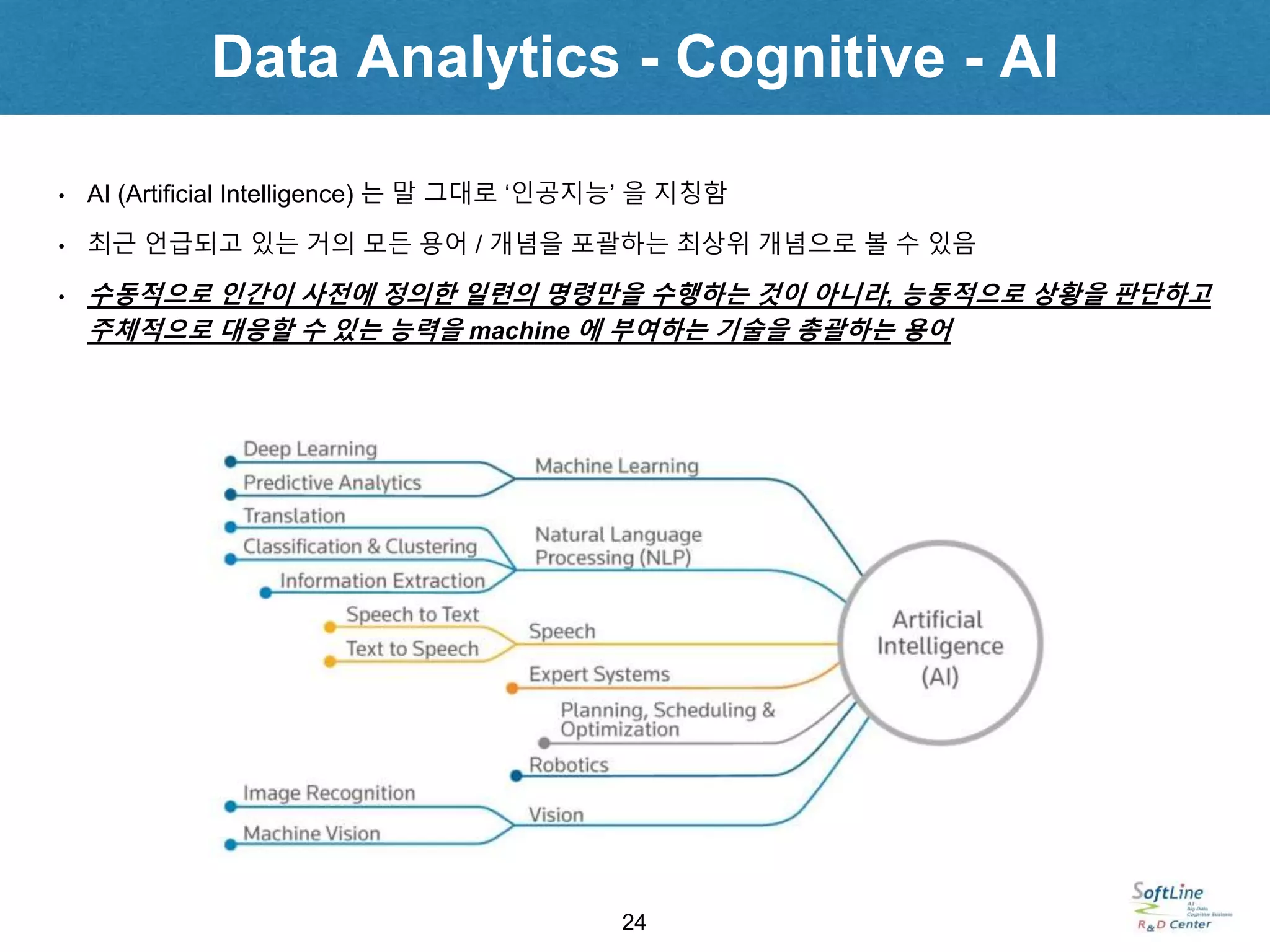
• AI (Artificial Intelligence) 는 말 그대로 ‘인공지능’ 을 지칭함
• 최근 언급되고 있는 거의 모든 용어 / 개념을 포괄하는 최상위 개념으로 볼 수 있음
• 수동적으로 인간이 사전에 정의한 일련의 명령만을 수행하는 것이 아니라, 능동적으로 상황을 판단하고
주체적으로 대응할 수 있는 능력을 machine 에 부여하는 기술을 총괄하는 용어
25.
