More Related Content

PDF
Pythonによるソーシャルデータ分析―わたしはこうやって修士号を取得しました― 
PDF

PDF
(道具としての)データサイエンティストのつかい方 
PDF
ロジスティック回帰の考え方・使い方 - TokyoR #33 
PDF

PPTX
人工知能の概論の概論と�セキュリティへの応用(的な~(改) 
PPTX

PDF
What's hot

PDF

PDF

PDF
ggplot2によるグラフ化@HijiyamaR#2 
PDF

PDF
Twitter分析のためのリアルタイム分析基盤@第4回Twitter研究会 
PDF
Jubatus: 分散協調をキーとした大規模リアルタイム機械学習プラットフォーム 
PDF

PDF

PDF
Randomforestで高次元の変数重要度を見る #japanr LT 
PDF

PDF
企業における自然言語処理技術の活用の現場(情報処理学会東海支部主催講演会@名古屋大学) 
PPTX
StanとRでベイズ統計モデリング読書会(Osaka.stan) 第6章 
PDF
Jubatusの紹介@第6回さくさくテキストマイニング 
PPTX

PDF

PDF
アルゴリズムイントロダクション 14章「データ構造の補強」解説 
PDF

PPTX

PDF

PDF
Similar to コース導入講義(荒木)

PDF

PDF

PDF
10分で分かるr言語入門ver2.9 14 0920 
PDF

PDF
10分で分かるr言語入門ver2.10 14 1101 
PDF

PPT
12-11-30 Kashiwa.R #5 初めてのR Rを始める前に知っておきたい10のこと 
PDF

PDF

PDF

PDF

PDF

PPTX
全部Excelだけで実現しようとして後悔するデータ分析 2nd Edition 
PDF

PPTX

PDF
外国語教育メディア学会第54回全国研究大会ワークショップ「Rによる外国語教育データの分析と可視化の基本」 
PDF
![[データマイニング+WEB勉強会][R勉強会] はじめてでもわかる 統計解析・データマイニング R言語入門](https://cdn.slidesharecdn.com/ss_thumbnails/rlecturehamada100213-100216161757-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[データマイニング+WEB勉強会][R勉強会] はじめてでもわかる 統計解析・データマイニング R言語入門 
PPT

