5
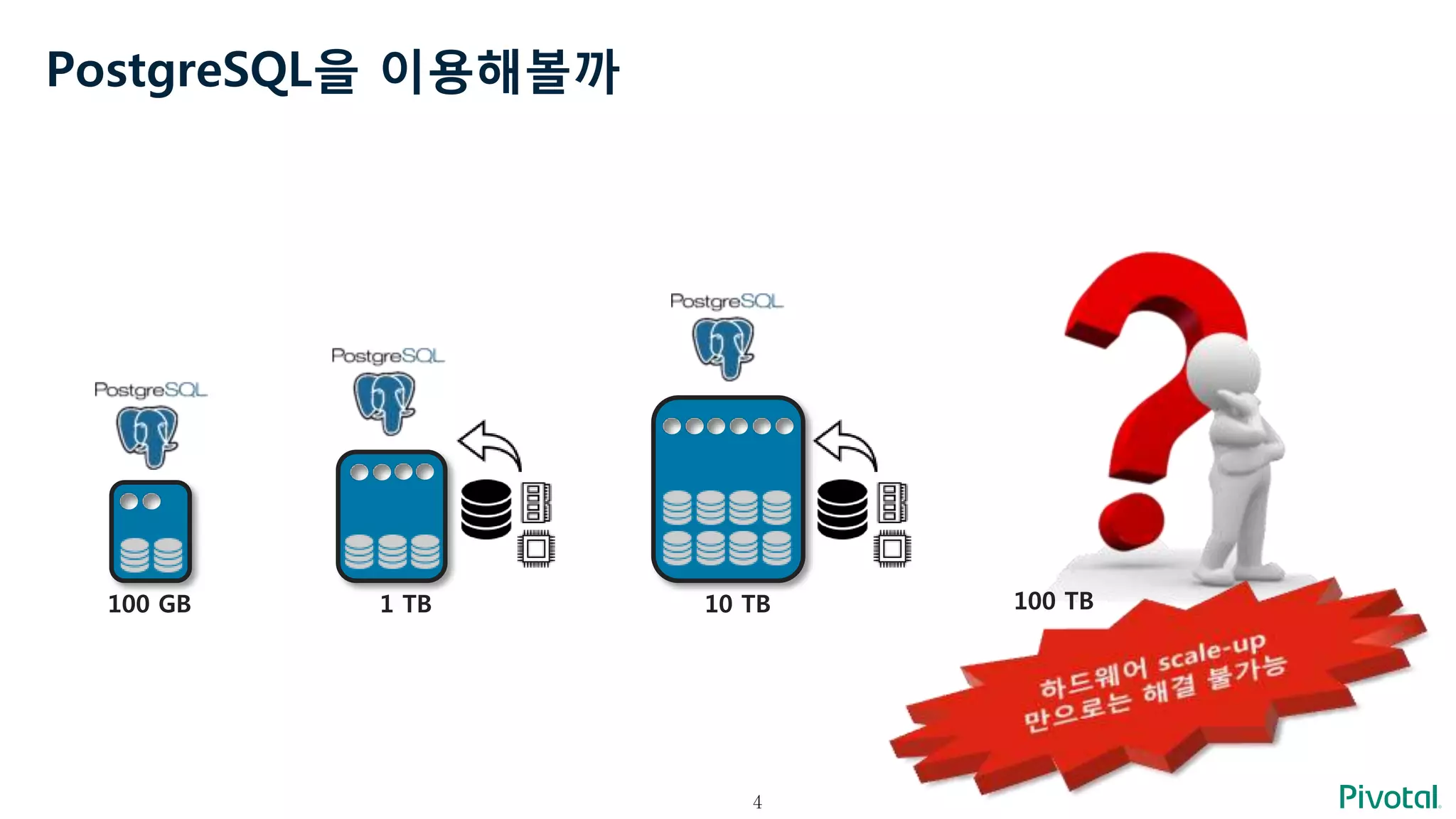
만약 여러 PostgreSQL이동시에 일을 한다면
데이터 처리량에 한계가 없겠구나
10 TB 10 TB 10 TB 10 TB 10 TB 10 TB 10 TB 10 TB 10 TB 10 TB
6.
6
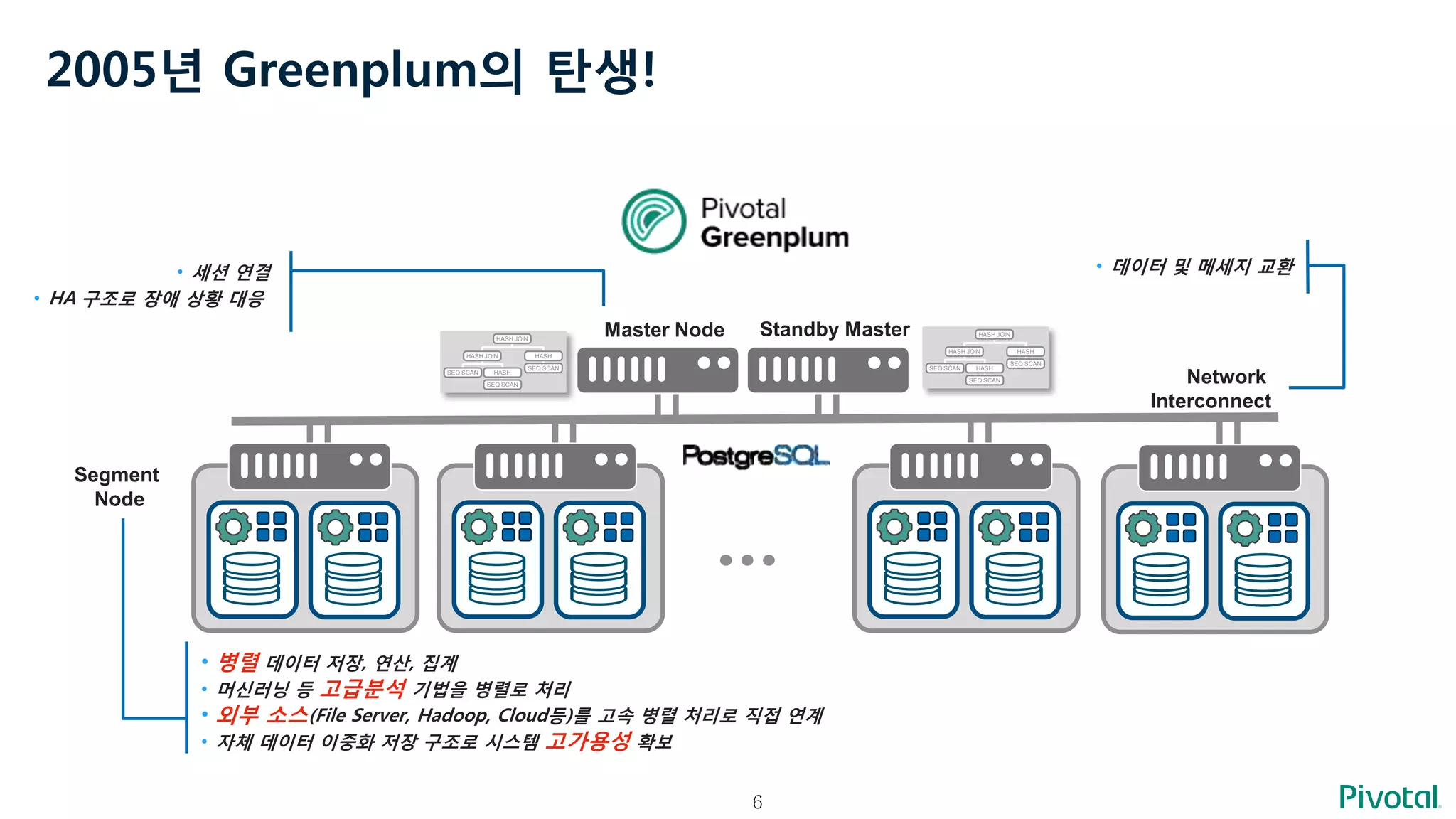
2005년 Greenplum의 탄생!
