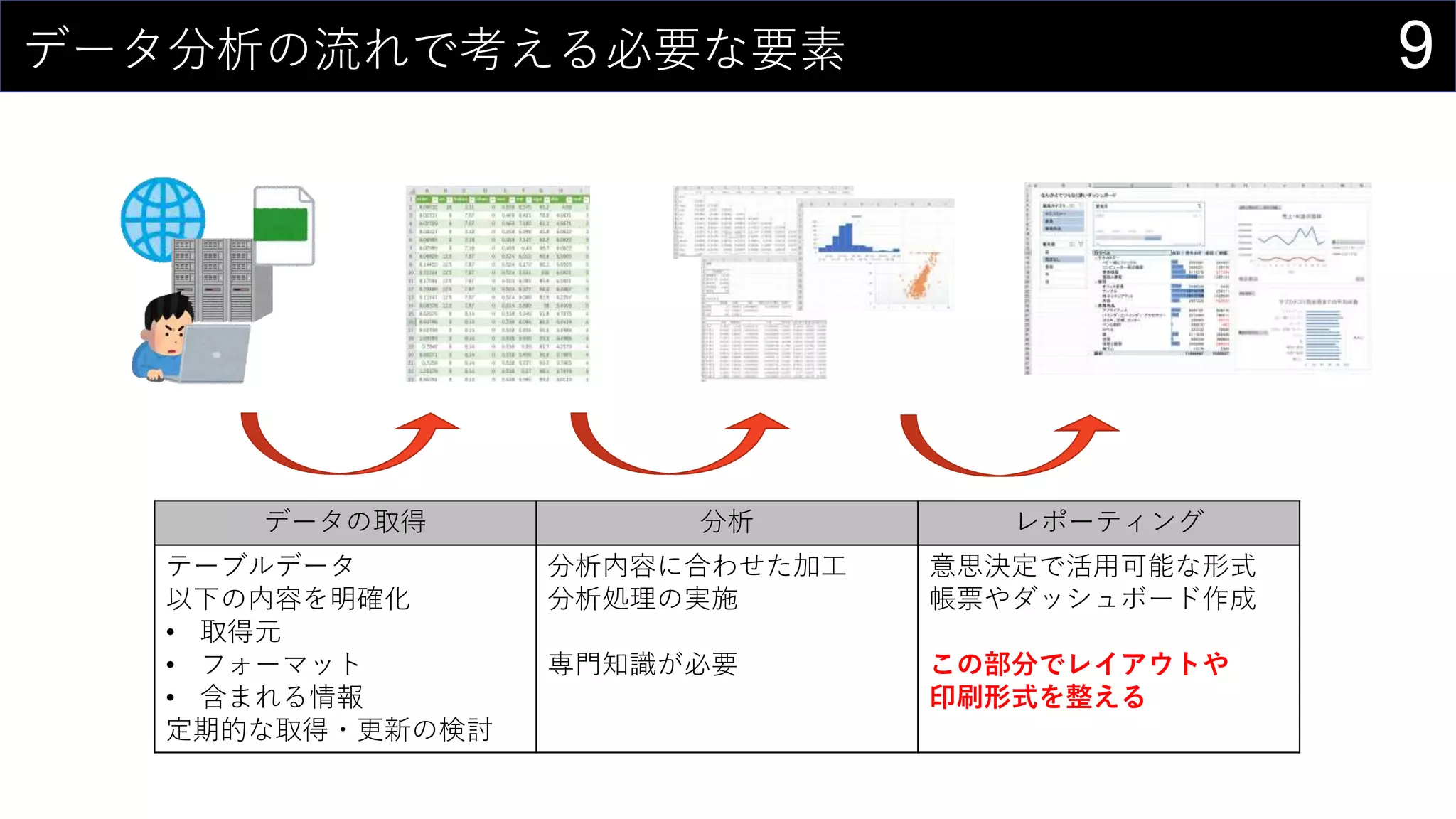
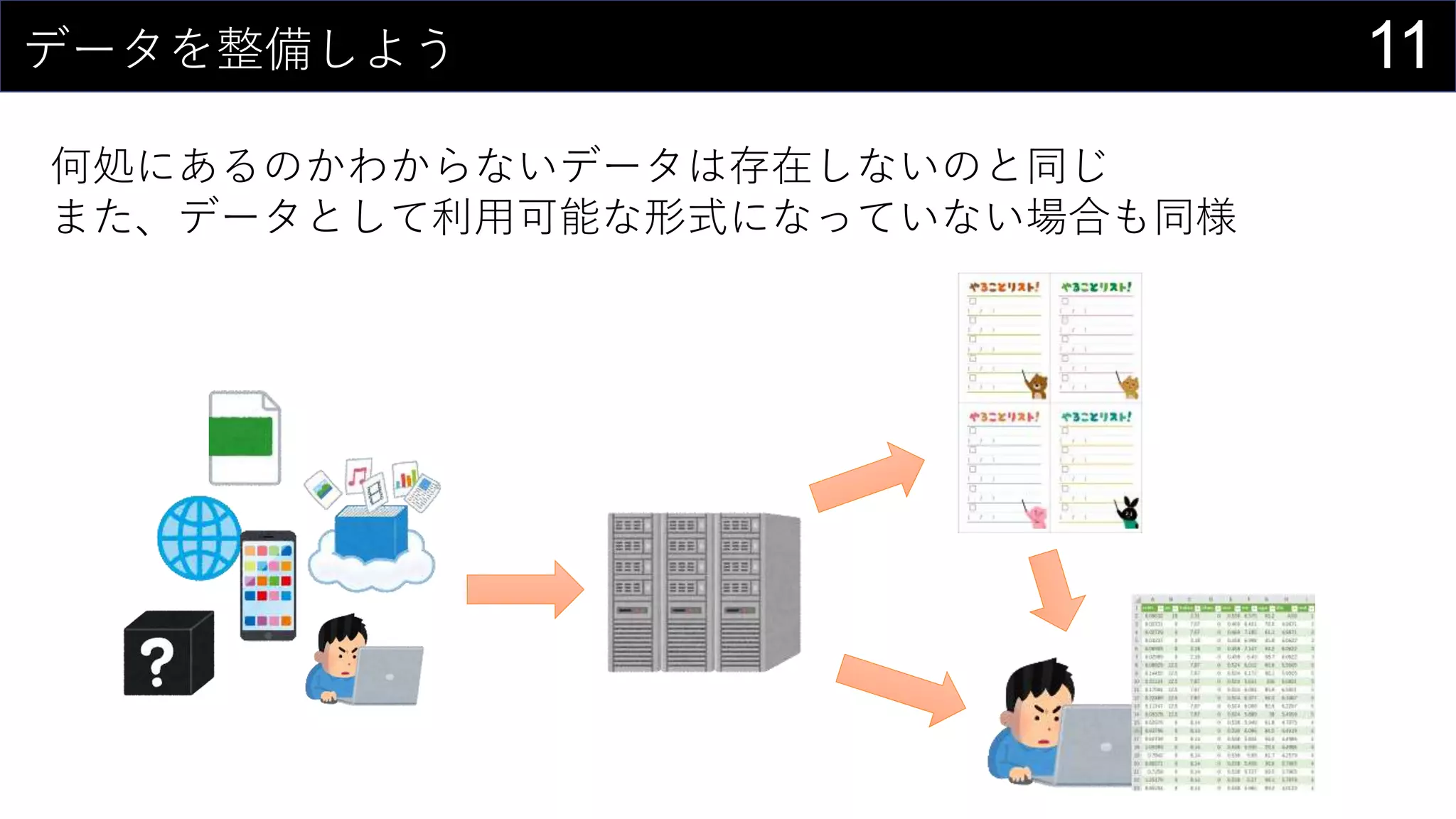
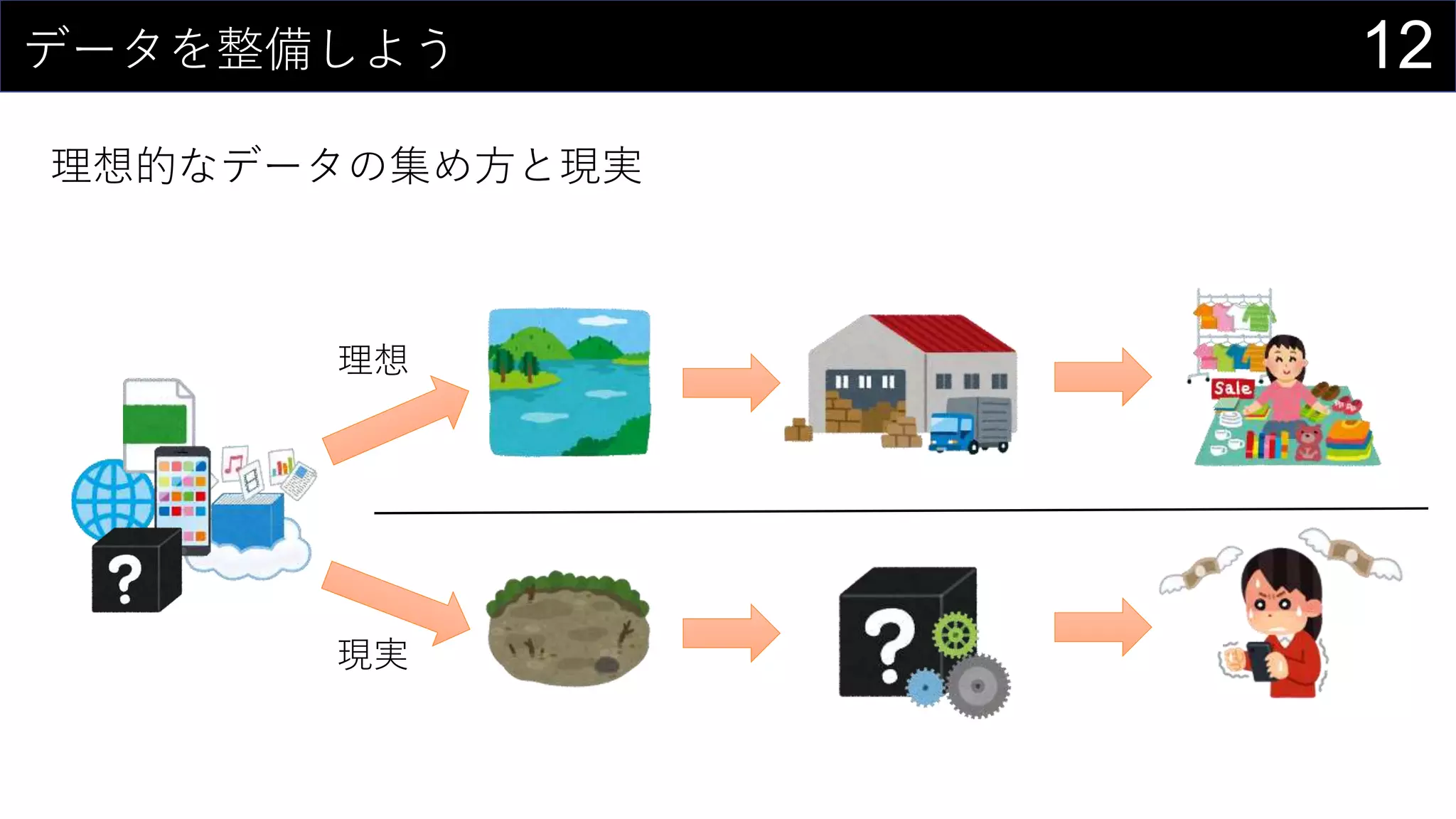
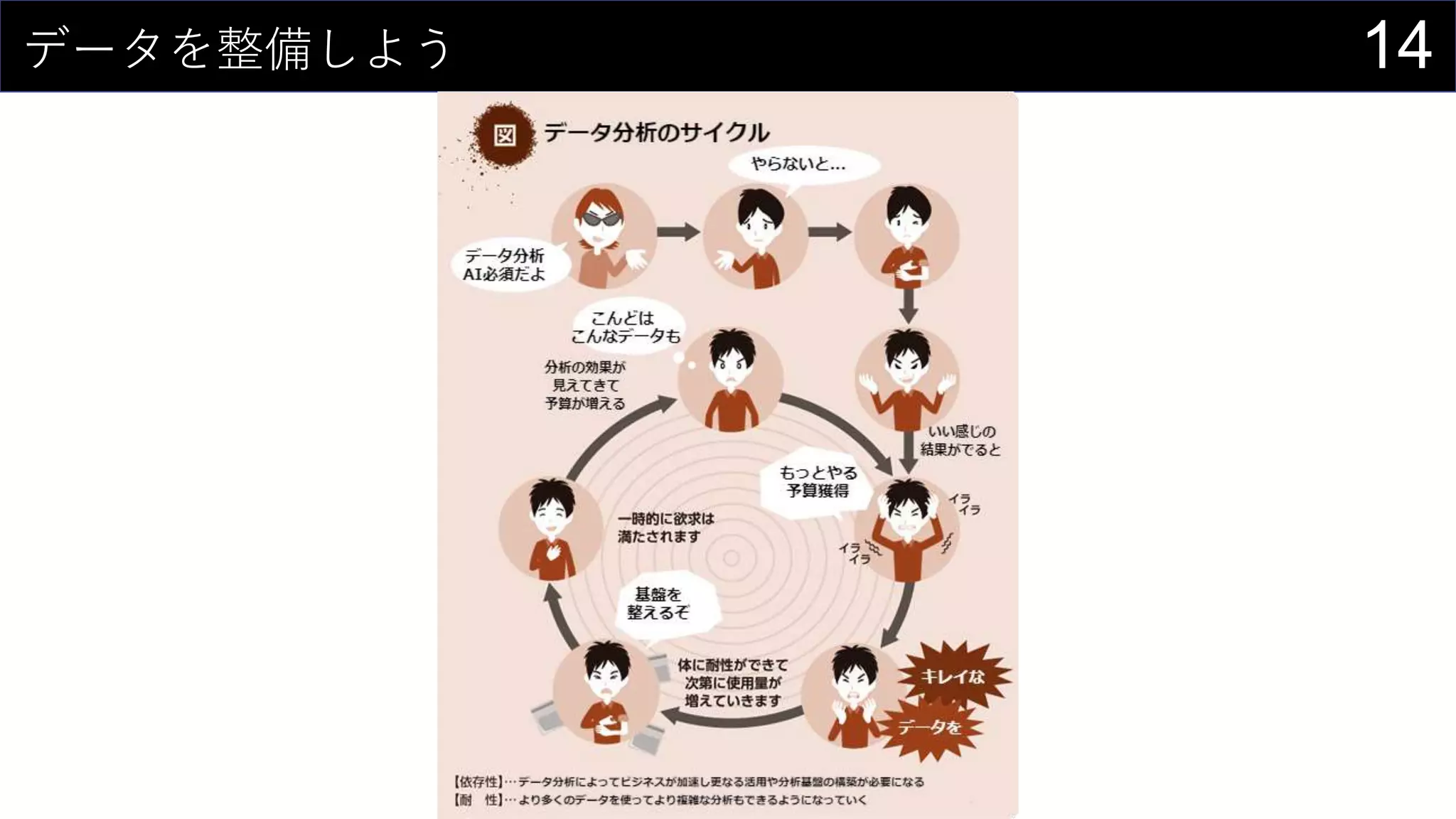
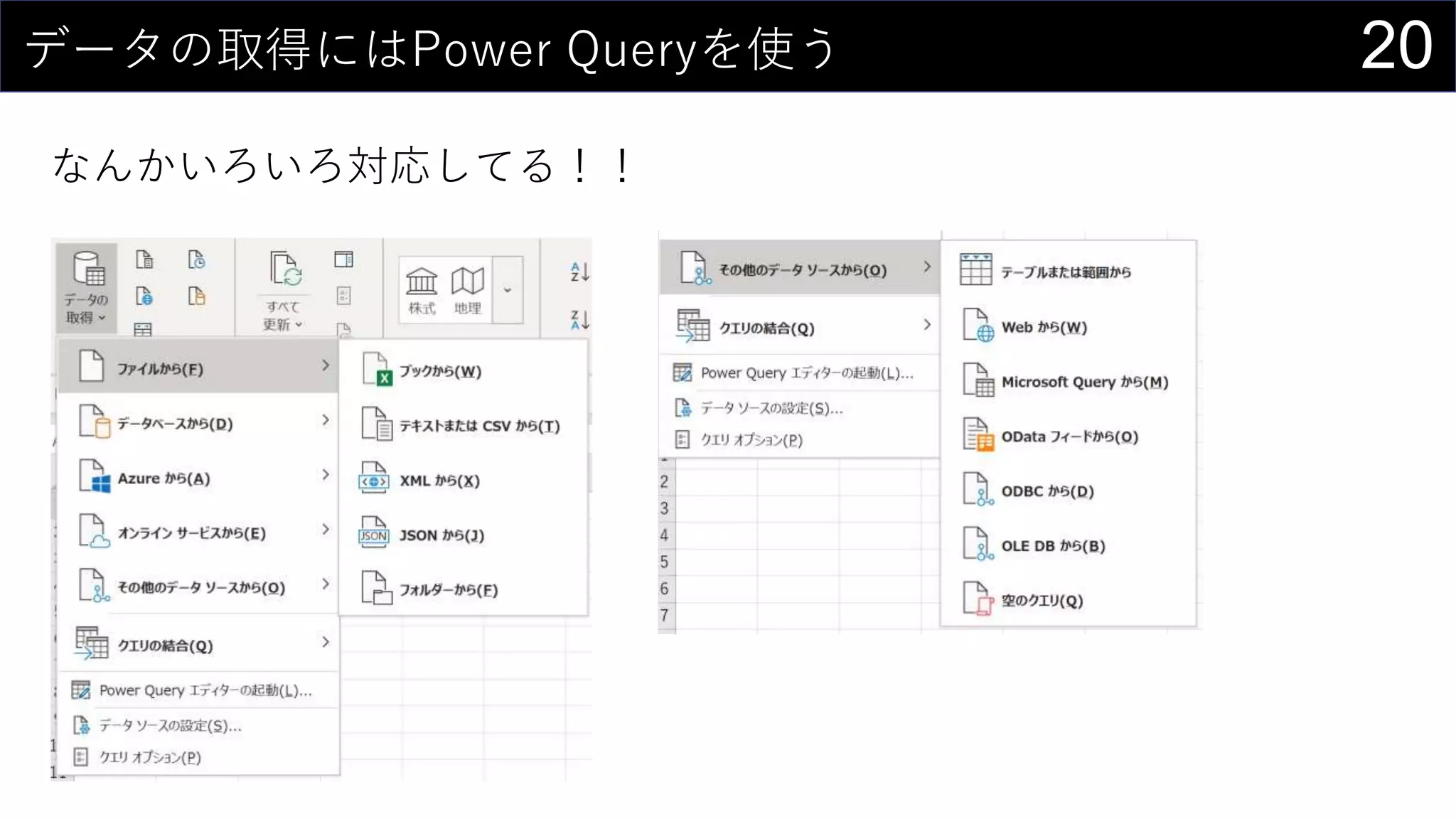
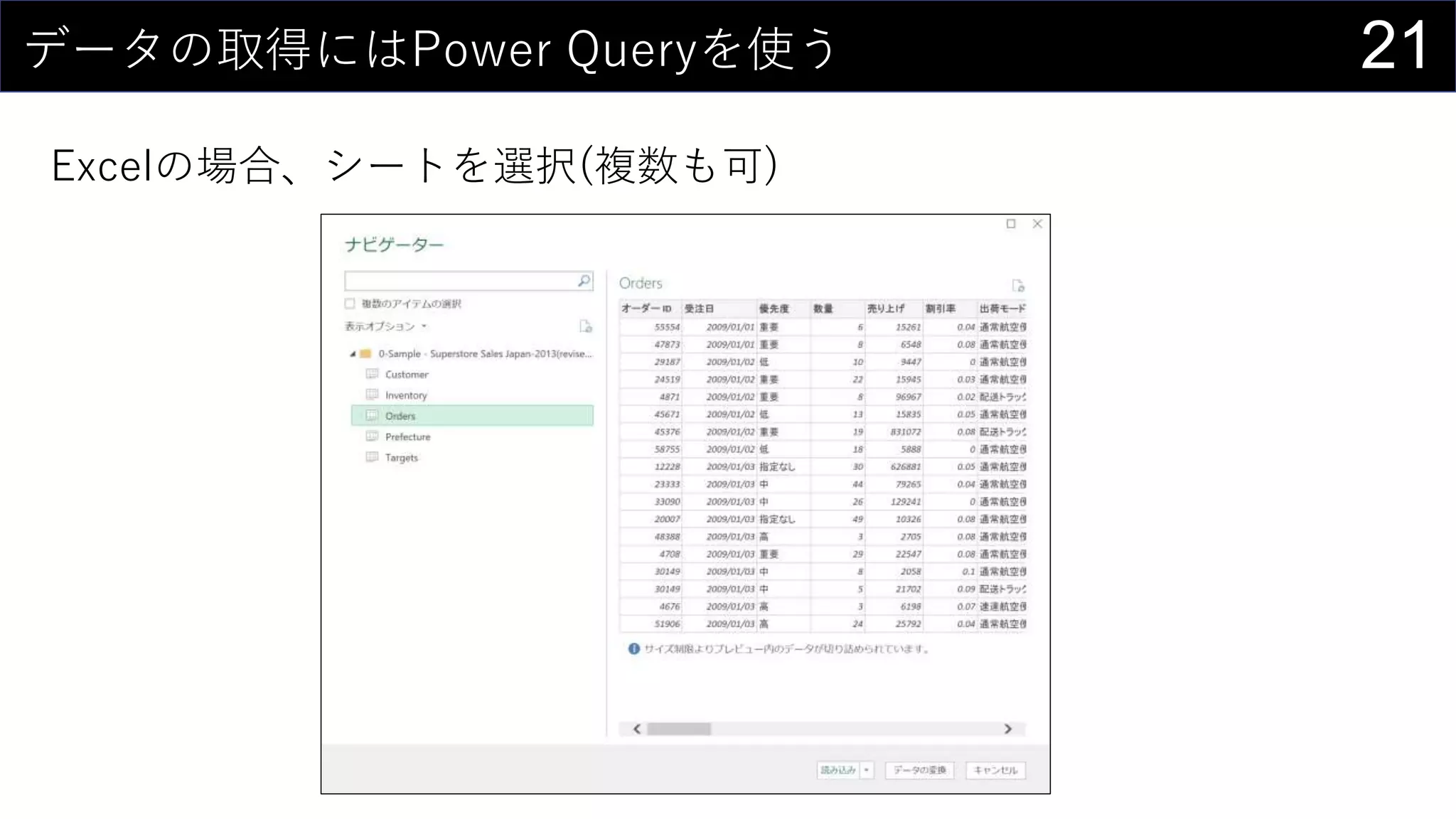
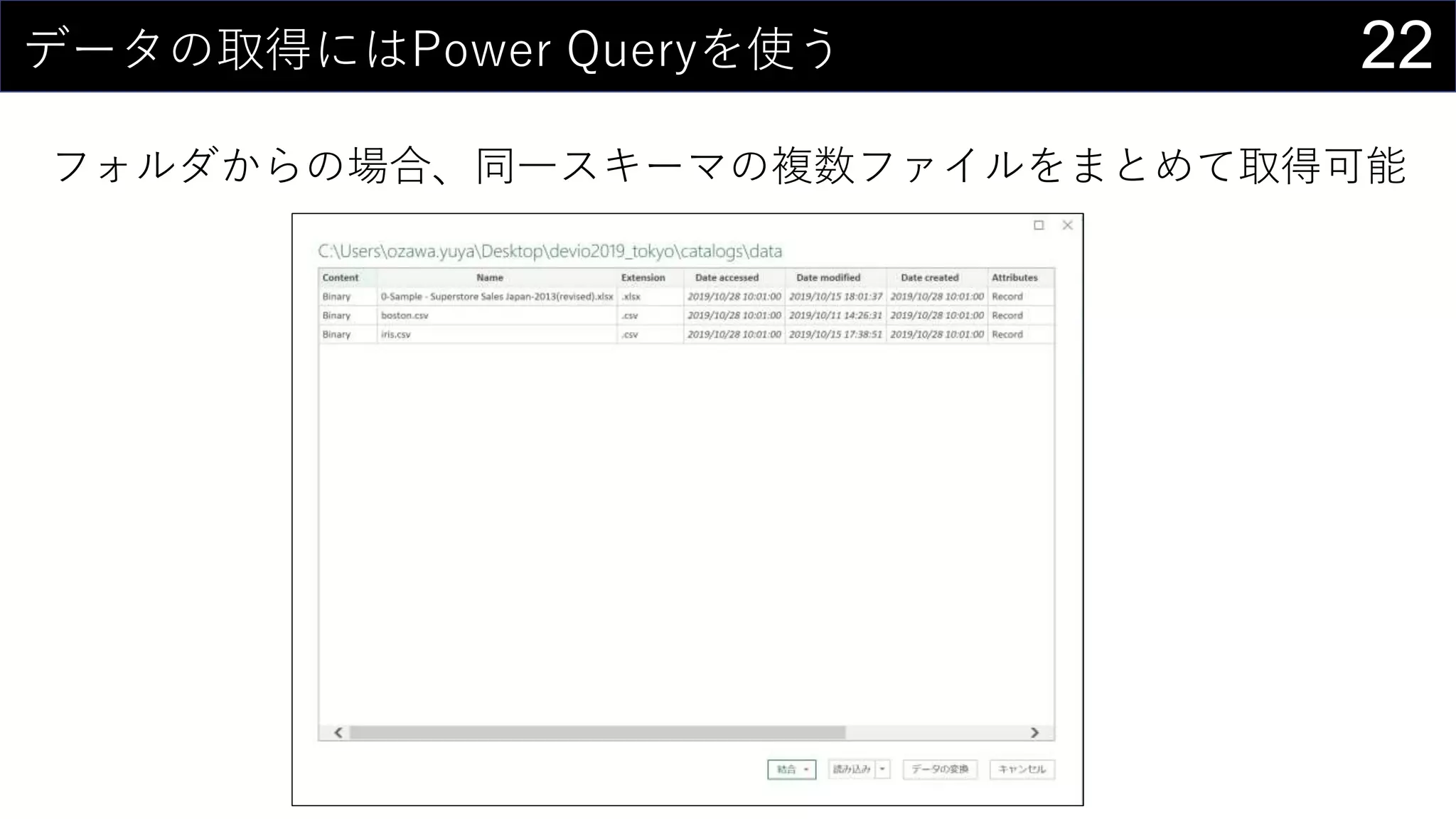
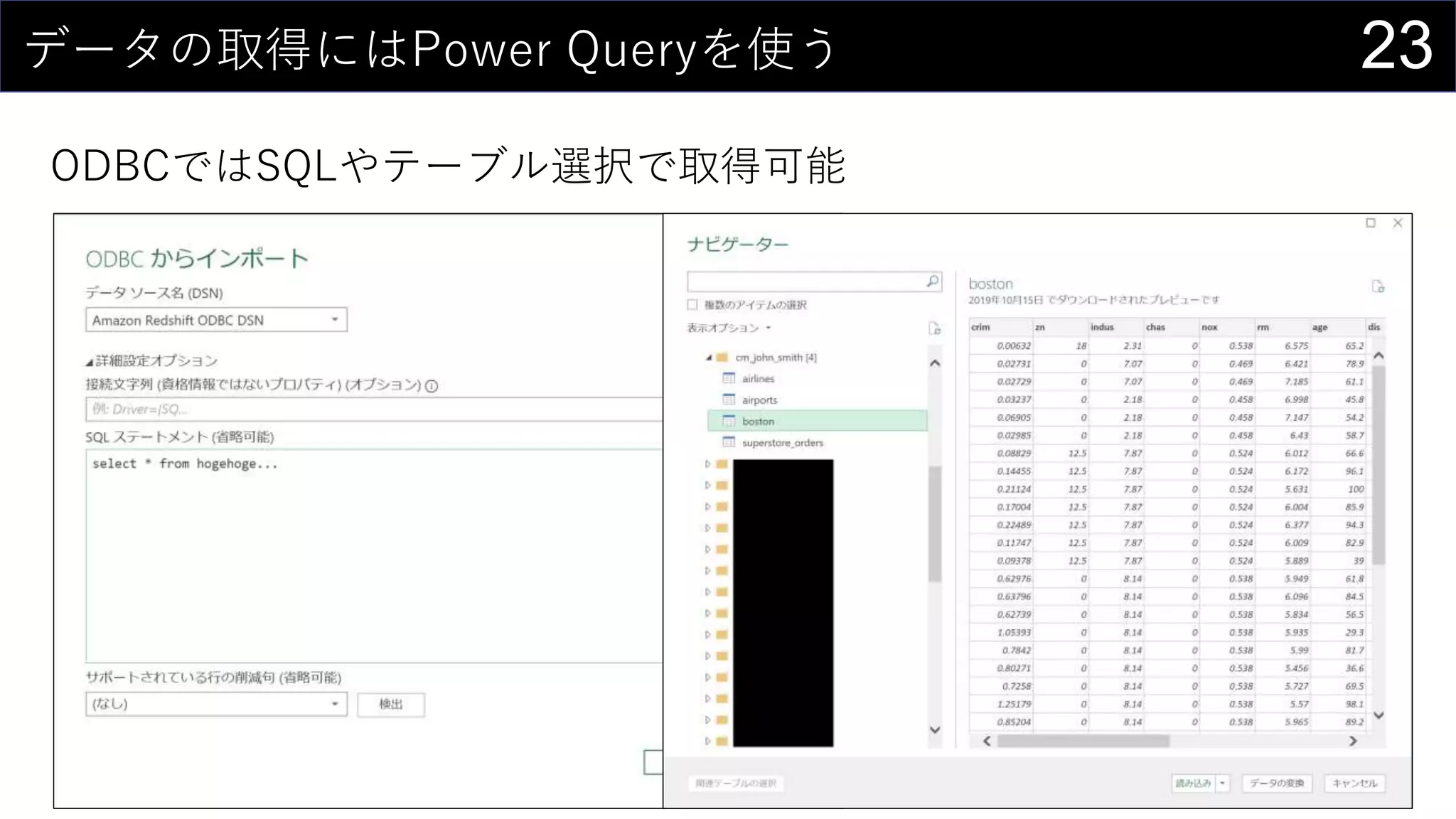
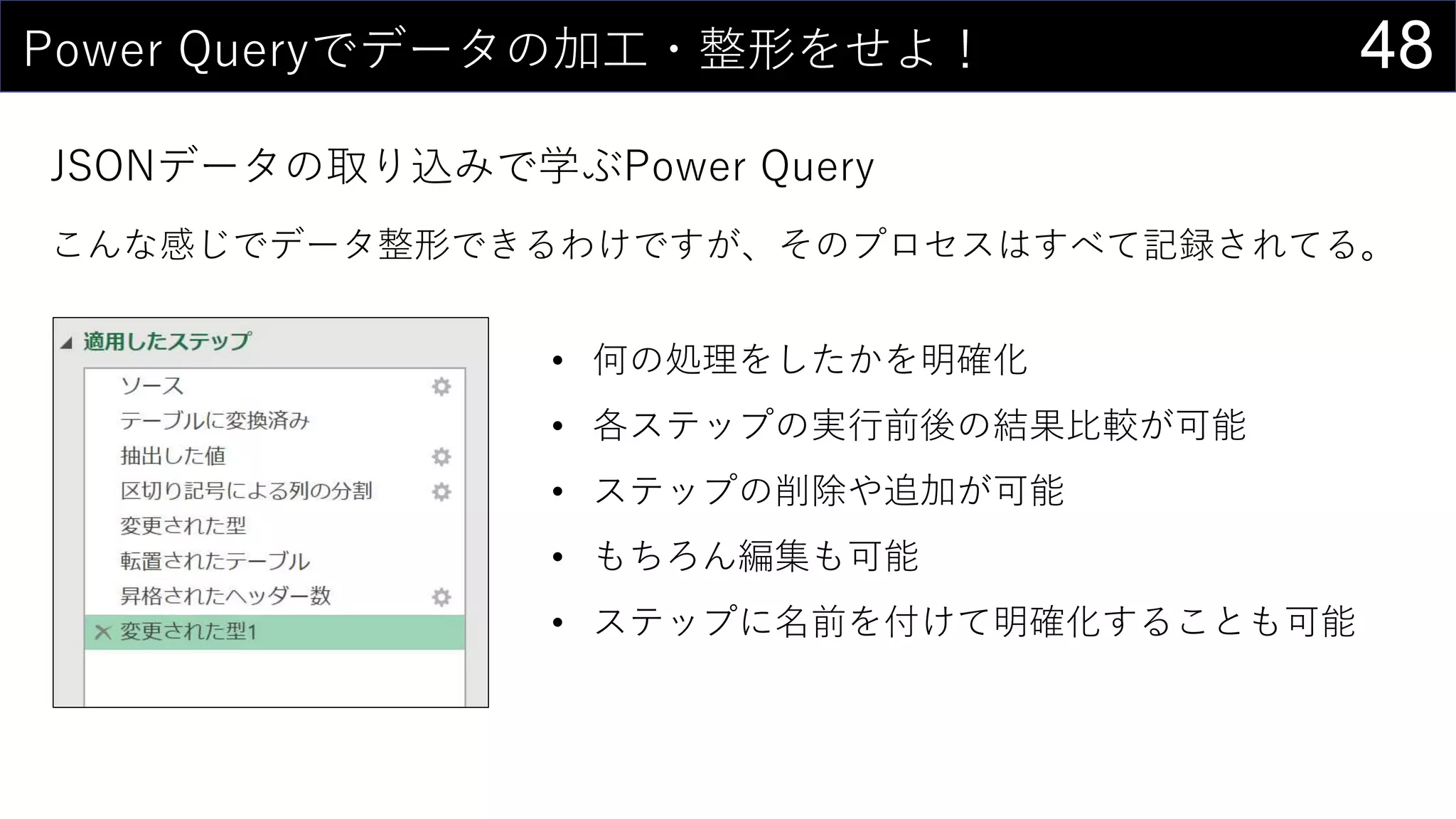
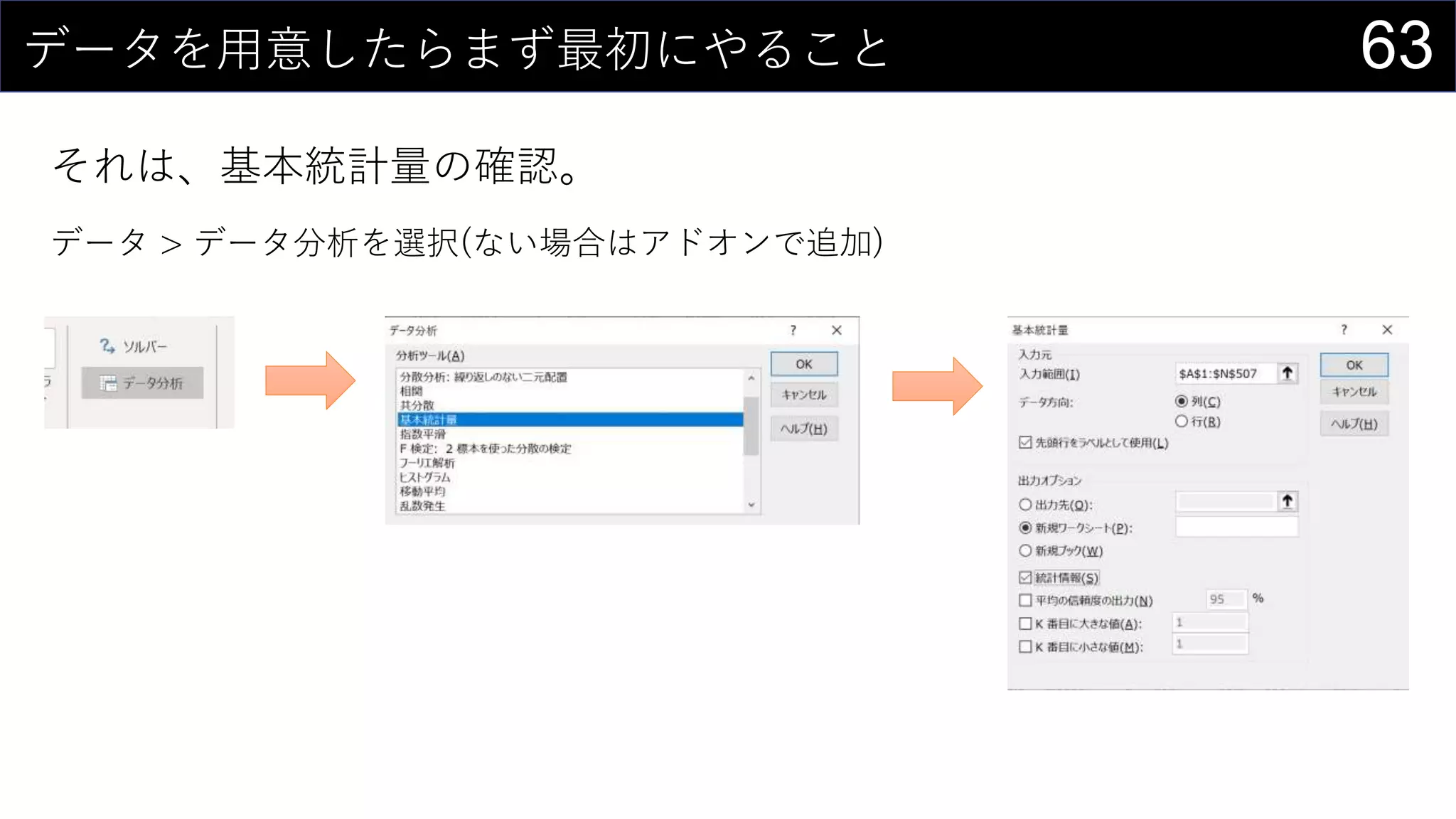
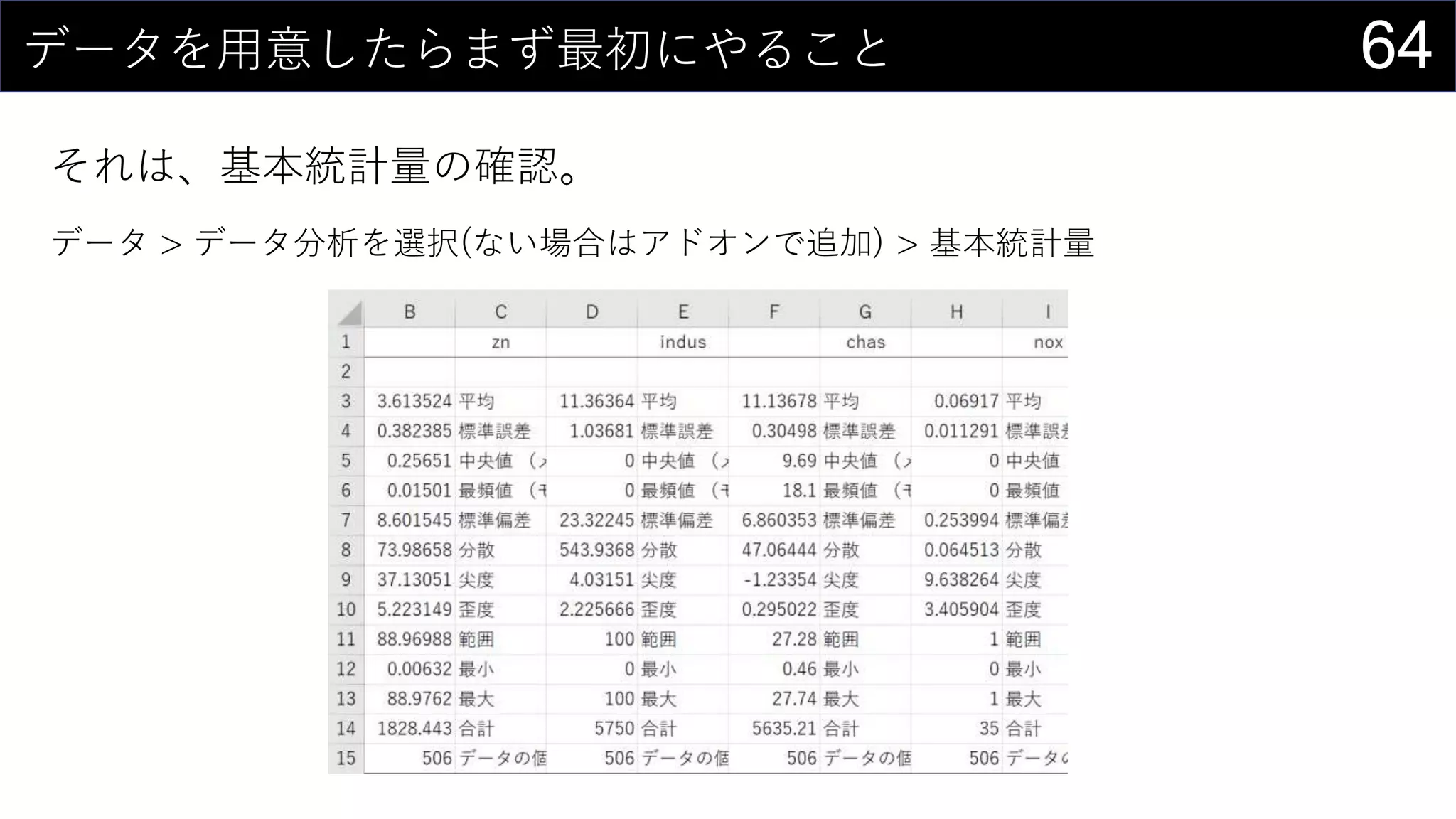