Data Analytics -Cognitive - Machine Learning
25
• 데이터 속에서 패턴을 찾고, 자동으로 분류하는 과정에서 학습하고, 학습의 결과를 바탕으로 추론, 예측하여 기존
의 업무를 보다 효율적으로 수행하거나 과거에는 할 수 없었던 업무를 수행하는 컴퓨터 프로그램을 지칭
• machine learning 이라는 용어는 1950년대에 처음 등장했고, 지금 사용되고 있는 대부분의 알고리즘들도 거의
대부분 예전에 개발된 것
• 오늘날 하드웨어 성능이 뒷받침되면서 machine learning 알고리즘들이 실제로 구현되고 적용되고 있는 것. 물론 하
드웨어 성능 외에도 생성되는 데이터의 양과 종류가 폭증했다는 것도 중요한 요인
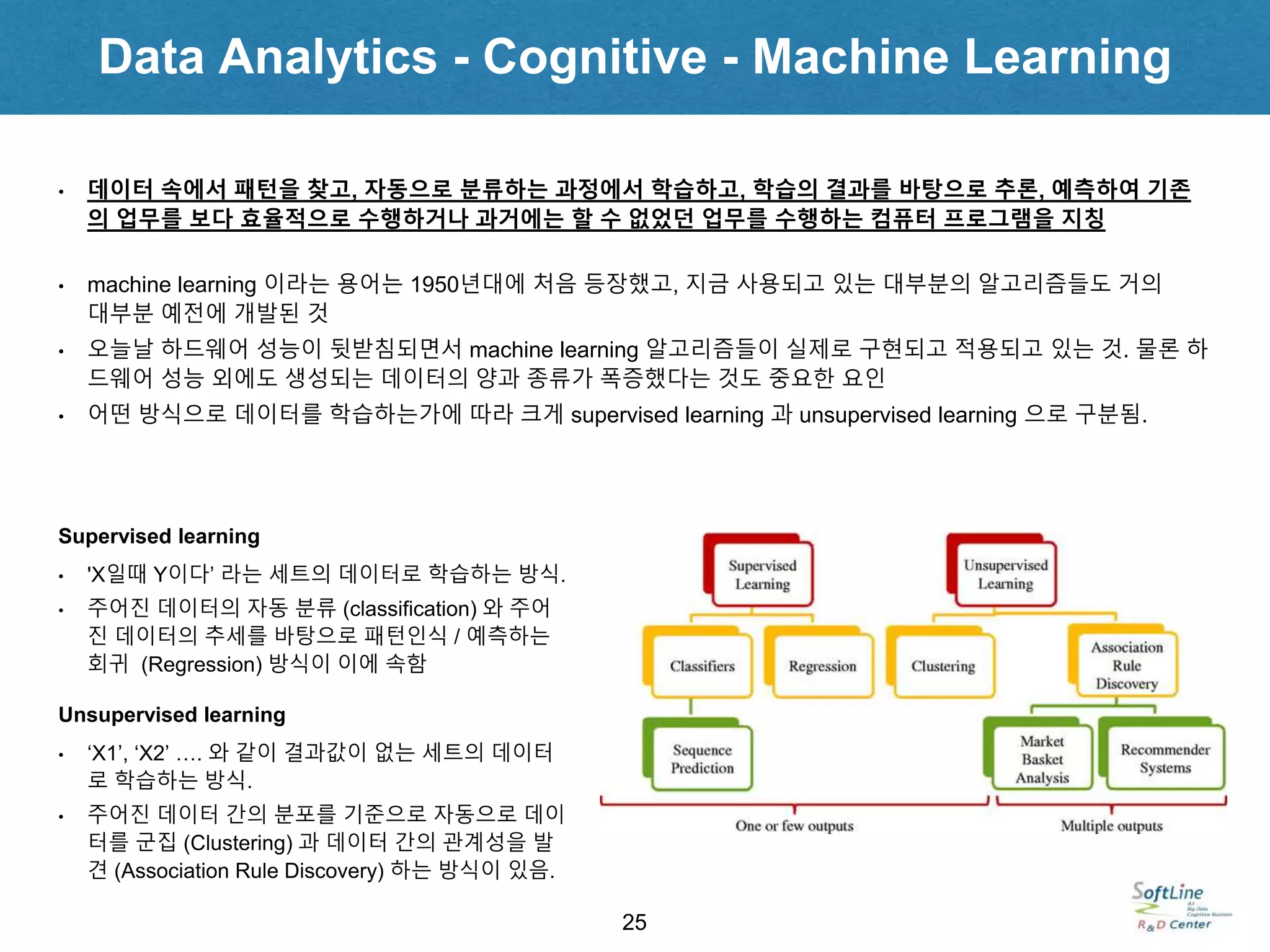
• 어떤 방식으로 데이터를 학습하는가에 따라 크게 supervised learning 과 unsupervised learning 으로 구분됨.
Supervised learning
• 'X일때 Y이다’ 라는 세트의 데이터로 학습하는 방식.
• 주어진 데이터의 자동 분류 (classification) 와 주어
진 데이터의 추세를 바탕으로 패턴인식 / 예측하는
회귀 (Regression) 방식이 이에 속함
Unsupervised learning
• ‘X1’, ‘X2’ …. 와 같이 결과값이 없는 세트의 데이터
로 학습하는 방식.
• 주어진 데이터 간의 분포를 기준으로 자동으로 데이
터를 군집 (Clustering) 과 데이터 간의 관계성을 발
견 (Association Rule Discovery) 하는 방식이 있음.
26.