Network
Interconnect
…
Segment
Node
StandbyMasterMaster Node
SEQ SCAN HASH
SEQ SCAN
HASH JOIN HASH
SEQ SCAN
HASH JOIN
SEQ SCAN HASH
SEQ SCAN
HASH JOIN HASH
SEQ SCAN
HASH JOIN
• 세션 연결
• HA 구조로 장애 상황 대응
• 데이터 및 메세지 교환
• 병렬 데이터 저장, 연산, 집계
• 머신러닝 등 고급분석 기법을 병렬로 처리
• 외부 소스(File Server, Hadoop, Cloud등)를 고속 병렬 처리로 직접 연계
• 자체 데이터 이중화 저장 구조로 시스템 고가용성 확보
7.
7
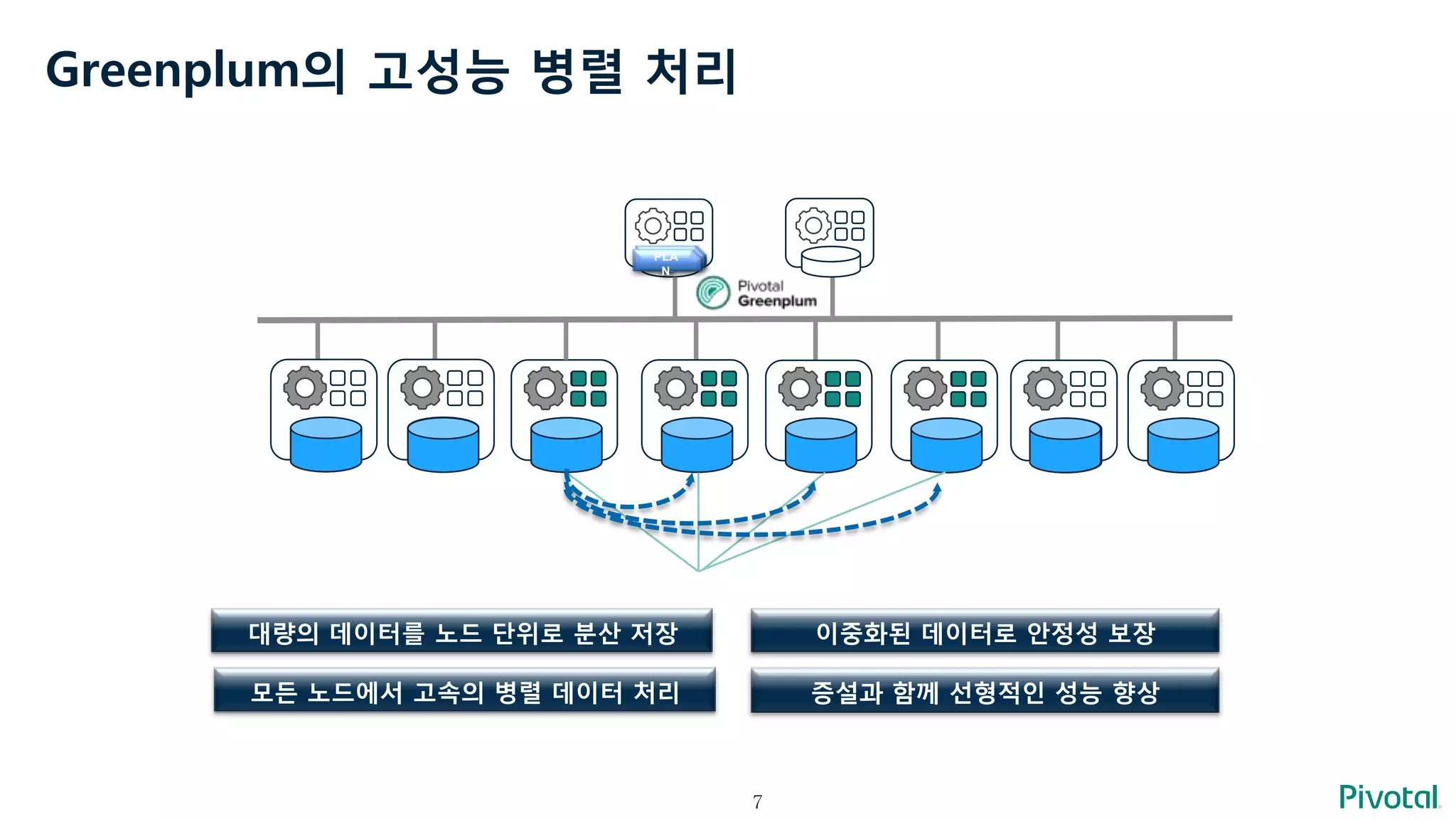
Greenplum의 고성능 병렬처리
대량의 데이터를 노드 단위로 분산 저장
모든 노드에서 고속의 병렬 데이터 처리
PLA
N
PLA
N
PLA
N
PLA
N
이중화된 데이터로 안정성 보장
증설과 함께 선형적인 성능 향상
8.