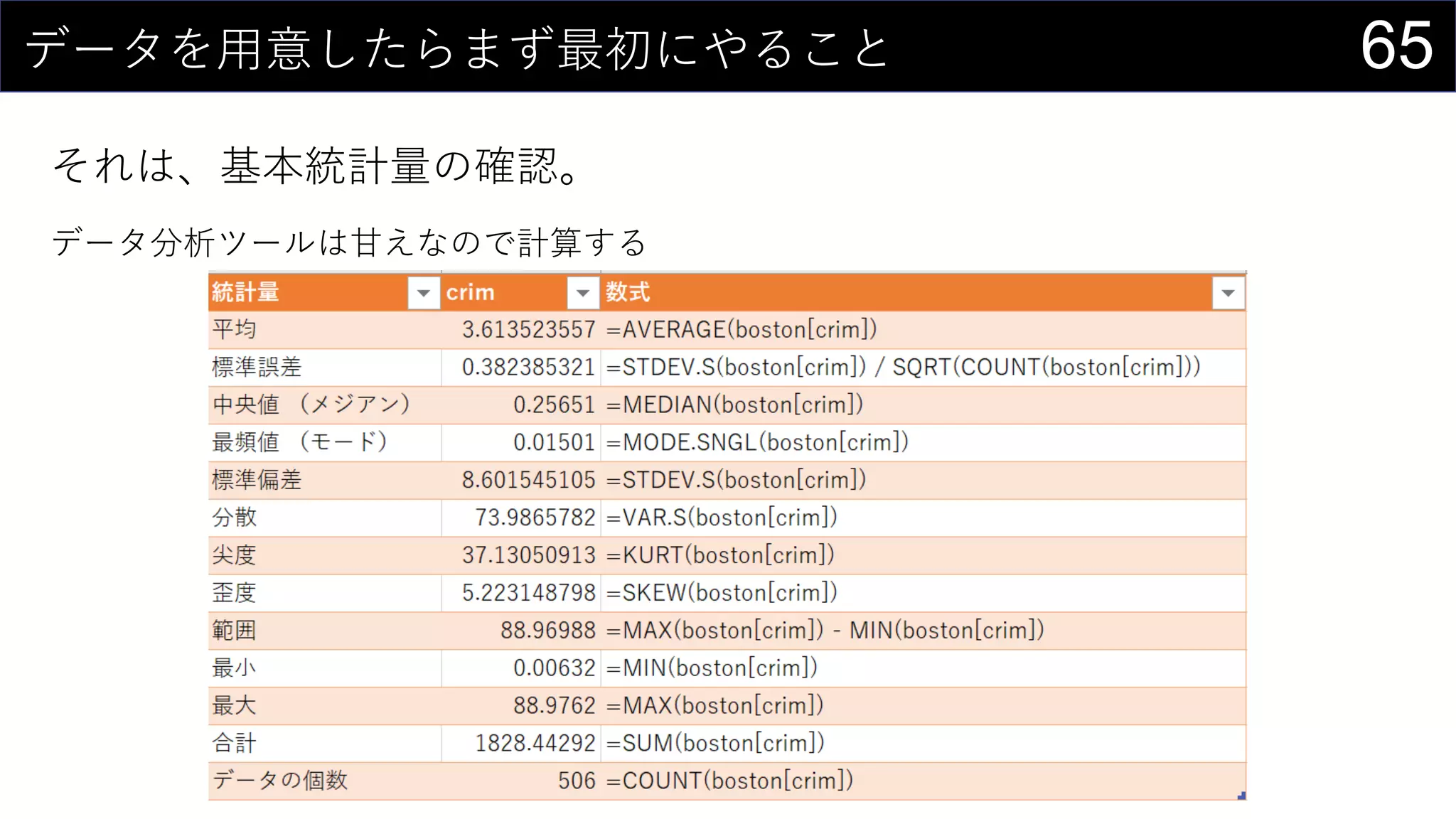
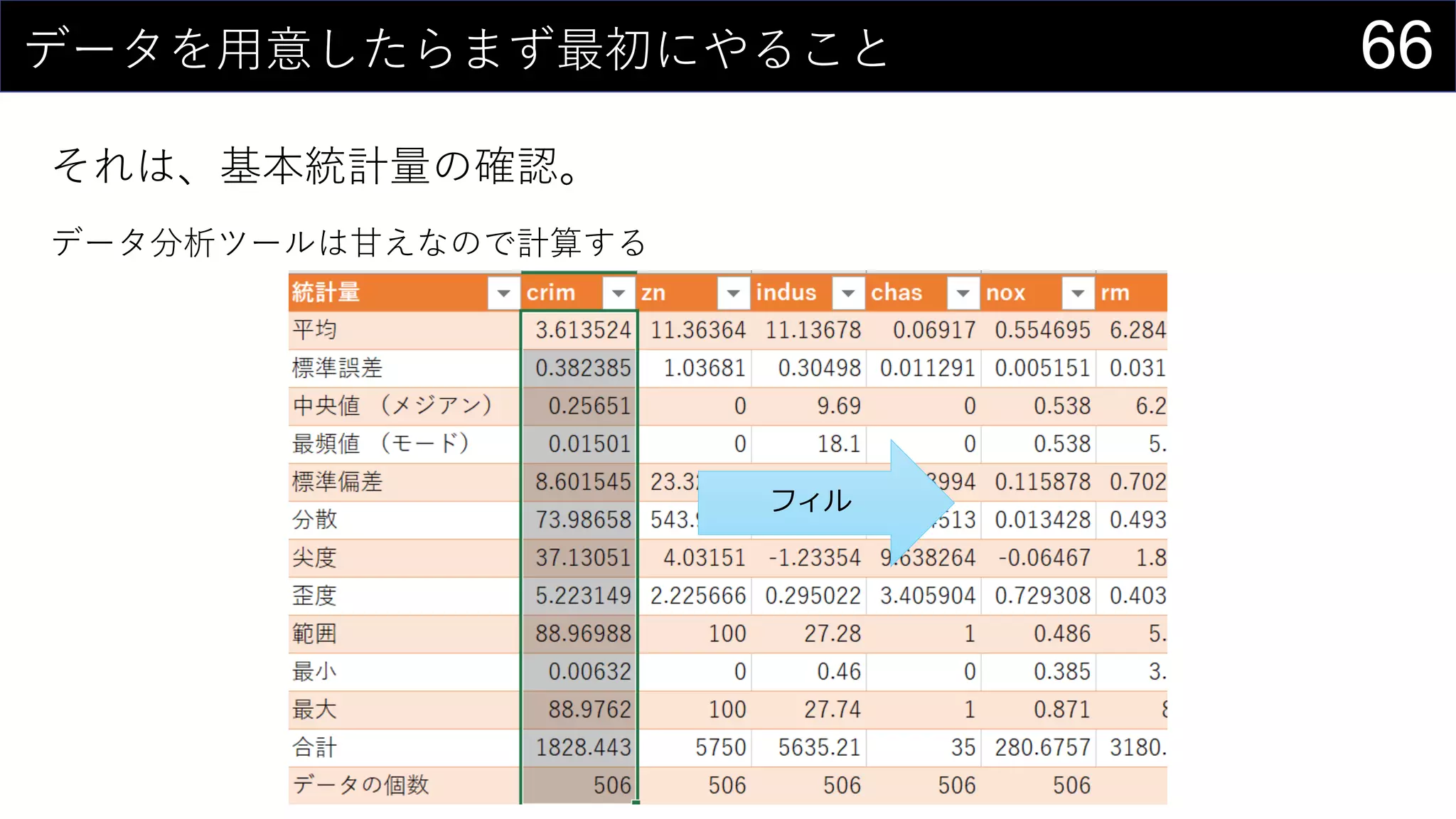
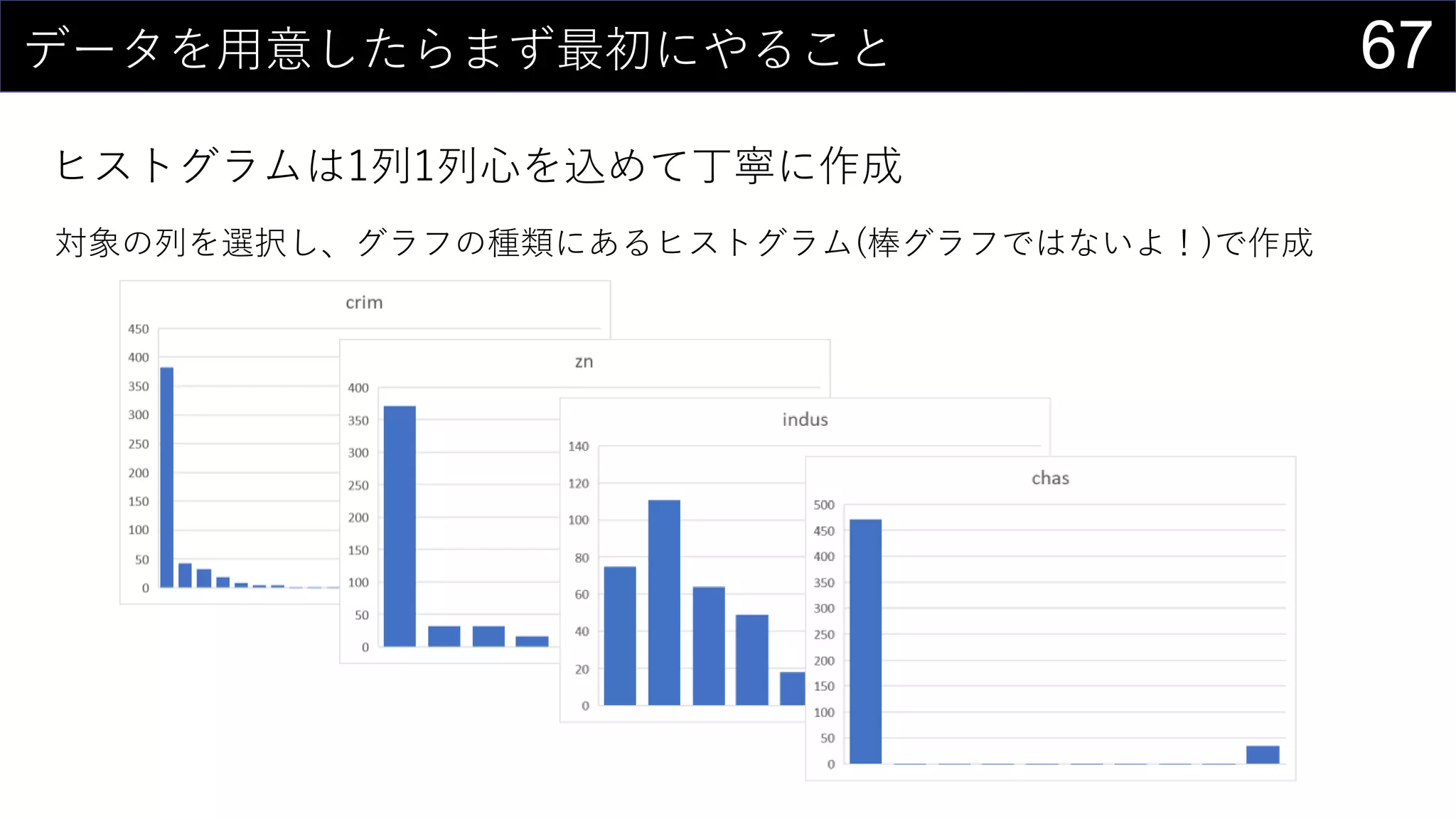
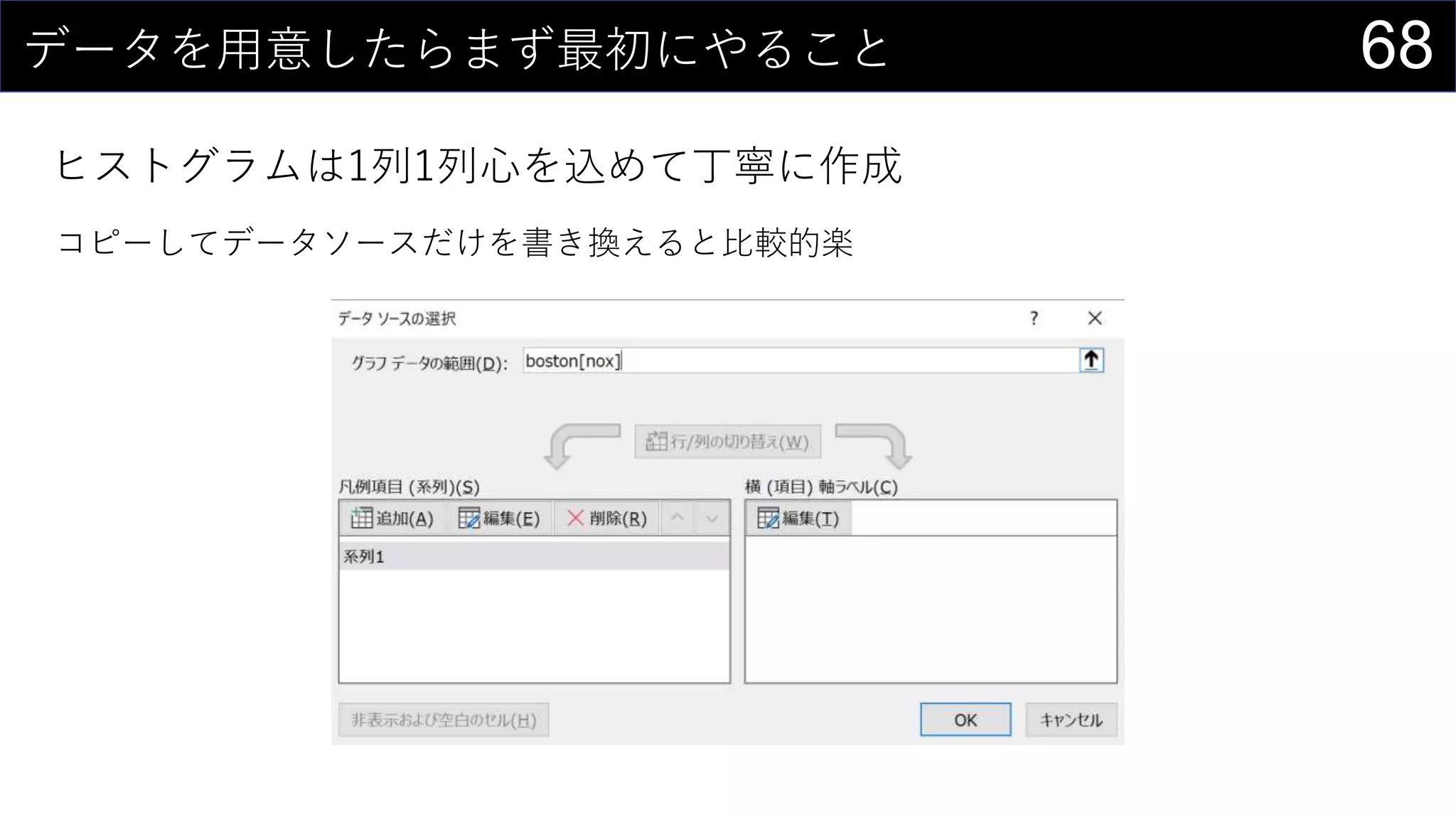
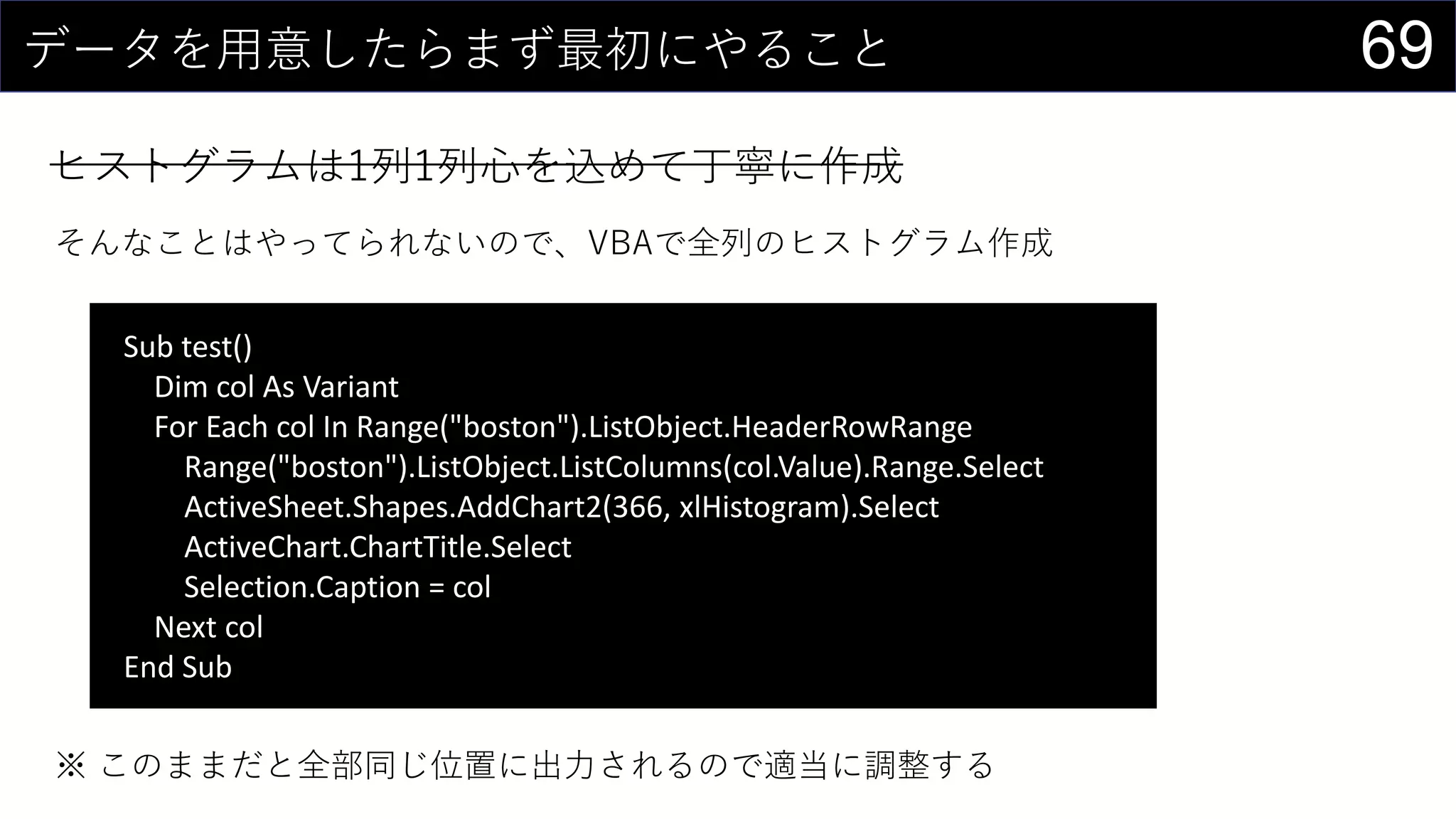
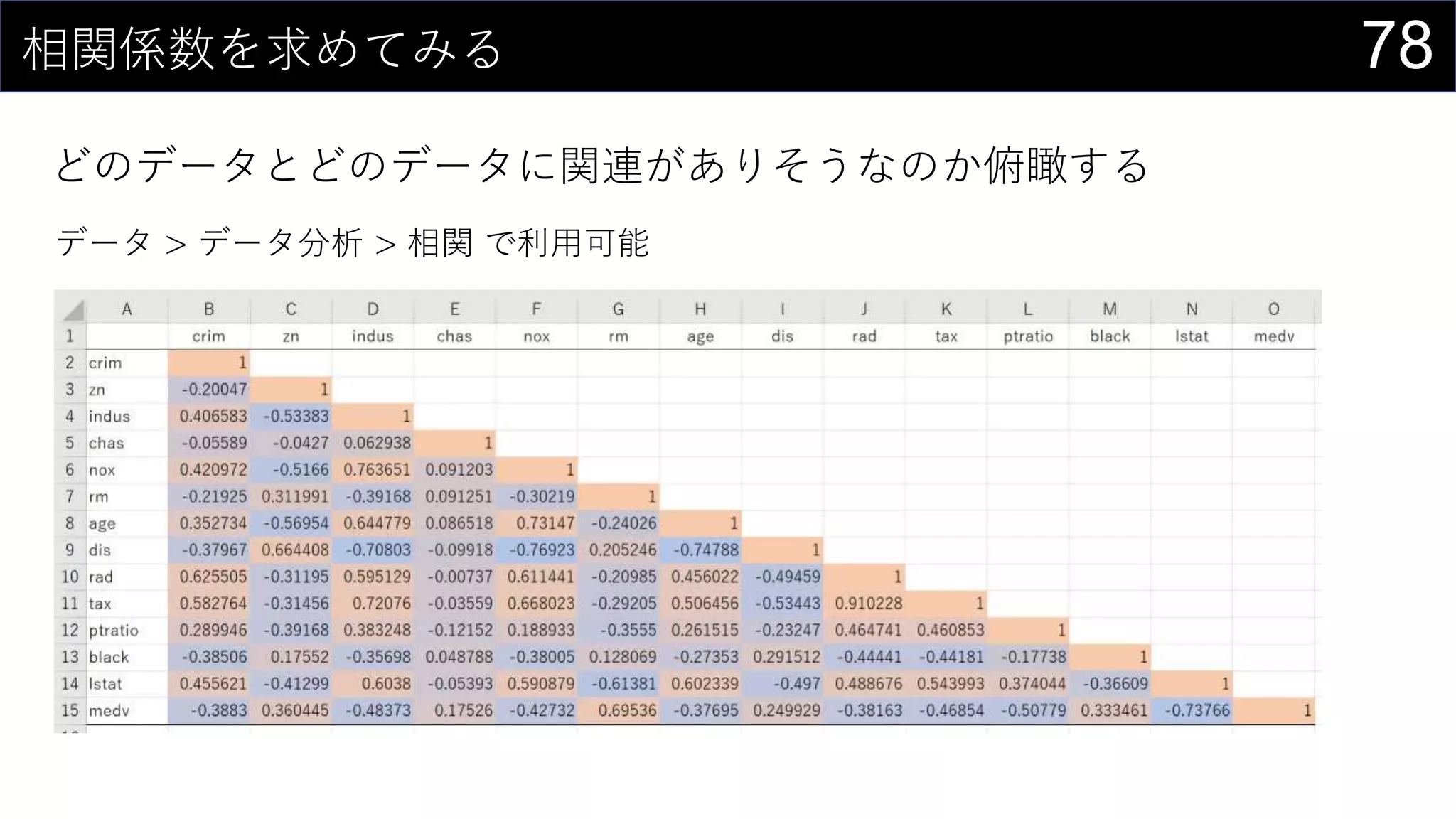
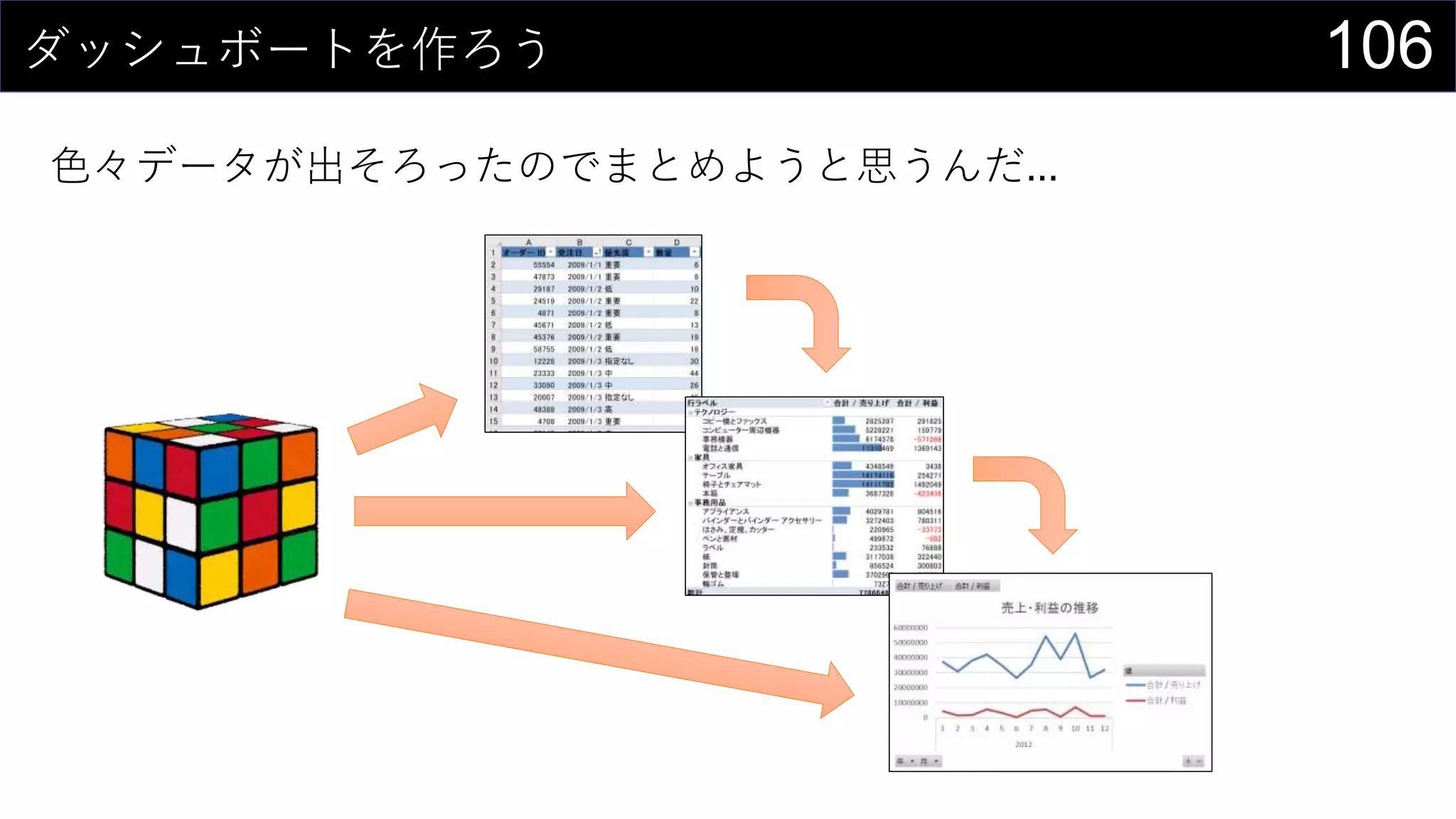
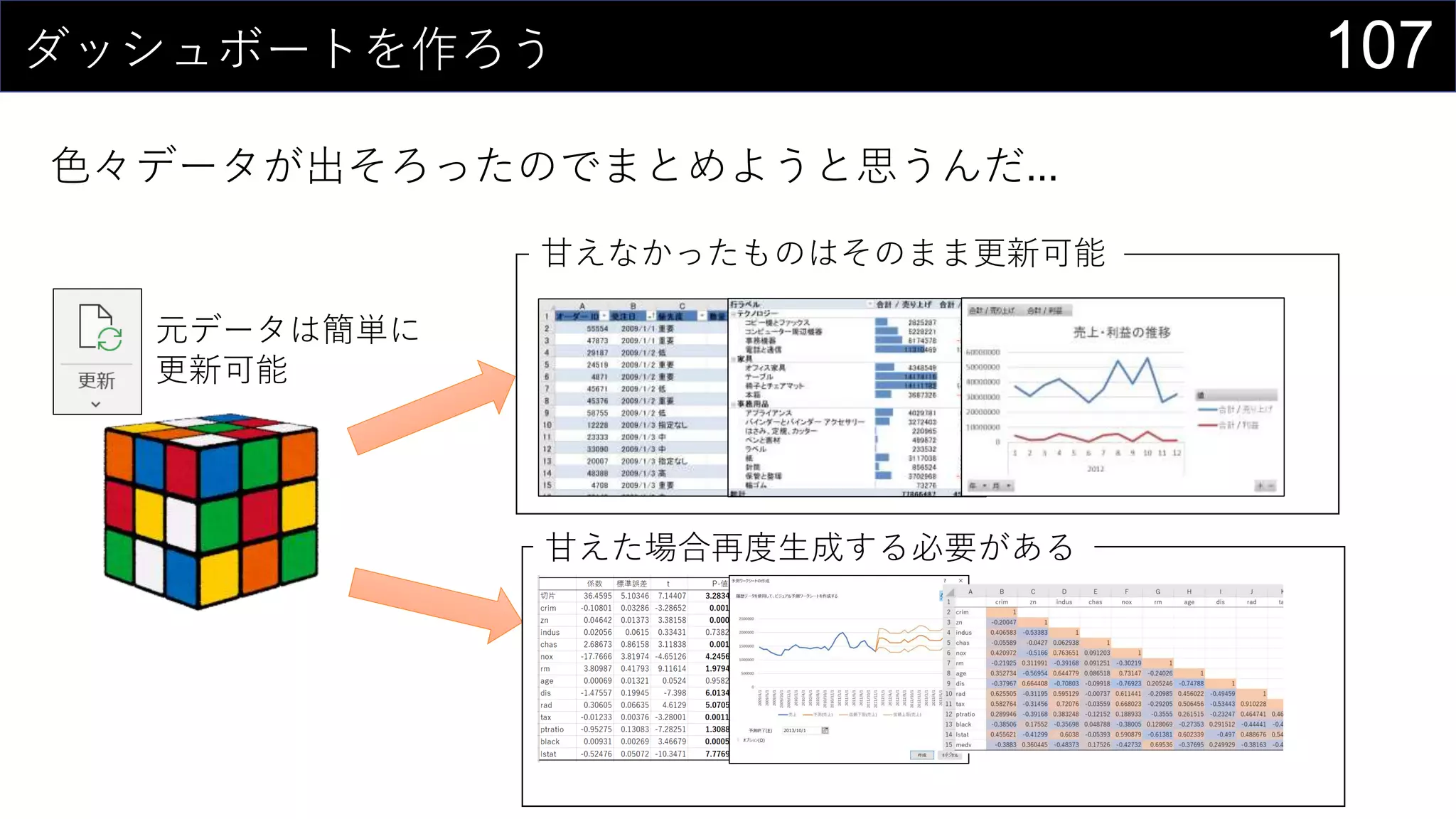
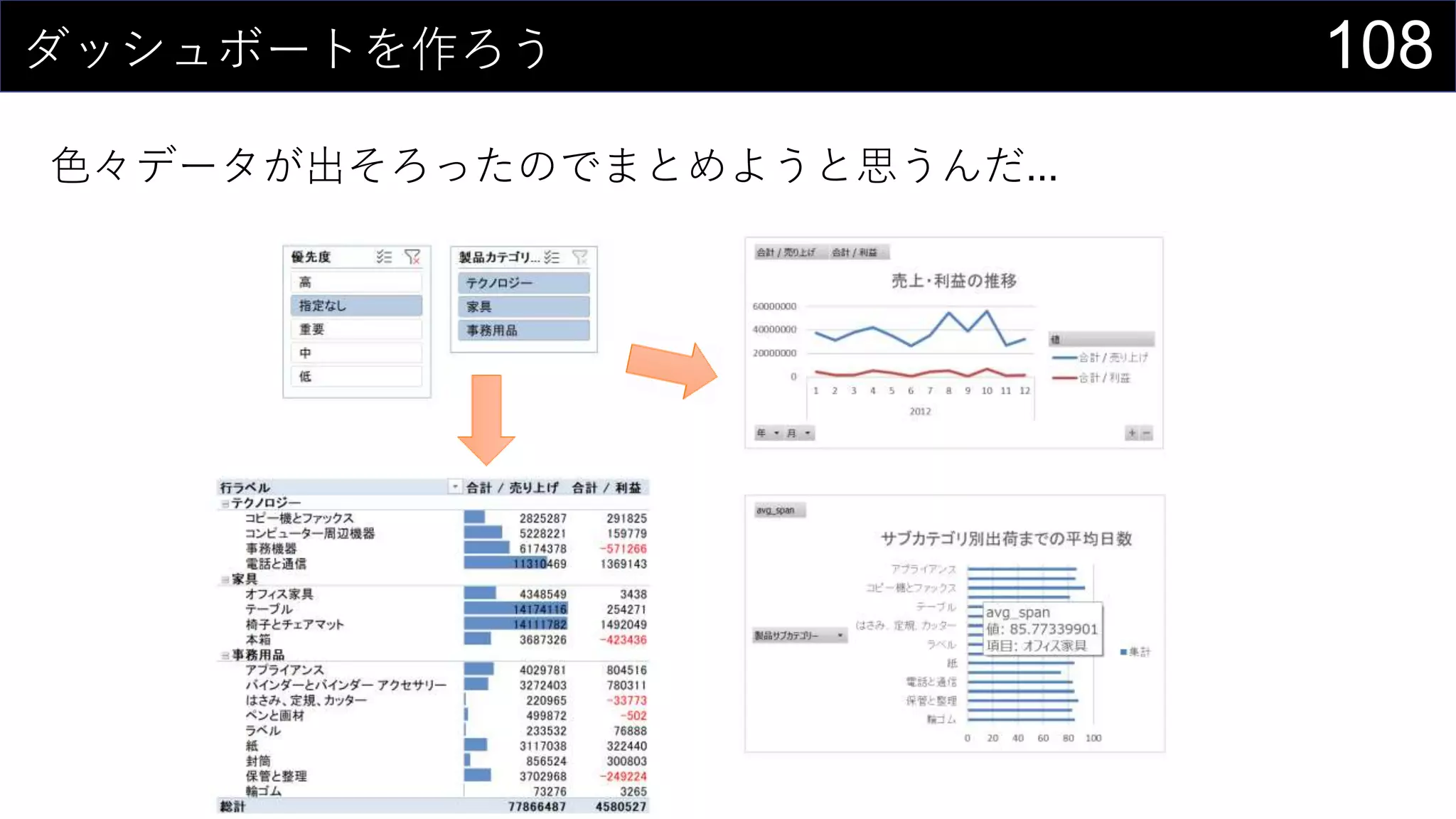
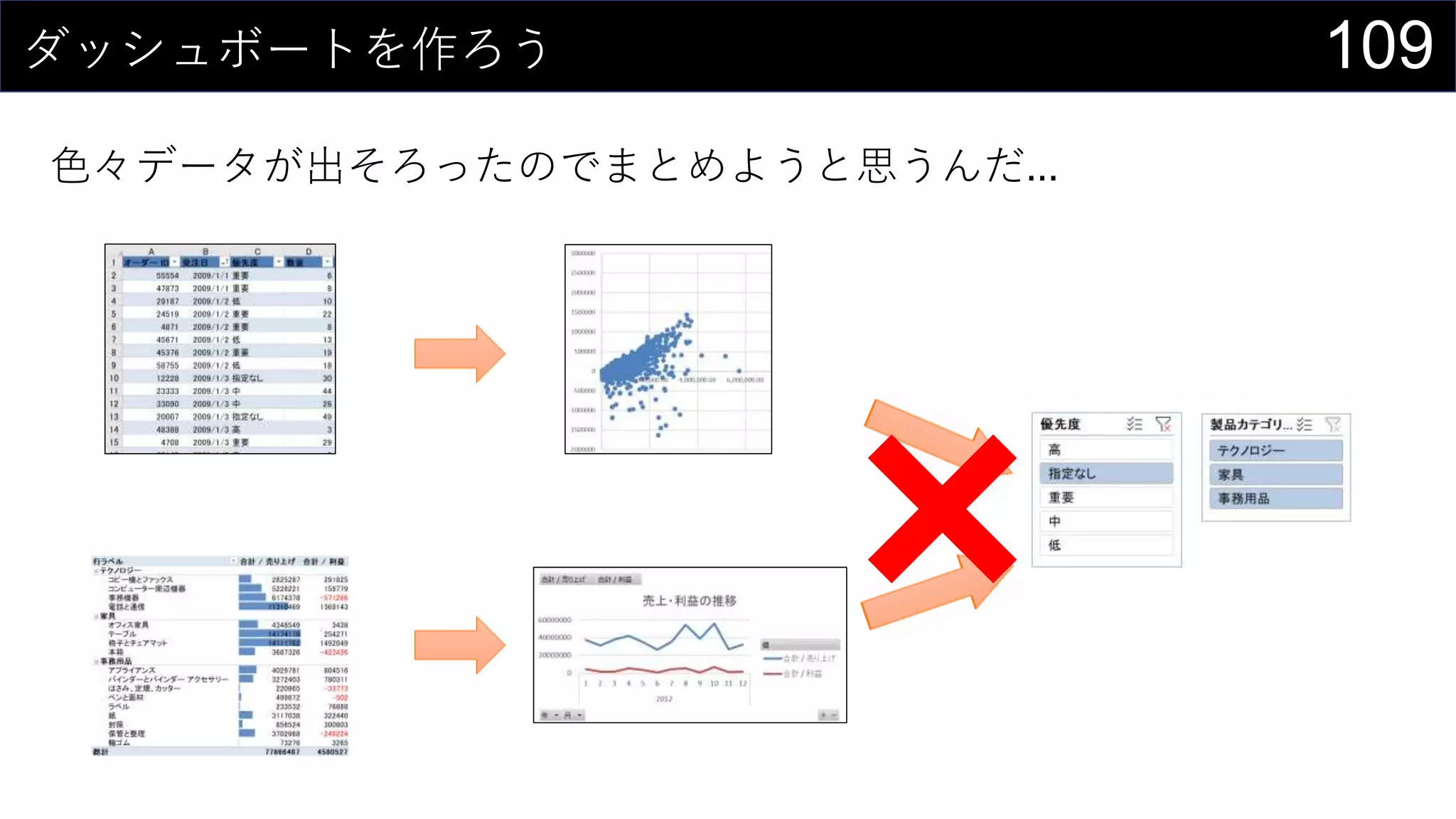
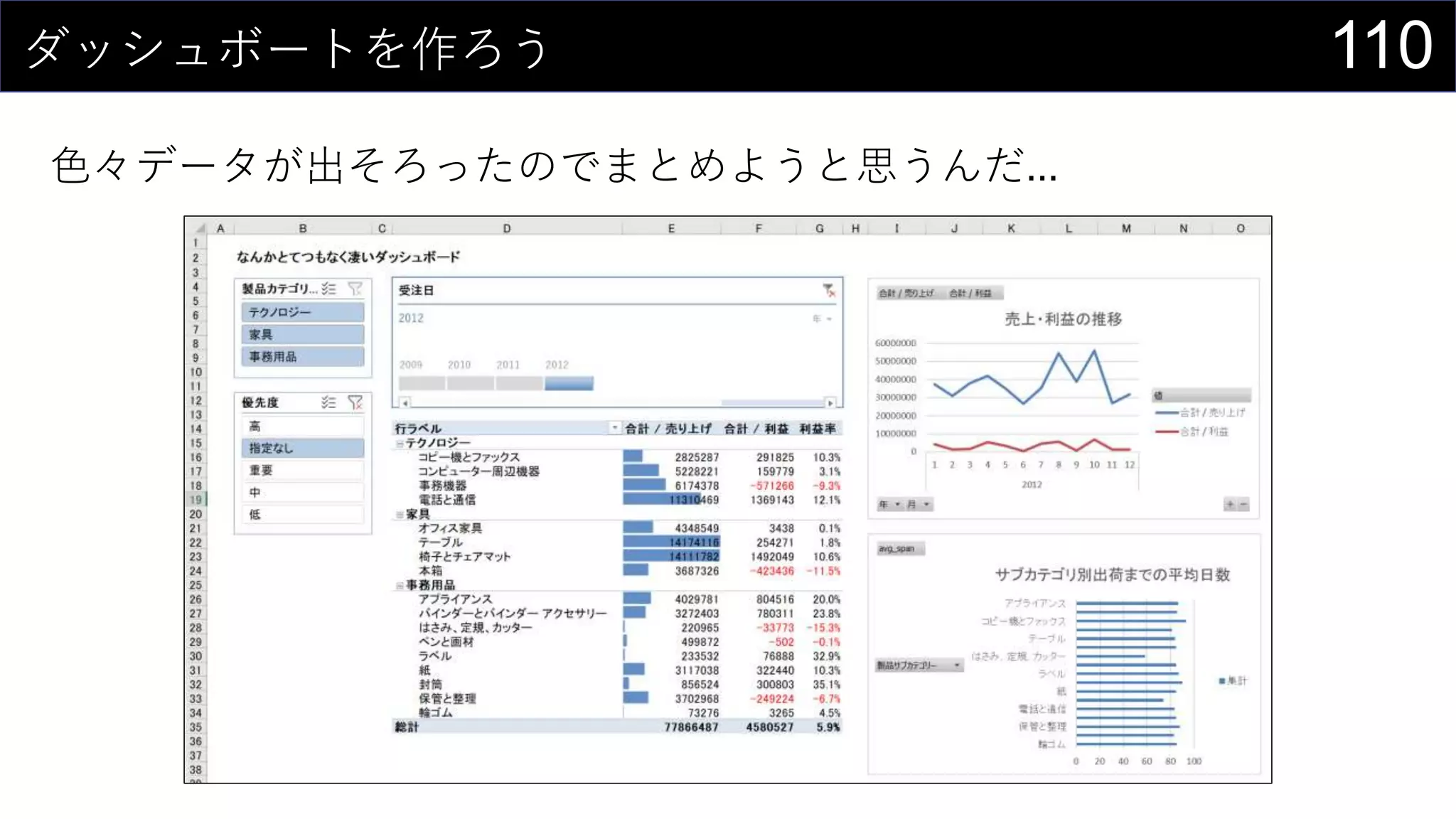
