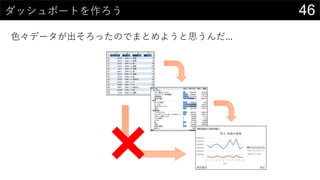
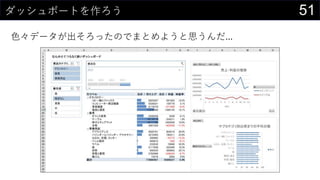
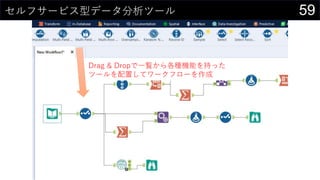
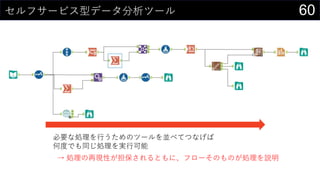
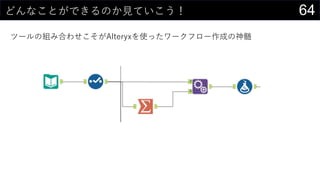
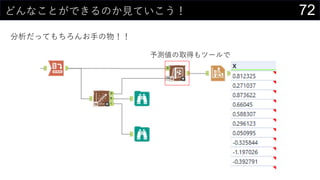
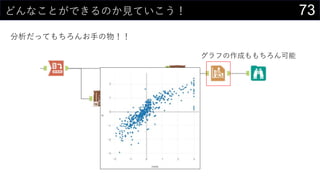
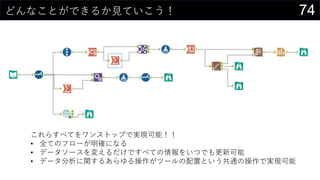
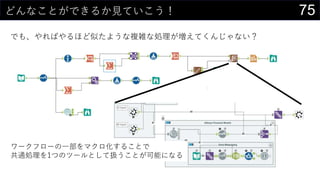
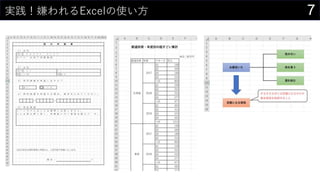
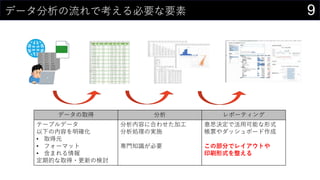
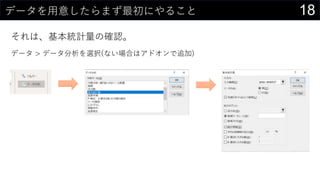
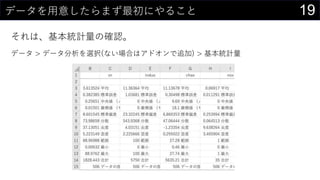
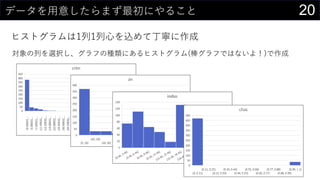
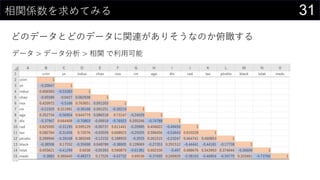
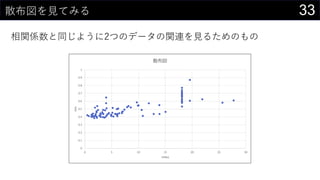
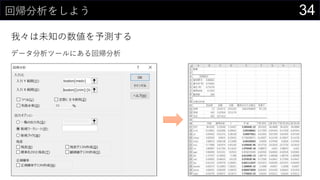
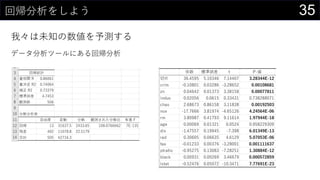
21データを用意したらまず最初にやること
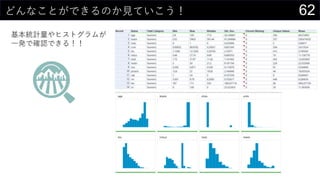
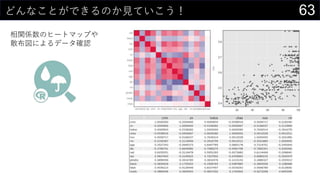
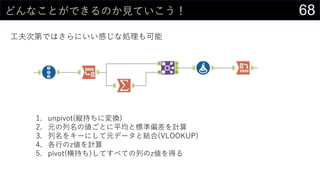
ヒストグラムは1列1列心を込めて丁寧に作成
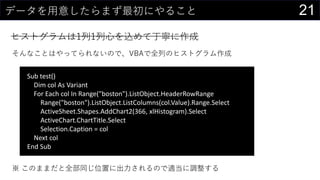
そんなことはやってられないので、VBAで全列のヒストグラム作成
Sub test()
Dim colAs Variant
For Each col In Range("boston").ListObject.HeaderRowRange
Range("boston").ListObject.ListColumns(col.Value).Range.Select
ActiveSheet.Shapes.AddChart2(366, xlHistogram).Select
ActiveChart.ChartTitle.Select
Selection.Caption = col
Next col
End Sub
※ このままだと全部同じ位置に出力されるので適当に調整する






