Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Hisao Soyama
16,268 views
大学生のTwitter利用に関する定量分析―利用目的とサービス設計の関係―
Technology
◦
Read more
11
Save
Share
Embed
Embed presentation
Download
Downloaded 17 times
1
/ 49
2
/ 49
3
/ 49
4
/ 49
5
/ 49
6
/ 49
7
/ 49
8
/ 49
9
/ 49
10
/ 49
11
/ 49
12
/ 49
13
/ 49
14
/ 49
15
/ 49
16
/ 49
17
/ 49
18
/ 49
19
/ 49
20
/ 49
21
/ 49
22
/ 49
23
/ 49
24
/ 49
25
/ 49
26
/ 49
27
/ 49
28
/ 49
29
/ 49
30
/ 49
31
/ 49
32
/ 49
33
/ 49
34
/ 49
35
/ 49
36
/ 49
37
/ 49
38
/ 49
39
/ 49
40
/ 49
41
/ 49
42
/ 49
43
/ 49
44
/ 49
45
/ 49
46
/ 49
47
/ 49
48
/ 49
49
/ 49
More Related Content
PDF
機械学習でお小遣いを稼ぐ! - 本推薦 Twitter bot の紹介 -
by
Masakazu Ishihata
PDF
Pythonで簡単ネットワーク分析
by
antibayesian 俺がS式だ
PDF
言語処理学会へ遊びに行ったよ
by
antibayesian 俺がS式だ
PDF
全文検索入門
by
antibayesian 俺がS式だ
PDF
S10 t1 spc_by_nowfromnow
by
Takeshi Akutsu
PDF
Sapporo20140709
by
Kimikazu Kato
PDF
どたばたかいぎ成果発表
by
Eric Sartre
PPTX
Python による 「スクレイピング & 自然言語処理」入門
by
Tatsuya Tojima
機械学習でお小遣いを稼ぐ! - 本推薦 Twitter bot の紹介 -
by
Masakazu Ishihata
Pythonで簡単ネットワーク分析
by
antibayesian 俺がS式だ
言語処理学会へ遊びに行ったよ
by
antibayesian 俺がS式だ
全文検索入門
by
antibayesian 俺がS式だ
S10 t1 spc_by_nowfromnow
by
Takeshi Akutsu
Sapporo20140709
by
Kimikazu Kato
どたばたかいぎ成果発表
by
Eric Sartre
Python による 「スクレイピング & 自然言語処理」入門
by
Tatsuya Tojima
What's hot
PDF
Lighting talk chainer hands on
by
Ogushi Masaya
PDF
捗るリコメンドシステムの裏事情(ハッカドール)
by
mosa siru
PPTX
Pythonで機械学習を自動化 auto sklearn
by
Yukino Ikegami
PDF
まとめ
by
Takeshi Akutsu
PPTX
データ分析スクリプトのツール化入門 - PyConJP 2016
by
Akinori Kohno
PDF
4コマ漫画 Machine Learning 分析データを集めたかった話
by
esu ji
PDF
「長野で語るStapyのビジョン」
by
Takeshi Akutsu
PDF
S10 t0 orientation
by
Takeshi Akutsu
PDF
私とUnityとLINQと
by
Ryota Murohoshi
PDF
S01 t2 akutsu_my_pythonhistory
by
Takeshi Akutsu
PDF
正しいプログラミング言語の覚え方
by
Kimikazu Kato
PDF
バブみ駆動開発_紬ちゃんデスクトップマスコット
by
temama
PDF
S06 t1 python学習奮闘記#4
by
Takeshi Akutsu
PPT
14対話bot発表資料
by
Keiichirou Miyamoto
PDF
Pythonを使った機械学習の学習
by
Kimikazu Kato
PDF
20110224jggug
by
y torazuka
PDF
Chainerのテスト環境とDockerでのCUDAの利用
by
Yuya Unno
PDF
養成読本と私
by
Kimikazu Kato
PPTX
Python勉強会in 長野 オープニング
by
Yuuki Nakajima
PDF
TensorFlowをざっくりLTしてみた
by
Mitsuki Ogasahara
Lighting talk chainer hands on
by
Ogushi Masaya
捗るリコメンドシステムの裏事情(ハッカドール)
by
mosa siru
Pythonで機械学習を自動化 auto sklearn
by
Yukino Ikegami
まとめ
by
Takeshi Akutsu
データ分析スクリプトのツール化入門 - PyConJP 2016