69データを用意したらまず最初にやること
ヒストグラムは1列1列心を込めて丁寧に作成
そんなことはやってられないので、VBAで全列のヒストグラム作成
Sub test()
Dim colAs Variant
For Each col In Range("boston").ListObject.HeaderRowRange
Range("boston").ListObject.ListColumns(col.Value).Range.Select
ActiveSheet.Shapes.AddChart2(366, xlHistogram).Select
ActiveChart.ChartTitle.Select
Selection.Caption = col
Next col
End Sub
※ このままだと全部同じ位置に出力されるので適当に調整する






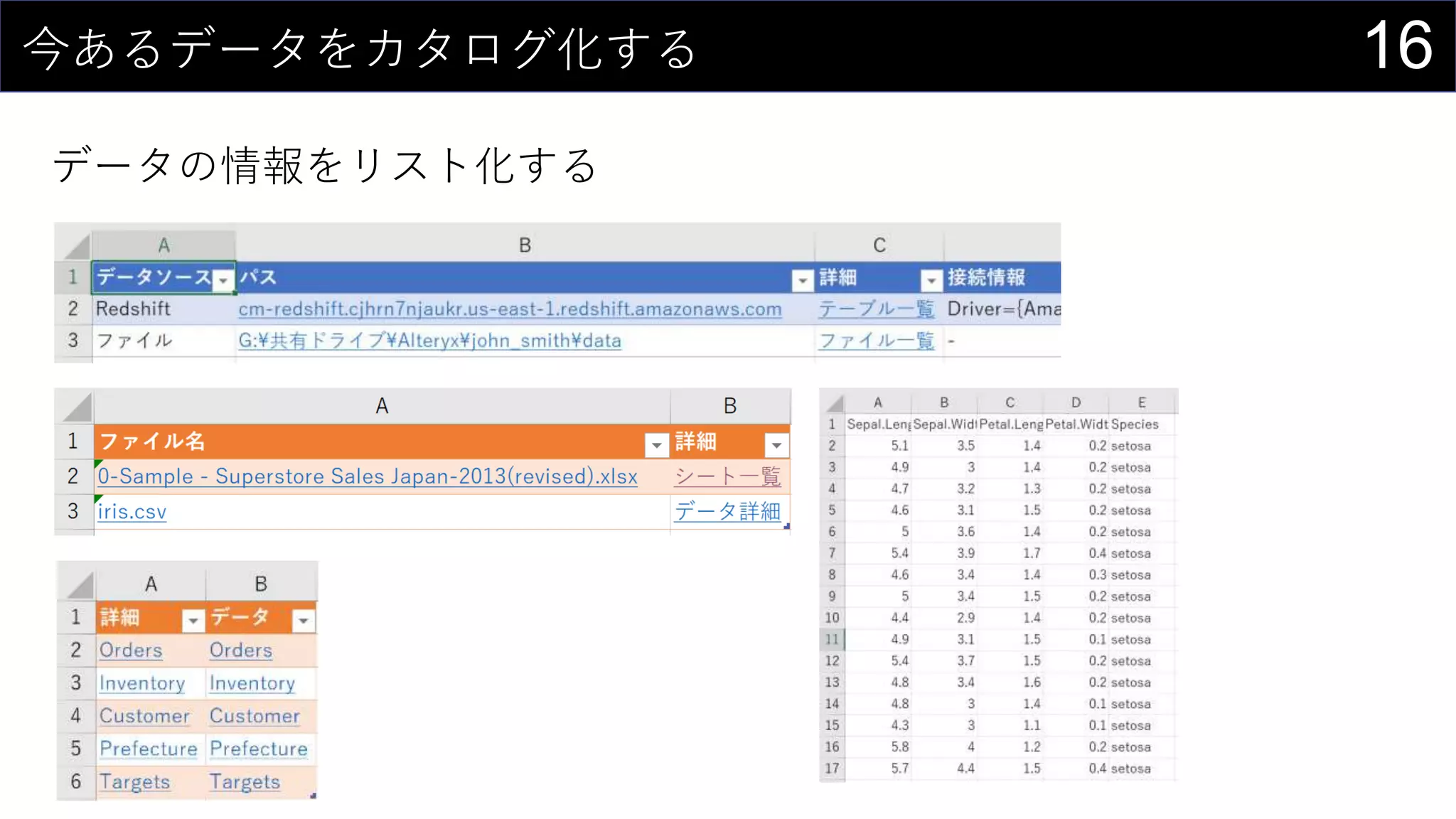
