Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Hisao Soyama
PDF, PPTX
4,198 views
階層ベイズでプロ野球各球団の「本当の強さ」を推定してみる
階層ベイズでプロ野球各球団の「本当の強さ」を推定してみる
Data & Analytics
◦
Read more
13
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 34
2
/ 34
3
/ 34
4
/ 34
5
/ 34
6
/ 34
7
/ 34
8
/ 34
9
/ 34
10
/ 34
Most read
11
/ 34
12
/ 34
13
/ 34
14
/ 34
15
/ 34
16
/ 34
17
/ 34
18
/ 34
19
/ 34
20
/ 34
21
/ 34
22
/ 34
23
/ 34
24
/ 34
25
/ 34
26
/ 34
27
/ 34
28
/ 34
29
/ 34
30
/ 34
31
/ 34
32
/ 34
33
/ 34
34
/ 34
More Related Content
PDF
2 3.GLMの基礎
by
logics-of-blue
PDF
階層モデルの分散パラメータの事前分布について
by
hoxo_m
PDF
マーク付き点過程
by
Yoshiaki Sakakura
PDF
Stanの便利な事後処理関数
by
daiki hojo
PPTX
心理学者のためのGlmm・階層ベイズ
by
Hiroshi Shimizu
PDF
Chapter9 一歩進んだ文法(前半)
by
itoyan110
PDF
Stanコードの書き方 中級編
by
Hiroshi Shimizu
PDF
第4回DARM勉強会 (構造方程式モデリング)
by
Yoshitake Takebayashi
2 3.GLMの基礎
by
logics-of-blue
階層モデルの分散パラメータの事前分布について
by
hoxo_m
マーク付き点過程
by
Yoshiaki Sakakura
Stanの便利な事後処理関数
by
daiki hojo
心理学者のためのGlmm・階層ベイズ
by
Hiroshi Shimizu
Chapter9 一歩進んだ文法(前半)
by
itoyan110
Stanコードの書き方 中級編
by
Hiroshi Shimizu
第4回DARM勉強会 (構造方程式モデリング)
by
Yoshitake Takebayashi
What's hot
PDF
2 4.devianceと尤度比検定
by
logics-of-blue
PPTX
ベイズ統計学の概論的紹介
by
Naoki Hayashi
PPTX
StanとRでベイズ統計モデリングに関する読書会(Osaka.stan) 第四章
by
nocchi_airport
PDF
Stan超初心者入門
by
Hiroshi Shimizu
PPTX
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
by
RyuichiKanoh
PDF
2 5 3.一般化線形モデル色々_Gamma回帰と対数線形モデル
by
logics-of-blue
PDF
ブースティング入門
by
Retrieva inc.
PDF
Prophet入門【理論編】Facebookの時系列予測ツール
by
hoxo_m
PPTX
SHAP値の考え方を理解する(木構造編)
by
Kazuyuki Wakasugi
PPT
100614 構造方程式モデリング基本の「き」
by
Shinohara Masahiro
PDF
[DL輪読会]Deep Learning 第5章 機械学習の基礎
by
Deep Learning JP
PDF
心理学におけるベイズ統計の流行を整理する
by
Hiroshi Shimizu
PPTX
ベイズファクターとモデル選択
by
kazutantan
PDF
pymcとpystanでベイズ推定してみた話
by
Classi.corp
PDF
MCMCと正規分布の推測
by
Gen Fujita
PDF
StanとRでベイズ統計モデリング読書会 Chapter 7(7.6-7.9) 回帰分析の悩みどころ ~統計の力で歌うまになりたい~
by
nocchi_airport
PDF
星野「調査観察データの統計科学」第3章
by
Shuyo Nakatani
PDF
バンディットアルゴリズム入門と実践
by
智之 村上
PDF
PRML輪読#1
by
matsuolab
PDF
階層ベイズとWAIC
by
Hiroshi Shimizu
2 4.devianceと尤度比検定
by
logics-of-blue
ベイズ統計学の概論的紹介
by
Naoki Hayashi
StanとRでベイズ統計モデリングに関する読書会(Osaka.stan) 第四章
by
nocchi_airport
Stan超初心者入門
by
Hiroshi Shimizu
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
by
RyuichiKanoh
2 5 3.一般化線形モデル色々_Gamma回帰と対数線形モデル
by
logics-of-blue
ブースティング入門
by
Retrieva inc.