8
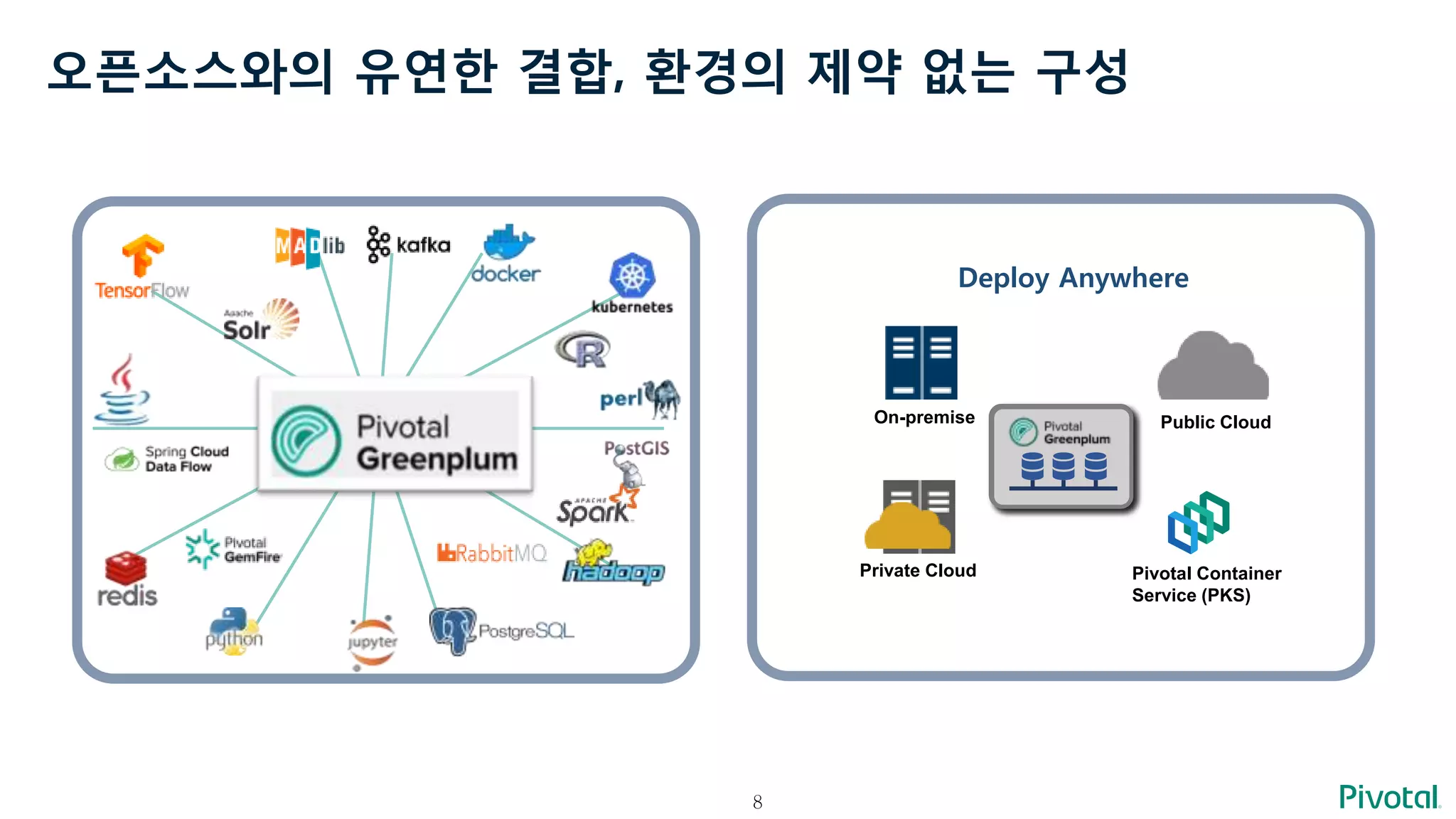
오픈소스와의 유연한 결합,환경의 제약 없는 구성
Deploy Anywhere
On-premise
Private Cloud
Public Cloud
Pivotal Container
Service (PKS)
9.
9
질문1. 얼마나 많은사람들이 Greenplum을 사용하는가?
17국내 고객수
42클러스터수
12
> 200TB
대용량 클러스터수
6.2전체 데이터량
480
단일클러스터기준
최대 데이터량
다수의 고객사로부터 검증된 분석 플랫폼
10.
10
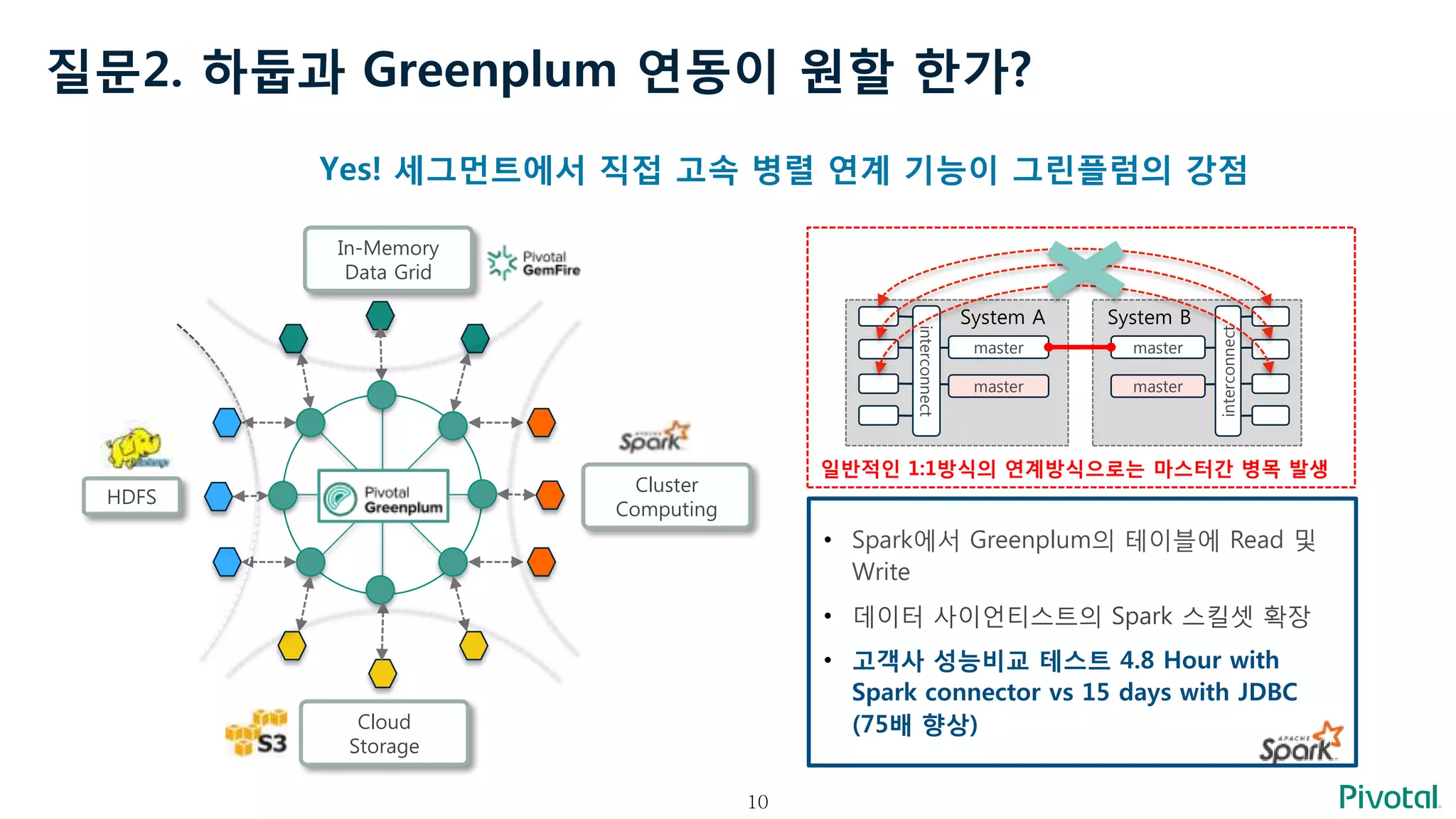
질문2. 하둡과 Greenplum연동이 원할 한가?