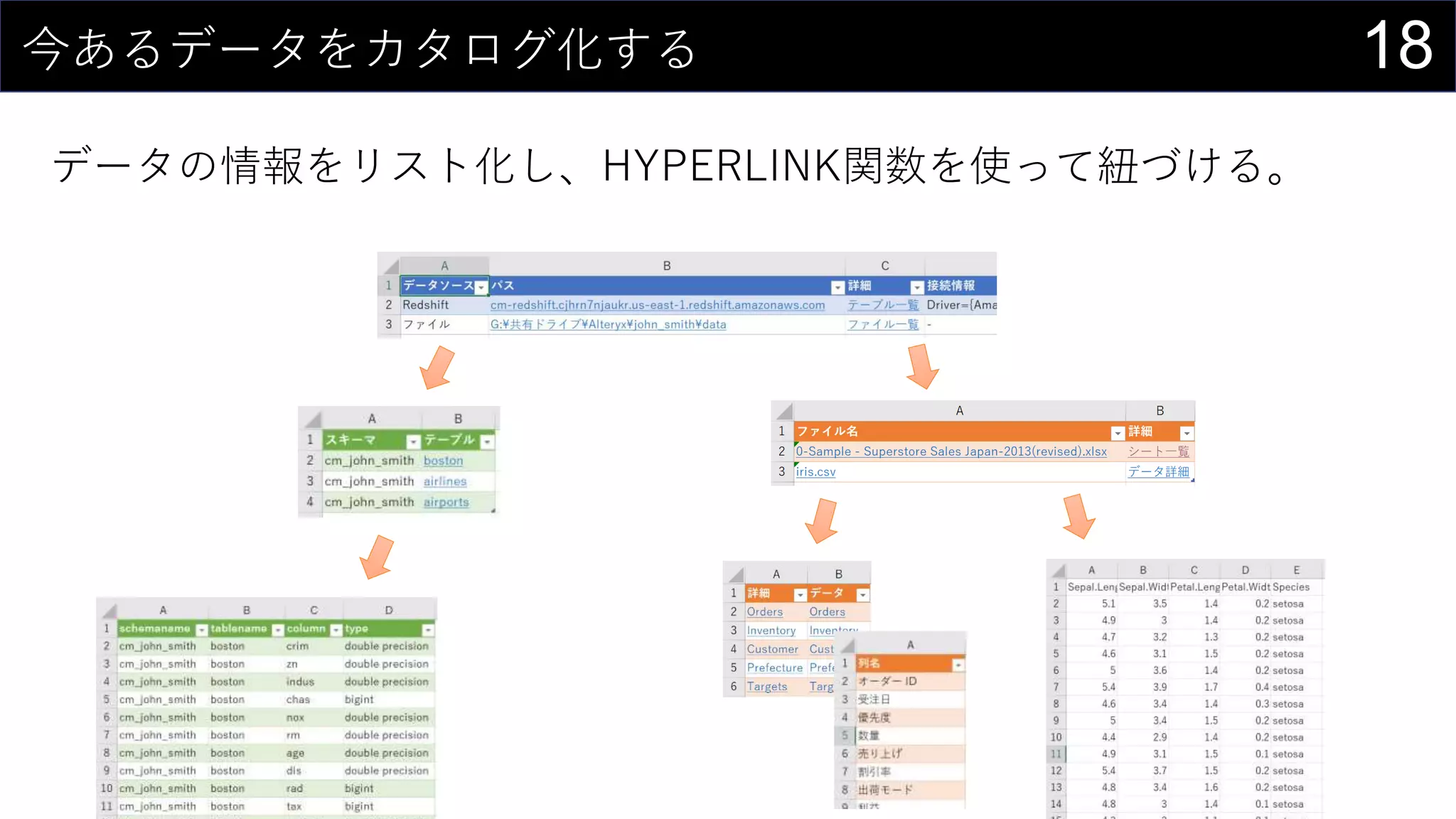
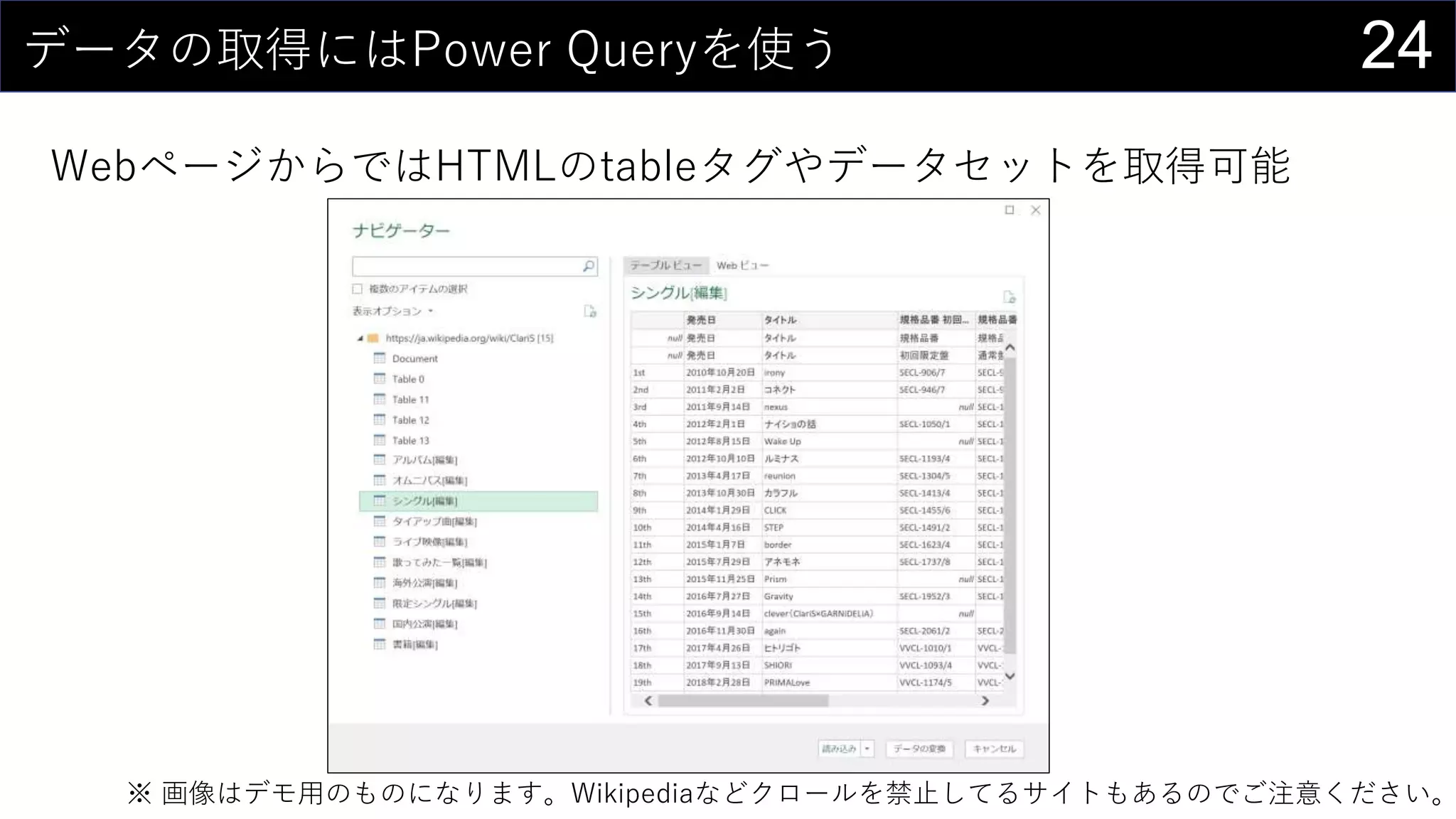
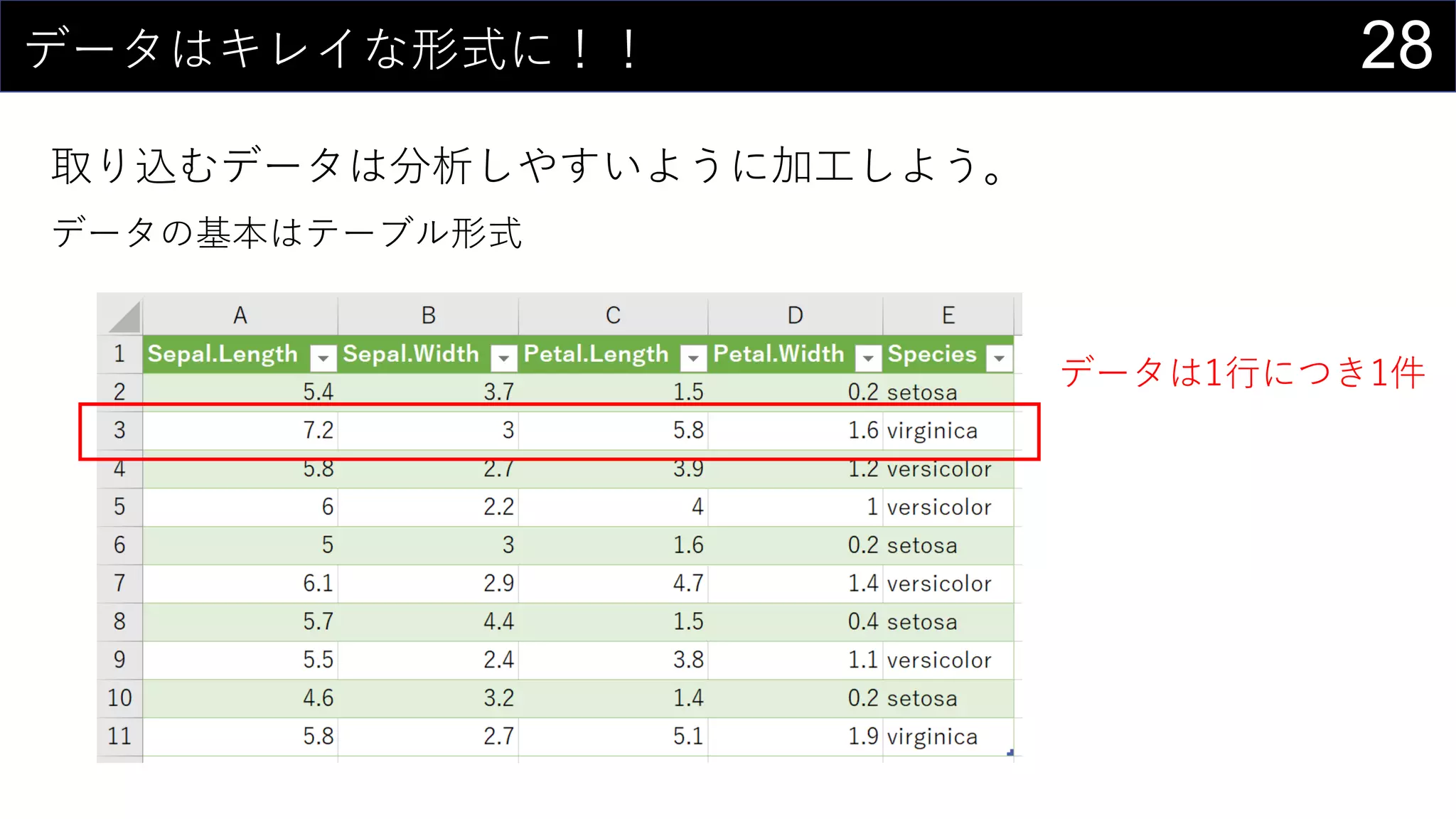
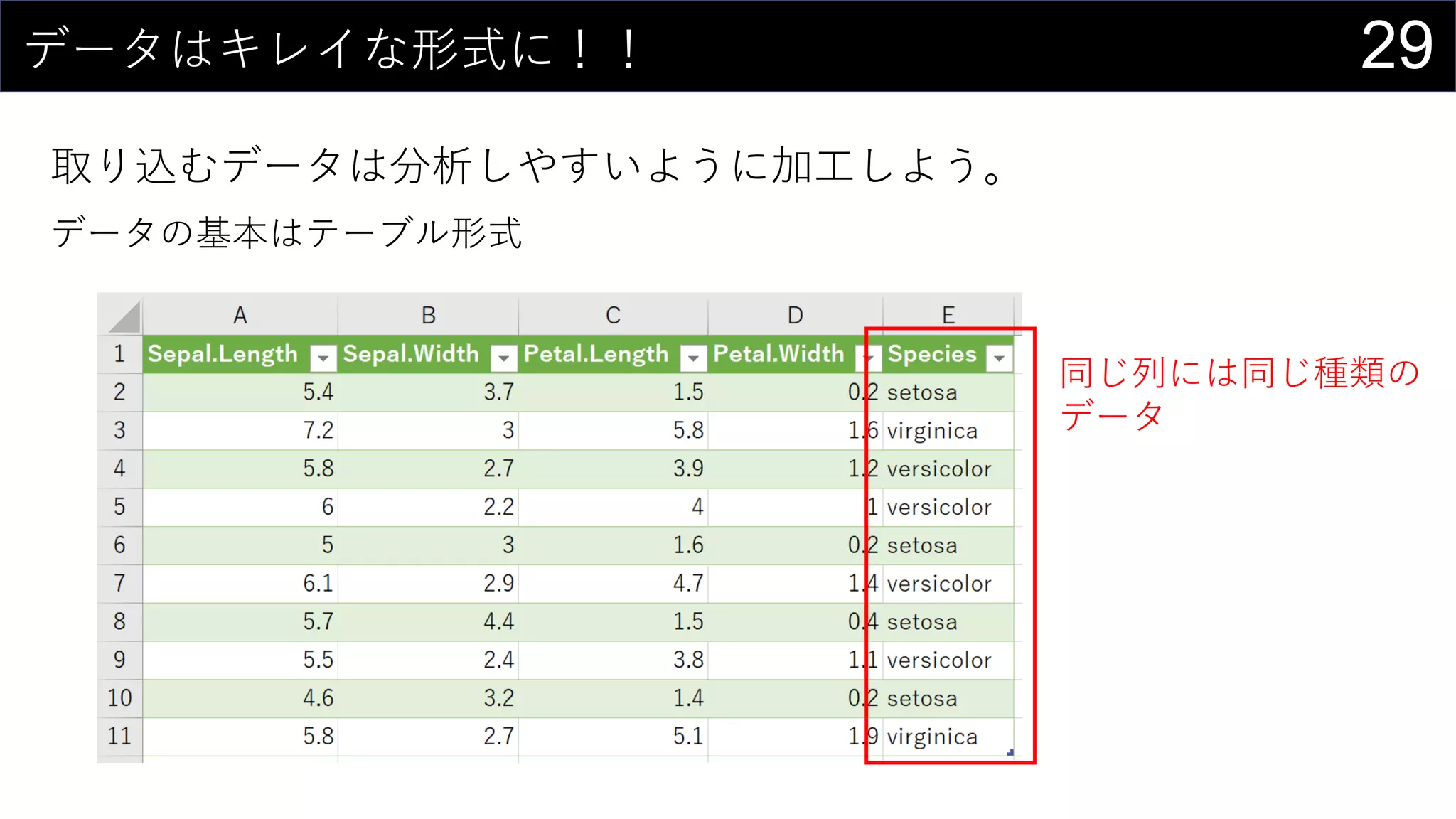
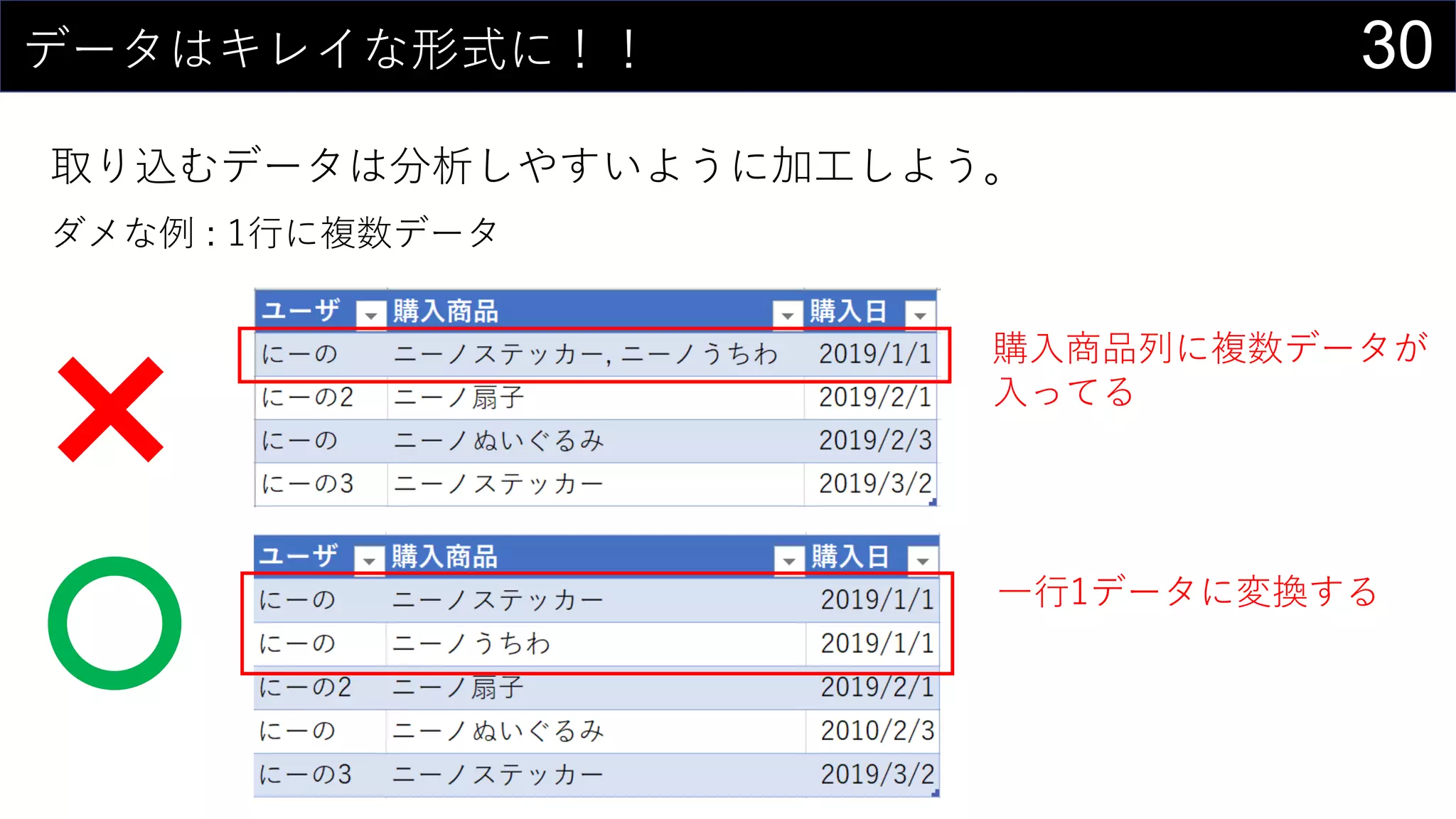
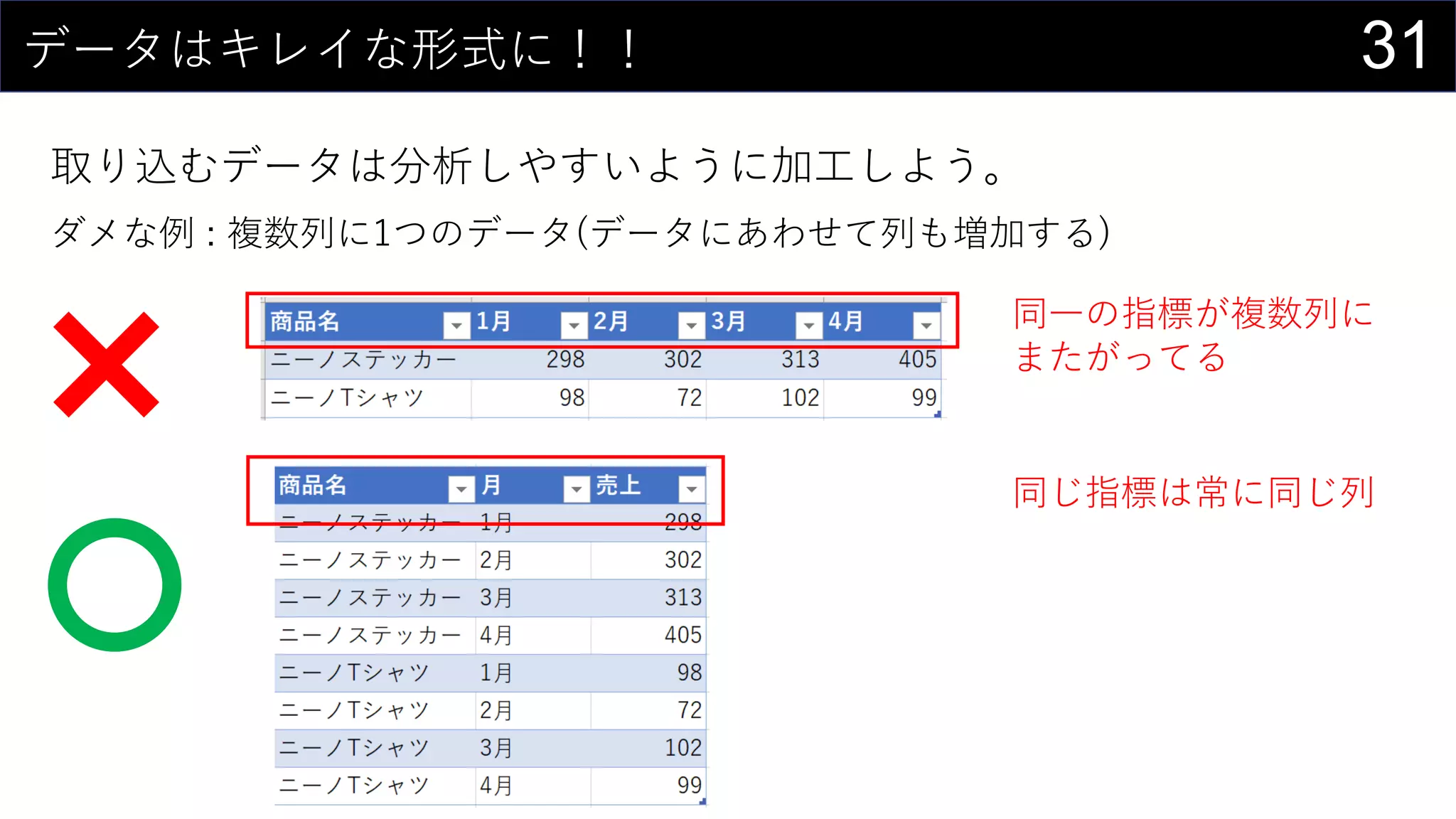
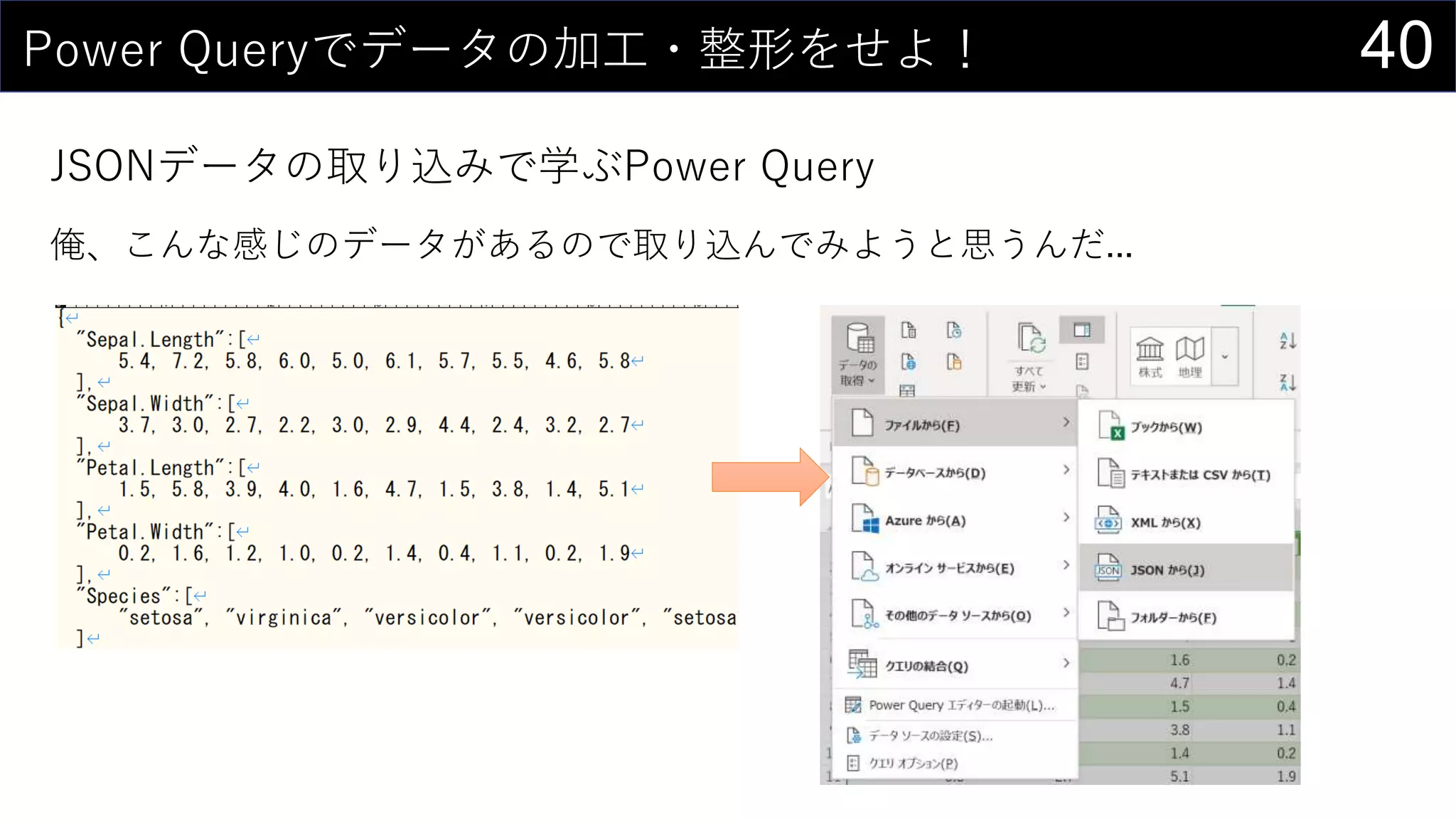
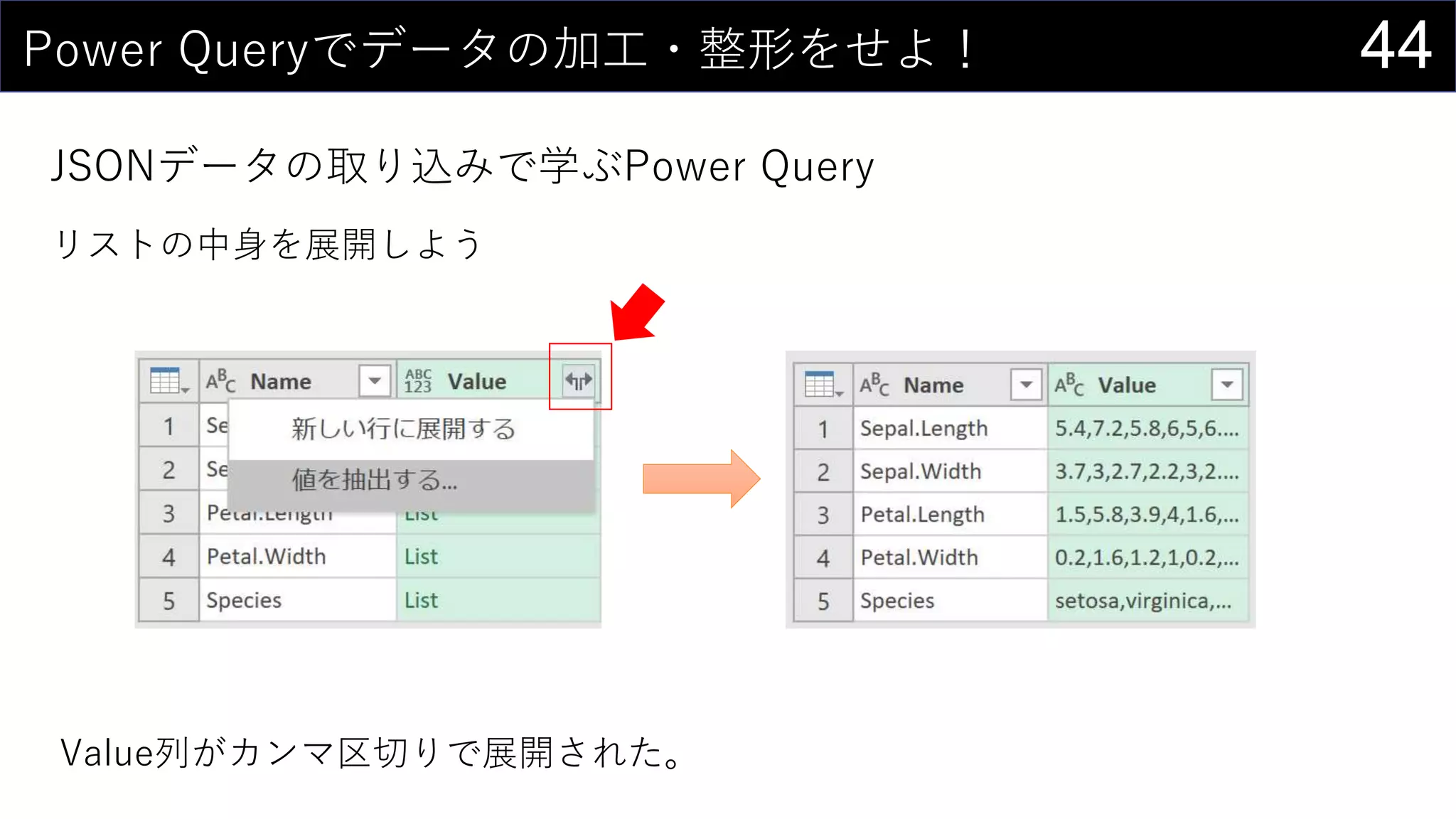
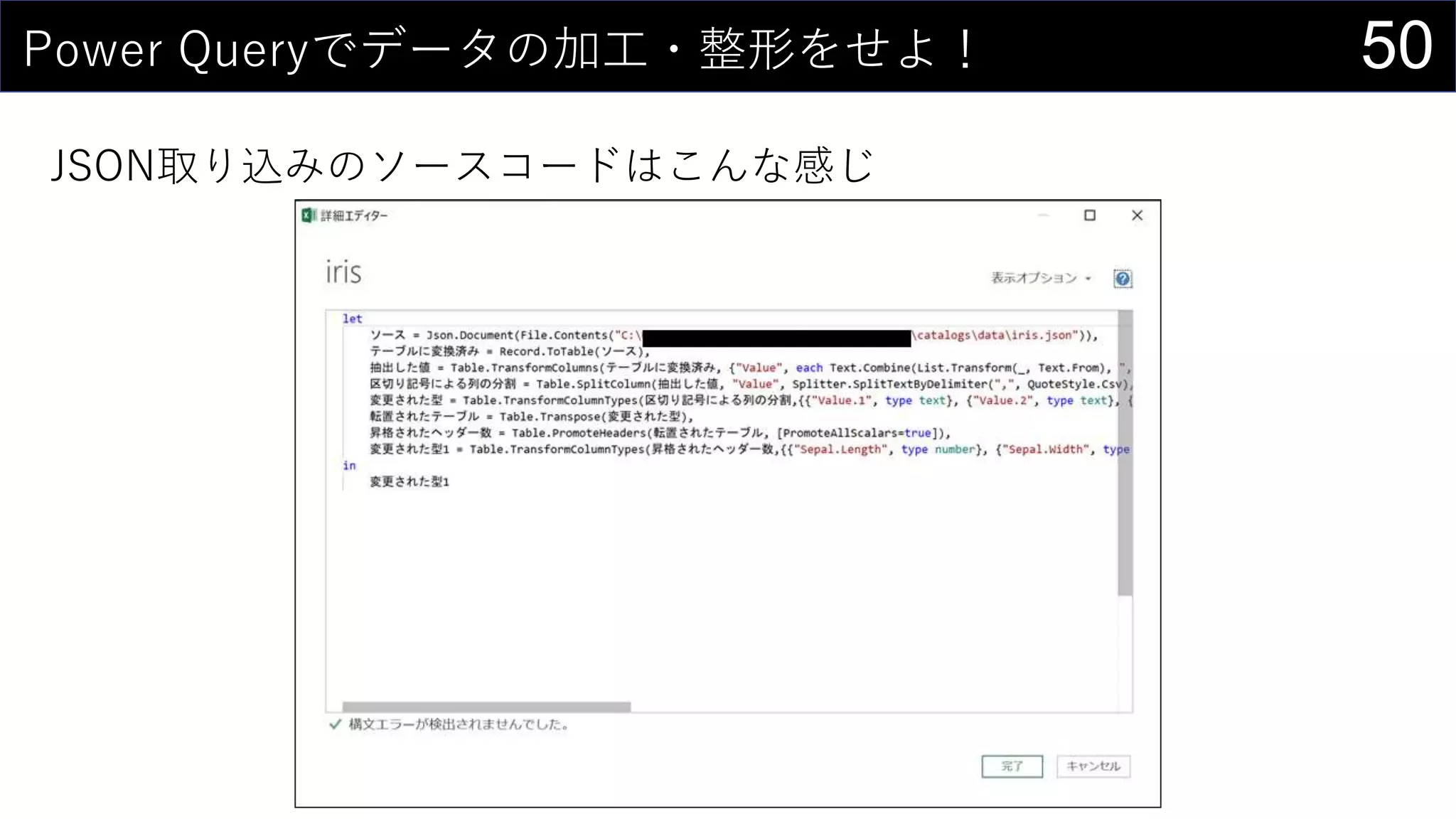
![17今あるデータをカタログ化する
データの情報をリスト化し、HYPERLINK関数を使って紐づける。