Prophet入門【理論編】Facebookの時系列予測ツール
by
hoxo_m
SHAP値の考え方を理解する(木構造編)
by
Kazuyuki Wakasugi
100614 構造方程式モデリング基本の「き」
by
Shinohara Masahiro
[DL輪読会]Deep Learning 第5章 機械学習の基礎
by
Deep Learning JP
心理学におけるベイズ統計の流行を整理する
by
Hiroshi Shimizu
ベイズファクターとモデル選択
by
kazutantan
pymcとpystanでベイズ推定してみた話
by
Classi.corp
MCMCと正規分布の推測
by
Gen Fujita
StanとRでベイズ統計モデリング読書会 Chapter 7(7.6-7.9) 回帰分析の悩みどころ ~統計の力で歌うまになりたい~
by
nocchi_airport
星野「調査観察データの統計科学」第3章
by
Shuyo Nakatani
バンディットアルゴリズム入門と実践
by
智之 村上
PRML輪読#1
by
matsuolab
階層ベイズとWAIC
by
Hiroshi Shimizu
Viewers also liked
PDF
本当に知ってる!? リアルなデータ分析の世界~サイカのエンジニアが語る、話題の技術の「いま」と「未来」~
by
Hisao Soyama
PDF
『アジャイルデータサイエンス』2章 データ
by
Hisao Soyama
PDF
Pythonによるソーシャルデータ分析―わたしはこうやって修士号を取得しました―
by
Hisao Soyama
PDF
10分でわかるPythonの開発環境
by
Hisao Soyama
PDF
『アジャイルデータサイエンス』1章 理論
by
Hisao Soyama
PDF
大学生のTwitter利用に関する定量分析―利用目的とサービス設計の関係―
by
Hisao Soyama
PDF
みんなで使おう京都データストア・ワークショップ
by
Department of Policy Planning, Kyoto Prefectural Government
PDF
Matrix
by
Hisao Soyama
PDF
『オープンソースで学ぶ社会ネットワーク分析』1章 イントロダクション
by
Hisao Soyama
PDF
グラフデータベース「Neo4j」の 導入の導入(続き)-Cypherの基本のキ-
by
Hisao Soyama
PDF
SQL Developerって必要ですか? 株式会社コーソル 河野 敏彦
by
CO-Sol for Community
PDF
グラフデータベース「Neo4j」の 導入の導入
by
Hisao Soyama
PDF
PyMCがあれば,ベイズ推定でもう泣いたりなんかしない
by
Toshihiro Kamishima
PDF
Pythonによる機械学習入門 ~SVMからDeep Learningまで~
by
Yasutomo Kawanishi
PDF
学部生向けベイズ統計イントロ(公開版)
by
考司 小杉
PDF
野球Hack!~Pythonを用いたデータ分析と可視化 #pyconjp
by
Shinichi Nakagawa
PDF
PyMC mcmc
by
Xiangze
本当に知ってる!? リアルなデータ分析の世界~サイカのエンジニアが語る、話題の技術の「いま」と「未来」~
by
Hisao Soyama
『アジャイルデータサイエンス』2章 データ
by
Hisao Soyama
Pythonによるソーシャルデータ分析―わたしはこうやって修士号を取得しました―
by
Hisao Soyama
10分でわかるPythonの開発環境
by
Hisao Soyama
『アジャイルデータサイエンス』1章 理論
by
Hisao Soyama
大学生のTwitter利用に関する定量分析―利用目的とサービス設計の関係―
by
Hisao Soyama
みんなで使おう京都データストア・ワークショップ
by
Department of Policy Planning, Kyoto Prefectural Government
Matrix
by
Hisao Soyama
『オープンソースで学ぶ社会ネットワーク分析』1章 イントロダクション
by
Hisao Soyama
グラフデータベース「Neo4j」の 導入の導入(続き)-Cypherの基本のキ-
by
Hisao Soyama
SQL Developerって必要ですか? 株式会社コーソル 河野 敏彦
by
CO-Sol for Community
グラフデータベース「Neo4j」の 導入の導入
by
Hisao Soyama
PyMCがあれば,ベイズ推定でもう泣いたりなんかしない
by
Toshihiro Kamishima
Pythonによる機械学習入門 ~SVMからDeep Learningまで~
by
Yasutomo Kawanishi
学部生向けベイズ統計イントロ(公開版)
by
考司 小杉
野球Hack!~Pythonを用いたデータ分析と可視化 #pyconjp
by
Shinichi Nakagawa
PyMC mcmc
by
Xiangze
階層ベイズでプロ野球各球団の「本当の強さ」を推定してみる
1.