HDFS
Cluster
Computing
Cloud
Storage
In-Memory
Data Grid
interconnect
master
master
System B
interconnect
master
master
System A
일반적인 1:1방식의 연계방식으로는 마스터간 병목 발생
• Spark에서 Greenplum의 테이블에 Read 및
Write
• 데이터 사이언티스트의 Spark 스킬셋 확장
• 고객사 성능비교 테스트 4.8 Hour with
Spark connector vs 15 days with JDBC
(75배 향상)
Yes! 세그먼트에서 직접 고속 병렬 연계 기능이 그린플럼의 강점
11.
11
질문3. 비정형 분석을위해서 하둡을 함께 사용해야만 하는가?
No. 그린플럼은 비정형 데이터까지 통합하여 분석
REGRESSIONCLASSIFICATIONCLUSTERINGGraph GeospatialTraditional BI / ReportSQL TEXT Transformation
Structured Data
Any Workload
Any Data
비정형 데이터 통합 분석 사례 : 국지성 이상기후 예측
다양한 유형의 날씨 관련 데이터를 병렬 시뮬레이션을 통해 국지성 집중호우 발생 10분 전 예측함
Data 수집 Data 통합/처리 및 분석 Application 활용
§ 다양한 유형의 대용량 데이터 수집 § Large-scale 3D rain computer simulation
- 100개의 날씨 병렬 시뮬레이션 동시 수행
(↔ 기존: 1개씩 시뮬레이션 순차 실행)
- 100m 그리드 공간 대상 예측
(↔ 기존: 2km 또는 5km 그리드 공간 대상)
§ 3D Nowcasting
- 모바일앱을 통해 실시간
국지성 집중호우
발생 10분 전 경고
- 정확도 80% 이상
(↔ 기존 50% 내외)
- Phased-array radar 측정 데이터
: 15개 층의 대기 습도
3차원 측정
(↔ 기존: 1개 층
2차원 측정)
: 30초 단위 업데이트
- 날씨 위성 측정 데이터
: 최상부 구름의 높이, 바람, 온도,
대기 내 습도
- 지도 데이터
- 교통 흐름 데이터
- 위치 태그된 트위터 데이터
ü 인명 및
재산 피해
최소화
[ GPDB 기반 국지성 집중호우 예측 플랫폼 ]
텍스트
벡터 데이터
비트맵
이미지
센서
데이터
- 인구 이동 데이터
대용량 데이터 분산 병렬 처리
(Massively Parallel Processing)
ü 다양한 유형의 데이터를 단일 플랫폼 내 저장
In-Database
예측 모형 분석
…
GPText
* source: “Greenplum for Extreme Weather Predictions and Analytics at Japan’s NICT” (https://www.youtube.com/watch?v=pjDSi1KGaDU)
12.
12
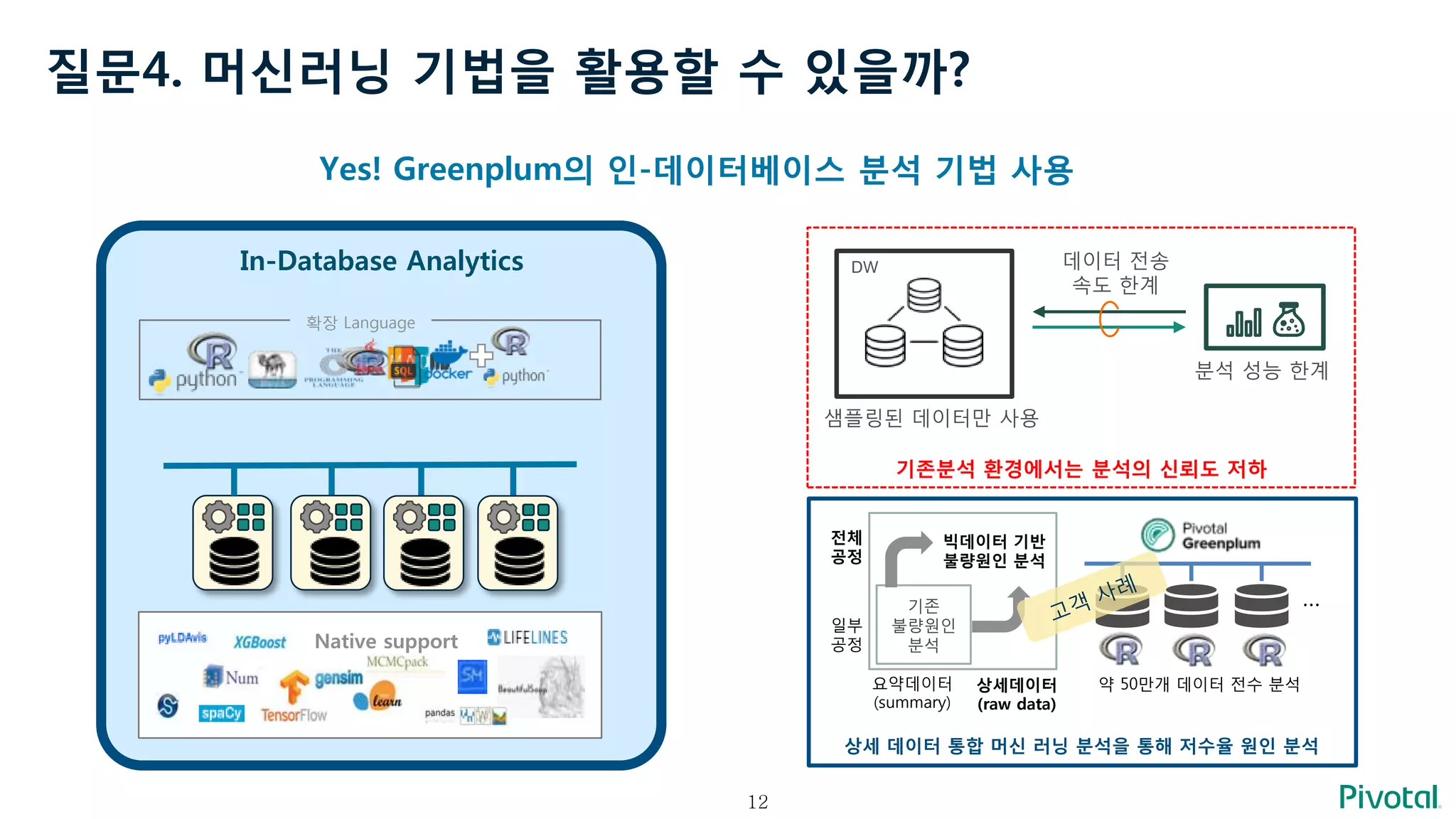
질문4. 머신러닝 기법을활용할 수 있을까?