HYPERLINK(“https://dev.classmethod.jp/”, “Developers.IO”)
HYPERLINK(“Z:analysisdata”, “データフォルダ”)
HYPERLINK(“[iris.xlsx]iris!A1”, “irisデータセット”)](https://image.slidesharecdn.com/devio2019tokyo-191031003046/75/Excel-2nd-Edition-17-2048.jpg)
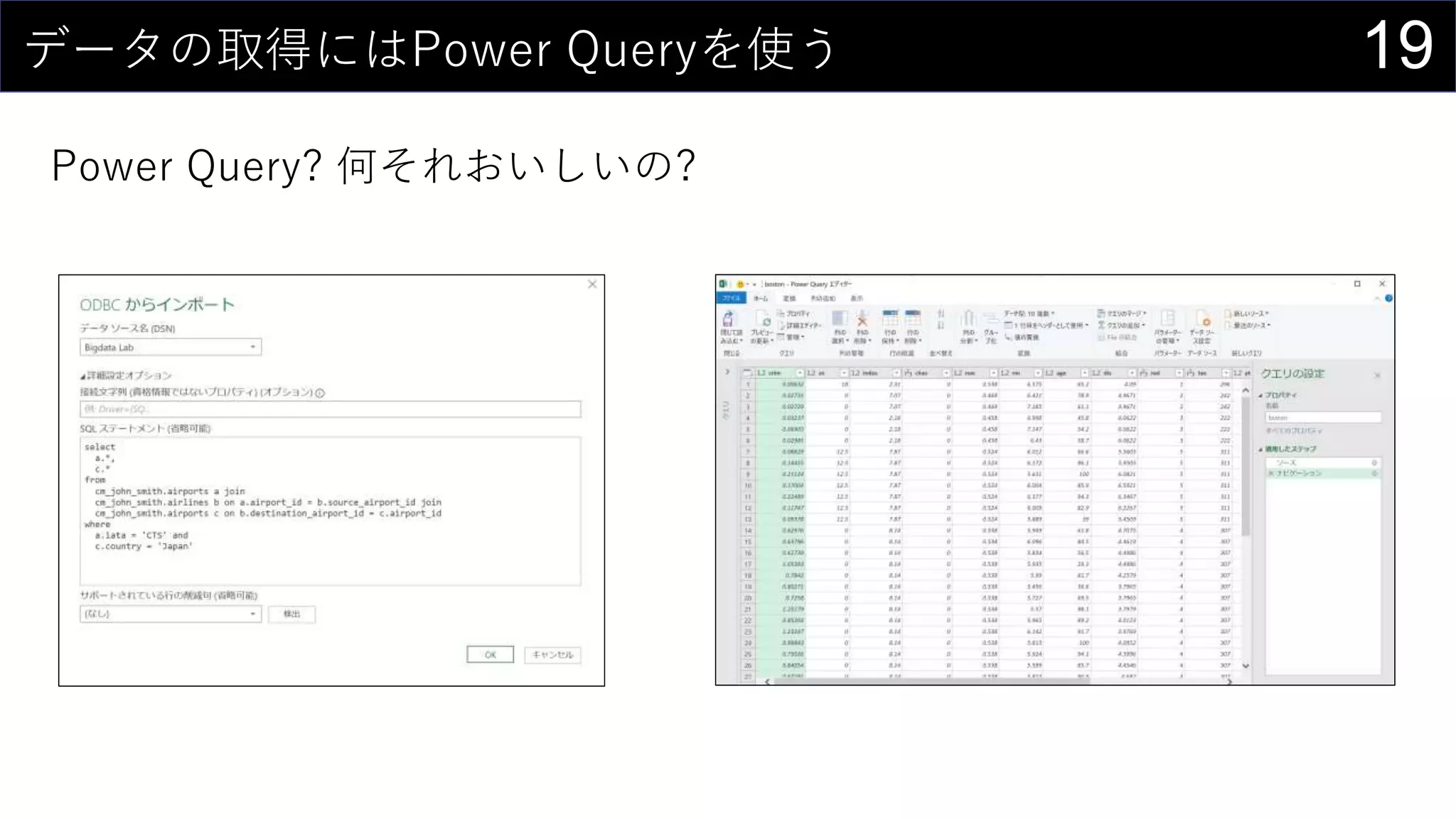
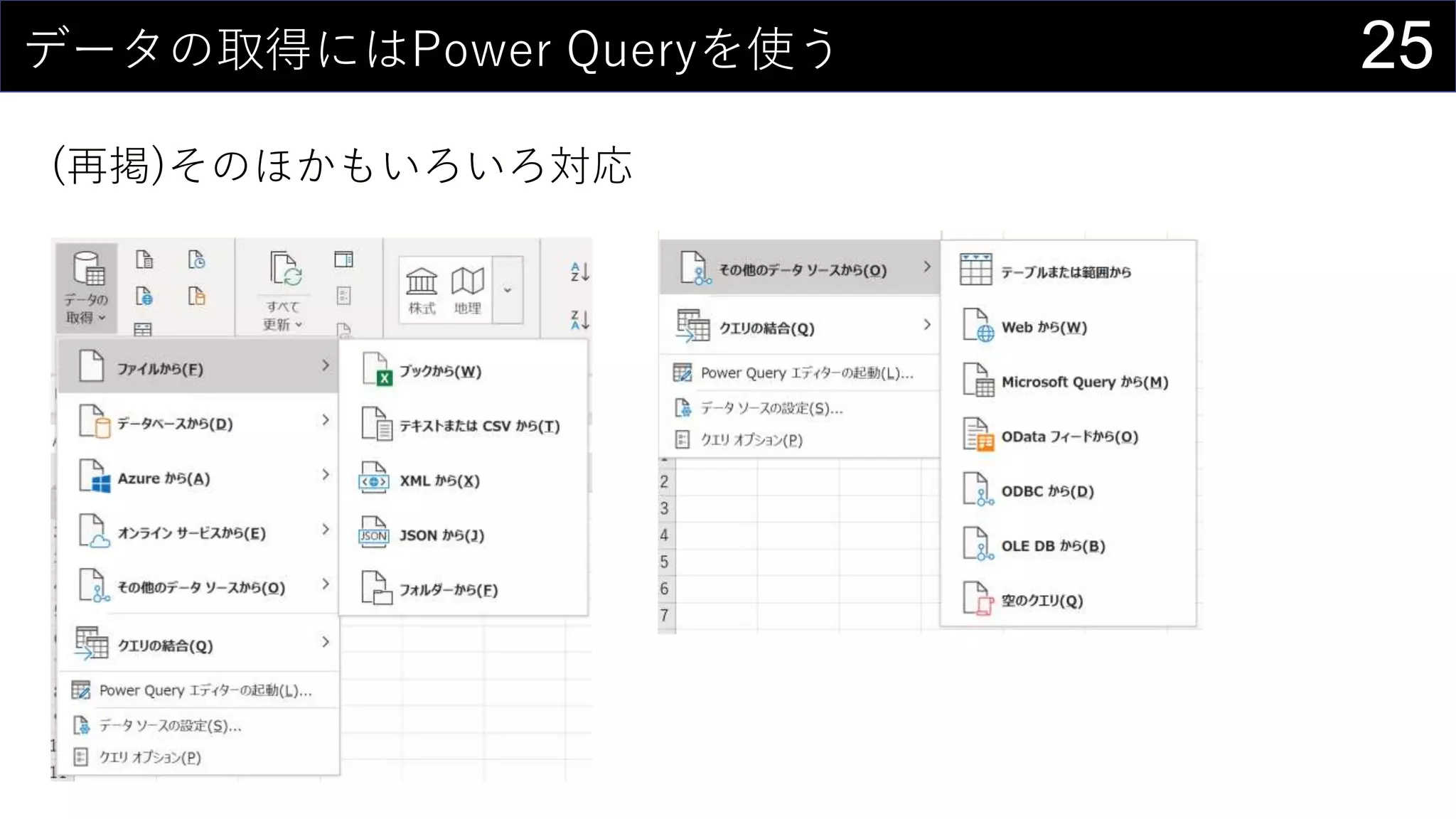



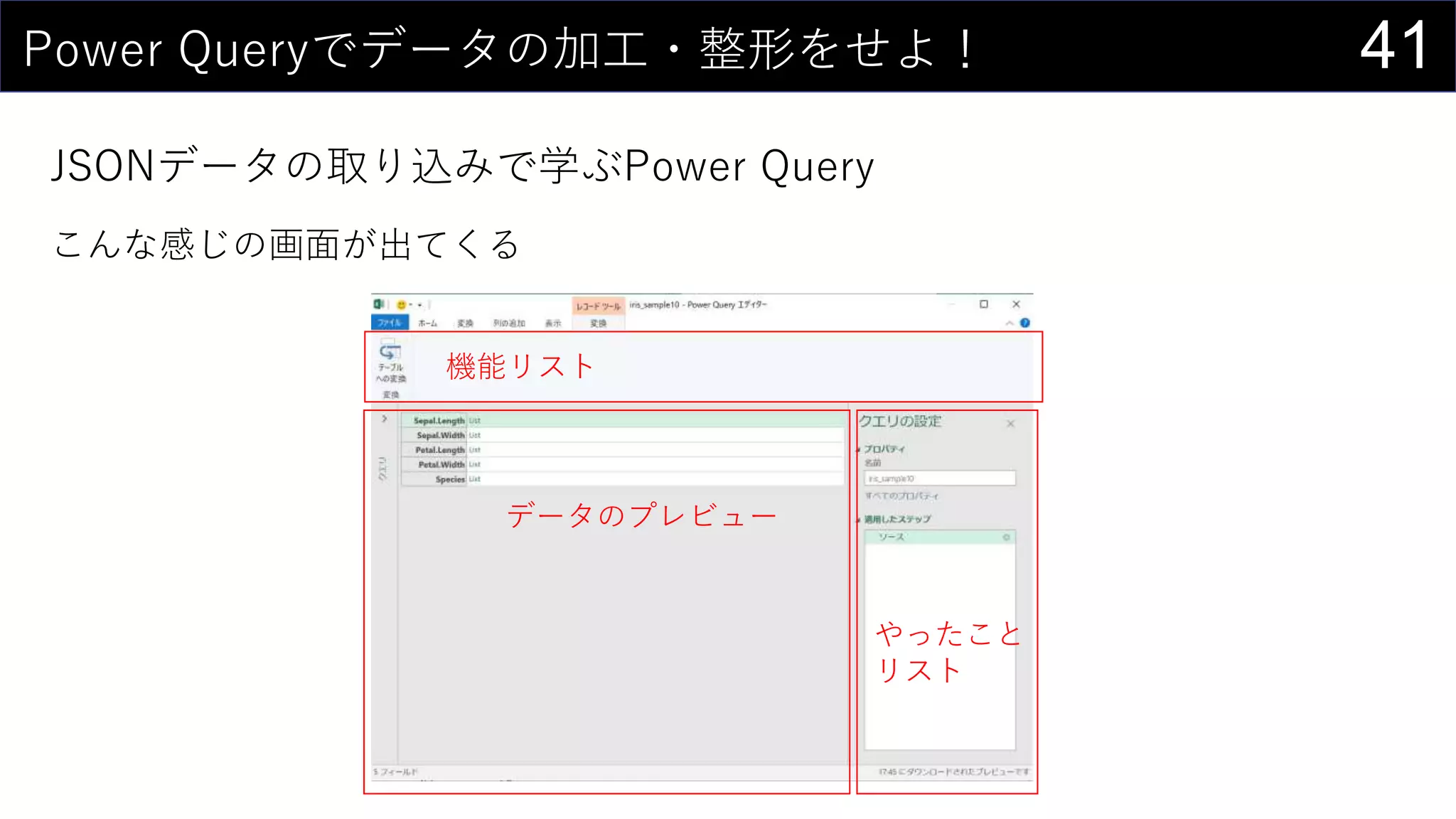
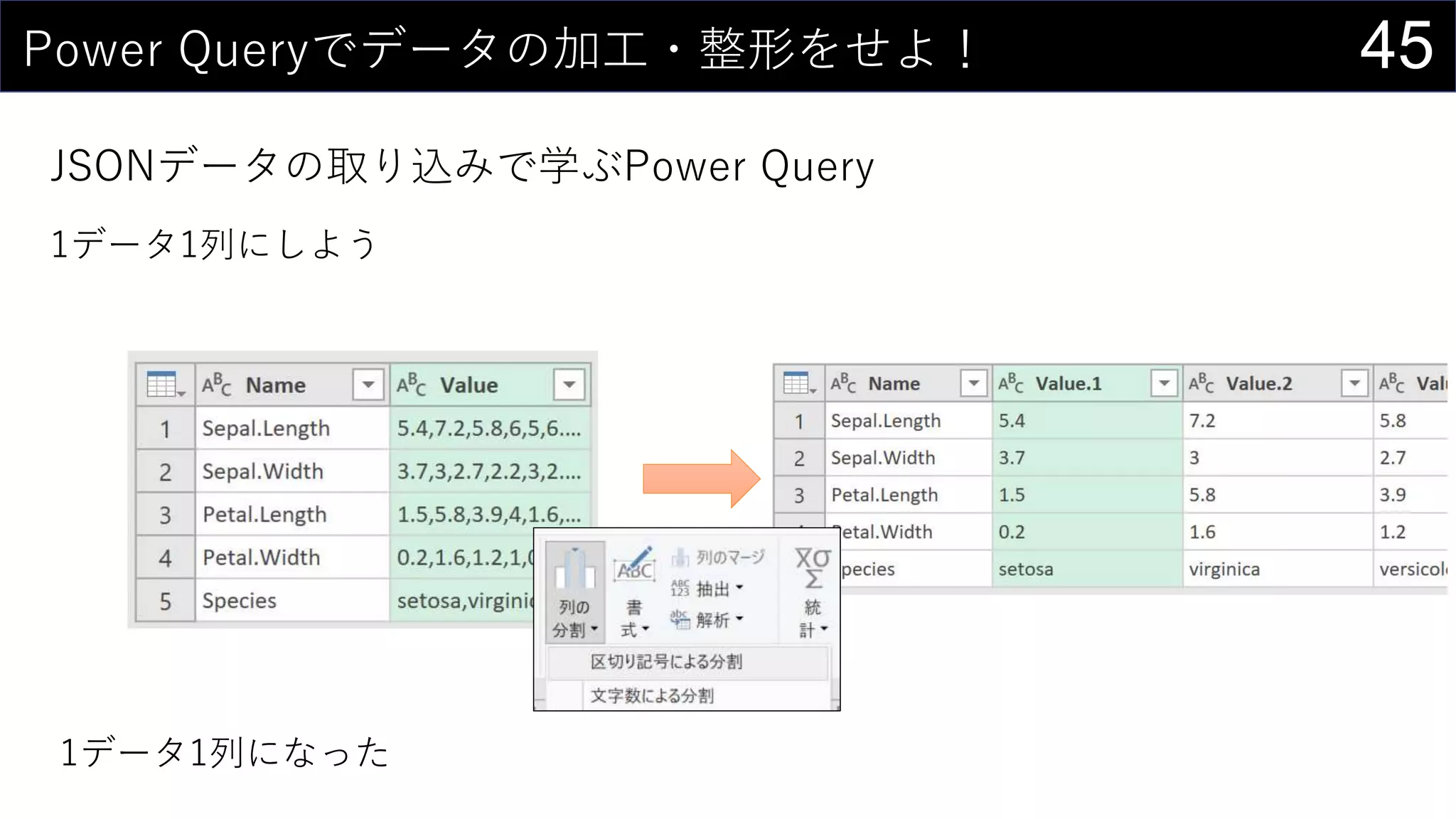
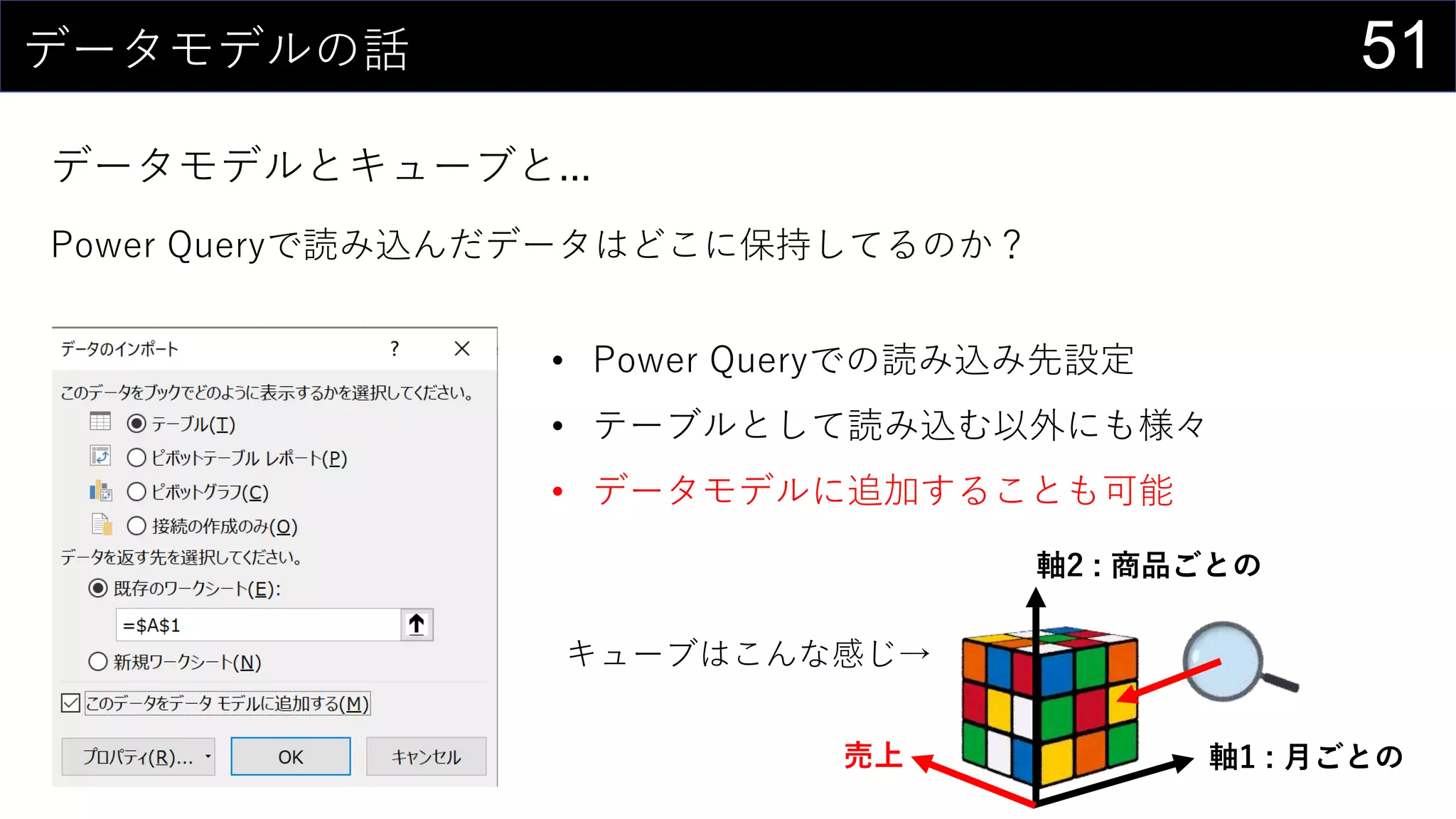
![35ところで...