Data Analytics -Cognitive - Neural Network
26
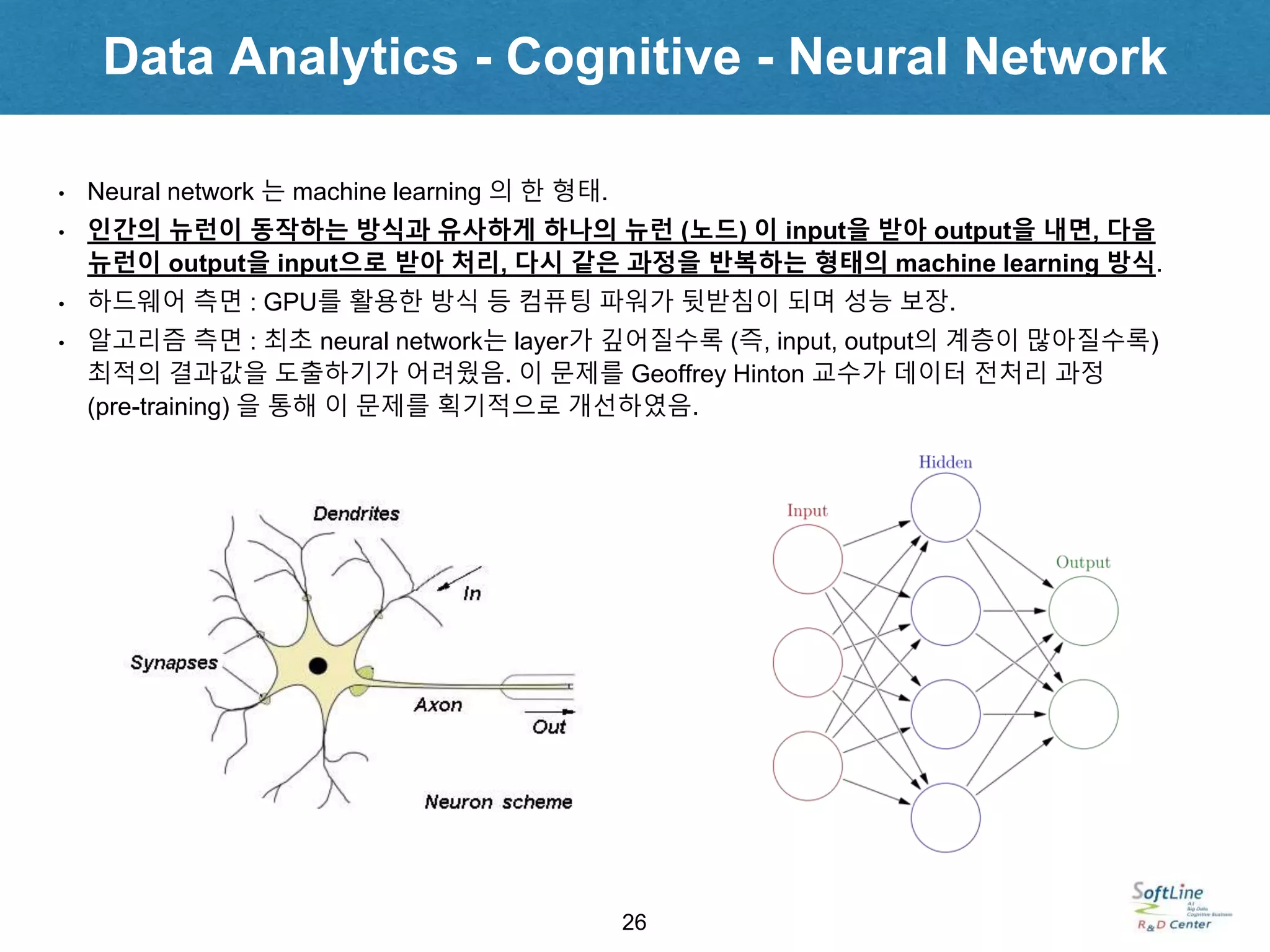
• Neural network 는 machine learning 의 한 형태.
• 인간의 뉴런이 동작하는 방식과 유사하게 하나의 뉴런 (노드) 이 input을 받아 output을 내면, 다음
뉴런이 output을 input으로 받아 처리, 다시 같은 과정을 반복하는 형태의 machine learning 방식.
• 하드웨어 측면 : GPU를 활용한 방식 등 컴퓨팅 파워가 뒷받침이 되며 성능 보장.
• 알고리즘 측면 : 최초 neural network는 layer가 깊어질수록 (즉, input, output의 계층이 많아질수록)
최적의 결과값을 도출하기가 어려웠음. 이 문제를 Geoffrey Hinton 교수가 데이터 전처리 과정
(pre-training) 을 통해 이 문제를 획기적으로 개선하였음.
27.