PDF
コース導入講義(荒木)
- 1.
- 2.
- 3.
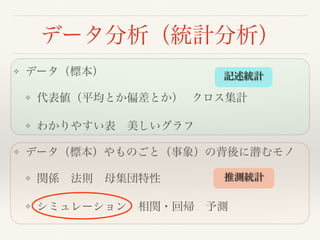
R, Python :データ分析の主流言語
❖ R + Python : データサイエンティスト の最低要件
❖ いま、ビッグデータ がブーム
❖ 従来の(伝統的な)データ処理/分析手法ではうまくいかない
→ より高度なICT環境とツールが必要(分散処理、Non-SQL・・・)
→ データサイエンス(データサイエンティスト)
データサイエンスを実践するヒト
「21世紀で最もセクシーな職業」
3V : Volume(量、とてつもなくデカい)
Velocity(速度、どんどん更新されていく)
Variety(多様、いろんなカタチ)
- 4.
- 5.
- 6.
ICT高度化の(データ分析への)恩恵
❖ 「よりカンタンに・より効率的に」「フリー free(自由、無料)」
❖【オープンデータ】公開の世界的な広がり
❖ 【ライブラリ(道具箱)】の充実(オープンソース、WebAPI)
❖ R の成熟, Python の勃興
❖ 可視化(見える化)の高度化 美しく精巧なグラフ
❖ 高度な分析もより容易に
❖ 積極的に活用しない手はない!
→ プログラミングの素養(基本作法)が必要
→ R ならカンタン、すぐにでも可
❖ Python ( OOP ) の修得には多少の時間がかかるが、得るモノは大きい。
実例 (Motion Chart) を見ましょう
http://rio.andrew.ac.jp/araki/gVisWB.html
( Google chart API + World Bank API ← R )
- 7.
Motion Chart
library(WDI)
inds <-c('SP.DYN.TFRT.IN','SP.DYN.LE00.IN',
'SP.POP.TOTL','NY.GDP.PCAP.CD', 'SE.ADT.1524.LT.FE.ZS')
indnams <- c(“fertility.rate", “life.expectancy",
"population","GDP.per.capita.Current.USD",
"15.to.25.yr.female.literacy")
wdiData <- WDI(country="all",
indicator=inds,start=1960,end=format(Sys.Date(),"%Y"),extra=TRUE)
colnum <- match(inds, names(wdiData))
names(wdiData)[colnum] <- indnams
library(googleVis)
WorldBank <- droplevels(subset(wdiData, !region %in% "Aggregates"))
M <- gvisMotionChart(WorldBank,idvar="country",timevar="year",
xvar="life.expectancy",yvar="fertility.rate",
colorvar="region",sizevar="population",
options=list(width=700, height=600),chartid="WorldBank")
plot(M)
World Bank からデータ取得
Google Visualisation API を呼び出す
- 8.
- 9.
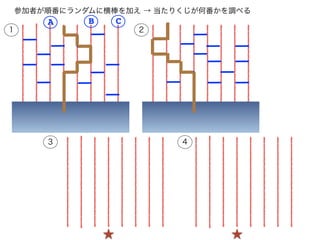
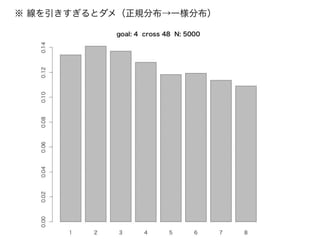
あみだくじ
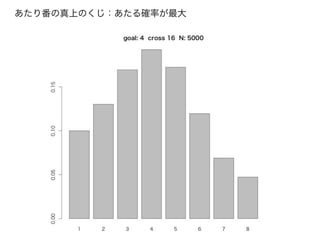
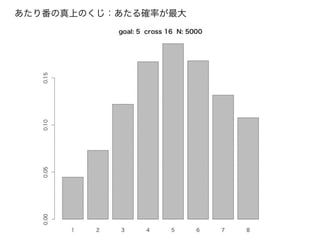
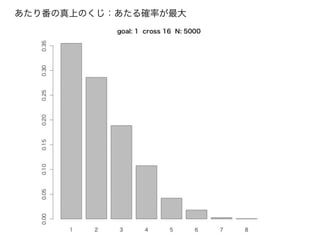
シミュレーションで、あみだくじの「必勝法」を知る
amidakuji <- function(ninzu=8,senbiki=2,goal=0){
# ninzu: あみだくじに参加する人数(=縦線の数)
# senbiki: 横棒(横移動の線)を一人何本引けるか
# goal: 終点のあたり番(0 ならランダムに決める)
sen = ninzu; dan = ninzu*2
x = matrix(0,nrow=dan,ncol=sen) # あみだくじの作成
k = 0; step = sen -1
while(k < ninzu*senbiki) {
i = sample(dan,size=1) ; j = sample(step,size=1)
if( x[i,j]==0 && x[i,j+1]==0 ) { x[i,j]=1; x[i,j+1]=-1; k = k+1 }
}
if(goal==0) goal=sample(sen,size=1) # 終点のあたり番(0ならランダムに)
atari = goal # あたりくじを終点から逆にたどっていく
for( i in dan:1) atari = atari + x[i,atari]
return(atari)
}
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
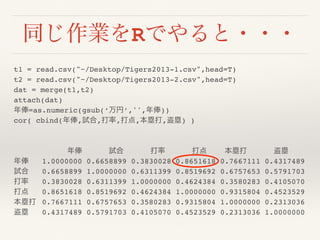
同じ作業をRでやると・・・
t1 = read.csv("~/Desktop/Tigers2013-1.csv",head=T)
t2= read.csv("~/Desktop/Tigers2013-2.csv",head=T)
dat = merge(t1,t2)
attach(dat)
年俸=as.numeric(gsub(‘万円’,'',年俸))
cor( cbind(年俸,試合,打率,打点,本塁打,盗塁) )
年俸 試合 打率 打点 本塁打 盗塁
年俸 1.0000000 0.6658899 0.3830028 0.8651618 0.7667111 0.4317489
試合 0.6658899 1.0000000 0.6311399 0.8519692 0.6757653 0.5791703
打率 0.3830028 0.6311399 1.0000000 0.4624384 0.3580283 0.4105070
打点 0.8651618 0.8519692 0.4624384 1.0000000 0.9315804 0.4523529
本塁打 0.7667111 0.6757653 0.3580283 0.9315804 1.0000000 0.2313036
盗塁 0.4317489 0.5791703 0.4105070 0.4523529 0.2313036 1.0000000
- 20.
- 21.
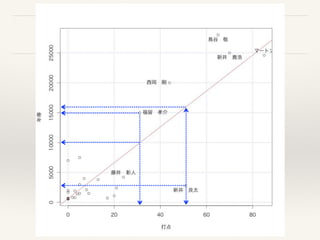
さらに プロ野球の分析 R
❖選手(打者選手)の年俸と打点の関係式を求めてみよう。
summary( lm(年俸~1+打点) )
❖ 打点を1点増やすと、年俸はどれくらい上がるか?
❖ 一億円プレーヤになるためには、打点は何点必要か?
❖ 給料もらいすぎの選手、給料が少なすぎる選手は誰か?
plot(打点,年俸)
abline(633.77,299.85,col=“red”)
identify(打点,年俸,選手名)
年俸 = 633.77 + 299.85 打点
(9.129)
R2 = 0.7485
299.85万円
10000=633.77+299.85*打点 " 打点=(10000-633.77)/299.85 = 31.3
- 23.