by
Akinori Kohno
4コマ漫画 Machine Learning 分析データを集めたかった話
by
esu ji
「長野で語るStapyのビジョン」
by
Takeshi Akutsu
S10 t0 orientation
by
Takeshi Akutsu
私とUnityとLINQと
by
Ryota Murohoshi
S01 t2 akutsu_my_pythonhistory
by
Takeshi Akutsu
正しいプログラミング言語の覚え方
by
Kimikazu Kato
バブみ駆動開発_紬ちゃんデスクトップマスコット
by
temama
S06 t1 python学習奮闘記#4
by
Takeshi Akutsu
14対話bot発表資料
by
Keiichirou Miyamoto
Pythonを使った機械学習の学習
by
Kimikazu Kato
20110224jggug
by
y torazuka
Chainerのテスト環境とDockerでのCUDAの利用
by
Yuya Unno
養成読本と私
by
Kimikazu Kato
Python勉強会in 長野 オープニング
by
Yuuki Nakajima
TensorFlowをざっくりLTしてみた
by
Mitsuki Ogasahara
Viewers also liked
PDF
『オープンソースで学ぶ社会ネットワーク分析』1章 イントロダクション
by
Hisao Soyama
PPTX
Importance
by
Naoki Masuda
PDF
階層ベイズでプロ野球各球団の「本当の強さ」を推定してみる
by
Hisao Soyama
PDF
Suicide ideation of individuals in online social networks tokyo webmining
by
Hiroko Onari
PDF
オープニングトーク - 創設の思い・目的・進行方針 -データマイニング+WEB勉強会@東京
by
Koichi Hamada
PDF
本当に知ってる!? リアルなデータ分析の世界~サイカのエンジニアが語る、話題の技術の「いま」と「未来」~
by
Hisao Soyama
PDF
Lightning-Talk: Ramen->Graph->Database, neo4j_fdw
by
Toshi Harada
PDF
GraphX Advent Calendar Day 14
by
鉄平 土佐
PDF
GraphX Advent Calendar Day15
by
鉄平 土佐
PDF
Matrix
by
Hisao Soyama
PDF
『アジャイルデータサイエンス』1章 理論
by
Hisao Soyama
PDF
MongoDBとAjaxで作る解析フロントエンド&GraphDBを用いたソーシャルデータ解析
by
Takahiro Inoue
PDF
『アジャイルデータサイエンス』2章 データ
by
Hisao Soyama
KEY
今日からわかる!ソーシャルグラフ解析
by
Daichi Onodera
PDF
Python twitter data_150709
by
BrainPad Inc.
PPTX
Sna4
by
Yudai Kato
PDF
Neo4j を Javaプログラムから使う
by
Masahiro Satake
PDF
Sna book chapter_5
by
Kenji Koshikawa
PDF
【サンプル】social-inサービス資料
by
AAsolution
PDF
社会ネットワーク分析第7回
by
Satoru Mikami
『オープンソースで学ぶ社会ネットワーク分析』1章 イントロダクション
by
Hisao Soyama
Importance
by
Naoki Masuda
階層ベイズでプロ野球各球団の「本当の強さ」を推定してみる
by
Hisao Soyama
Suicide ideation of individuals in online social networks tokyo webmining
by
Hiroko Onari
オープニングトーク - 創設の思い・目的・進行方針 -データマイニング+WEB勉強会@東京
by
Koichi Hamada
本当に知ってる!? リアルなデータ分析の世界~サイカのエンジニアが語る、話題の技術の「いま」と「未来」~
by
Hisao Soyama
Lightning-Talk: Ramen->Graph->Database, neo4j_fdw
by
Toshi Harada
GraphX Advent Calendar Day 14
by
鉄平 土佐
GraphX Advent Calendar Day15
by
鉄平 土佐
Matrix
by
Hisao Soyama
『アジャイルデータサイエンス』1章 理論
by
Hisao Soyama
MongoDBとAjaxで作る解析フロントエンド&GraphDBを用いたソーシャルデータ解析
by
Takahiro Inoue
『アジャイルデータサイエンス』2章 データ
by
Hisao Soyama
今日からわかる!ソーシャルグラフ解析
by
Daichi Onodera
Python twitter data_150709
by
BrainPad Inc.