Data Analytics -Cognitive - Deep Learning
27
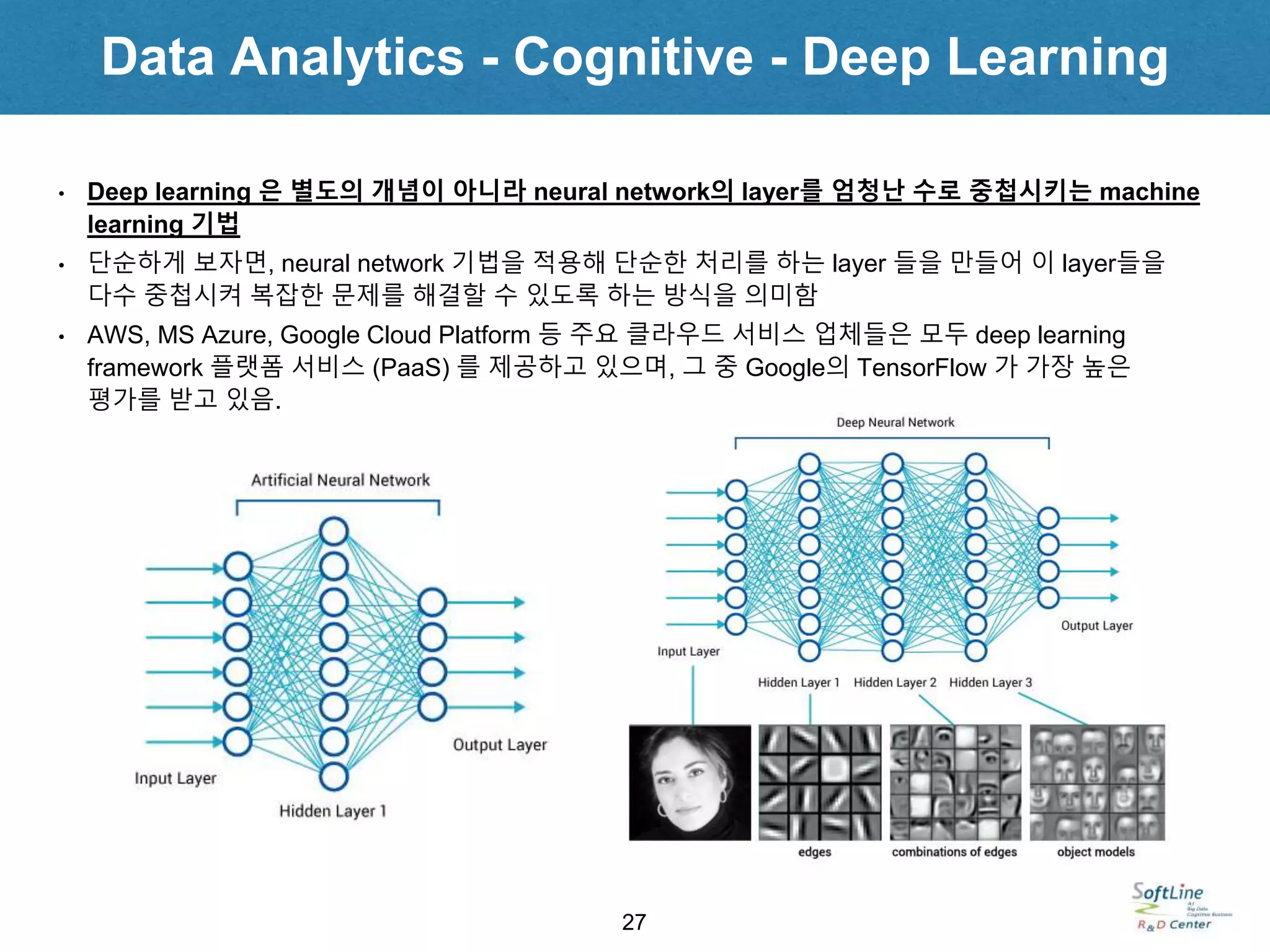
• Deep learning 은 별도의 개념이 아니라 neural network의 layer를 엄청난 수로 중첩시키는 machine
learning 기법
• 단순하게 보자면, neural network 기법을 적용해 단순한 처리를 하는 layer 들을 만들어 이 layer들을
다수 중첩시켜 복잡한 문제를 해결할 수 있도록 하는 방식을 의미함
• AWS, MS Azure, Google Cloud Platform 등 주요 클라우드 서비스 업체들은 모두 deep learning
framework 플랫폼 서비스 (PaaS) 를 제공하고 있으며, 그 중 Google의 TensorFlow 가 가장 높은
평가를 받고 있음.
28.
Data Analytics -Cognitive - 첨언
28
• 일반적인 대중이나 기업의 관심은 대부분 deep learning 혹은
neural network에 쏠려있지만, 사실 대부분의 machine learning
알고리즘은 이들과 무관함
• 중요한 것은 내가 어떤 문제를 해결하고자 하며, 이를 위해 어떤
machine learning 알고리즘 사용해야 하는가를 판단하는 것
• 4차 산업혁명이다 해서 무조건 deep learning으로 뭔가를 해야 하는
것이 아님.
• 보유한 데이터를 통해 어떤 목적을 이루고자 하는지, 어떤 문제를
데이터로 어떻게 해결하고자 하는지에 대한 고민없이 덮어놓고
덤벼서는 안됨.
• 결국, 데이터와 업무를 아는 사람들의 고민이 바탕이 된 이후,
machine learning이 되었든, deep learning이
되었든 실질적인 적용방안을 강구하는 것이 옳은 접근방식.