階層ベイズで プロ野球各球団の 「本当の強さ」を 推定してみる @who_you_me
2.
2016年 いろいろなことがありました
3.
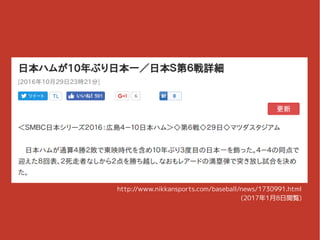
ショッキングな出来事
4.
http://www.nikkansports.com/baseball/news/1730991.html (2017年1月8日閲覧)
5.
ちょっと待ってほしい
6.
日本シリーズ勝者 = 一番強いチーム なのか?
7.
私怨で言ってるんじゃなくて 統計の話がしたいんですよ私は ● Cの真の勝率が0.6、Fの真の勝率が0.4のと き、4勝2敗以上の成績でFが勝者となる確率 – 0.1792
8.
私怨で言ってるんじゃなくて 統計の話がしたいんですよ私は ● 「本当はCの方が強い場合でも17.9%の確率で 起こる現象」が実際に起こったからといってF の方が強いって言えますか奥さん – フォーマルに言うと「Cの真の勝率が0.6という帰 無仮説を有意水準0.05で棄却できない」
9.
私怨で言ってるんじゃなくて 統計の話がしたいんですよ私は ● 日本シリーズは「先に4勝した方が勝ち」 ● (引き分けを考慮しないと)最大7試合しかな いので、日本シリーズ勝者 = 真の強者である と主張することは難しい そもそも今はクライマックスシリーズがあるので議論はさらに面倒なことに
10.
ではどうすればよいか
11.
ではどうすればよいか ● 半年かけて年間143試合もやっているので、 「シーズン順位(勝率) = 真の強さを反映」 とは言えそう ● ではシーズン勝率を見ればいいのか?
12.
よくない
13.
よくない理由 ● リーグ間には実力差があるので(パ>>>セ) 異なるリーグ間で勝率を単純に比較することは できない ● 交流戦はあるが、1チームあたり18試合しかな いので「交流戦順位 = 真の強さを反映」とも 言えない –
(だからこそ日本シリーズがある)
14.
シーズンの全勝敗情報を活かしつつ、 直接対決が少ないチーム同士でも 実力を比較できるような方法は ないのだろうか……
15.
ある
16.
ベイズモデリングだ!!!
17.
こんなデータセットを作る ● 1試合が1行の勝敗データ ● F対Hの対戦成績が15-9のとき、LoserがF、 WinnerがHの行が9個、逆の行が15個ある
18.
こうモデリングする 松浦(2016) p. 189
モデル式10-4を一部改変
19.
こうモデリングする
20.