構造化参照 is 何?
セルの範囲ではなく列名を使ってデータを取り出す参照方法
↑こんな感じのデータがあるとする
テーブル名[列名]で特定の列全体を取り出す
=SUM(iris[Sepal.Length])](https://image.slidesharecdn.com/devio2019tokyo-191031003046/75/Excel-2nd-Edition-35-2048.jpg)
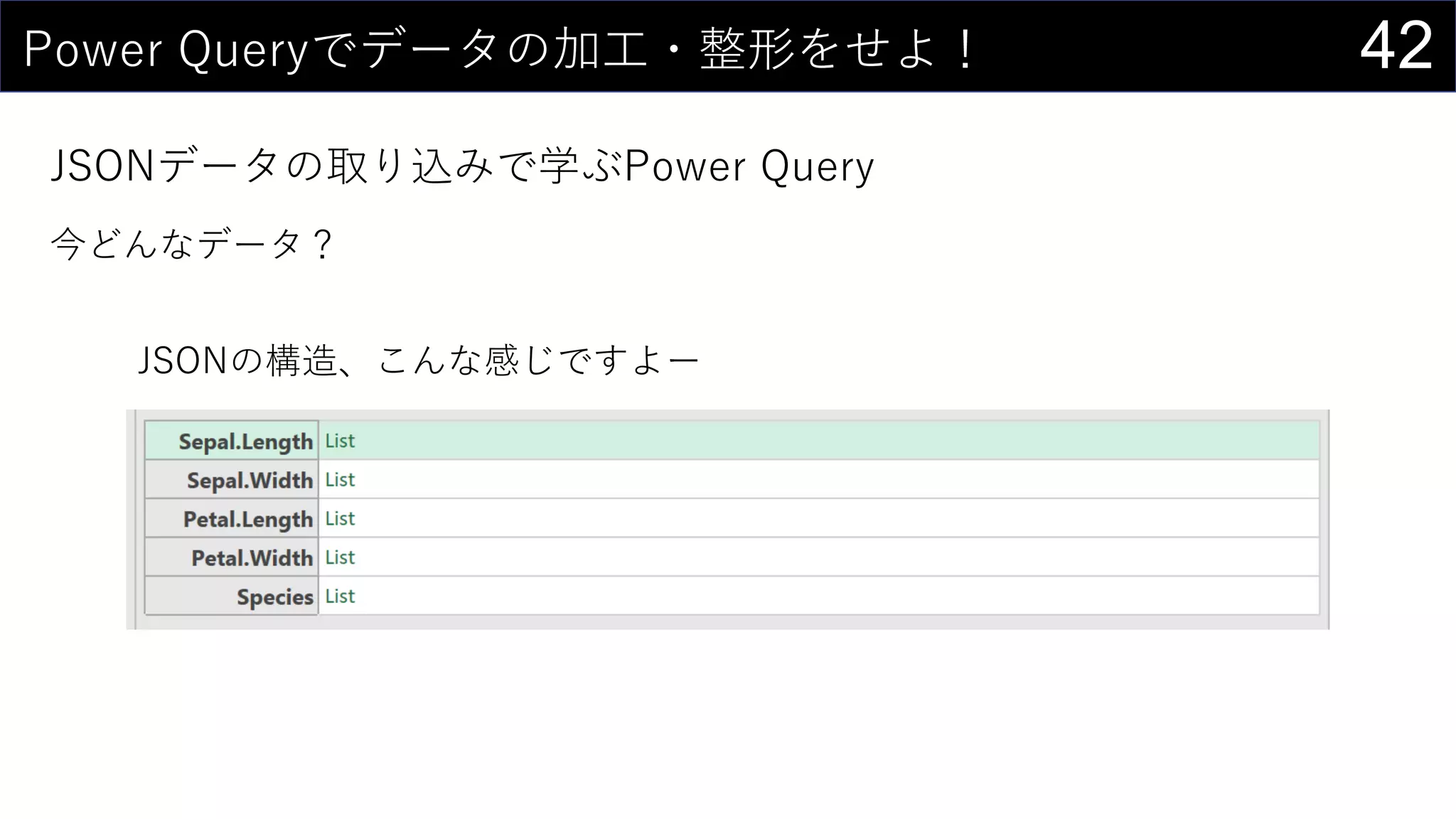
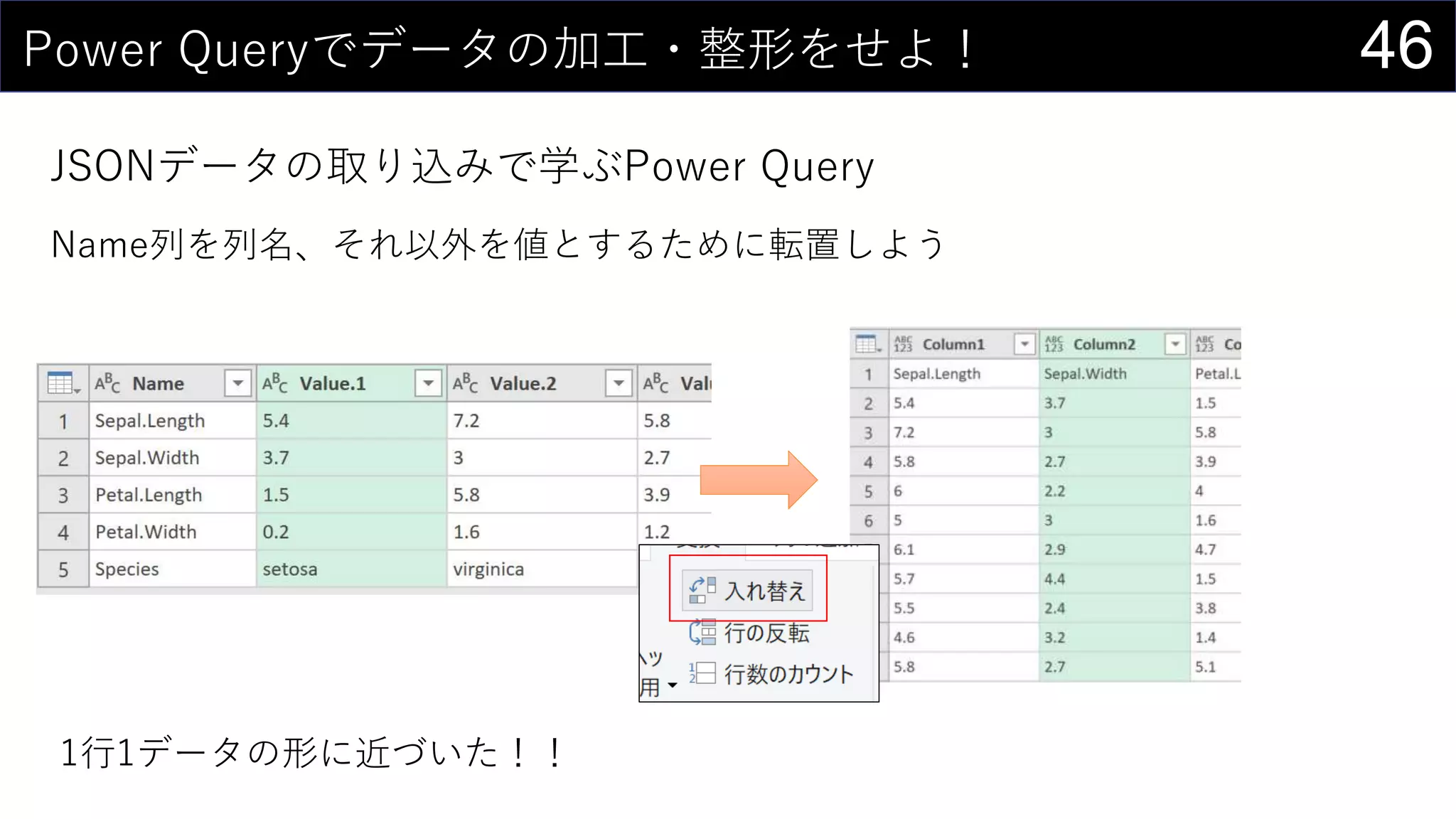
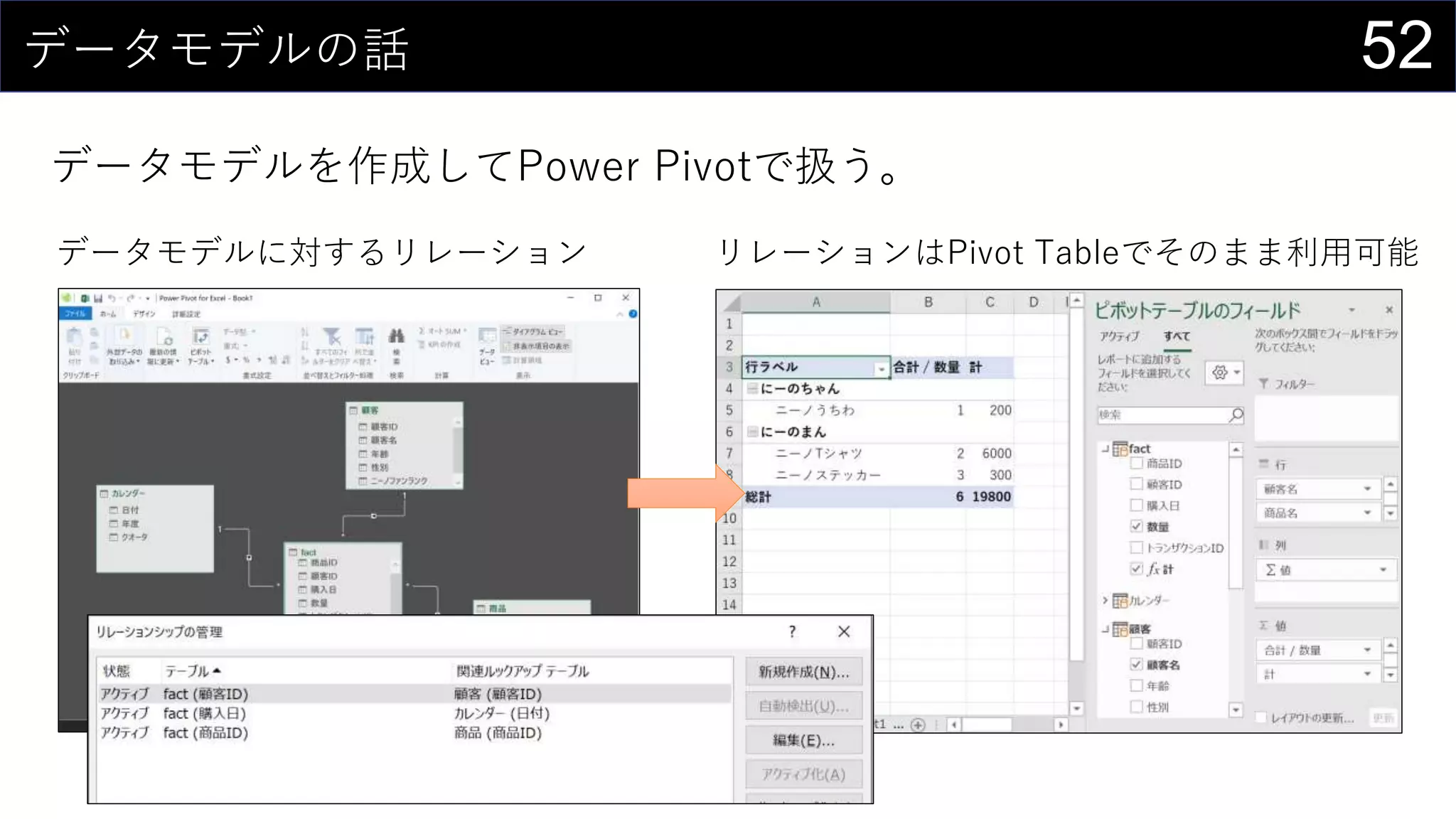
![36ところで...
構造化参照 is 何?
セルの範囲ではなく列名を使ってデータを取り出す参照方法
↑こんな感じのデータがあるとする
テーブル名[[列名1]:[列名2]]で連続する複数列を取り出す
=SUMPRODUCT(iris[[Sepal.Length]:[Sepal.Width]])
テーブル名のみでデータ部分全体を取り出す
=SUMPRODUCT(iris)](https://image.slidesharecdn.com/devio2019tokyo-191031003046/75/Excel-2nd-Edition-36-2048.jpg)
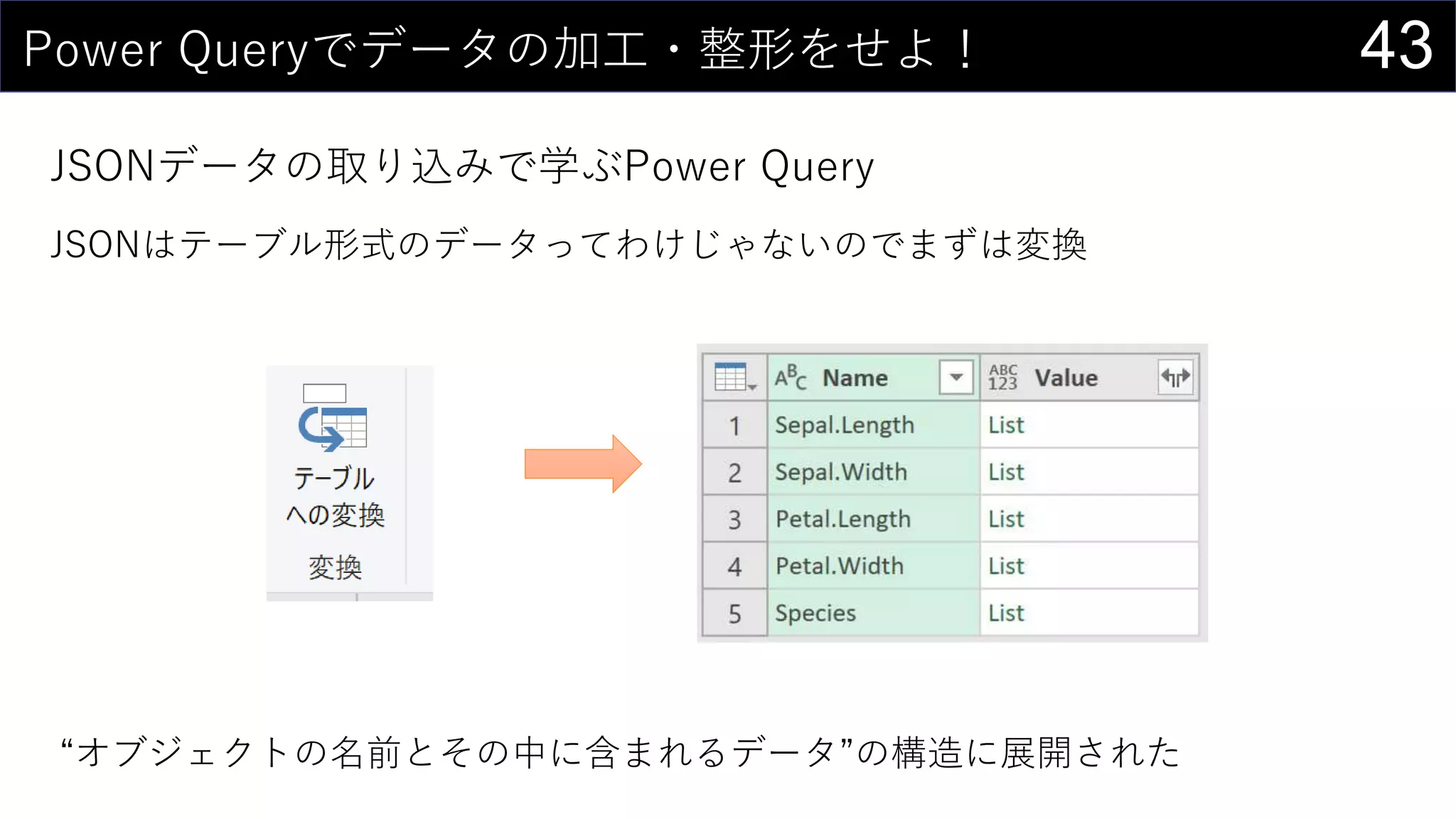
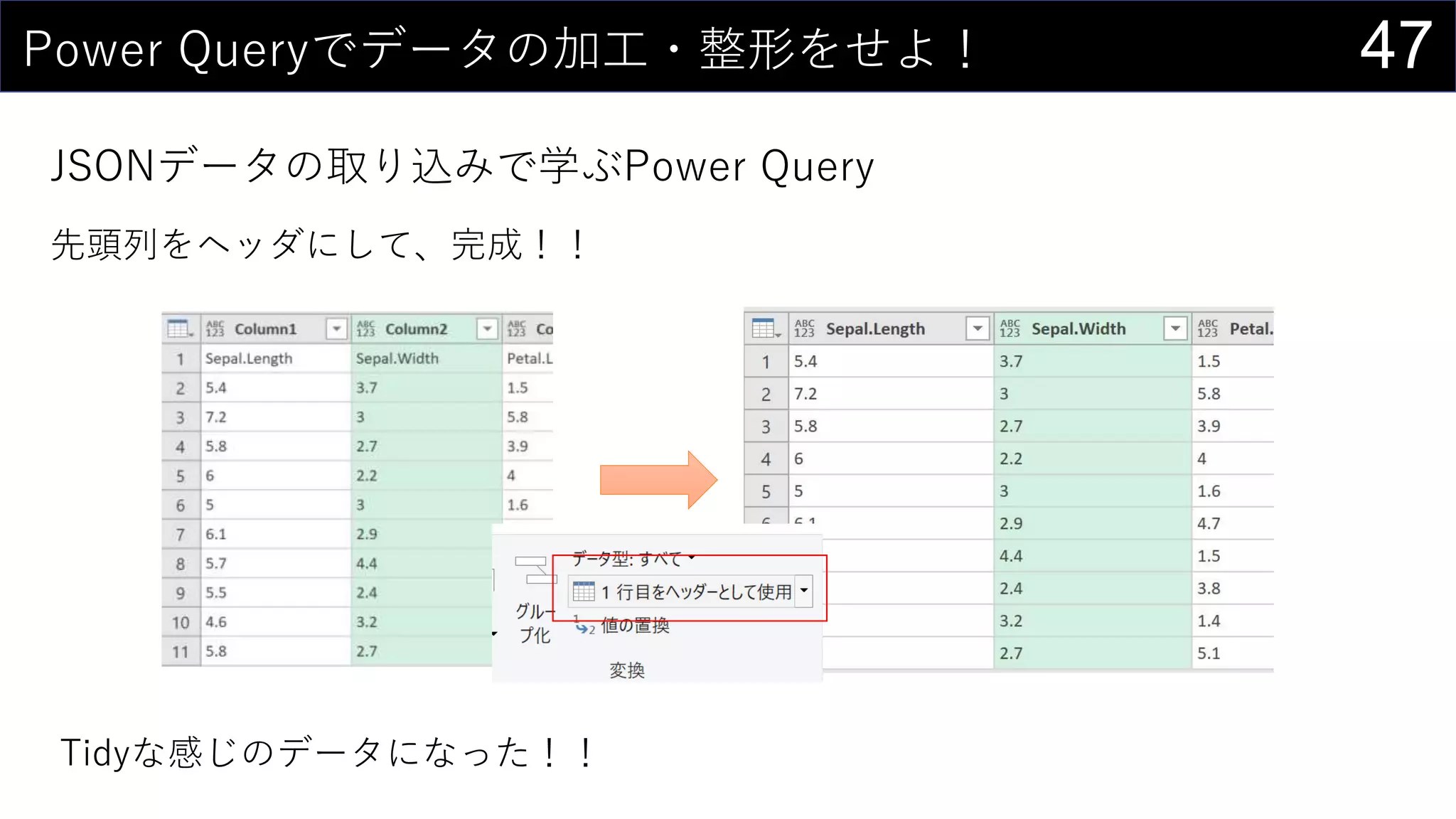
![37ところで...
構造化参照 is 何?