Sna4
by
Yudai Kato
Neo4j を Javaプログラムから使う
by
Masahiro Satake
Sna book chapter_5
by
Kenji Koshikawa
【サンプル】social-inサービス資料
by
AAsolution
社会ネットワーク分析第7回
by
Satoru Mikami
Similar to 大学生のTwitter利用に関する定量分析―利用目的とサービス設計の関係―
PDF
Webdbf2012
by
Akihiro Koide
PDF
ad:tech tokyo 2011_NEC BIGLOBE Junko Watanabe
by
Le Grand
PDF
Twitter講習会20100922
by
Shinya ICHINOHE
PDF
NTT研究所におけるYammerの取り組みと、社内Twitterの統計解析
by
Tokoroten Nakayama
PPTX
Information Network or Social Network?
by
Motoka Fukui
PPT
新潟大学「情報リテラシー概論」11-13回
by
Shinya ICHINOHE
PPTX
アカデミックブートキャンプ20120906
by
義広 河野
PPTX
ソーシャルメディアの使い分け~Twitter, Facebook, LinkedIn, Google+, foursquare~
by
義広 河野
PDF
Hadoopエンタープライズソリューションセミナー2012: Hadoop&RabbitMQを利用したTwitter全量リアルタイム解析
by
Kenji Hara
PDF
大規模グラフアルゴリズムの最先端
by
Takuya Akiba
PDF
Hadoop Conference Japan 2013 Winter: "見える"Twitter全量リアルタイム解析 ~Hadoop/RabbitMQ処...
by
Kenji Hara
PDF
ネットワーク科学で挑戦するゲームマーケティング改革
by
RyoAdachi
PDF
Twitterクライアントがこの先生き残るには #twtr_hack
by
Shinichi Sasaki
PPTX
ソーシャルメディア活用によるパーソナルブランディングのススメ(前編)
by
義広 河野
PPTX
ソーシャルメディアの魅力と実践活用20120525
by
義広 河野
PDF
Qualitative researcher in social net age by souich kiyama @twittcher sep. 29,...
by
Shigeru Kishikawa
PDF
ソーシャルメディア、スマートフォン全盛時代に我々は何ができるか
by
ブレークスルーパートナーズ 赤羽雄二
PDF
test
by
Shinya Mori (@mosuke5)
PPT
Niil11
by
Shinya ICHINOHE
PPTX
第1回ソーシャルメディア講義20111129
by
義広 河野
Webdbf2012
by
Akihiro Koide
ad:tech tokyo 2011_NEC BIGLOBE Junko Watanabe
by
Le Grand
Twitter講習会20100922
by
Shinya ICHINOHE
NTT研究所におけるYammerの取り組みと、社内Twitterの統計解析
by
Tokoroten Nakayama
Information Network or Social Network?
by
Motoka Fukui
新潟大学「情報リテラシー概論」11-13回
by
Shinya ICHINOHE
アカデミックブートキャンプ20120906
by
義広 河野
ソーシャルメディアの使い分け~Twitter, Facebook, LinkedIn, Google+, foursquare~
by
義広 河野
Hadoopエンタープライズソリューションセミナー2012: Hadoop&RabbitMQを利用したTwitter全量リアルタイム解析
by
Kenji Hara
大規模グラフアルゴリズムの最先端
by
Takuya Akiba
Hadoop Conference Japan 2013 Winter: "見える"Twitter全量リアルタイム解析 ~Hadoop/RabbitMQ処...
by
Kenji Hara
ネットワーク科学で挑戦するゲームマーケティング改革
by
RyoAdachi
Twitterクライアントがこの先生き残るには #twtr_hack
by
Shinichi Sasaki
ソーシャルメディア活用によるパーソナルブランディングのススメ(前編)
by
義広 河野
ソーシャルメディアの魅力と実践活用20120525
by
義広 河野
Qualitative researcher in social net age by souich kiyama @twittcher sep. 29,...