On-demand Infra
30
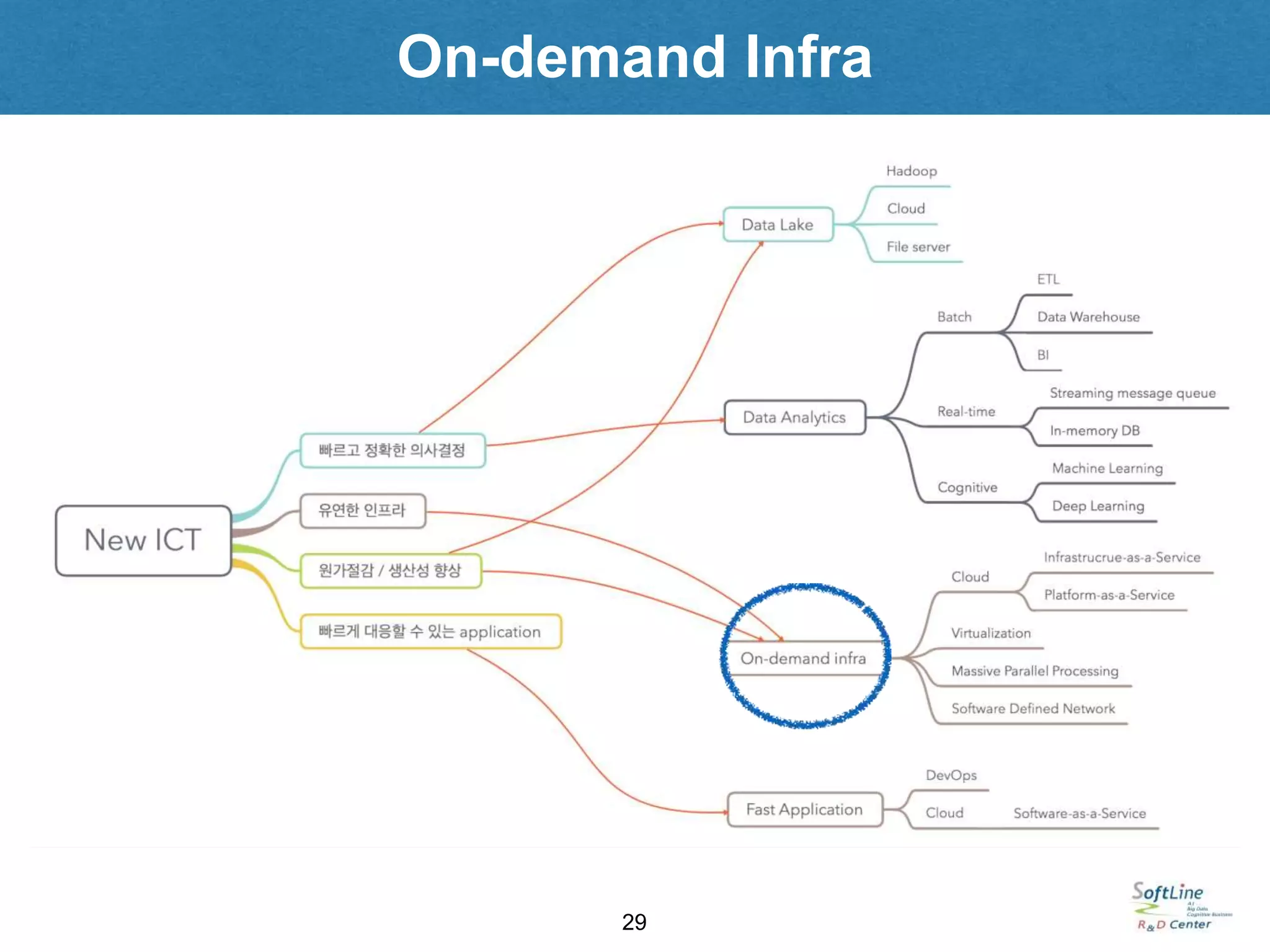
• 필요한시점에 필요한 만큼의 인프라 리소스를 확보할 수 있는 유연한 인프라 환경
• 인프라 투자 비용을 감축시키기 위해 다양한 기술들이 지난 십여년 간 꾸준히 등장했음
(thin provisioning, virtualization…)
• 유연한 on-demand 인프라를 자체적으로 on-premise IDC에 구성하면 SDC (Software-defined Data Center)
• 초고속 인터넷 망의 발전으로 인터넷을 통해 가상 리소스를 실시간으로 필요한 만큼 쓸 수 있게 되었음
• 이처럼 온라인으로 리소스를 필요한만큼 빌려 쓰고 쓴 만큼 비용을 지불하는 구조가 클라우드.
31.