![Motion Chart
library(WDI)
inds <- c('SP.DYN.TFRT.IN','SP.DYN.LE00.IN',
'SP.POP.TOTL','NY.GDP.PCAP.CD', 'SE.ADT.1524.LT.FE.ZS')
indnams <- c(“fertility.rate", “life.expectancy",
"population","GDP.per.capita.Current.USD",
"15.to.25.yr.female.literacy")
wdiData <- WDI(country="all",
indicator=inds,start=1960,end=format(Sys.Date(),"%Y"),extra=TRUE)
colnum <- match(inds, names(wdiData))
names(wdiData)[colnum] <- indnams
library(googleVis)
WorldBank <- droplevels(subset(wdiData, !region %in% "Aggregates"))
M <- gvisMotionChart(WorldBank,idvar="country",timevar="year",
xvar="life.expectancy",yvar="fertility.rate",
colorvar="region",sizevar="population",
options=list(width=700, height=600),chartid="WorldBank")
plot(M)
World Bank からデータ取得
Google Visualisation API を呼び出す](https://image.slidesharecdn.com/random-150609134712-lva1-app6891/85/slide-7-320.jpg)
![あみだくじ
シミュレーションで、あみだくじの「必勝法」を知る
amidakuji <- function(ninzu=8,senbiki=2,goal=0) {
# ninzu: あみだくじに参加する人数(=縦線の数)
# senbiki: 横棒(横移動の線)を一人何本引けるか
# goal: 終点のあたり番(0 ならランダムに決める)
sen = ninzu; dan = ninzu*2
x = matrix(0,nrow=dan,ncol=sen) # あみだくじの作成
k = 0; step = sen -1
while(k < ninzu*senbiki) {
i = sample(dan,size=1) ; j = sample(step,size=1)
if( x[i,j]==0 && x[i,j+1]==0 ) { x[i,j]=1; x[i,j+1]=-1; k = k+1 }
}
if(goal==0) goal=sample(sen,size=1) # 終点のあたり番(0ならランダムに)
atari = goal # あたりくじを終点から逆にたどっていく
for( i in dan:1) atari = atari + x[i,atari]
return(atari)
}](https://image.slidesharecdn.com/random-150609134712-lva1-app6891/85/slide-9-320.jpg)