Yes! Greenplum의 인-데이터베이스 분석 기법 사용
In-Database Analytics
Native support
확장 Language
기존분석 환경에서는 분석의 신뢰도 저하
분석 성능 한계
DW
샘플링된 데이터만 사용
데이터 전송
속도 한계
상세 데이터 통합 머신 러닝 분석을 통해 저수율 원인 분석
요약데이터
(summary)
상세데이터
(raw data)
일부
공정
전체
공정
기존
불량원인
분석
빅데이터 기반
불량원인 분석
…
약 50만개 데이터 전수 분석
14
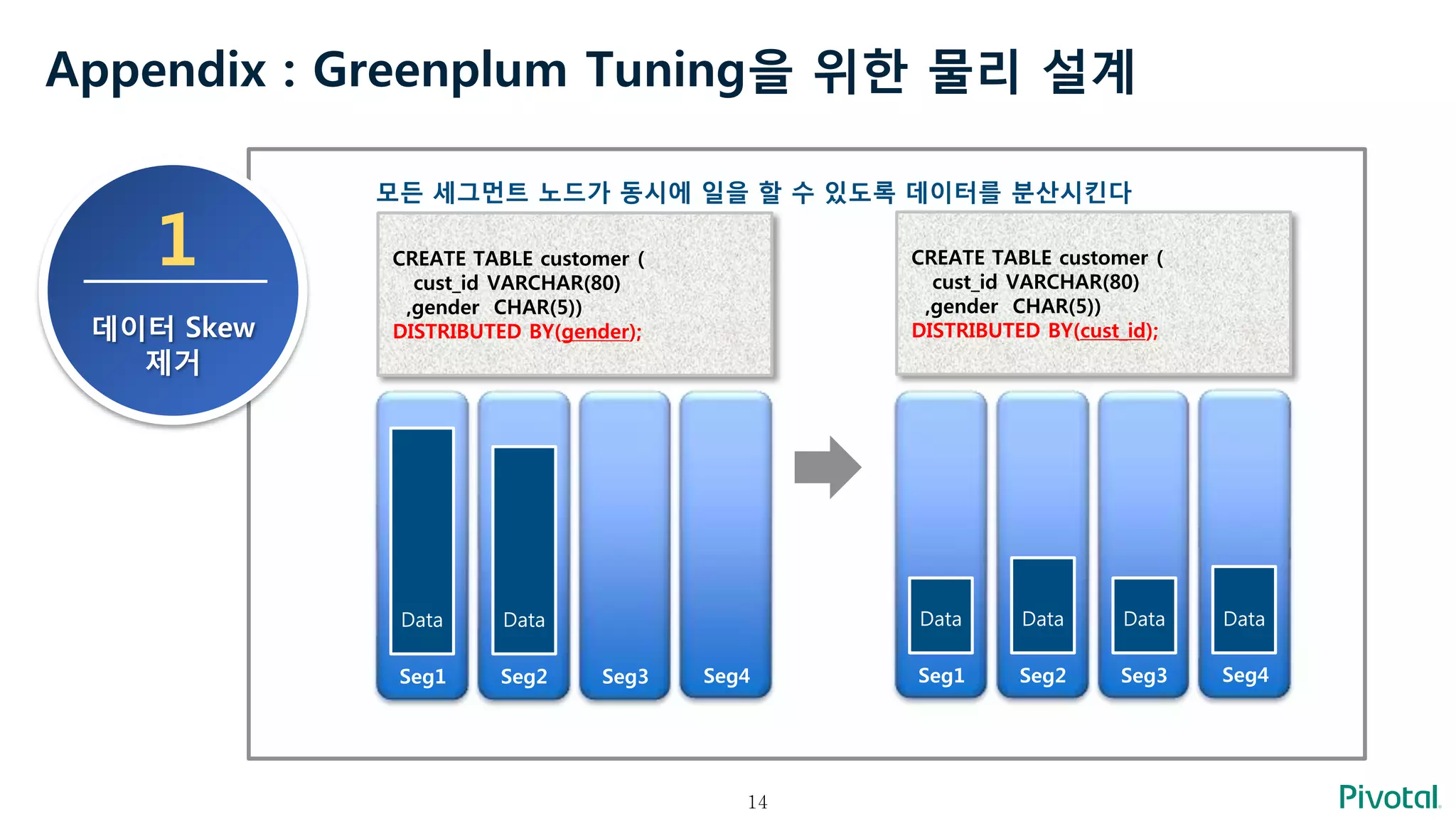
Appendix : GreenplumTuning을 위한 물리 설계
1
데이터 Skew
제거
모든 세그먼트 노드가 동시에 일을 할 수 있도록 데이터를 분산시킨다
Seg1 Seg2 Seg3 Seg4
CREATE TABLE customer (
cust_id VARCHAR(80)
,gender CHAR(5))
DISTRIBUTED BY(gender);
Data Data
Seg1 Seg2 Seg3 Seg4
CREATE TABLE customer (
cust_id VARCHAR(80)
,gender CHAR(5))
DISTRIBUTED BY(cust_id);
Data Data Data Data
15.