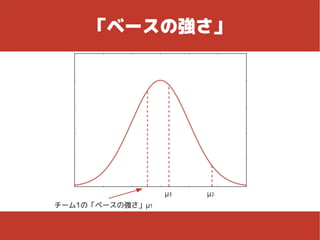
「ベースの強さ」 ● 各チームごとに「ベースの強さ」がある – 「ベースの強さ」はチームごとに異なる ● 「ベースの強さ」は正規分布に従う – 「身長は正規分布する」と似たような感じ チームtの「ベースの強さ」(μt)は平均0、分散σμの正規分布に従う Tはチーム数(今回は12)
22.
パフォーマンス ● 毎試合「ベースの強さ」どおりのパフォーマン スが出せるわけではない ● 試合ごとのパフォーマンスは「ベースの強さ」 を平均とする正規分布に従う g試合目のチームtのパフォーマンスは平均μt(チームtの「ベースの強さ」)、 分散σtの正規分布から生成される Gは試合数(今回は840) σtの分布については識別性の話をしなければならなくなるので ここではスルーさせてください
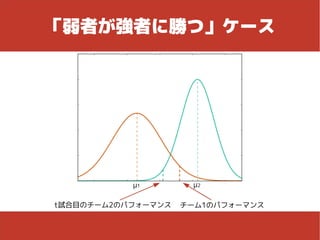
23.
勝敗 ● パフォーマンスが高い方が勝つ – パフォーマンスは確率的に決まるので、たまたま 「調子の悪い日」と「調子の良い日」が重なれば、 弱者が強者に勝つこともある g試合目の勝者(W)のパフォーマンスは、敗者(L)のパフォーマンスを上回っている 引き分けはモデルに組み込むのが大変そうだったので除外しています
25.
再掲 松浦(2016) p. 189
モデル式10-4を一部改変
26.
パラメータを推定する ● 以上のストーリーに沿いモデルを作成 ● 実際の勝敗データで学習し、「ベースの強さ」 のパラメータ(と他のパラメータ)を推定する パラメータの分布についての議論はより高度な知識が必要になるのでここでは割愛し、 事後分布の平均値で点推定しています σtの推定値についても今回の議論の本筋とはあまり関係がないので割愛します
27.
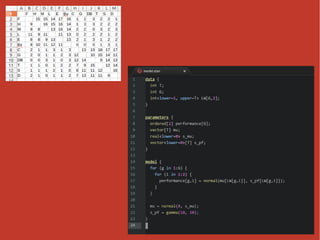
実際にやってみた ● データは手入力 – 12x12のセルを埋めるだけなので ● 前処理やグラフ描画はPython ● パラメータの推定にはStan – ベイズ推定が得意な確率的プログラミング言語 –
PyStanを使ってPythonから扱う ● pandasでごにょごにょしたデータをまんま渡せて便利
29.
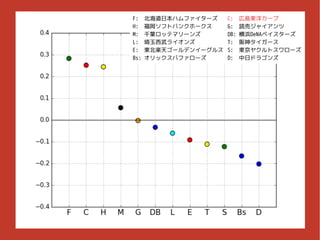
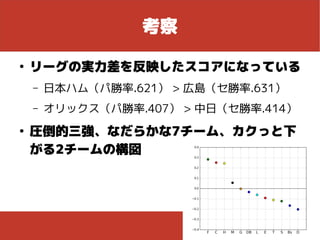
結果
32.
考察 ● リーグの実力差を反映したスコアになっている – 日本ハム(パ勝率.621) >
広島(セ勝率.631) – オリックス(パ勝率.407) > 中日(セ勝率.414)
33.
参考文献 東京大学教養学部統計学教室(1992)『自然科学の統計学』 東京大学出版会 松浦健太郎(2016)『StanとRでベイズ統計モデリング』 共立出版
34.
おしまい
Download















































![[DL輪読会]Deep Learning 第5章 機械学習の基礎](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning5-180601021956-thumbnail.jpg?width=640&height=640&fit=bounds)

