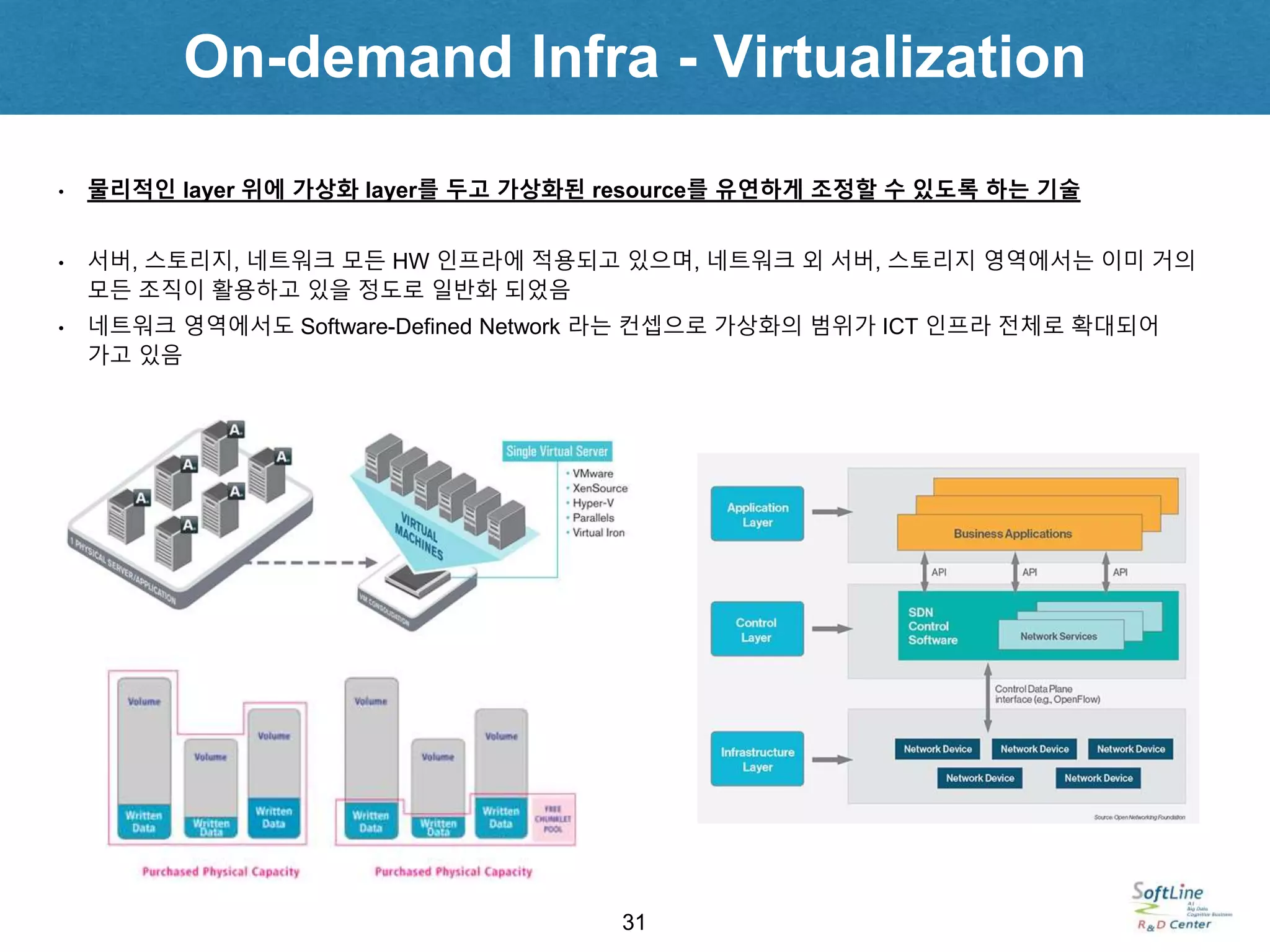
On-demand Infra -Virtualization
31
• 물리적인 layer 위에 가상화 layer를 두고 가상화된 resource를 유연하게 조정할 수 있도록 하는 기술
• 서버, 스토리지, 네트워크 모든 HW 인프라에 적용되고 있으며, 네트워크 외 서버, 스토리지 영역에서는 이미 거의
모든 조직이 활용하고 있을 정도로 일반화 되었음
• 네트워크 영역에서도 Software-Defined Network 라는 컨셉으로 가상화의 범위가 ICT 인프라 전체로 확대되어
가고 있음
32.
On-demand Infra -Cloud
32
• 가상화 기술을 기반으로 공통의 인프라 풀을 만들어 각 서비스에 필요한 만큼의 리소스를 인터넷을 통해 동적으로
할당해 주는 플랫폼
• 클라우드 인프라 리소스에 대한 접근 범위에 따라 구분
• Public : 공용 클라우드 서비스로서 다수가 공통 리소스 풀을 사용
• Hybrid : 리소스 중 일부는 public, 일부는 private
• Private : 개별 고객이 자신의 인프라 환경을 클라우드로 전환
• 클라우드 서비스 범위에 따른 구분
• IaaS (Infrastructure as a Service) :
서버, 스토리지, 네트워크 등 하드웨어 자원만
클라우드를 통해 제공
• PaaS (Platform as a Service) :
OS 환경 혹은 특정 개발환경 등 어플리케이션
구동을 위한 플랫폼 제공
• SaaS (Software as a Service) :
클라우드를 통한 application 서비스 제공
(HR, ERP, CRM 등)
33.