15
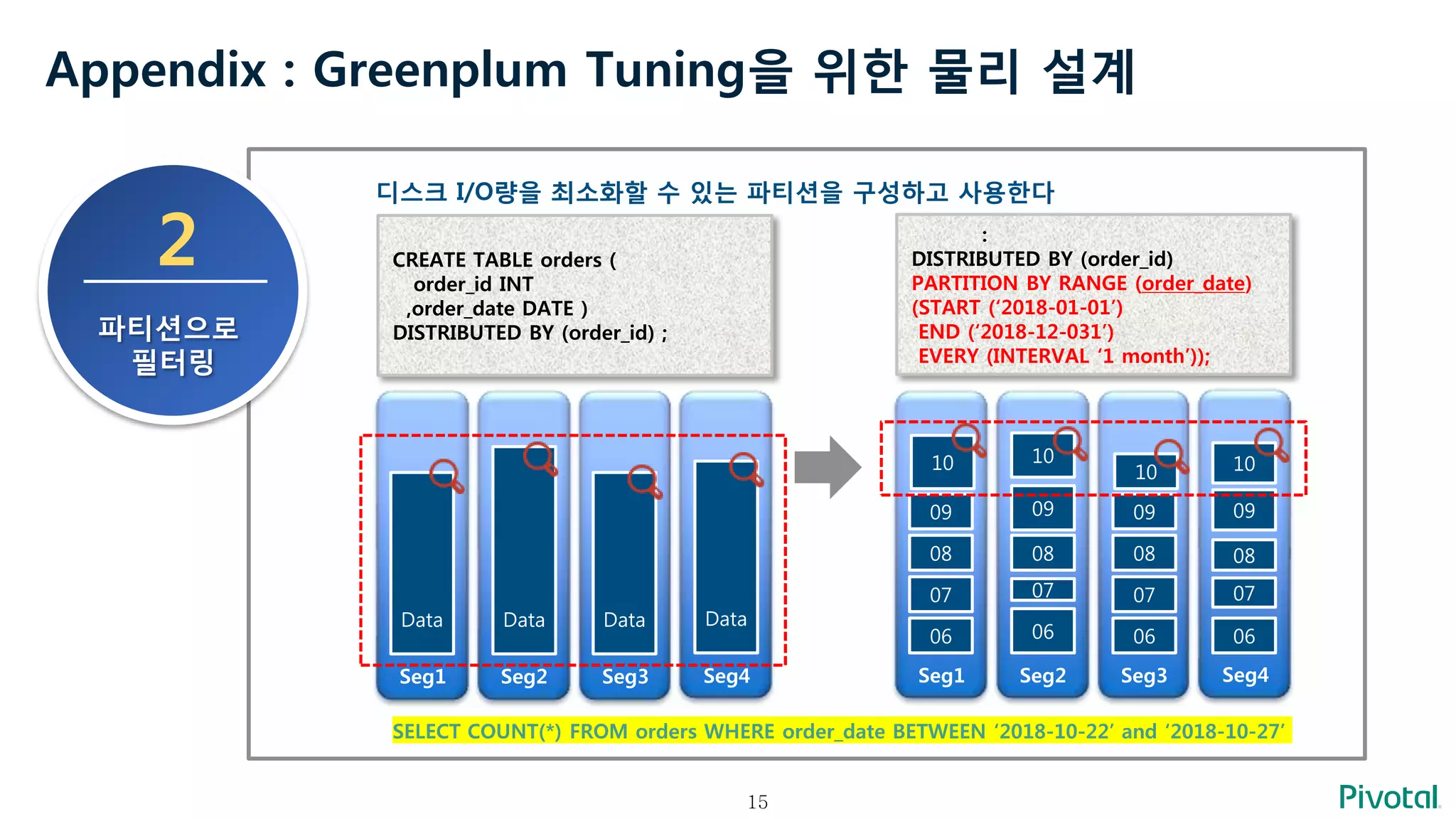
Appendix : GreenplumTuning을 위한 물리 설계
2
파티션으로
필터링
디스크 I/O량을 최소화할 수 있는 파티션을 구성하고 사용한다
Seg1 Seg2 Seg3 Seg4
CREATE TABLE orders (
order_id INT
,order_date DATE )
DISTRIBUTED BY (order_id) ;
Data Data
Seg1 Seg2 Seg3 Seg4
:
DISTRIBUTED BY (order_id)
PARTITION BY RANGE (order_date)
(START (‘2018-01-01’)
END (‘2018-12-031’)
EVERY (INTERVAL ‘1 month’));
06 06 06 06
Data Data
SELECT COUNT(*) FROM orders WHERE order_date BETWEEN ‘2018-10-22’ and ‘2018-10-27’
07 07 07 07
08 08 08 08
09 09 09 09
10 10
10 10
16.
16
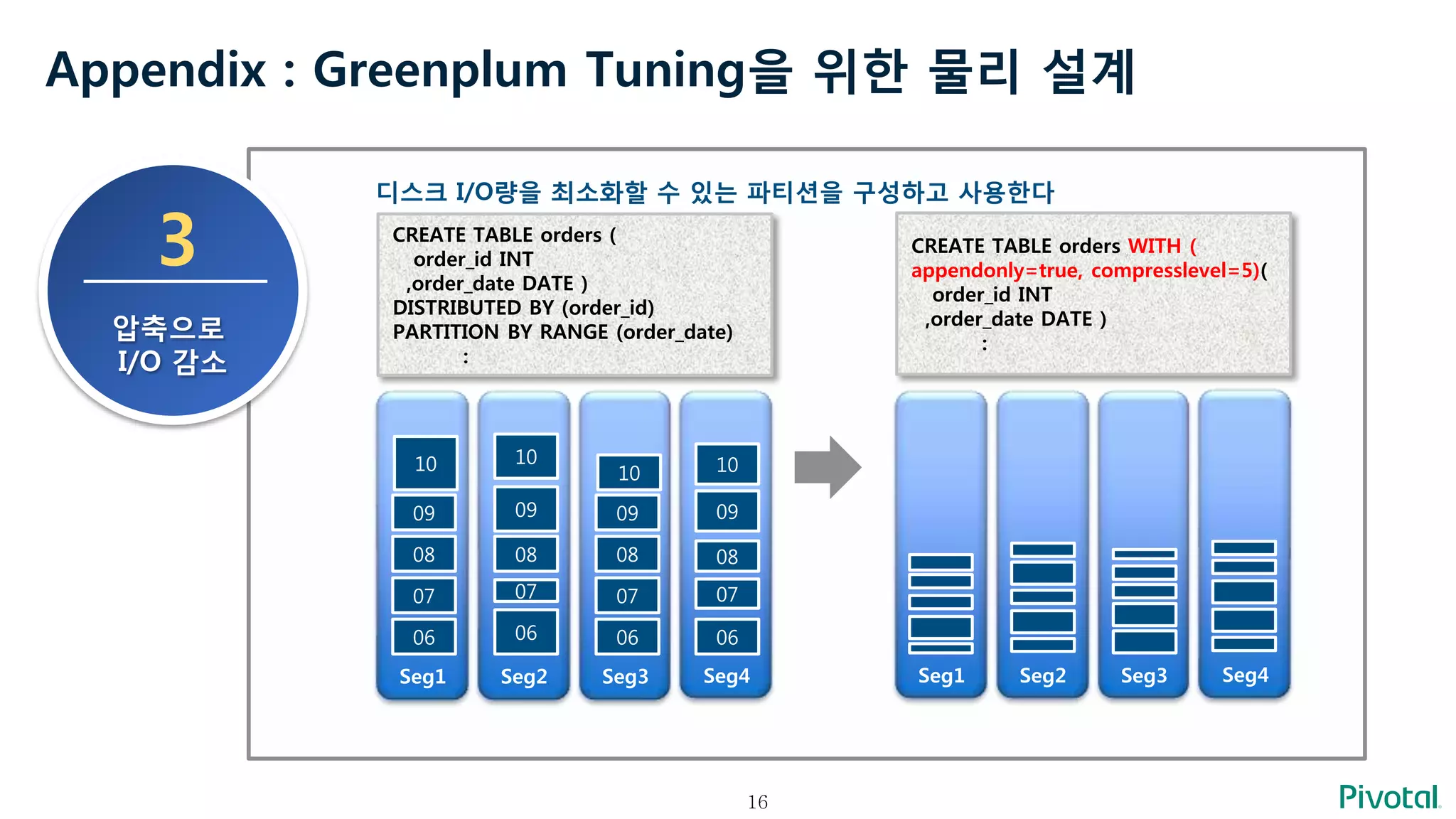
Appendix : GreenplumTuning을 위한 물리 설계
3
압축으로
I/O 감소
디스크 I/O량을 최소화할 수 있는 파티션을 구성하고 사용한다
Seg1 Seg2 Seg3 Seg4
CREATE TABLE orders (
order_id INT
,order_date DATE )
DISTRIBUTED BY (order_id)
PARTITION BY RANGE (order_date)
:
Seg1 Seg2 Seg3 Seg4
CREATE TABLE orders WITH (
appendonly=true, compresslevel=5)(
order_id INT
,order_date DATE )
:
06 06 06 06
07 07 07 07
08 08 08 08
09 09 09 09
10 10
10 10
17.