セルの範囲ではなく列名を使ってデータを取り出す参照方法
↑こんな感じのデータがあるとする
テーブル名[#見出し]で列全体を取り出す
=COUNTA(iris[#見出し])
テーブル名[[#見出し], [列名]]で特定の列を取り出す
=iris[[#見出し], [Sepal.Length]]](https://image.slidesharecdn.com/devio2019tokyo-191031003046/75/Excel-2nd-Edition-37-2048.jpg)











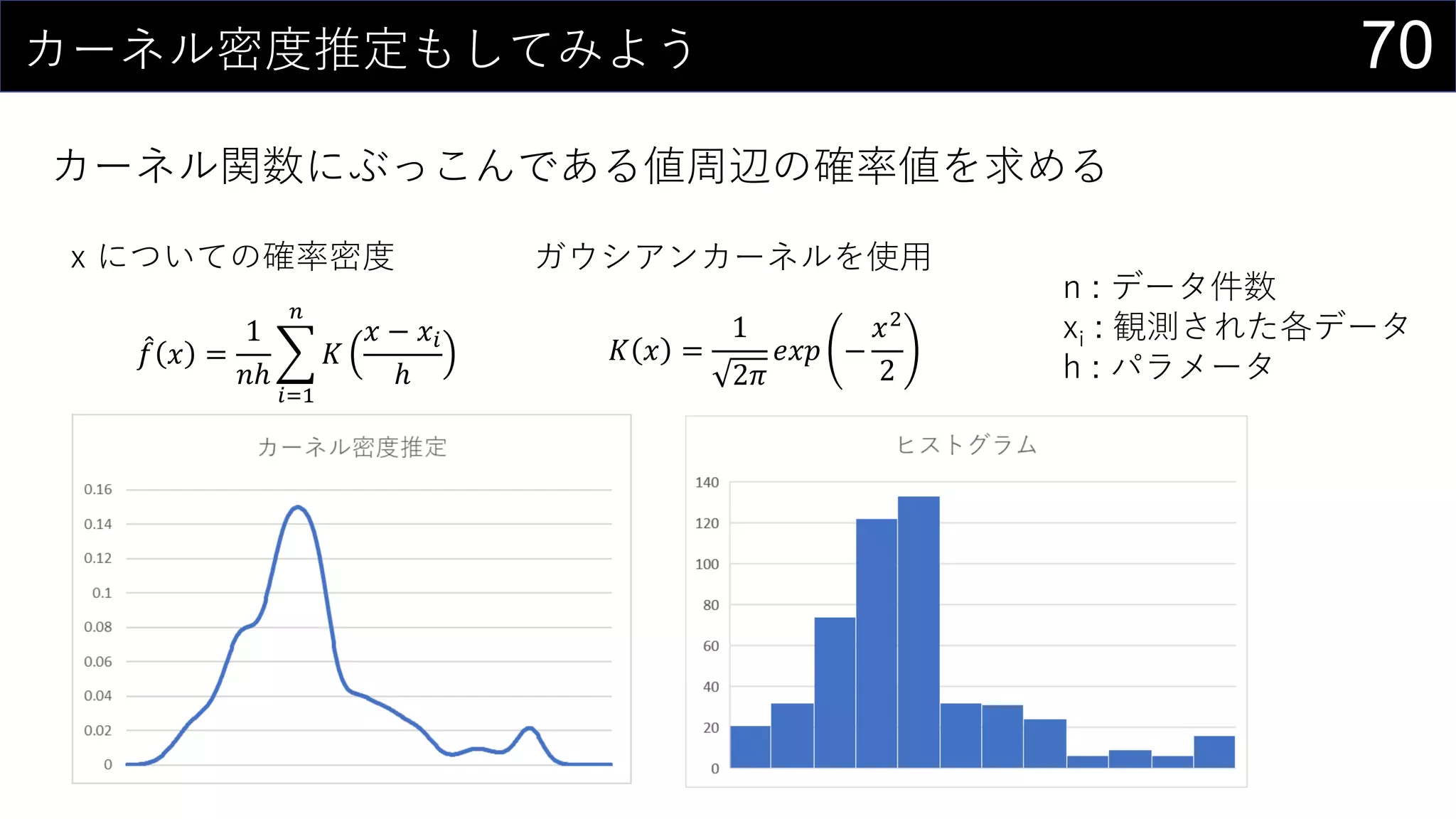
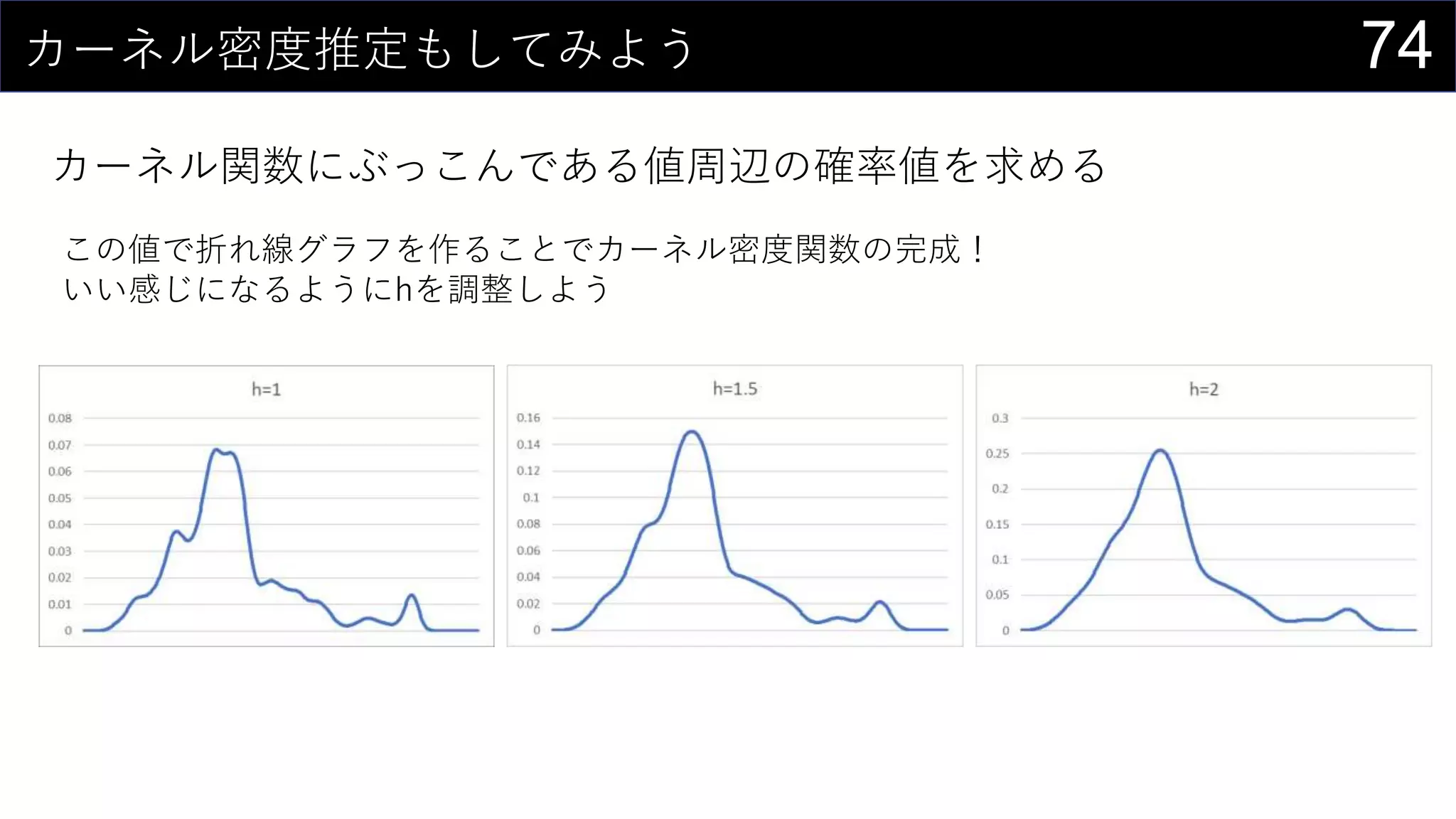
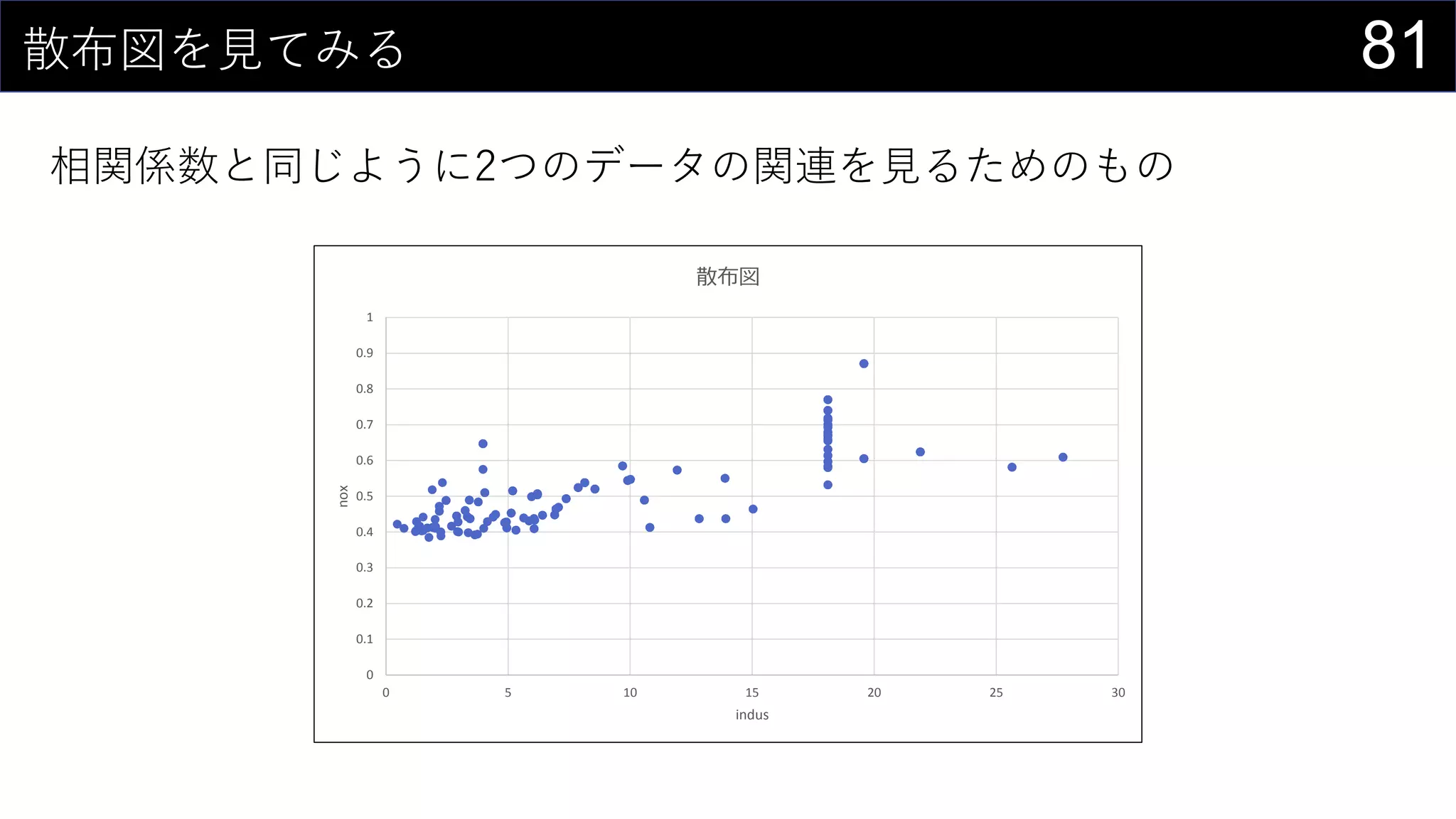
![71カーネル密度推定もしてみよう
カーネル関数にぶっこんである値周辺の確率値を求める
取りうるxの範囲をデータから決める
• 最大値 : MAX(boston[medv])
• 最小値 : MIN(boston[medv])
編集 > フィル > 連続データの作成
でmin/maxを参照にxの値を生成する
• 今回は0~60までを0.1刻みで生成](https://image.slidesharecdn.com/devio2019tokyo-191031003046/75/Excel-2nd-Edition-71-2048.jpg)
![72カーネル密度推定もしてみよう
カーネル関数にぶっこんである値周辺の確率値を求める
𝑥𝑖
𝑥
ℎ {=SUM(
1 / SQRT(2 * PI()) *
EXP(
-POWER(($D3 - boston[medv]) / E$2, 2) / 2
)
) / COUNT(boston[medv]) * E$2}
𝑓 𝑥 =
1
𝑛ℎ
𝑖=1
𝑛
1
2𝜋
𝑒𝑥𝑝 −
𝑥 − 𝑥𝑖 ℎ 2
2
計算する値 :](https://image.slidesharecdn.com/devio2019tokyo-191031003046/75/Excel-2nd-Edition-72-2048.jpg)

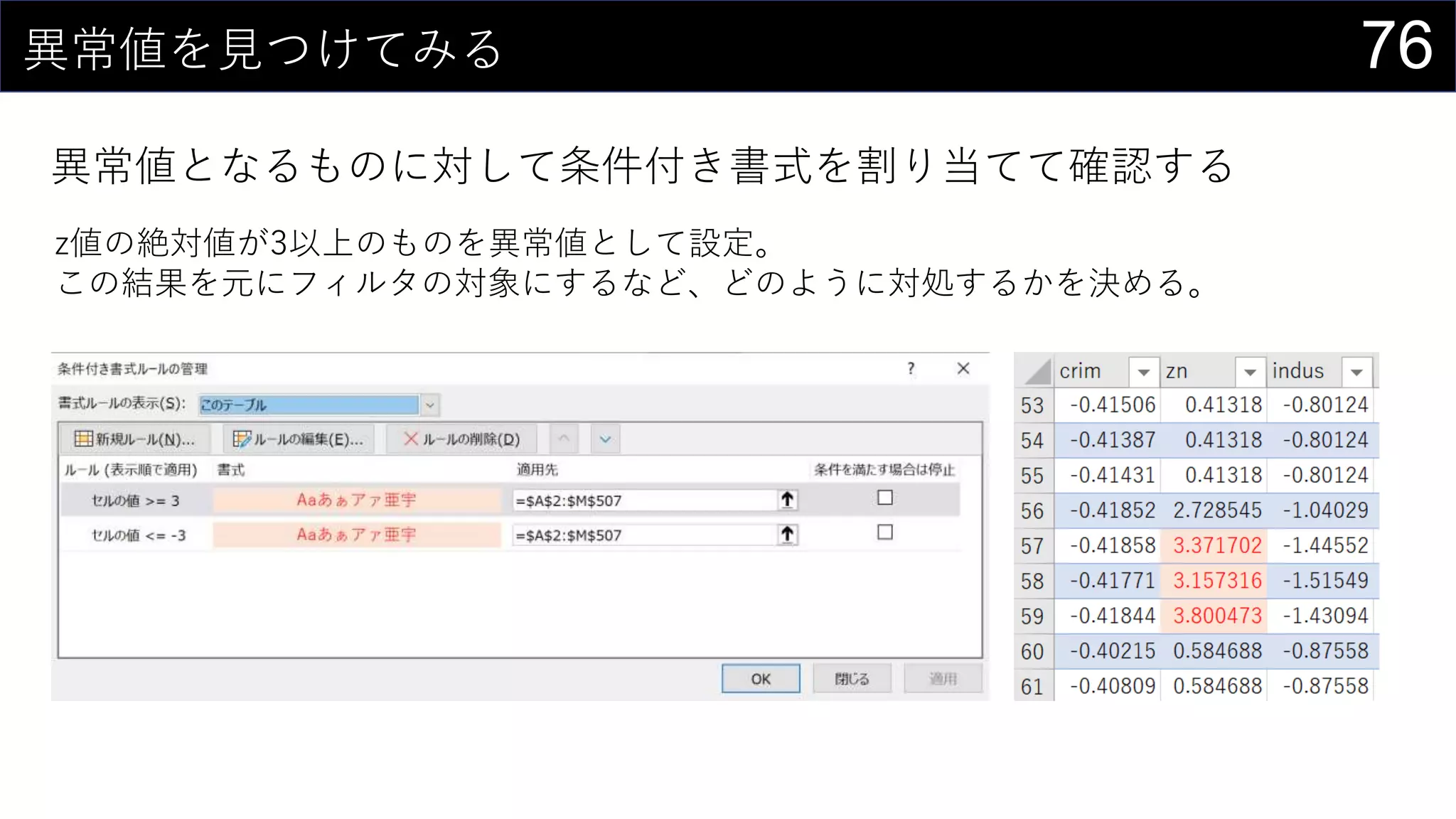
![75異常値を見つけてみる
z値を計算する
𝑧 = (𝑥 − 𝜇) 𝜎
=STANDARDIZE(
boston[@nox],
AVERAGE(boston[nox]),
STDEV.S(boston[nox]))
計算する値 :
• テーブルになってれば行は勝手に計算される
• 列方向はオートフィルで](https://image.slidesharecdn.com/devio2019tokyo-191031003046/75/Excel-2nd-Edition-75-2048.jpg)

![79相関係数を求めてみる
別解 : 頑張って計算する
各データのz値
{=MMULT(TRANSPOSE(boston_z), boston_z) / (COUNT(boston_z[crim])-1)}
行列積を計算してデータ件数-1で割る
データ分析ツールは甘えなので計算する](https://image.slidesharecdn.com/devio2019tokyo-191031003046/75/Excel-2nd-Edition-79-2048.jpg)

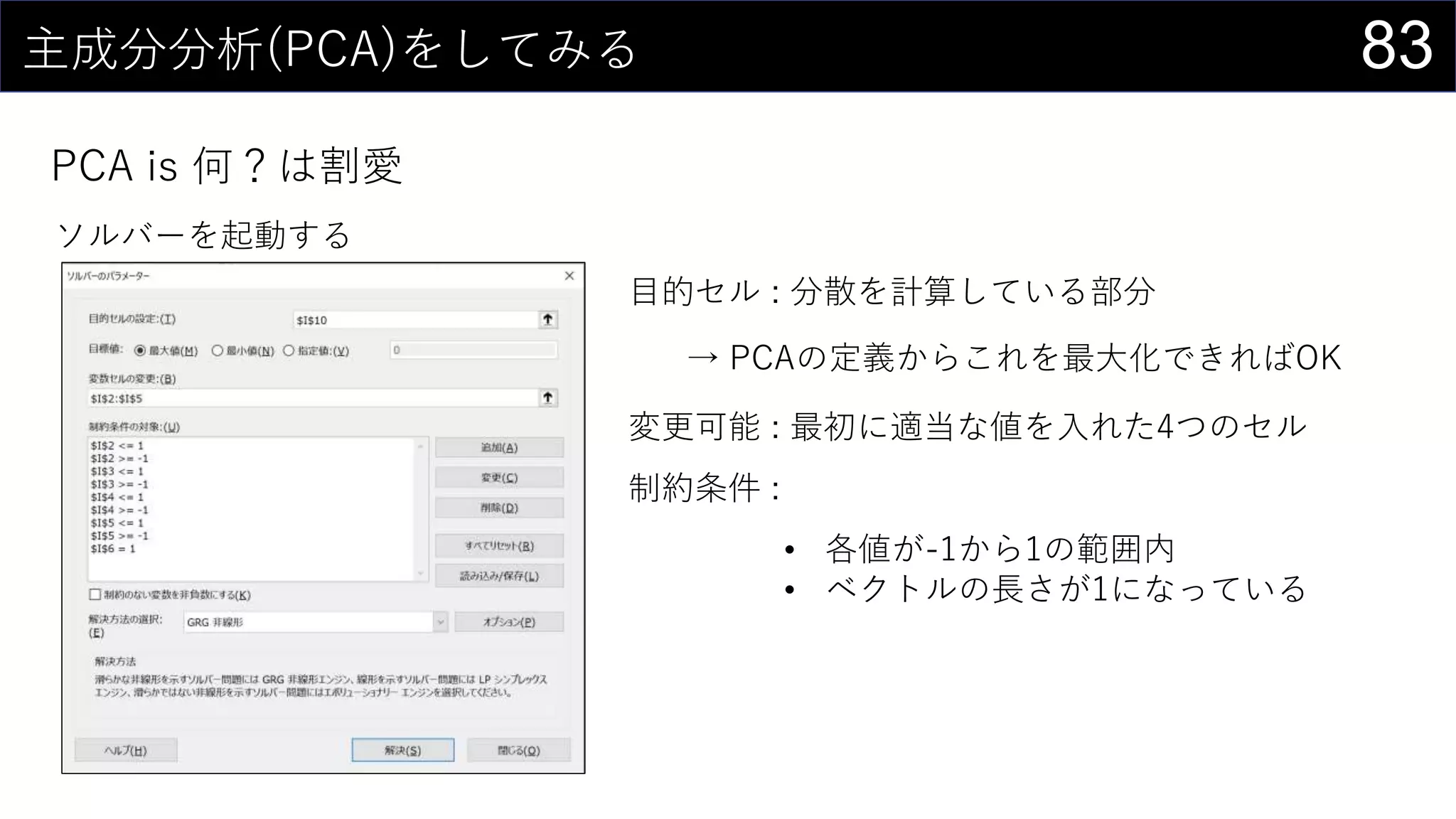
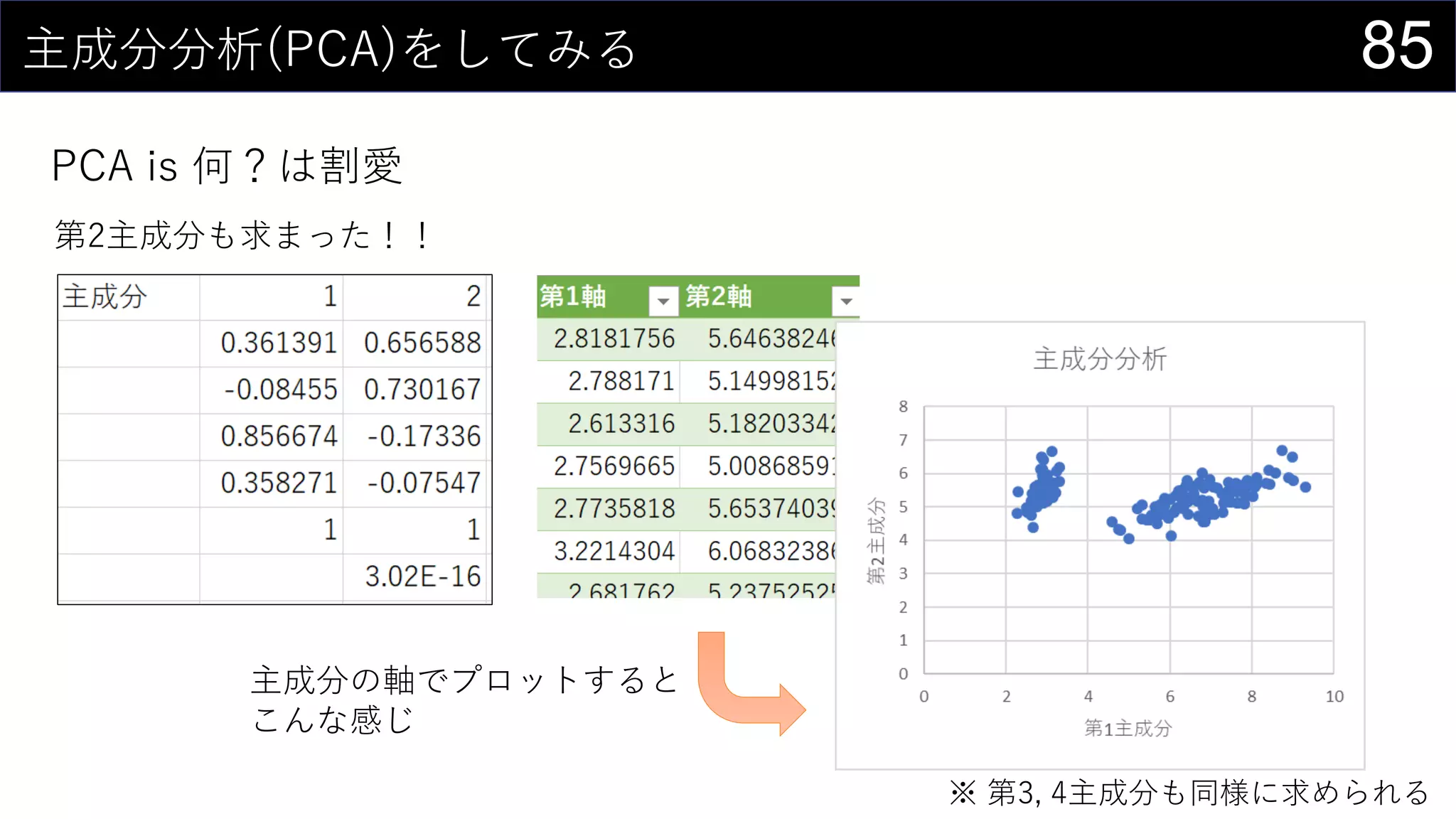
![82主成分分析(PCA)をしてみる
PCA is 何?は割愛
列数と同じ数の適当な値を入れる
適当な値
=SUMSQ(I2:I5)
ベクトルの長さ
{=MMULT(
iris4[@[Sepal.Length]:[Petal.Width]],
$J$2:$J$5)}
主成分の値を計算する
分散を求める
=VAR.S(iris4[第1軸])](https://image.slidesharecdn.com/devio2019tokyo-191031003046/75/Excel-2nd-Edition-82-2048.jpg)


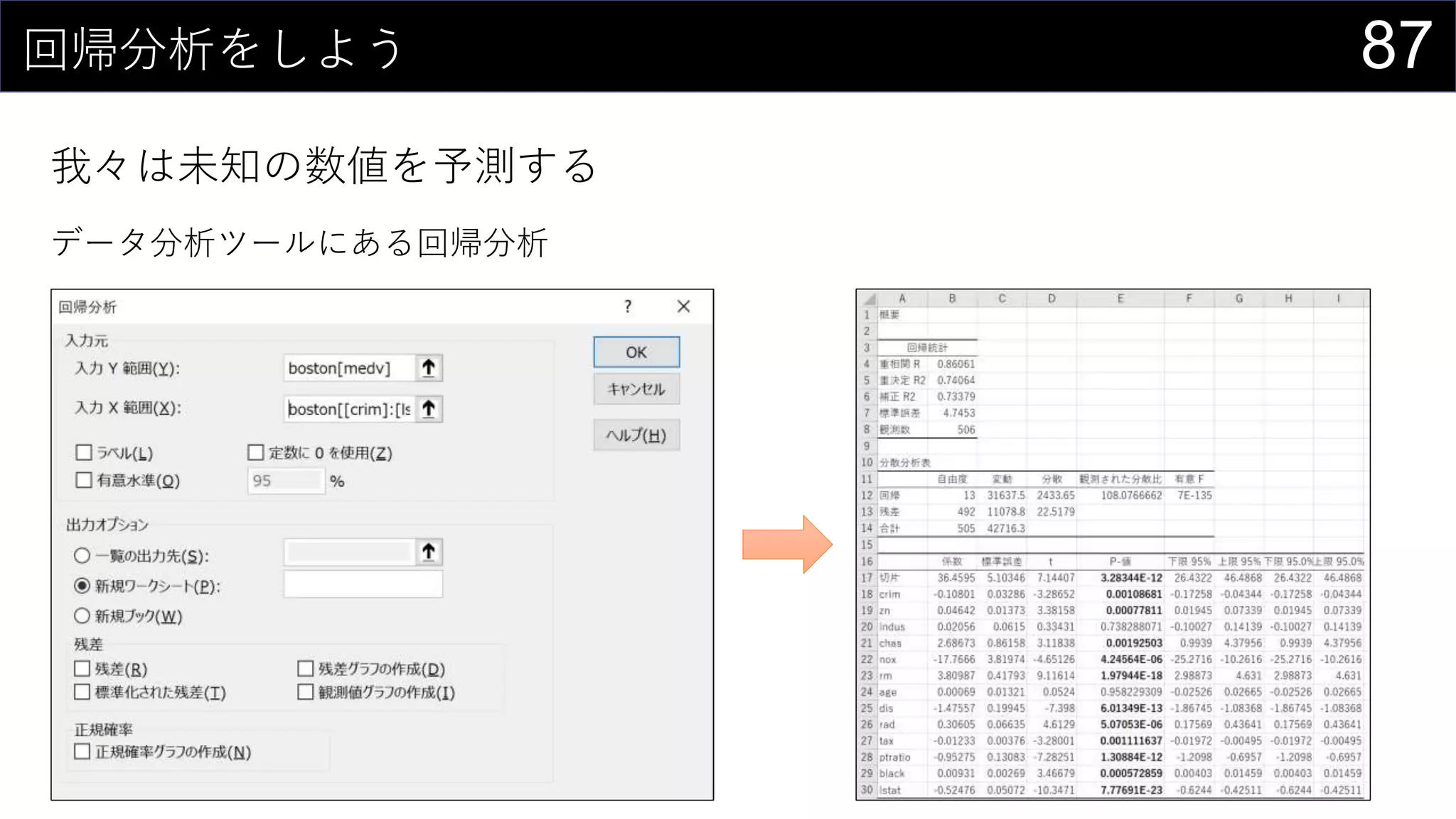
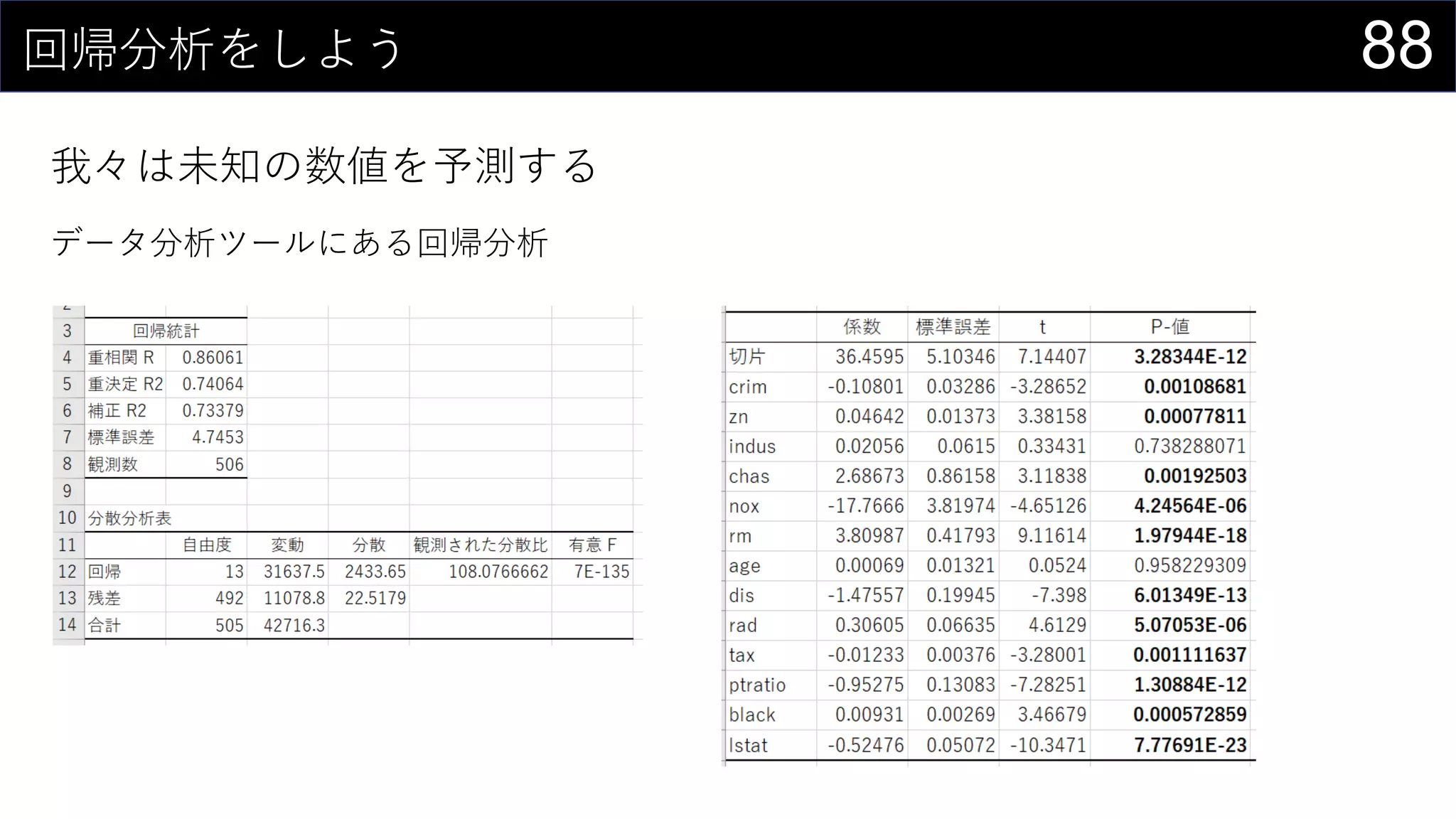