by
Shigeru Kishikawa
ソーシャルメディア、スマートフォン全盛時代に我々は何ができるか
by
ブレークスルーパートナーズ 赤羽雄二
test
by
Shinya Mori (@mosuke5)
Niil11
by
Shinya ICHINOHE
第1回ソーシャルメディア講義20111129
by
義広 河野
More from Hisao Soyama
PDF
People analyticsと社会ネットワーク分析
by
Hisao Soyama
PDF
コードレビューのアンチパターンについて考えてみた
by
Hisao Soyama
PDF
10分でわかるPythonの開発環境
by
Hisao Soyama
PDF
グラフデータベース「Neo4j」の 導入の導入(続き)-Cypherの基本のキ-
by
Hisao Soyama
PDF
グラフデータベース「Neo4j」の 導入の導入
by
Hisao Soyama
PDF
Pythonによるソーシャルデータ分析―わたしはこうやって修士号を取得しました―
by
Hisao Soyama
People analyticsと社会ネットワーク分析
by
Hisao Soyama
コードレビューのアンチパターンについて考えてみた
by
Hisao Soyama
10分でわかるPythonの開発環境
by
Hisao Soyama
グラフデータベース「Neo4j」の 導入の導入(続き)-Cypherの基本のキ-
by
Hisao Soyama
グラフデータベース「Neo4j」の 導入の導入
by
Hisao Soyama
Pythonによるソーシャルデータ分析―わたしはこうやって修士号を取得しました―
by
Hisao Soyama
大学生のTwitter利用に関する定量分析―利用目的とサービス設計の関係―
1.
このスライドは、 アレな元院生の修士論文の内容を 淡々と述べる物です。 過度な期待はしないでください。
2.
あと、部屋は明るくして、 画面から3メートルは離れて 見やがって下さい。
3.
大学生のTwitter 利用に関する定量分析
―利用目的とサービス設計の関係― Quantitative Analysis of Twitter Usage in University Students: Relationship between Usage Intention and Service Design TokyoWebmining 21st 2012/08/26 @who_you_me 3
4.
アジェンダ 1.研究概要 2.これからTwitter分析をする人へのアドバイス 3.Twitter API v1.1について
4
5.
自己紹介 ●
@who_you_me(冬見/ふゆみ) ● 某ISPの新入社員 ● 今すぐフォローを外すべきPython界のクソ エンジニア ● 学位:修士(社会学) ● Degree: Master of Social Sciences 5
6.
●
勉強会やってます ● 社会ネットワーク分析勉強会(#TokyoSNA) ● 次回は9/7(金) 6
7.
1. 研究概要
7
8.
はじめに ●
社会科学に属する研究です(たぶん) ● 技術的には『集合知プログラミング』レベ ル ● Hard Scienceではないので、いろいろ面倒 くさい – 「お前の研究面白そうだけど、それ何かの役 に立つの?」 – 「それサンプル偏ってるだけだろ」 – 「論理飛躍してるだろ」 8
9.
目的 ●
Twitterは、他のSNSと比べて情報収集や情 報発信によく使わているらしい ● Twitterと他のSNSとの違いって何だろう? – 140字制限 – 人間関係に向きがある! ● フォロー ←→ フレンド ● 「情報収集/発信」と「非対称な関係」 この2つの間に関係ってあるんだろうか? 9
10.
対象 ●
全ユーザーを対象とするのは非現実的 ● とはいえランダムサンプリングも微妙 – ネットワークデータとれない ● 結果の厳密性は落ちるが、あるコミュニ ティに絞るのがいい ● Twitterのボリューム層である、大学生を対 象にしよう! ● というのが表向きの理由 10
11.
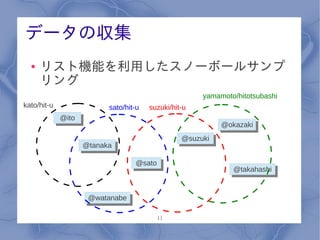
データの収集 ●
リスト機能を利用したスノーボールサンプ リング yamamoto/hitotsubashi kato/hit-u sato/hit-u suzuki/hit-u @ito @ito @okazaki @okazaki @suzuki @suzuki @tanaka @tanaka @sato @sato @takahashi @takahashi @watanabe @watanabe 11
12.
●
毎月一日に上記の方法で、一橋生のアカウ ントを取得 – プロフィール – フォロー、フォロワー – 一ヶ月分のツイート ● 取得期間:2010年12月〜2011年9月 ● 卒業生・他大生も含まれているので、手作 業でクリーニング – アカウント数:1,631 – ツイート数:1,774,684 12
13.