On-demand Infra -Cloud
33
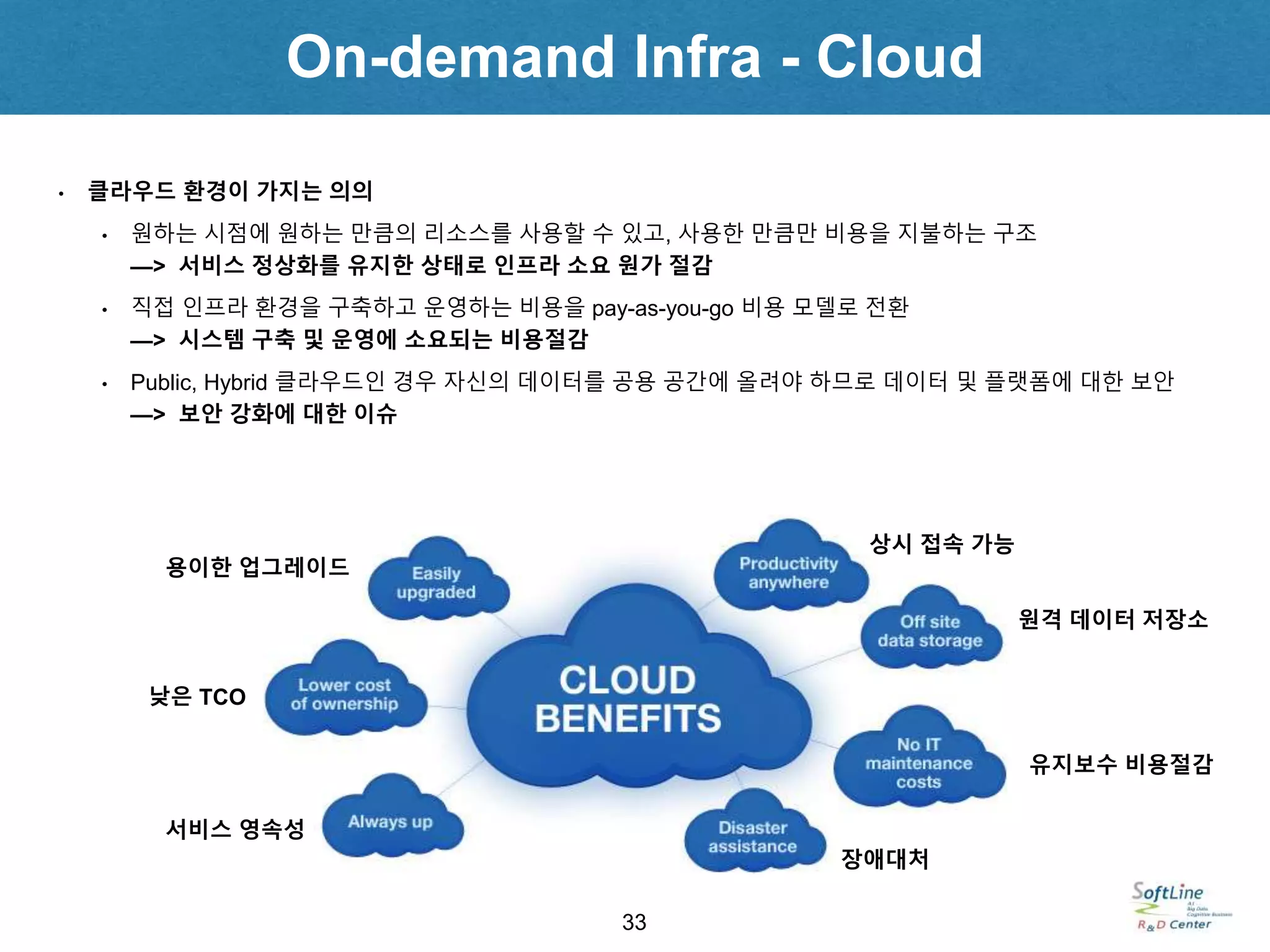
• 클라우드 환경이 가지는 의의
• 원하는 시점에 원하는 만큼의 리소스를 사용할 수 있고, 사용한 만큼만 비용을 지불하는 구조
—> 서비스 정상화를 유지한 상태로 인프라 소요 원가 절감
• 직접 인프라 환경을 구축하고 운영하는 비용을 pay-as-you-go 비용 모델로 전환
—> 시스템 구축 및 운영에 소요되는 비용절감
• Public, Hybrid 클라우드인 경우 자신의 데이터를 공용 공간에 올려야 하므로 데이터 및 플랫폼에 대한 보안
—> 보안 강화에 대한 이슈
용이한 업그레이드
낮은 TCO
서비스 영속성
장애대처
유지보수 비용절감
원격 데이터 저장소
상시 접속 가능
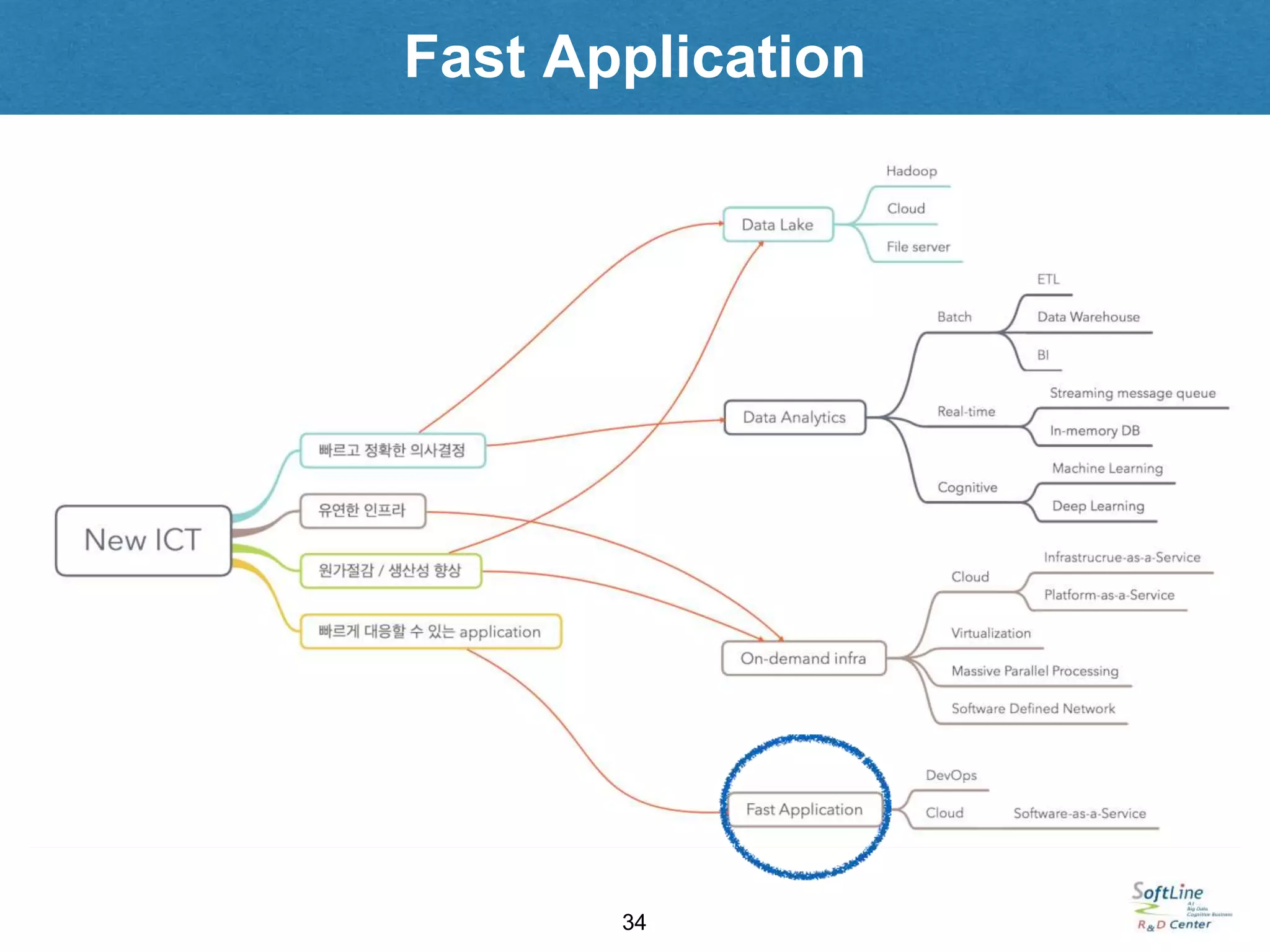
Fast Application
35
• 폭포수모델에 기반한 긴 기간에 걸친 프로젝트를 통해 어플리케이션을 개발하는 과거의 모델로는 빠르게
변화해야 하는 비즈니스 요건을 수용하기 어려움
• 따라서, 완벽한 어플리케이션을 개발해 업무에 적용하는 모델보다는…
• Application 을 상대적으로 작은 규모로 전체 업무 단위보다는 업무 내 서비스 단위로 구분
• 작은 단위의 application을 빠르게 개발하고 업무에 적용하여 운영단계로 진입
• 운영과정에서 추가 개발 / 업데이트를 통해 개선
• 이처럼 ‘빠른 개발 —> 운영 —> 개발 / 업데이트 —> 운영’ 과정을 반복적으로 진행하는 방식에 가장 적합한
소프트웨어 공학적 방법론이 agile 방법론
• 이러한 개발방식을 지원하는 플랫폼을 DevOps 라고 함






















![[코세나, kosena] 빅데이터 구축 및 제안 가이드](https://cdn.slidesharecdn.com/ss_thumbnails/random-161220075637-thumbnail.jpg?width=640&height=640&fit=bounds)



![[코세나, kosena] 금융권의 머신러닝 활용사례](https://cdn.slidesharecdn.com/ss_thumbnails/skytree-171103160507-thumbnail.jpg?width=640&height=640&fit=bounds)