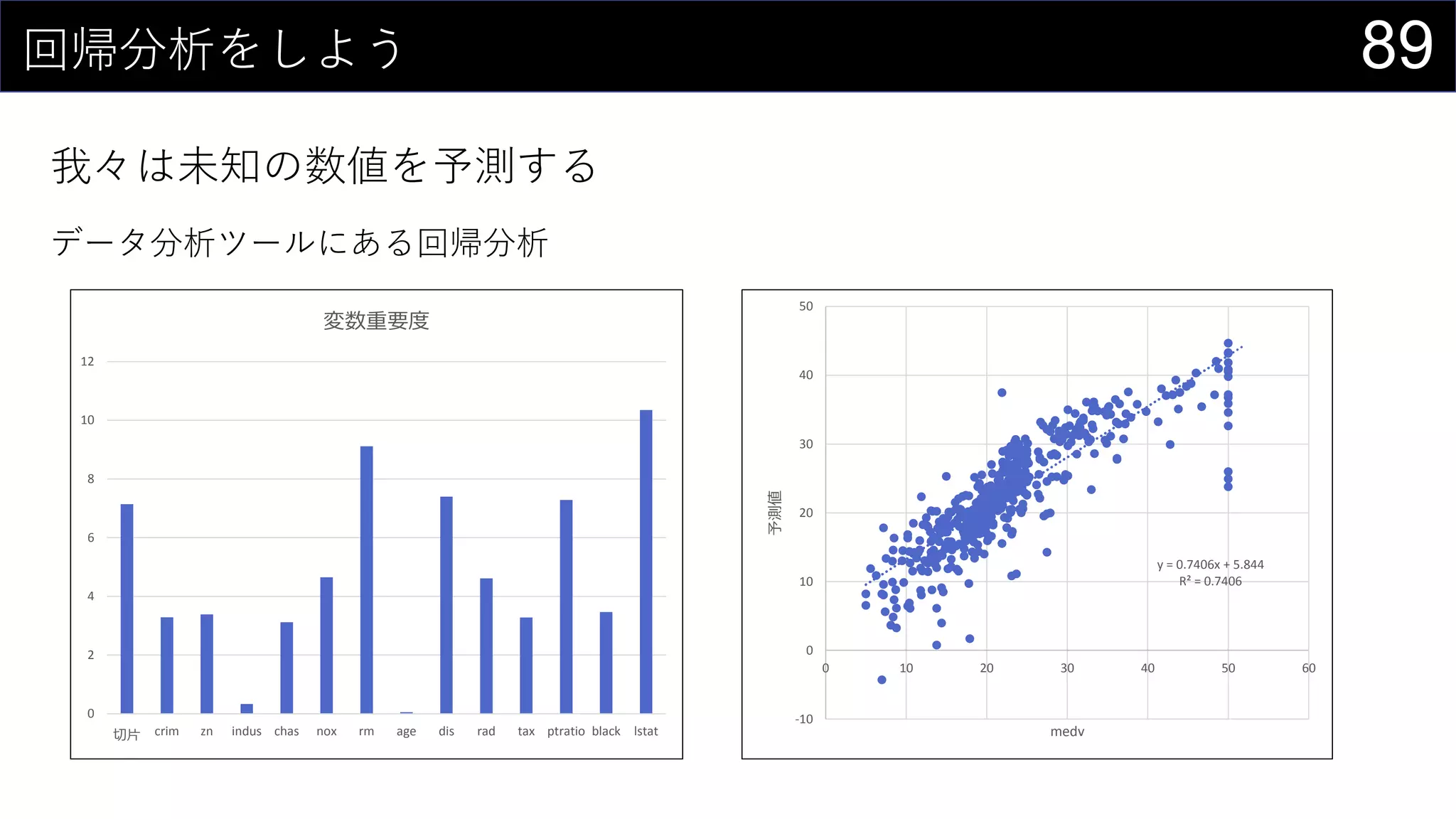
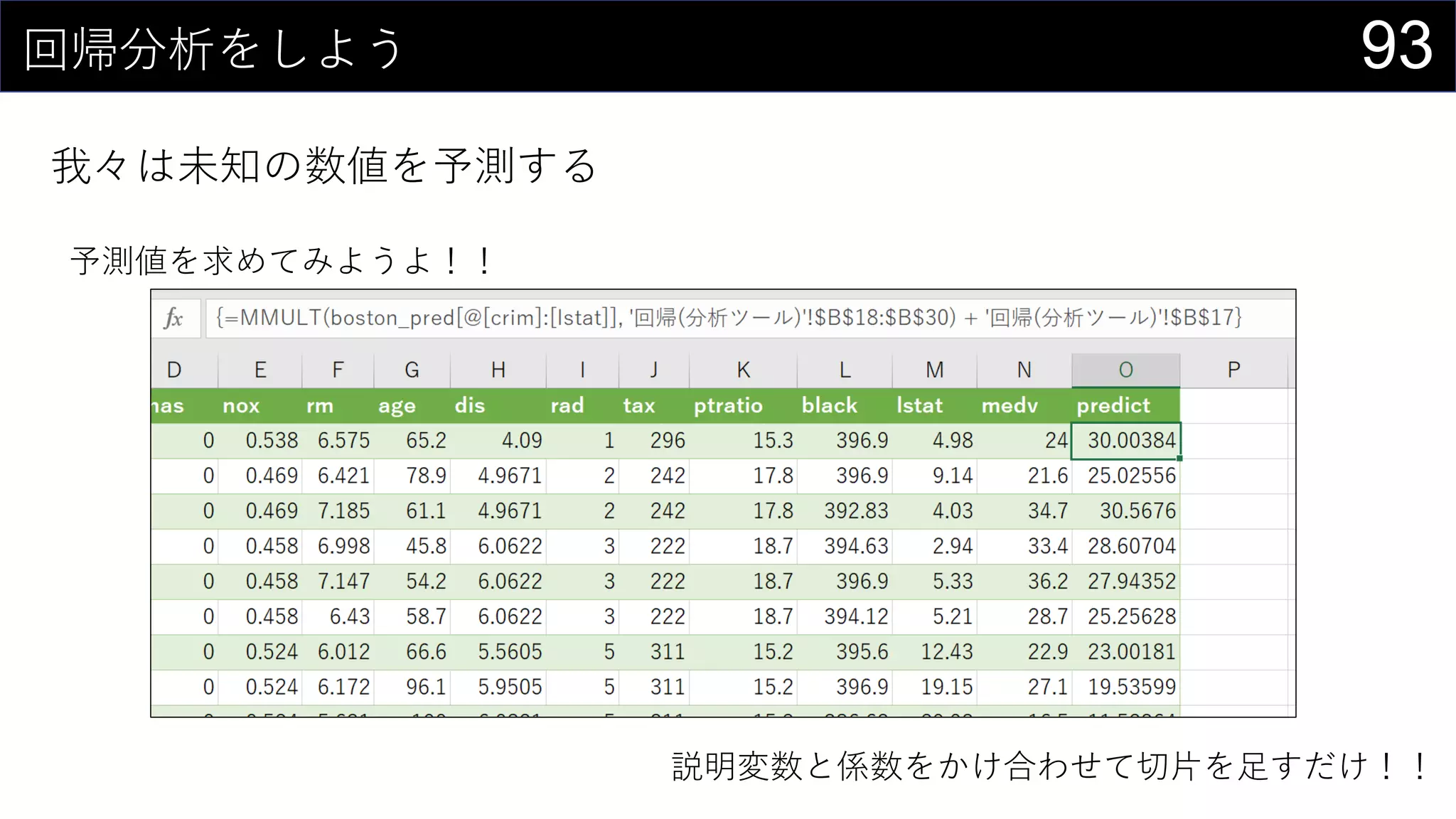
![90回帰分析をしよう
我々は未知の数値を予測する
データ分析ツールは甘えなので計算する
とはいえ、回帰は関数が用意されている
{=LINEST(boston[medv], boston[[crim]:[lstat]], TRUE, TRUE)}
※ 係数の順番が元データと逆になるので注意](https://image.slidesharecdn.com/devio2019tokyo-191031003046/75/Excel-2nd-Edition-90-2048.jpg)

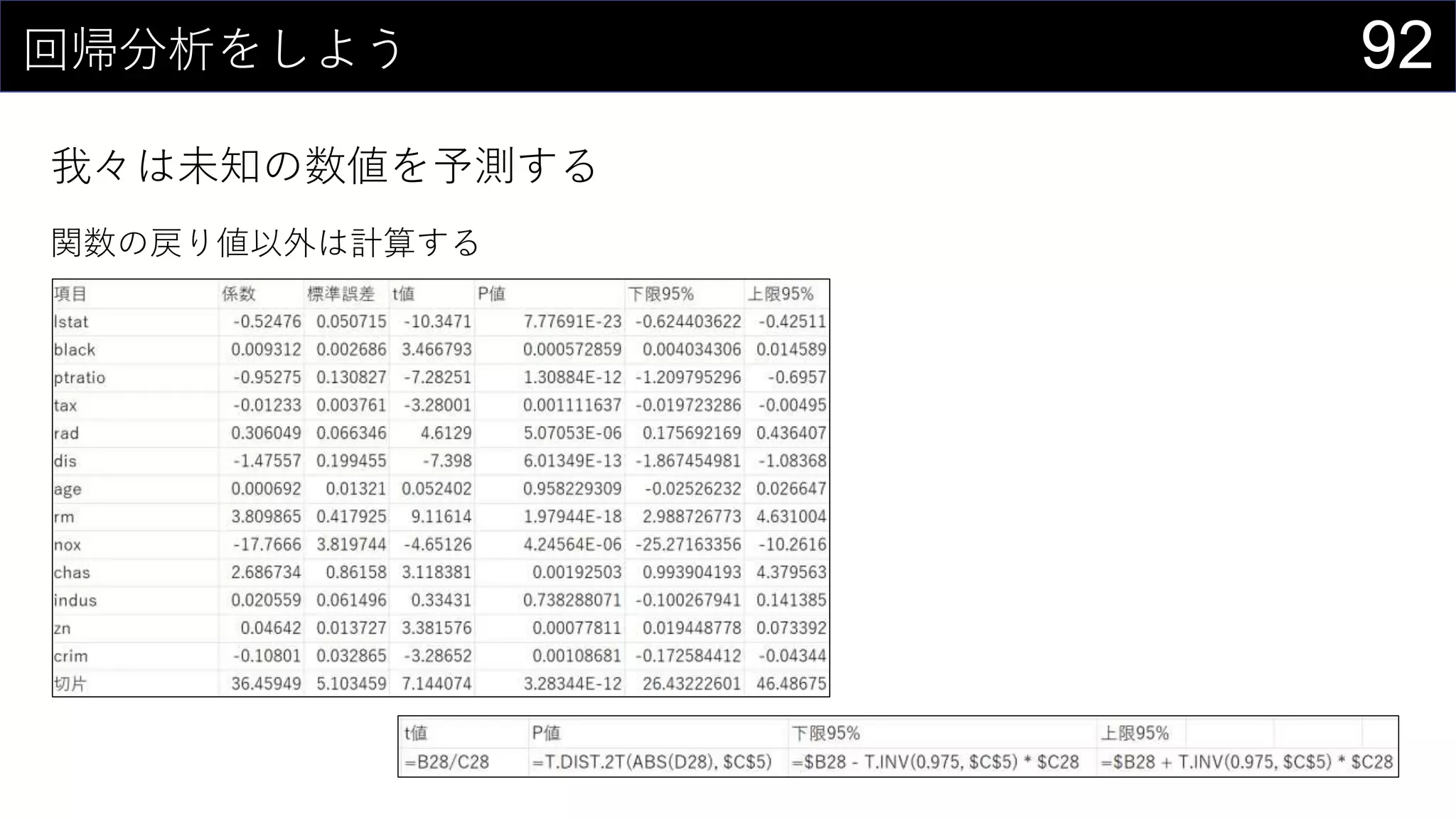
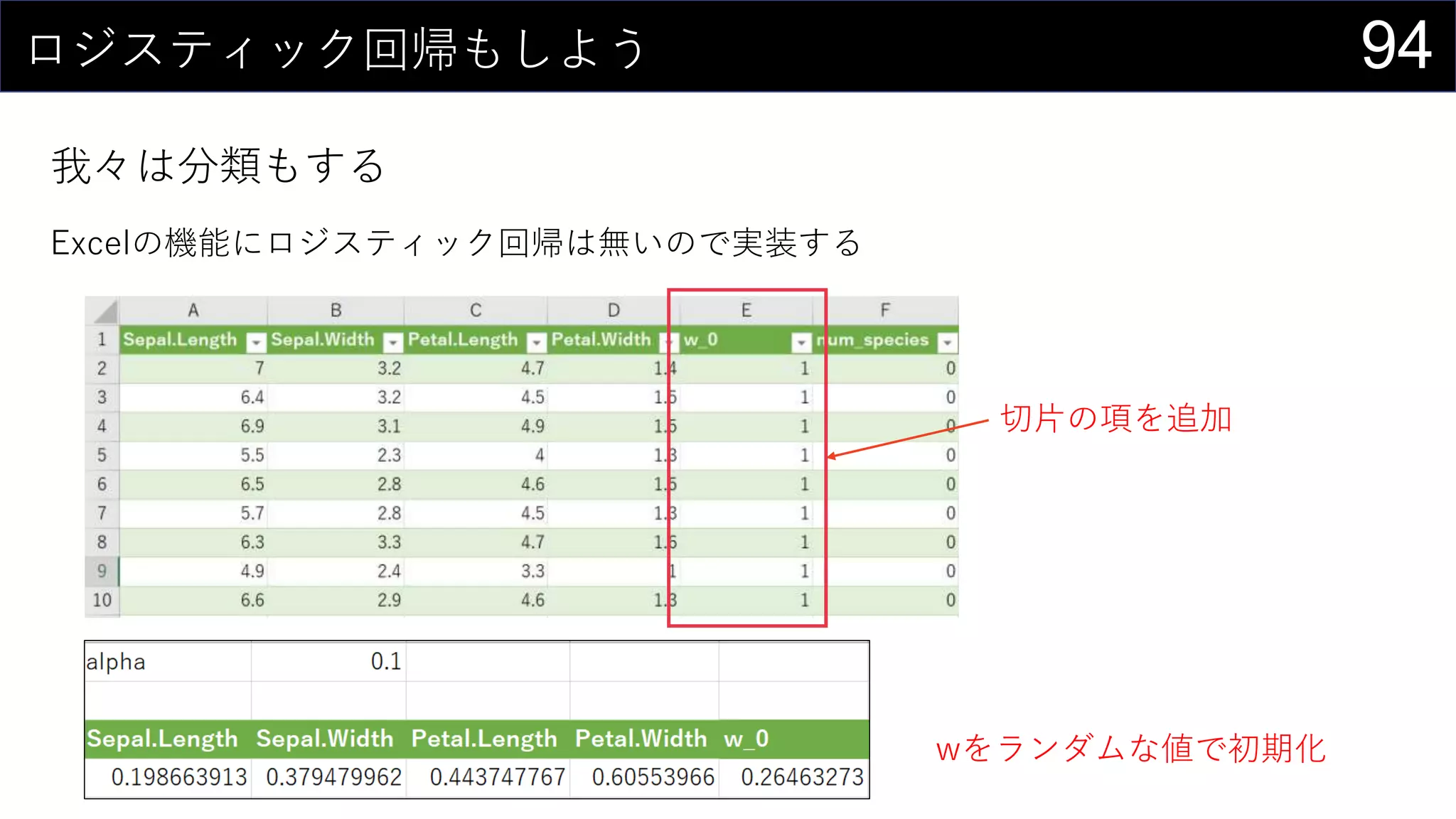
![95ロジスティック回帰もしよう
我々は分類もする
Excelの機能にロジスティック回帰は無いので実装する
損失関数を計算
∅ 𝒙 =
1
1 + exp 𝒘 𝑇 𝒙
𝐸 = −
𝑖=1
𝑛
𝑦𝑖 𝑙𝑛∅ 𝑥𝑖 + 1 − 𝑦 𝑙𝑛 1 − ∅ 𝑥𝑖
{=-SUM(
iris_orig[num_species] *
LN(1 / (1 + EXP(-MMULT(iris_orig[[Sepal.Length]:[w_0]], TRANSPOSE(A4:E4))))) +
(1-iris_orig[num_species]) *
LN((1 - 1 / (1+EXP(-MMULT(iris_orig[[Sepal.Length]:[w_0]], TRANSPOSE(A4:E4))))))
)](https://image.slidesharecdn.com/devio2019tokyo-191031003046/75/Excel-2nd-Edition-95-2048.jpg)
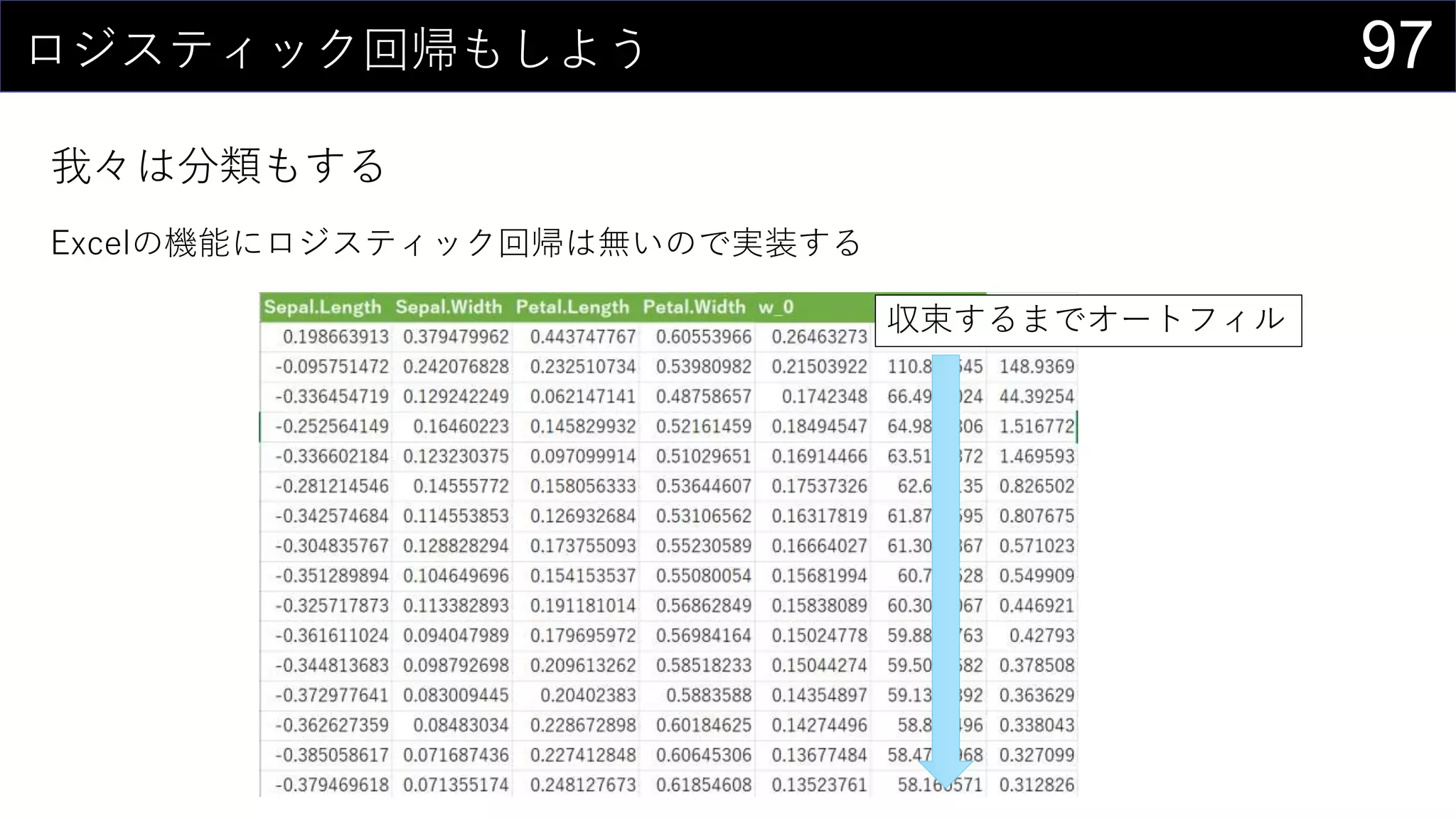
![96ロジスティック回帰もしよう
我々は分類もする
Excelの機能にロジスティック回帰は無いので実装する
損失関数の微分とハイパーパラメータα
の値を使って各wの値を更新
𝑤𝑖 = 𝑤𝑖 + 𝛼
𝜕𝐸
𝜕𝑤𝑖
𝜕𝐸
𝜕𝑤 𝑛
= 𝒚 − ∅ 𝒙
𝑇
𝒙𝑖
=$A4:$E4 + $B$1 *
MMULT(
TRANSPOSE(iris_orig[num_species] –
(1/(1+EXP(
-MMULT(iris_orig[[Sepal.Length]:[w_0]],
TRANSPOSE($A4:$E4)))))),
iris_orig[[Sepal.Length]:[w_0]]
)/COUNT(iris_orig[Sepal.Length])
損失関数の減り具合を確認](https://image.slidesharecdn.com/devio2019tokyo-191031003046/75/Excel-2nd-Edition-96-2048.jpg)
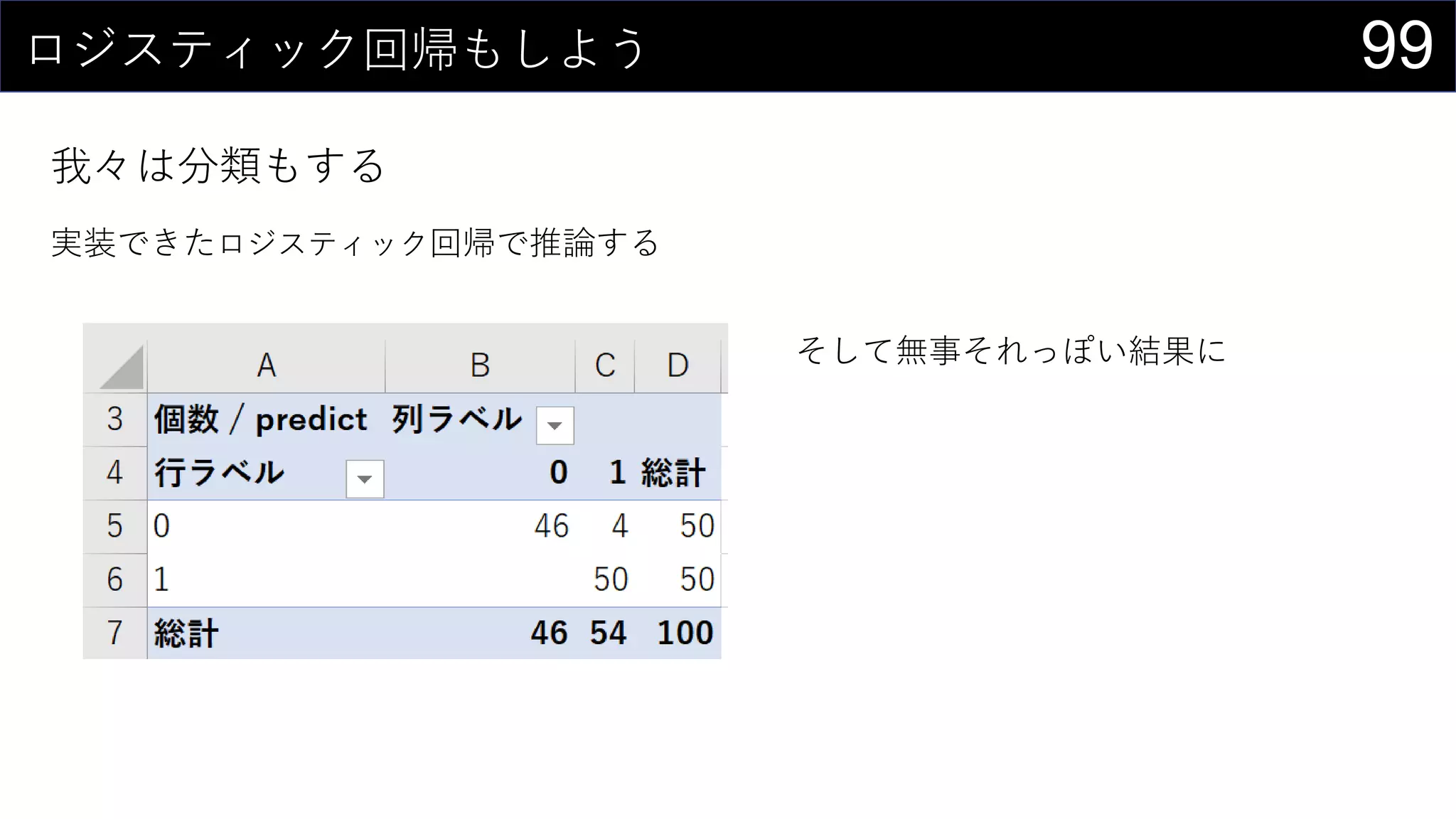
![98ロジスティック回帰もしよう
我々は分類もする
実装できたロジスティック回帰で推論する
=IF([@predict] > 0.5, 1, 0)
{=1 / (1 + EXP(-MMULT(iris[@[Sepal.Length]:[w_0]], TRANSPOSE(Sheet1!$D$300:$H$300))))}](https://image.slidesharecdn.com/devio2019tokyo-191031003046/75/Excel-2nd-Edition-98-2048.jpg)








![[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス](https://cdn.slidesharecdn.com/ss_thumbnails/amazonauroratips-170307140000-thumbnail.jpg?width=640&height=640&fit=bounds)


























