基本統計 13
14.
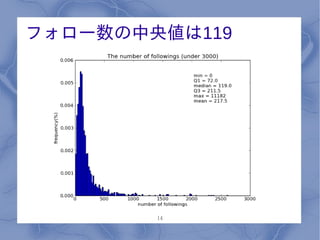
フォロー数の中央値は119
14
15.
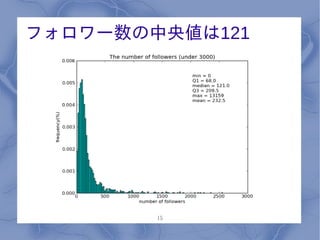
フォロワー数の中央値は121
15
16.
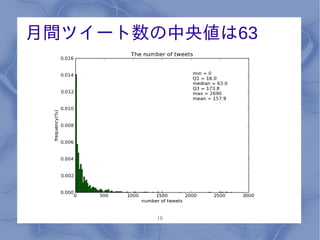
月間ツイート数の中央値は63
16
17.
リプライが4割強、RTは1割弱
17
18.
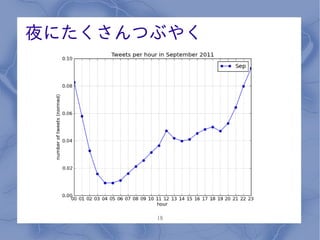
夜にたくさんつぶやく
18
19.
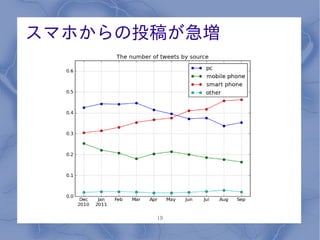
スマホからの投稿が急増
19
20.
ここからが本番! ●
「情報収集・情報発信」と「非対称な関 係」この二つの関係をどう分析する? ● ツイート内容を分析すれば、そのユーザー が情報発信メインか、日常会話メインかが わかるのでは? ● 「非対称な関係」については、片想いとか 片想われとか 20
21.
ツイート内容の分析 ●
MeCabで形態素解析し、ユーザーごとの名 詞使用回数を集計 ● k-means法でクラスタリング ● クラスタごとの特徴語をみる 21
22.
形態素解析 ●
文を単語に分け、品詞情報などのタグを付 与 すもももももももものうち すもももももももものうち すもも 名詞,一般,*,*,*,*,すもも,スモモ,スモモ も 助詞,係助詞,*,*,*,*,も,モ,モ もも 名詞,一般,*,*,*,*,もも,モモ,モモ も 助詞,係助詞,*,*,*,*,も,モ,モ もも 名詞,一般,*,*,*,*,もも,モモ,モモ の 助詞,連体化,*,*,*,*,の,ノ,ノ うち 名詞,非自立,副詞可能,*,*,*,うち,ウチ,ウチ EOS 22
23.
k-means法によるクラスタリング ●
名詞のみを取り出し、ユーザーごとの名詞 使用回数を集計 ● k-means法でクラスタリング – http://d.hatena.ne.jp/nitoyon/20090409/kmeans_visualise 23
24.
クラスタごとの特徴語
24
25.
●
次元縮約も何もやってないけど、意外とう まく分かれたんじゃね? ● 特徴語が日常会話っぽいクラスタはリプラ イ多いし、情報発信っぽいクラスタはRT多 い 25
26.
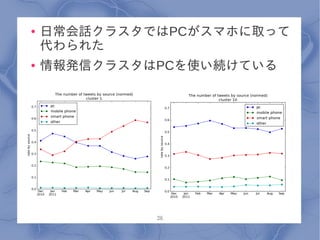
●
日常会話クラスタではPCがスマホに取って 代わられた ● 情報発信クラスタはPCを使い続けている 26
27.
非対称な関係 ●
フォローに占める片想いの割合、フォロ ワーに占める片想われの割合で判断 ● クラスターごとに、「片想い率」「片想わ れ率」の頻度分布をみる 27
28.
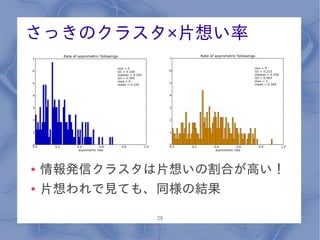
さっきのクラスタ×片想い率 ●
情報発信クラスタは片想いの割合が高い! ● 片想われで見ても、同様の結果 28
29.
