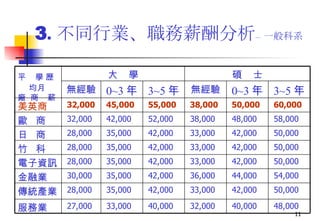
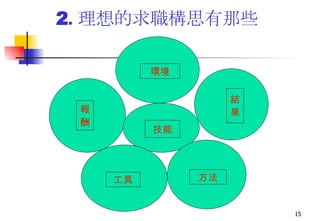
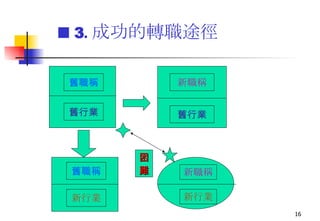
本次講座由邱煥濤秘書長主講,探討社會新鮮人的生涯規劃及就業市場環境。內容包括國內外經濟趨勢、不同產業就業市場分析、求職技能及個人履歷準備技巧等,旨在幫助新鮮人把握機會與制定未來職業規劃。講座還強調了健康的就業價值觀和成功求職的關鍵要素。