17
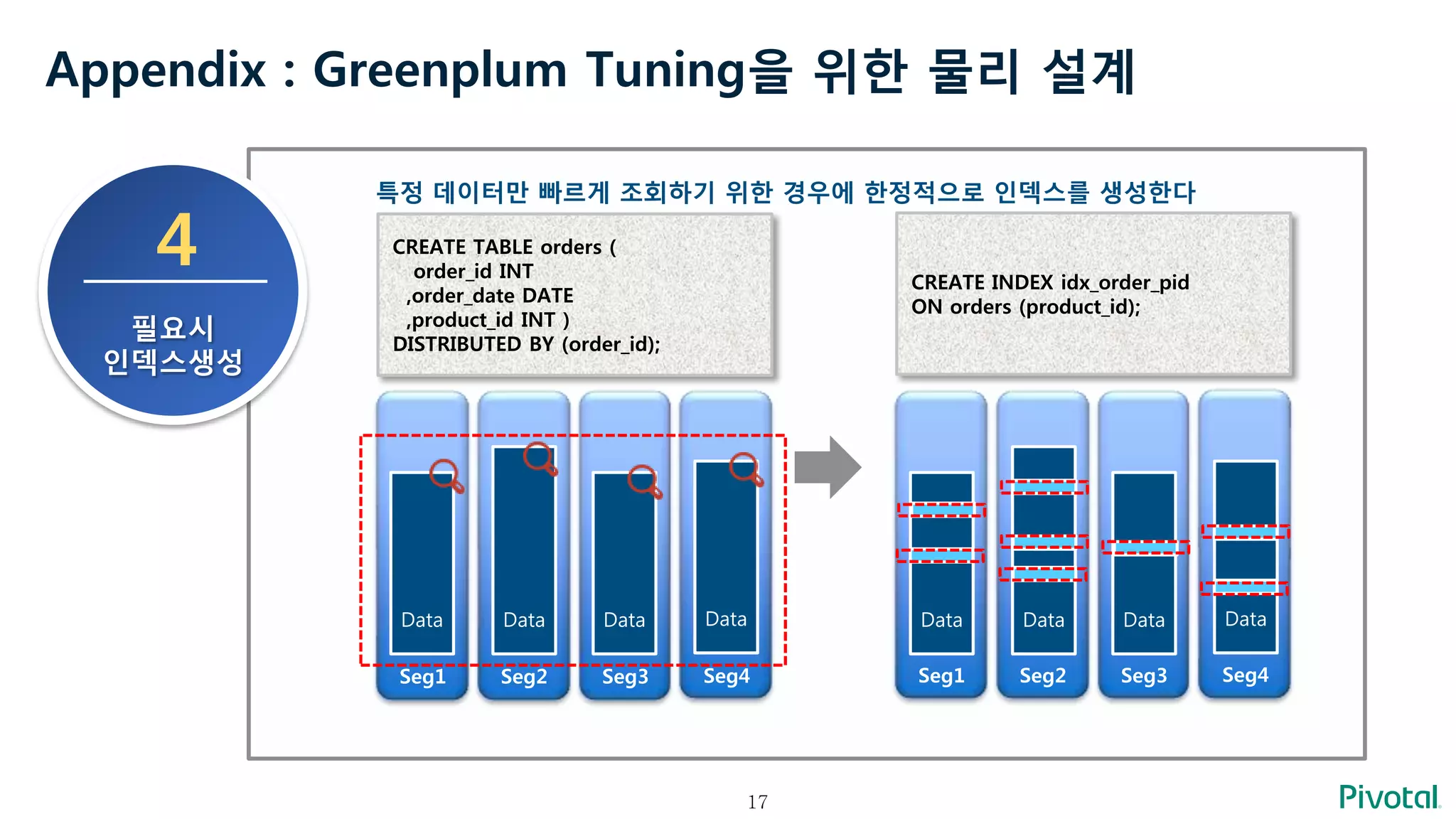
Appendix : GreenplumTuning을 위한 물리 설계
4
필요시
인덱스생성
특정 데이터만 빠르게 조회하기 위한 경우에 한정적으로 인덱스를 생성한다
Seg1 Seg2 Seg3 Seg4
CREATE TABLE orders (
order_id INT
,order_date DATE
,product_id INT )
DISTRIBUTED BY (order_id);
Seg1 Seg2 Seg3 Seg4
CREATE INDEX idx_order_pid
ON orders (product_id);
Data Data Data Data Data Data Data Data




![11
질문3. 비정형 분석을 위해서 하둡을 함께 사용해야만 하는가?