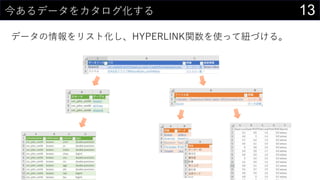
![14今あるデータをカタログ化する
データの情報をリスト化し、HYPERLINK関数を使って紐づける。
HYPERLINK(“https://dev.classmethod.jp/”, “Developers.IO”)
HYPERLINK(“Z:analysisdata”, “データフォルダ”)
HYPERLINK(“[iris.xlsx]iris!A1”, “irisデータセット”)](https://image.slidesharecdn.com/devio2019sapporo-191019074137/85/Excel-14-320.jpg)
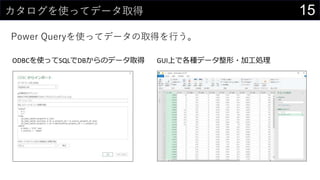
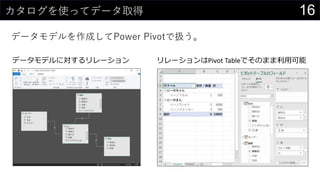

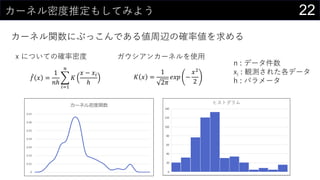
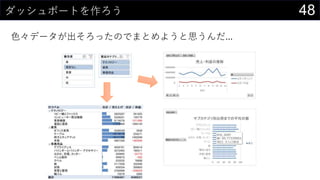
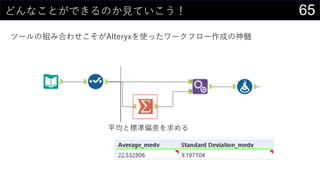
![23カーネル密度推定もしてみよう
カーネル関数にぶっこんである値周辺の確率値を求める
取りうるxの範囲をデータから決める
• 最大値 : MAX(boston[medv])
• 最小値 : MIN(boston[medv])
• データ件数 : COUNT(boston[medv])
• ついでにパラメータhもセルに入れておく
編集 > フィル > 連続データの作成 でmin/maxを参照にxの値を生成する
• 今回は0~60までを0.1刻みで生成](https://image.slidesharecdn.com/devio2019sapporo-191019074137/85/Excel-23-320.jpg)


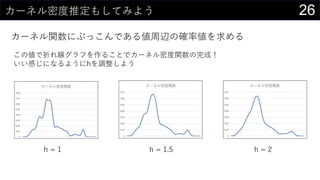
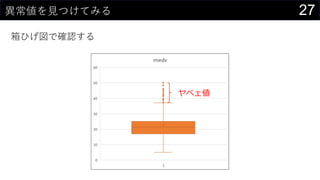
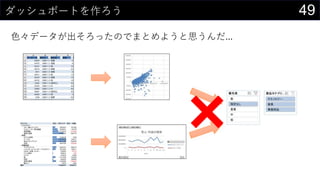
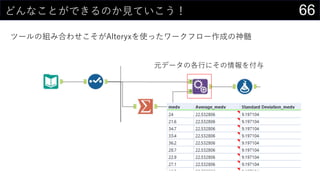
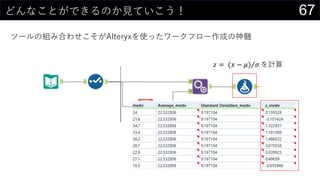
![28異常値を見つけてみる
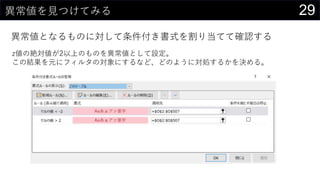
z値を計算する
• 𝑧 = (𝑥 − 𝜇) 𝜎
• 平均を計算
• Q2セル : AVERAGE(boston[medv])
• 標準偏差を計算
• Q3セル : STDEV.S(boston[medv])
• 各値のz値を計算する
• ([@medv] - $Q$2) / $Q$3
• まとめて計算しちゃうことも可能
• ([@medv] - AVERAGE([medv])) / STDEV.S([medv])
テーブルの列名で範囲を指定
この列に追加](https://image.slidesharecdn.com/devio2019sapporo-191019074137/85/Excel-28-320.jpg)



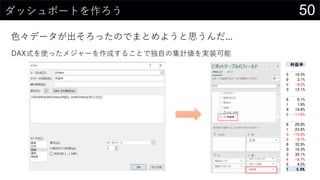
![41ロジスティック回帰もしよう
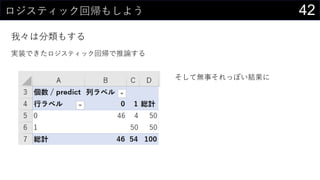
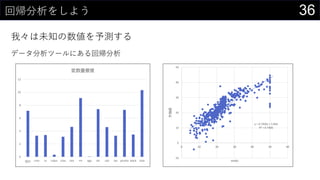
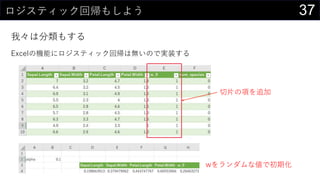
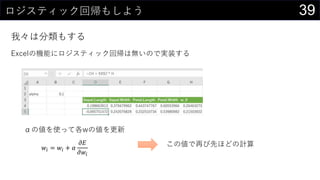
我々は分類もする
実装できたロジスティック回帰で推論する
• {=1 / (1 + EXP(-MMULT(iris[@[Sepal.Length]:[w_0]], TRANSPOSE(Sheet1!$D$300:$H$300))))}
• =IF([@predict] > 0.5, 1, 0)](https://image.slidesharecdn.com/devio2019sapporo-191019074137/85/Excel-41-320.jpg)