![[SSA] 01.bigdata database technology (2014.02.05)](https://cdn.slidesharecdn.com/ss_thumbnails/01-140225072202-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)









![[코세나, kosena] 빅데이터 기반의 End-to-End APM과 비정형 데이터 분석 자료입니다.](https://cdn.slidesharecdn.com/ss_thumbnails/bigdataapmunstructureddata-140604123332-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

![[경북] I'mcloud information](https://cdn.slidesharecdn.com/ss_thumbnails/imcloudinformation-151105091525-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DDC 2018] Metatron 오픈소스화 및 생태계 구축 (SKT 이정룡, 김지호)](https://cdn.slidesharecdn.com/ss_thumbnails/ddc2018session1-181126012837-thumbnail.jpg?width=640&height=640&fit=bounds)



![[2018] 효율적인 데이터 관리를 위한 플랫폼 개발기](https://cdn.slidesharecdn.com/ss_thumbnails/machinebigdata06-190212052349-thumbnail.jpg?width=640&height=640&fit=bounds)







![[2016 데이터 그랜드 컨퍼런스] 1 3. bk3(엔코아)데이터그랜드컨퍼런스 4차산업혁명의 핵심-데이터경제-엔코아](https://cdn.slidesharecdn.com/ss_thumbnails/1-3-161125004936-thumbnail.jpg?width=640&height=640&fit=bounds)