No. 그린플럼은 비정형 데이터까지 통합하여 분석
REGRESSIONCLASSIFICATIONCLUSTERINGGraph GeospatialTraditional BI / ReportSQL TEXT Transformation
Structured Data
Any Workload
Any Data
비정형 데이터 통합 분석 사례 : 국지성 이상기후 예측
다양한 유형의 날씨 관련 데이터를 병렬 시뮬레이션을 통해 국지성 집중호우 발생 10분 전 예측함
Data 수집 Data 통합/처리 및 분석 Application 활용
§ 다양한 유형의 대용량 데이터 수집 § Large-scale 3D rain computer simulation
- 100개의 날씨 병렬 시뮬레이션 동시 수행
(↔ 기존: 1개씩 시뮬레이션 순차 실행)
- 100m 그리드 공간 대상 예측
(↔ 기존: 2km 또는 5km 그리드 공간 대상)
§ 3D Nowcasting
- 모바일앱을 통해 실시간
국지성 집중호우
발생 10분 전 경고
- 정확도 80% 이상
(↔ 기존 50% 내외)
- Phased-array radar 측정 데이터
: 15개 층의 대기 습도
3차원 측정
(↔ 기존: 1개 층
2차원 측정)
: 30초 단위 업데이트
- 날씨 위성 측정 데이터
: 최상부 구름의 높이, 바람, 온도,
대기 내 습도
- 지도 데이터
- 교통 흐름 데이터
- 위치 태그된 트위터 데이터
ü 인명 및
재산 피해
최소화
[ GPDB 기반 국지성 집중호우 예측 플랫폼 ]
텍스트
벡터 데이터
비트맵
이미지
센서
데이터
- 인구 이동 데이터
대용량 데이터 분산 병렬 처리
(Massively Parallel Processing)
ü 다양한 유형의 데이터를 단일 플랫폼 내 저장
In-Database
예측 모형 분석
…
GPText
* source: “Greenplum for Extreme Weather Predictions and Analytics at Japan’s NICT” (https://www.youtube.com/watch?v=pjDSi1KGaDU)](https://image.slidesharecdn.com/02-20181103pgdayseminarv1-181112041352/75/Pgday-Seoul-2018-Greenplum-11-2048.jpg)































![[NDC18] 야생의 땅 듀랑고의 데이터 엔지니어링 이야기: 로그 시스템 구축 경험 공유 (2부)](https://cdn.slidesharecdn.com/ss_thumbnails/ndc2018-2-180430180517-thumbnail.jpg?width=640&height=640&fit=bounds)
![[124]네이버에서 사용되는 여러가지 Data Platform, 그리고 MongoDB](https://cdn.slidesharecdn.com/ss_thumbnails/124mongodb-181011042943-thumbnail.jpg?width=640&height=640&fit=bounds)






![[경북] I'mcloud information](https://cdn.slidesharecdn.com/ss_thumbnails/imcloudinformation-151105091525-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)


![[AWS Builders] 우리 워크로드에 맞는 데이터베이스 찾기](https://cdn.slidesharecdn.com/ss_thumbnails/awsbuildersaws201webinardatabasejuyeonpark-190306072417-thumbnail.jpg?width=640&height=640&fit=bounds)






![[스마트스터디]모바일 애플리케이션 서비스에서의 로그 수집과 분석](https://cdn.slidesharecdn.com/ss_thumbnails/redismongodbmysql-171107063045-thumbnail.jpg?width=640&height=640&fit=bounds)

![[pgday.Seoul 2022] PostgreSQL with Google Cloud](https://cdn.slidesharecdn.com/ss_thumbnails/pgday-postgresqlwithgooglecloud-221114013605-5def484f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2020] SQL Tuning](https://cdn.slidesharecdn.com/ss_thumbnails/pgday-201117134901-thumbnail.jpg?width=640&height=640&fit=bounds)
![[pgday.Seoul 2022] PostgreSQL구조 - 윤성재](https://cdn.slidesharecdn.com/ss_thumbnails/pgday2022-postgresql-20221112-221114014106-bbfb1955-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2017] 1. PostGIS의 사례로 본 PostgreSQL 확장 - 장병진](https://cdn.slidesharecdn.com/ss_thumbnails/postgispostgresqlpgday2017-171103060406-171106044046-thumbnail.jpg?width=640&height=640&fit=bounds)
![[pgday.Seoul 2022] 서비스개편시 PostgreSQL 도입기 - 진소린 & 김태정](https://cdn.slidesharecdn.com/ss_thumbnails/postgresql-221121085744-f0fb1a8a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[pgday.Seoul 2022] POSTGRES 테스트코드로 기여하기 - 이동욱](https://cdn.slidesharecdn.com/ss_thumbnails/postgres-221114014538-b9df2ddf-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2021] 1. 예제로 살펴보는 포스트그레스큐엘의 독특한 SQL](https://cdn.slidesharecdn.com/ss_thumbnails/sql-211217063145-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2021] 2. Porting Oracle UDF and Optimization](https://cdn.slidesharecdn.com/ss_thumbnails/oracleudfmigration20211203-211227052428-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2018] 이기종 DB에서 PostgreSQL로의 Migration을 위한 DB2PG](https://cdn.slidesharecdn.com/ss_thumbnails/04-pgdaydb2pgv1-181112042107-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2017] 6. GIN vs GiST 인덱스 이야기 - 박진우](https://cdn.slidesharecdn.com/ss_thumbnails/pgday-171106044702-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2019] Citus를 이용한 분산 데이터베이스](https://cdn.slidesharecdn.com/ss_thumbnails/citus20191207studypgday-191218045308-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2018] replacing oracle with edb postgres](https://cdn.slidesharecdn.com/ss_thumbnails/01-replacingoraclewithedbpostgres20181023-181112040354-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2019] Advanced FDW](https://cdn.slidesharecdn.com/ss_thumbnails/tarantulav2-191218044914-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2018] PostgreSQL 11 새 기능 소개](https://cdn.slidesharecdn.com/ss_thumbnails/pgday2018-pg11-181112042714-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2018] PostgreSQL Authentication with FreeIPA](https://cdn.slidesharecdn.com/ss_thumbnails/05-20181103pgdayseoulpostgresqlauthenticationwithfreeipa-181112042327-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2020] 포스트그레스큐엘 자국어화 이야기](https://cdn.slidesharecdn.com/ss_thumbnails/postgresqli18nko-201117135339-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2018] AWS Cloud 환경에서 PostgreSQL 구축하기](https://cdn.slidesharecdn.com/ss_thumbnails/03-pgday-flytothecloudkimdongsu-181112041825-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2018] PostgreSQL 성능을 위해 개발된 라이브러리 OS 소개 apposha](https://cdn.slidesharecdn.com/ss_thumbnails/06-pgdayseoul2018sangwook-181112042505-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2019] AppOS 고성능 I/O 확장 모듈로 성능 10배 향상시키기](https://cdn.slidesharecdn.com/ss_thumbnails/appos-2019-191218045825-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2017] 5. 테드폴허브(올챙이) PostgreSQL 확장하기 - 조현종](https://cdn.slidesharecdn.com/ss_thumbnails/postgresql-171106044405-thumbnail.jpg?width=640&height=640&fit=bounds)