結論 ●
Twitterが情報発信・収集によく使われる背 景には「非対称な人間関係」というサービ ス設計上の特徴が影響しているようだ 29
30.
おまけ ●
社会ネットワーク分析勉強会(#TokyoSNA) 主催としてはこれをやらなくては! ● 一橋生どものTwitterネットワークをお絵描 き 30
31.
31
32.
32
33.
2. これからTwitter分析をする人への
アドバイス 33
34.
の名を借りた、ステマタイム!!
34
35.
Pythonとお友達になろう! ●
勉強が捗る – 集合知プログラミング – 入門ソーシャルデータ – 入門自然言語処理 – オープンソースで学ぶ社会ネットワーク分析 これ、ぜーんぶサンプルコードがPython 35
36.
●
豊富なライブラリ群 – NLTK, Numpy/scipy, matplotlib, networkx ● Rに対抗しようとする人達の存在 ● 個人レベルの分析なら、Python一択だね! 36
37.
MongoDBとお友達になろう! ●
Web APIで取ってくるデータって、だいた いJSON ● リレーショナルなDB – 事前に保存するデータ項目決める – テーブルスキーマを定義 – 仕様変わったらテーブル構造変えないと、、 ● スキーマレスなNoSQL – JSONそのまま突っ込むだけ!! 37
38.
サンプリングについて、ちゃんと考えよう ●
厳密性とデータの取りやすさ/分析のしや すさとの兼ね合い 継続的にデータを取ろう! ● 時系列データは貴重 – さっきのスマホの普及とか – ソーシャルネットワークの生成過程とか 38
39.
Twitter様のご機嫌に注意しよう! ●
API叩くと結構な頻度で503エラーを返して くださりやがる ● APIの仕様変更 – ちょくちょくやる上に、予告なし – 2010年8月 Basic認証廃止。OAuthへ移行 – 2012年8月…… 39
40.
3. Twitter API
v1.1について 40
41.
概要 ●
Twitter APIの新バージョン(v1.1)が数週 間以内にリリースされます ● 移行期間は6カ月 – 半年後にはv1.0は使えなくなります ● APIの利用回数制限について、大きな変更 があります 41
42.
変更点のポイント ●
すべてのエンドポイントについて、認証が 必須に ● エンドポイントごとに、利用回数の制限が かかります ● 開発者ルールの変更 42
43.
エンドポイントとは ●
タイムラインを取得したかったらGET statuses/home_timeline – http://api.twitter.com/1/statuses/home_timeline.json ● DM送信したかったらPOST direct_messagaes/new – https://api.twitter.com/1/direct_messages/new.json ● こうした、APIの各機能それぞれのURLの ことをエンドポイントと言います 43
44.
認証が必須に ●
今までは一部のエンドポイントは認証なし で使えたのが、全て必須になる – bot, スクレイピング対策 ● 大半の人は元から全て認証してただろうか ら、影響なさそう ● Search APIも認証必須になるのはむしろ嬉 しい – 今まではIP単位で回数制限かかってたので 44
45.
利用回数制限の変化 ●
全てのエンドポイント合計して、1時間350 アクセスだったのが、エンドポイントごと に別個で利用回数制限がかかるようになる – 1時間60アクセス – タイムライン/プロフィールの取得、ユー ザー検索については、1時間720アクセス 45
46.
●
どちらに転ぶか微妙、、、 – どんな情報を取得したいかによる ● でも、データ取るときって普通1つのエンド ポイント叩きまくるような、、、 ● Twitter社の思惑を考えると、今回の変更で APIへの負荷は減るに決まってるから得はし ないような、、 46
47.
開発者ルールの変更 ●
アプリ開発者に向けた話なので、我々には あまり関係ないか ● 要はサードパーティのクライアントアプリ を潰したいらしい 47
48.
まとめ ●
リリースされてみないことにはわからん \(^o^)/ ● ただし、Twitterが今後目指す方向性が見え てきたような – すべてのtwitter.com内で完結させたい – 「Twitterでできること」をTwitter社が完全に コントロールしたい 個人的にはこれは、うーん、、、 48
49.
以上、ご清聴 ありがとうございました!
Download